



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

XaaSユニット クロスエンジニアリング所属の田中です。
エンジニアリング組織では、開発力の向上を目指し、日々様々な改善を行なっています。エンジニアリング組織のパフォーマンスを可視化することで現状把握、ボトルネックの把握、改善策の実行を行うことができます。
今回は、 Pull Request の指標を収集・計測をし組織のパフォーマンスを可視化しましたので、その事例を紹介します。
Pull Requestとは、ソフトウェア開発において、プロジェクトの途中で変更・追加されたコードが、メインのコードベースに組み込まれる前のレビュープロセスのことです。
Pull Requestにて開発プロセスの効率を評価するために、次の3点のデータに注目することが重要だと考えられます。
これらのデータを可視化することで、開発プロセスのボトルネックがどこにあるか、どのように改善できるかを具体的に把握することができます。
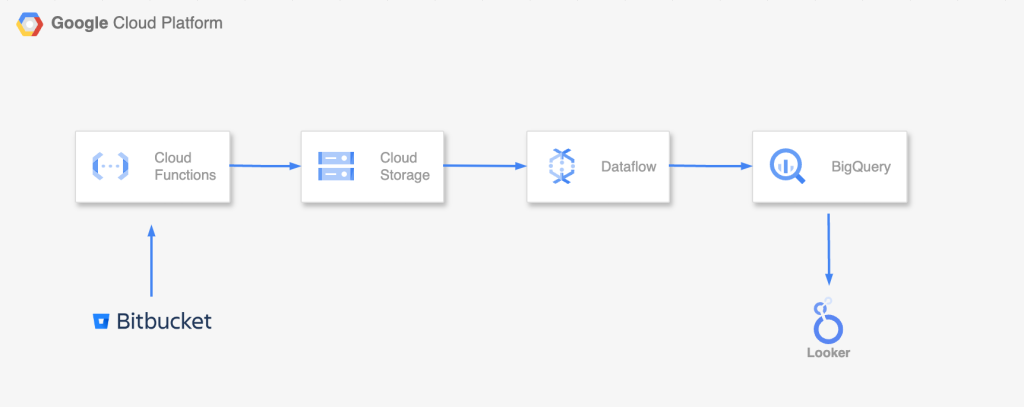
Bitbucket APIから取得し、GCSにrow data として保存します。GCS から Dataflowで整形を行い、各指標をBigQueryに保存します。最後にLooker Studioで可視化を行いました。
Bitbucket APIから取得 → GCS
import axios from "axios";
import "dotenv/config";
import fs from "fs";
import { Storage } from "@google-cloud/storage";
const bitbucketApi = axios.create({
baseURL: "https://api.bitbucket.org/2.0",
timeout: 10000,
headers: { Authorization: `Bearer ${process.env.BITBUCKET_ACCESS_TOKEN}` },
});
const repoSlug = process.env.REPO || "";
const workspaceId = process.env.WORKSPACE || "";
const bucketName = process.env.BUCKET_NAME || "";
const getPRs = async (repoSlug: string, workspaceId: string) => {
let hasMore = true;
let page = 1;
let allPRs: Object[] = [];
while (hasMore) {
const response = await bitbucketApi.get(
`/repositories/${workspaceId}/${repoSlug}/pullrequests`,
{
params: {
state: "MERGED",
page: page,
},
}
);
allPRs = allPRs.concat(response.data.values);
hasMore = Boolean(response.data.next);
page++;
console.log("page", page);
}
return allPRs;
};
const uploadFileToGCS = async (bucketName: string, filePath: string) => {
const storage = new Storage();
const bucket = storage.bucket(bucketName);
const fileName = filePath.split("/").pop();
try {
await bucket.upload(filePath, {
destination: fileName,
});
console.log(`Success: Uploaded ${filePath} to ${bucketName}/${fileName}`);
} catch (error) {
console.error("Error in GCS upload:", error);
}
};
const main = async () => {
try {
const prs = await getPRs(repoSlug, workspaceId);
const ndJsonContent = prs.map((obj) => JSON.stringify(obj)).join("\n");
const filePath = `data/${repoSlug}-full.ndjson`;
fs.writeFileSync(filePath, ndJsonContent);
console.log("Success: write ndJson");
await uploadFileToGCS(bucketName, filePath);
} catch (error) {
console.error("Error", error);
}
};
main();Bitbucket APIでPRを一括で取得できないので、ページ毎に取得しています。
GCS → Dataflow
import json
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
pipeline_options = PipelineOptions(
runner="DataflowRunner",
project="your_project",
temp_location="gs://your/backet-path/temp",
region="asia-northeast1",
)
def flatten_json_array(json_str):
json_arr = json.loads(json_str)
return json_arr
def process_pr_data(pr_json_str):
from datetime import datetime
pr = json.loads(pr_json_str)
created_on = datetime.fromisoformat(pr["created_on"].rstrip("Z"))
updated_on = datetime.fromisoformat(pr["updated_on"].rstrip("Z"))
duration_seconds = (updated_on - created_on).total_seconds()
duration_days = duration_seconds / 86400
return {
"pr_id": pr["id"],
"title": pr["title"],
"author": pr["author"]["display_name"],
"comment_count": pr["comment_count"],
"created_on": created_on,
"updated_on": updated_on,
"duration_days": duration_days,
"insertion_timestamp": datetime.utcnow(),
}
schema = "pr_id:INTEGER, title:STRING, author:STRING, comment_count:INTEGER, created_on:TIMESTAMP, updated_on:TIMESTAMP, duration_days:FLOAT, insertion_timestamp:TIMESTAMP"
def run():
with beam.Pipeline(options=pipeline_options) as pipeline:
prs = (
pipeline
| "ReadFromGCS"
>> beam.io.ReadFromText("gs://backet-path/path.ndjson")
| "ProcessPRData" >> beam.Map(process_pr_data)
)
prs | "WriteToBigQuery" >> beam.io.WriteToBigQuery(
"project:dataset-path.table-path",
schema=schema,
create_disposition=beam.io.BigQueryDisposition.CREATE_IF_NEEDED,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND,
)
if __name__ == "__main__":
run()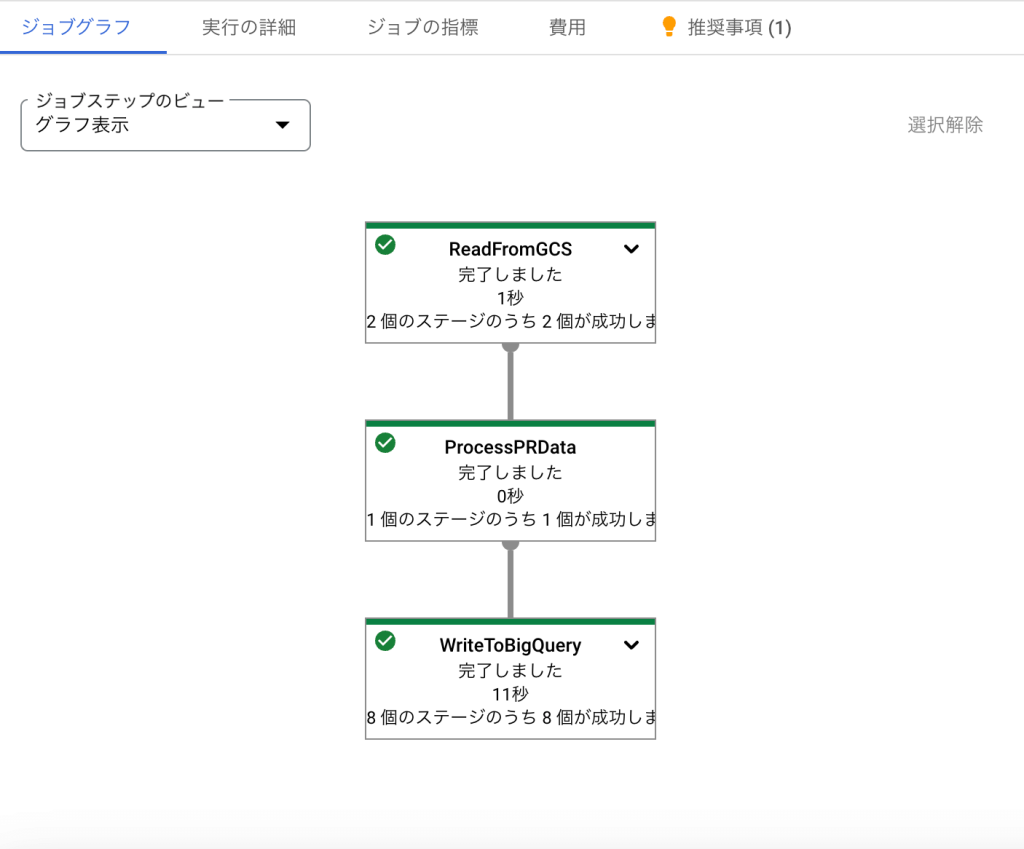
あるプロダクトのPull Requestに関する過去1年のデータを可視化した結果がこちらになります。

