



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社が提供するマーケティングプラットフォームや運用型広告支援ツールを開発する部門には、サービスやインフラの信頼性を高める活動を行う「SREチーム」があります。 本ブログでは、その「SREチーム」のアクティビティとして、「ポストモーテム」と言われる事後検証を実施した事例を紹介します!
こんにちは。プロダクトビジネス本部の山崎です。
私は、マーケティング・プラットフォームのサービス開発をしている部門でReliability Engineeringを担当しております。”リライアビリティ・エンジニアリング” ?はて、聞いたこと無いぞ!?と感じられたエンジニアの方も多いのではないでしょうか?
DevOpsに興味をお持ちの開発者さんであれば、Google 社が提唱している “SRE” ( Site Reliability Engineering ) という言葉は、ご存じかもしれません。「class SRE implements DevOps」で検索すると、それらしき情報を見つけることができると思います。詳しくは他のサイトにある情報に委ねることにして、ここでは単に「 SRE とは、サービスやインフラの信頼性を支えるための技術 」として話を進めます。
私たちの部門では、Google 社に倣って「商品、会社、社員がこれまでに得てきた信頼を持続するために協働するチーム」として、SRE活動を行うチームができました。私は、そのチームのエンジニアなのですが、自分の立場をどう表現するべきか悩んで、社内でReliability Engineerと名乗るようにしました。
実は社内でも未だ浸透していませんので、もしかするとこのブログ記事が公開されることで、社内で認知されるかもしれません。
私たちは、文字通り “信頼性をエンジニアリング” する役割なのですが、正直なところチームの発足時には、何から始めてよいのか分かりませんでした。Google 社が蓄積したベストプラクティスとして様々な情報がオープンになっています。特に、オライリージャパン社から出版されている、「SRE サイトリライアビリティエンジニアリング ―Googleの信頼性を支えるエンジニアリングチーム 」を教科書に、私たちの信頼性向上の活動に参考になりそうなプラクティスを探しました。その中で見つけたのが「ポストモーテム(Postmortem)」です。
本稿では、SREとしては未熟なチームである私たちが「ポストモーテム」を初めて実施してみた事例をご紹介します。
「ポストモーテム」という言葉をITの文脈ではないところで調べると、死亡後の”検死”という意味だそうです。少し気分が沈みそうなネーミングですが、何か障害(その中でもサービスが停止してしまうなどの深刻な障害)があった際に、事後に検証を行うということです。
一般的に深刻な停止障害は、滅多に起きるものではなく、現場では “検死という言葉のイメージ通りの事象” が起きることはほとんど無いのではないでしょうか。
私たちが提供する「Rtoaster(アールトースター)」 も(過信は禁物ですが)停止に至るような障害はまず起こらないでしょう。
そこで、どのような障害が起こった際にポストモーテムを行うのか、定義を決めるところからスタートすることにしました。
障害検知の課題、顧客アナウンスの体制的な課題、障害対応の自動化の課題など、様々な要因を加味して、どのような障害でポストモーテムを行った方がよいかを決めるべきだと思いますが、私たちは次のような単純な言葉で表すようにしました。
ポストモーテムとなる対象は、次の判定基準に1つでも当てはまる障害とします。 判定基準1)障害の対象が重要顧客である 判定基準2)障害期間が●●時間以上である 判定基準3)障害が顧客からの申告で発覚した
判定基準1については、私たちの提供するサービスをご利用いただいているお客様にもパレートの法則(いわゆる「80:20の法則」)に近しい状況はあり、売上に与えるインパクトが大きいかどうかというのは、ビジネスの上で重要だと考えて、この基準を設けました。また、例えサービスの利用量が多い主要なお客様が含まれていなくても、複数顧客が利用しているサービスに影響があった場合は、この基準のなかでポストモーテムの対象とするようにしています。
