



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
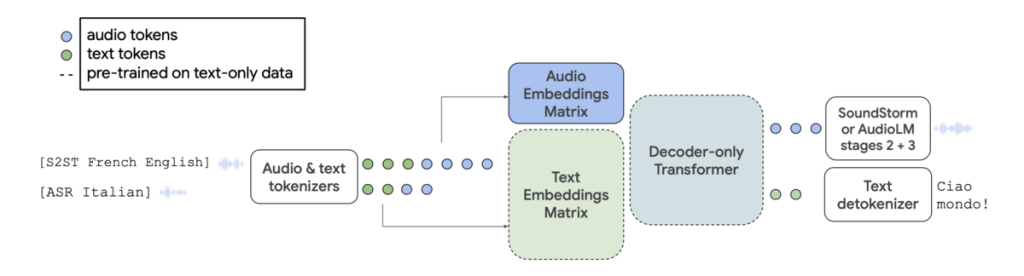
AudioPaLMの機能
AudioPaLMの特徴
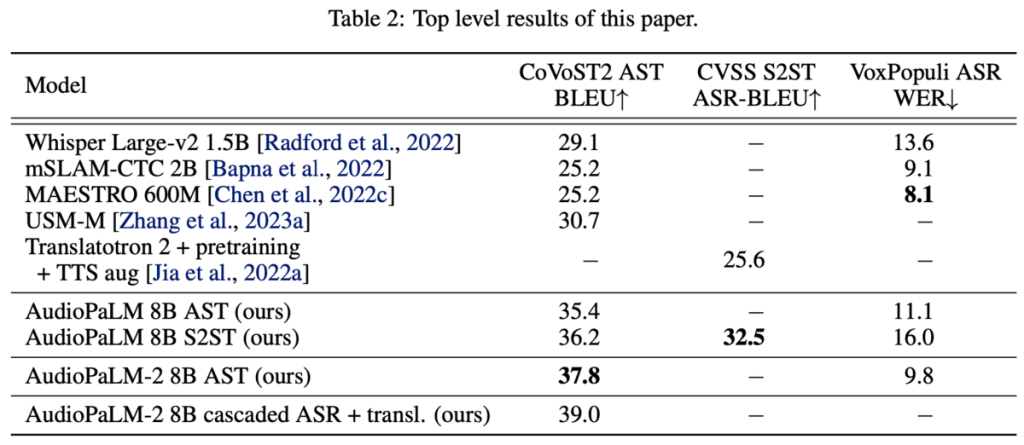
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
4つ目の論文は音声に関する論文です。
選出した論文はGoogleが6月に発表した、テキストと音声の両方に対応可能な大規模な音声理解・生成モデルであるAudioPaLMについての論文です。
音声翻訳のベンチマークではOpneAIのWhisperを上回っており、今後の音声翻訳ツールのデファクトスタンダードにもなり得るモデルであるため、選出いたしました。
AudioPaLMの機能
AudioPaLMの特徴
既存手法との比較
下表の通り、音声翻訳(AST)・音声認識(ASR)において既存手法を大きく上まっていることがわかります。
論文で言及されている課題は以下の通りです。
Q: GoogleからAPIで提供されてるのか?
Q: 日本語には対応しているか?
| タイトル | 概要 |
|---|---|
| PaLM 2 Technical Report | GoogleのテキストベースのLLMであるPaLM2についての論文 |
| PaLM: Scaling Language Modeling with Pathways | GPaLM2の元となるPaLMについての論文 |
| AudioLM: a Language Modeling Approach to Audio Generation | Googleの音声ベースのLLMであるAudioLMについての論文 |
| Robust Speech Recognition via Large-Scale Weak Supervision | OpenAIの音声処理モデルであるWhisperについての論文 |
今回は、生成AI・基盤モデルのマルチモーダリティに関する技術論文を4つご紹介させていただきました。
今後も、社内で実施しているレビュー会での発表内容をブログで発信させていただくつもりですので、ご期待ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