一般的にPR数は多く、平均PRクローズ時間は短い方がパフォーマンスが高い状態とされます。
また開発タスクがあまりない、アクティブではないプロジェクトの場合はPR数は減り、平均PRクローズ時間は増える傾向にありました。

このグラフを例にすると①の期間はPR数が少なく(週20PR以下)、平均PRクローズ時間が長く(12日以上)良い状態とは言えません。
それに対し②の期間はPR数が多く(週50PR以上)、平均PRクローズ時間も短く(1.5日以下)パフォーマンスが高い状態と言えることがわかります。
①~②の期間では、”Pull Requestをできるだけ小さくする”、”レビューを優先度の高いタスクとする”、”レビュアーのボトルネックを解消する”などの改善取り組みを行いました。
その結果、パフォーマンスが向上していることがわかりやすくグラフから読み取ることができます。
これらの取り組みの結果、組織のパフォーマンスをPull Requestの指標から評価することができました。個々の感覚ではなく、可視化することで現在の状態、改善の効果を客観的に把握することができました。
また”PRクローズまでの時間”に加え、”PR作成からレビューが開始されるまでの時間”や、”チケット開始からクローズまでの時間”など計測できるものはまだ多くあるので、より多角的にエンジニア組織のパフォーマンスを評価できるようにしていきたいと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