判定基準2については、おそらく一般的には、そのサービスに関わるSLAに基づいた基準にするのがよいでしょう。しかし、私たちが提供しているサービスは、お客様から見えるサービスの内部でマイクロサービスとして動作しているコンポーネントがあり、個々の状況に応じて、それぞれ整理して閾値を設定しなければならない状況です。さらには、マイクロサービスの運用期間も異なるため、そのサービスの成熟度も考慮するなど、言葉で表現するのは簡単そうですが、実態は言うほど簡単ではないのが悩ましいところです。具体的な時間は、そういった事情もあって非公開情報なので、伏せてあります。
判定基準3については、アラート監視等の運用の仕組みや体制に課題が潜んでいる可能性があるため設けた基準です。
このように判定基準は決めましたが、私たちの判断も手探りの状況ですので、少し厳しめの運用をしています。社内で発見が少し遅れていたら、お客様からの問い合わせで発覚した可能性もあるというような「ひやり・はっと」の段階でもポストモーテムを開くようにしています。このあたりは、意識の高い熟練の先輩エンジニアの皆さんの助言やリードもあって、ポストモーテムの運用が軌道に乗りつつあります。
次に、この基準に照らし合わせて、ポストモーテムを行うのですが、障害が起きたら、先ずはその障害対応に全力を注ぐべきです。障害対応の真っ只中では、冷静な要因分析ができず、そして障害のあとでは、日々の業務に追われて、 その痛みはすぐに忘れてしまうのが開発業務の常ではないでしょうか。
そこで、障害もない冷静な時期に、敢えて時間を確保して、改善活動にあてようとしたのが、ポストモーテムを実施する意義になります。私たちは、今までの障害対応フローを次のようなフローに変更(従来の障害フローにタスクを追加)して、ポストモーテムを運用することにしました。
(※「Rtoaster」は ISMS にも対応しています。以下は、実際に社内で作ったフローとは異なり、簡略した図です。)
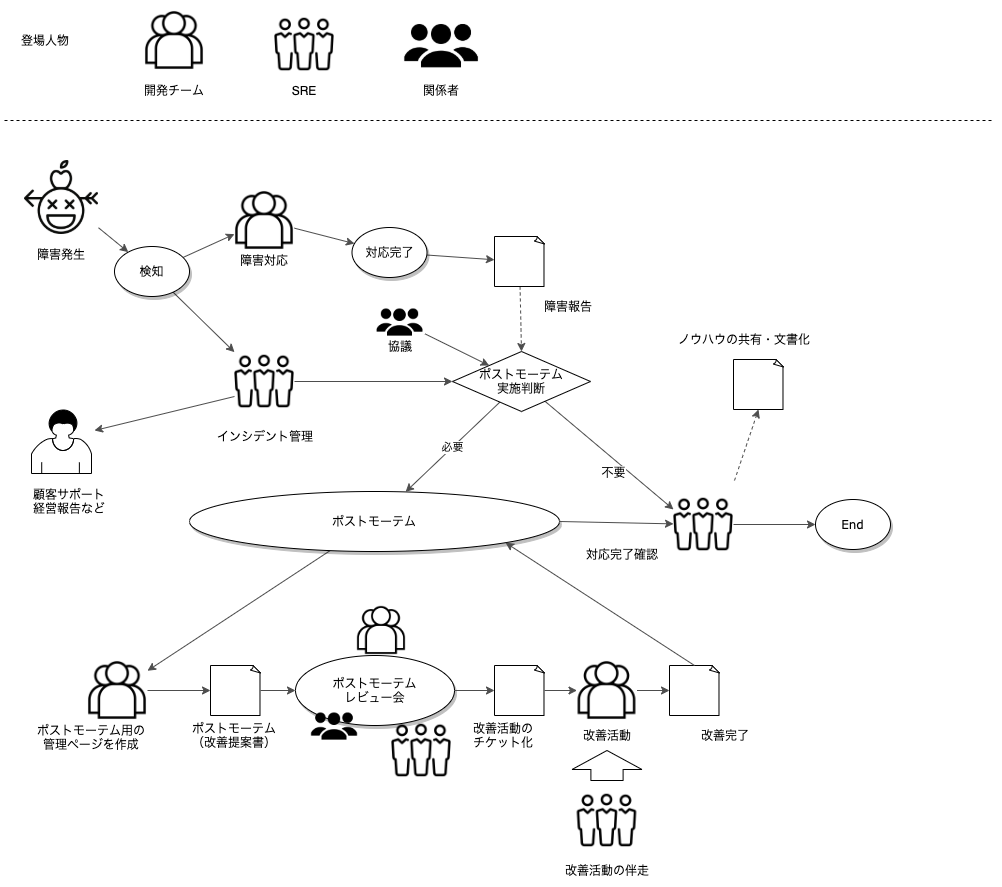
さて、本稿では「初めてポストモーテムを実施してみた」という事例の紹介をしているのですが、それはつまり、それなりの障害があったということを明らかにしている訳です。残念ながら、そのような障害が発生してしまったのは事実です。ただし、あくまで内部的に課題となった事例であって、お客様に多大なご迷惑をおかけしたような事例ではなかったということだけは、先に強調させて頂きます。
具体的にどういった事例だったかということは本稿では重要ではないので、その部分は伏せて、ポストモーテムを実施した際のポイントについて幾つか見てみましょう。
ポストモーテムのテンプレートを準備して、そのテンプレートをコピーしてポストモーテムの診断書を書きます。診断書を書くのは、実際の運用・開発の担当者やそのチームに書いていただきます。
各担当者は、障害を対応しているときは、反省点に気づいていたと思いますが、事後改めて振返ったときに、そのテンプレートに沿って書くことによって、整理ができた内容も多かったと思います。
例えば、テンプレートは根本原因を発見するように促してあり、原因究明のための要因分析において、何が重要な事項なのか、従属的な事項なのかを記述者は整理しなければなりません。さらに、ポストモーテム診断書では、ビジネスインパクトに対する言及も任意で記述する欄もあり、「チーム内だけでなく、広く社内で連携する意識をもてるように」という副次的な効果も考えられています。
ポストモーテム診断書が提出されて、いざレビューする段階になります。
レビュー会では、次のようなメンバーに参加して頂くようにしています。
レビューは対面レビューとしました。対象となる開発チームからはチームリーダーを含めたチームのほぼ全員に参加していただき、 Reliability Engineerはチーム全員が参加します。それなりの人数が参加するレビュー会になるため、30分という時間に制限して開催するようにしています。
SREチームのメンバーは、チームのミッションとして参加する動機付けがあるのですが、部門きっての熟練の開発エンジニアの皆さんは、開発者としての気概や責任感が動機となって参加してくださっています。そのお陰で、レビューでは建設的で的確な意見が寄せられ、改善案を具体化することができました。
私はレビュー会に参加し、熟練の開発エンジニアの意見を聞けたことで、気づかされたことも多く、開発者としての成長の機会でもあると感じました。
今後は、レビュー会参加の動機付けを、エンジニアの品質や障害に対する気持ちを頼りにせず、このポストモーテムが開発エンジニアとしての”冷静な目”を養うための機会ととらえて、熟練の開発エンジニアだけではなく、対象チームメンバー以外の誰でも参加できるような仕組みづくりが課題となりそうです。
