

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスコンサルティングユニット所属の金です。
現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
今回は、ソフトウェアエンジニアリングにおけるLLMの適用をトピックにメイン論文と関連論文を紹介します。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
ソフトウェアエンジニアリングにおけるLLMの適用

両分野における関連論文数のトレンド
ソフトウェアエンジニアリングの分野では、作業の自動化と効率化が強く求められており、特に大規模現モデル(LLM)の応用に対する期待が高まっています。これは、コーディング、テスト、デバッグなどのタスクをより迅速かつ効果的に行うための手段として見られています。 しかし、ソフトウェアエンジニアリングにおけるLLMの具体的な能力や、それに伴うリスクや制約についての知見は、まだ十分に整理されていないのが現状です。これには、LLMsの出力の信頼性や、特定の技術的課題(例えば、生成されたコードの品質や適切なテストケースの生成など)への対応が含まれます。 Metaなどの研究者たちによる「Large Language Models for Software Engineering: Survey and Open Problems」(の中で特にソフトウェア開発の内容)をまとめてみました。
https://arxiv.org/abs/2310.03533
メイン論文の構成は下図の通りです。本記事ではソフトウェア開発と関係のあるセクション3~7を解説します。
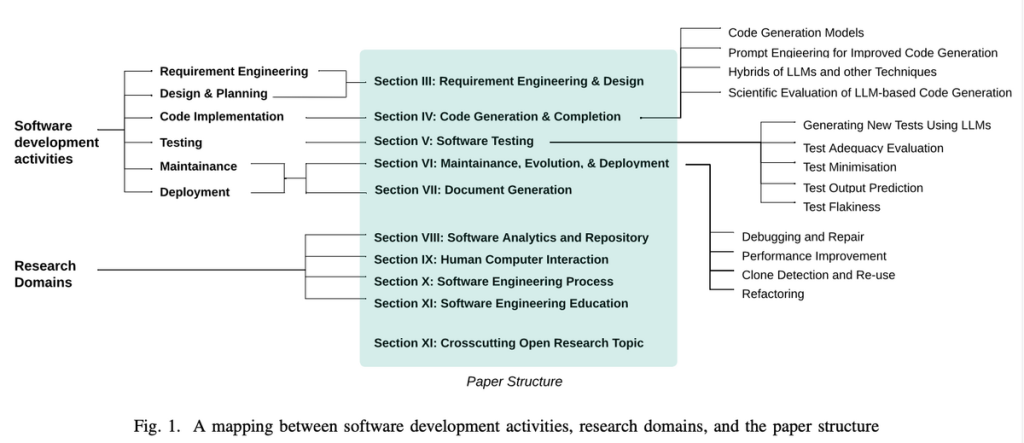
現状の要件工学と設計:
LLMによる貢献の可能性:
障壁と課題:
要約:
関連論文:

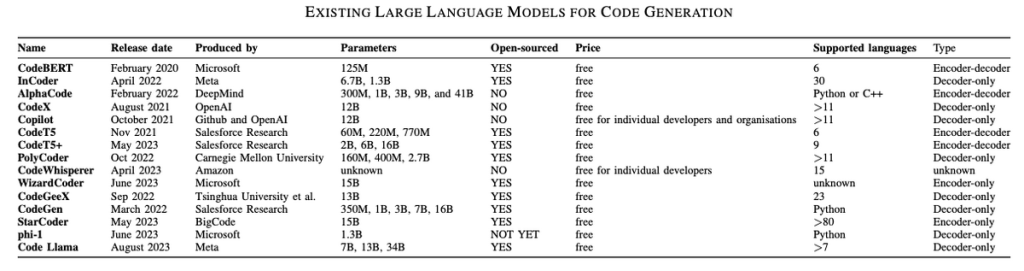
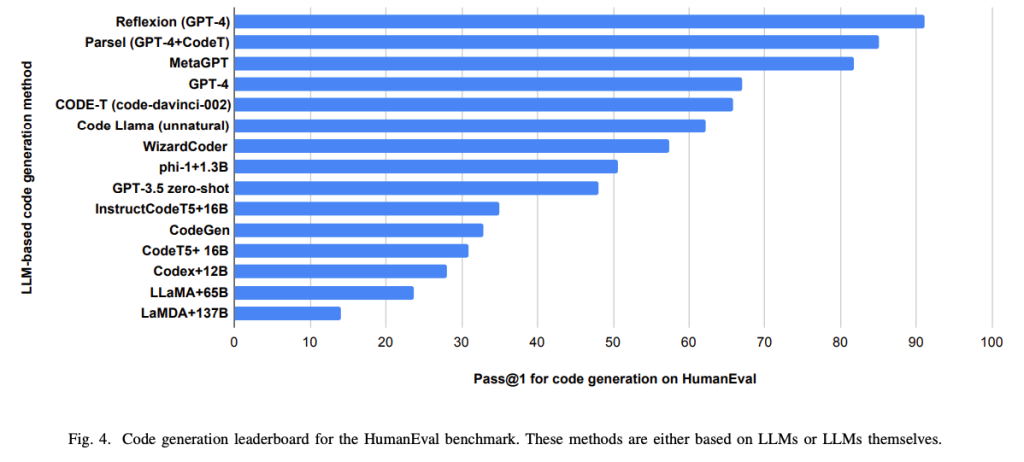
現状:
LLMの貢献:
障壁と課題:
要約:
関連論文:
| タイトル | 概要 |
|---|---|
| https://arxiv.org/abs/2305.12050 | ・CodeComposeの展開経験を報告。 ・Incoder LLMに基づくコード補完ツールとして、450万件の提案が行われ、22%の受け入れ率を達成。 ・開発者からの質的フィードバックは92%が肯定的であった。 |
| https://arxiv.org/abs/2302.06590 | ・GitHub Copilotの助けを借りて、プログラマーが非自明なタスクを56%速く完了できたことを報告。 ・対照群と比較して、HTTPサーバーの実装などのタスクの効率が大幅に向上。 |
| https://arxiv.org/abs/2107.03374 | ・CodeX、GPT言語モデルの導入と評価。新しい評価セット「HumanEval」を通じて、ドックストリングからのプログラム合成のための機能的正確さを測定。 ・CodeXがGPT-3とGPT-Jを上回るパフォーマンスを発揮したことを確認。 |
| https://arxiv.org/abs/2306.11644 | ・教科書品質のコードコーパスでのトレーニングにより、より小さいLLMでも大規模モデルに匹敵するパフォーマンスが達成可能であることを示唆。 ・GPT-4モデルを使用して既存のPythonコードコーパスを分類し、学生がプログラミングを学ぶためのコードの教育的価値を評価。 |
現状
LLMの貢献:
障壁と課題:
要約:
関連論文:
| タイトル | 概要 |
|---|---|
| https://arxiv.org/abs/2306.05152 | ・LLMはソフトウェアテストの自動化を助けるが、ハルシネーションや限られた自動評価能力が課題。 ・プロンプトエンジニアリング、テストの自己評価、科学的基盤の改善が今後の重要な研究方向。 |
| CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models | ・従来の検索ベースのソフトウェアテスト(SBST)と大規模言語モデル(LLM)を組み合わせて、テストのカバレッジを改善する。 ・進捗が停滞するまでSBSTを適用し、その後カバレッジが不十分なコードに対して例となるテストケースをCodexのようなLLMに要求して、テストケース生成を強化する。 ・486のベンチマークにおけるテストでは、標準のSBSTやLLMのみの方法と比較して、CodaMosaは統計的に有意なカバレッジの改善を示した。 |
現状:
LLMの貢献:
障壁と課題:
要約:
関連論文:
| タイトル | 概要 |
|---|---|
| https://arxiv.org/abs/2304.13187 | ・GPT-4のリファクタリング能力の実験と評価。 ・研究ではGPT-4が提供したリファクタリングの例を用いて、コード品質がHalstead複雑性やMcCabe複雑性といった既存の構造的メトリクスに従ってどのように改善されるかを分析している。 ・GPT-4はリファクタリングを通じてコード品質を有意に改善することが可能であることを示している。 |
| https://arxiv.org/abs/2301.03373 | ・コードアシスタントとしてのAI、特にチャットボットの潜在能力に注目。 ・レガシーコードのリファクタリングと、複雑なコードリポジトリの説明や機能をよりアクセスしやすく、簡単にするプロセスにおけるAIの役割に光を当てている。 ・AIコードアシスタントがレガシーコードの理解とリファクタリングを支援し、高価値リポジトリの機能を簡潔に説明することの有益性を強調。 |
現状:
障壁と課題:
要約:
関連論文:
| [2305.12865] Automatic Code Summarization via ChatGPT: How Far Are We? | ChatGPTを使ってPythonコードの要約能力をテストしましたが、他のモデルよりも性能が低かった。 |
| [2304.06815] Automatic Semantic Augmentation of Language Model Prompts (for Code Summarization) | GPT-3.5でコード要約の精度を高めるために、特別な指示を与える方法(プロンプトエンジニアリング)を用いました。 |
| [2304.11384] Large Language Models are Few-Shot Summarizers: Multi-Intent Comment Generation via In-Context Learning | 既存の言語モデルがコードの異なる技術的側面からの要約を生成できる能力を持っていることを確認しました。 |
1. LLMの現状:
2. LLMのできること:
3. リスクと制約:
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