ポストモーテムをスタートさせる際に、ある先輩エンジニアが「障害・バグを憎んで、人を憎まずに、失敗から学び再発防止したり製品・チームが成長したりするため」という標語を掲げてくれました。SRE活動では「リスクを受容する」原則からスタートしています。つまり、システムやサービスは完全なものではなく、障害が発生するものであるという前提に立っています。
特にシビアな障害対応の現場では、ともすると個人の責に帰着させようとする雰囲気になってしまうこともあるかもしれません。しかし、障害は発生するべくして発生してしまったものとして考えるべきです。発生してしまった障害は、体制や方法に問題があるものとして、 ポストモーテムでは「冷静に」なって診断を行うために、レビュー会では、最初の数分は、ポストモーテムの意義と先ほどの先輩エンジニアの掲げた標語を説明するようにしております。
レビュー会後は、対象メンバーによる改善提案がされ、レビュー会で出た熟練エンジニアの意見が入った具体的な改善が行われることになりました。次に、具体的に改善活動に入るわけですが、そもそも例外的な措置の考慮が不足していて滅多に起きないケースが起こってしまった事象を改善しようというものです。開発メンバーが関わるような改善作業は、ともすると優先順位が低くなりがちです。SREチームとしても、ビジネススピードとのトレードオフを言われてしまうと、優先順位を高くすることを強いるのが難しい状況もでてきます。そこで、すべてのポストモーテムに一律の改善期限を設けるのではなく、再発するリスクを考えて、開発メンバーと協議する必要があります。そして、改善を完遂できるのはあくまで開発チームであり、SREチームはその伴走者として支援していくことが大切です。普段の開発作業に追われている開発チームが途中で改善を投げ出してしまわないように、SREチームでも開発チームとは別チケットでタスクの管理をするようにしました。
ポストモーテムで明らかになった課題は、このようなフローを通じて改善されていきます。
改善提案のなかには、個別の事象には留まらないで、全てのマイクロサービスで共通的に活かせそうな提案もありました。例えば、クラウドサービスの使い方でハマったとか、こう使えば回避できたとか、実は調査の際に問い合わせたから知り得た情報などさまざまです。そのような情報には、障害が起こったからこそ気づけたり、詳細に分かったりしたことも幾つかありました。それらは、次の問題を未然に防ぐために、開発部門全体で共有するべきノウハウでした。そこで、SREチームが担当してノウハウとして情報共有を図るようにしております。
ポストモーテムを実施した際のポイントをまとめておきます。
ポストモーテム実施のポイント(まとめ) – 改善提案書としての「ポストモーテム診断書」を書く – レビュー会の参加メンバーは多角的な視野で見られるようなメンバーを選抜する – 個人攻撃にはならないように注意する – SREチームは改善活動の伴走者であるという意識をもって改善に関わる – ポストモーテムで得た知識の情報共有を進める
ポストモーテムを実施してみると、同じ事象がおきるリスクが減らせたという直接的な効果ばかりではないと感じました。情報共有だったり、熟練の開発エンジニアの品質に対する見方や障害復旧の自動化に関する考え方などが学べる機会にもなっています。実際、DevOpsに意識の高い開発者の方ほど、ポストモーテムを積極的にとらえている傾向にあるように感じました。
件の教科書では「ポストモーテムの文化」という章の名称がついています。ポストモーテムを始めてみて、”文化”と表現されている意図が少しだけ感じ取れた気がしています。教科書を読んでいるだけではなく、実践することで、SREチームの役割が見えてきたと思います。
ブレインパッドでは、広告に関わる大量のアクセスを処理しているフロントエンドサービスやそのデータをルールベースや機械学習で処理するバックエンドサービス、そしてウェブ広告配信、メール配信、スマートフォンへのPUSH配信など様々な配信のサービスを開発、運用しております。
本稿でご紹介したとおり、私たちSREチームは、未熟ながら日々の課題に取り組んで、組織としても成長しようとしています。
当社では、開発エンジニアやデータサイエンティストを積極的に募集しています。サービス開発やそのサービス運用を支えて頂ける方、新卒採用・キャリア採用ともにご応募をお待ちしています!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













