



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

自社開発プロダクト「Rtoaster」をはじめとする製品群を扱うプロダクトビジネス本部の社員によるエンジニアブログです。今回は、「Rtoaster」のデータ基盤チームが社内向けのレポート改善のために、Lookerを導入したお話をご紹介します!
弊社が提供しているプロダクト・サービス「Rtoaster(アールトースター)」では、導入企業様のWebサイトの顧客体験向上のために行動データを蓄積して自動最適化などに役立てていただいております。蓄積されたデータをお客様のサイトパフォーマンスやレコメンド実績の確認、エンドユーザの理解促進にご利用いただけます。ご依頼があれば、弊社の経験豊かなスタッフが「Rtoaster action+(アクション・プラス)」の活用支援の一環で蓄積されたデータの集計可視化や分析結果の報告をさせていただいております。
この度、筆者が所属しているデータ基盤チーム(Rtoasterのログ・マスタデータを管理する開発チーム 過去の投稿はこちら)では、Rtoaster action+(以下action+)のデータ活用の支援で用いられるレポートを改善する取り組みを行っておりました。本投稿ではその経緯やレポート再開発で得た知見などについてご紹介したいと思います。
本投稿は以下の話題を含んでいます。
そのためデータや指標管理に関わる仕事を行っている方や、業務効率向上のためのBIツール導入を検討中の方に興味を持ってもらえる内容となっているので、最後まで読んでいただければと思います。
弊社で行っている業務の一つとして「action+の運用支援」があります。
action+を導入いただいた場合、運用担当者様は基本的にaction+を運用したご経験がない状態でaction+運用をしていただくことになるため、運用ノウハウが無かったり、action+の機能について把握できていない状態となります。そのため導入初期の段階では運用担当者様にaction+を使いこなしていただけますように、弊社のスタッフ「カスタマーサクセス(以下CS)」が運用支援を行っております。
運用支援の際に運用担当者様とCSで、Webサイトの訪問状況やaction+で設定したレコメンド施策のパフォーマンスなど(レコメンドを表示した回数・WebサイトでCVした回数など)を確認するレポートがあり、レポートで確認し合います。これを社内では「オンボーディングレポート」と呼んでいます。このオンボーディングレポートに対して、レポート開発関係者内で改善の要望があったため、この度データ基盤チームでレポートの再開発を行いました。
レポート改善の要望としては以下の議題が挙がっていました。
これらの問題が発生していた理由としては、データ分析やシステム開発を行う職種の人間がレポート開発に積極的に関わることができておらず、CSにデータ活用の役割を任せてしまっていたことが原因でした。この原因により、特定のグループや職種だけで決められた指標定義が作成されたり、本来の業務範囲を超えた不得意な課題(ビジネス側の人間がシステム仕様を踏まえたSQLを実装するなど)に取り組まざるをえない状態になっていました。
開発・運用体制の見直し
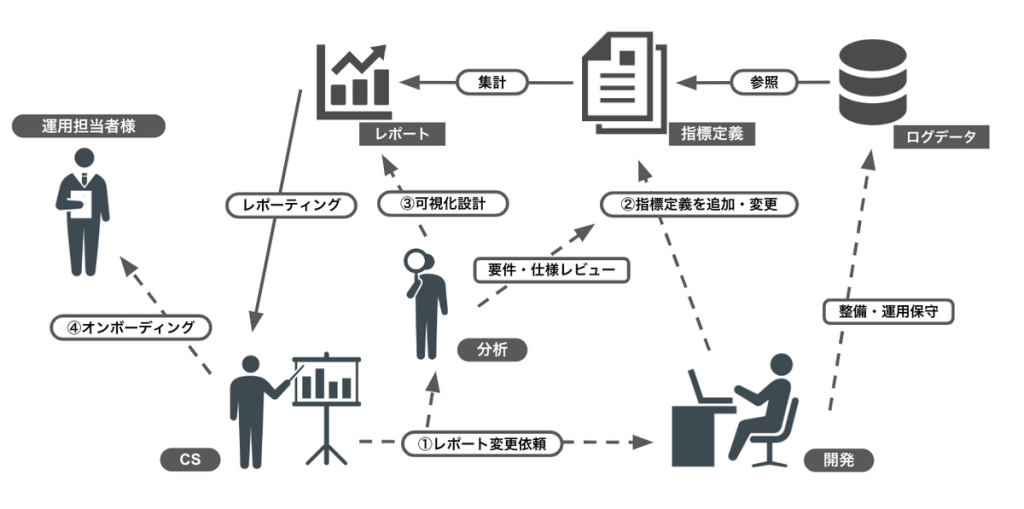
今回の問題を解決できるように「CSに任せきりではなくデータ分析者・システム開発者も関わるデータ活用」を目標として、レポート再開発時の関係性や今後想定している運用の流れを三者で協議しました。
協議の結果、それぞれの立場・役割を明確にして、それぞれがやるべきことに専念できる体制として
という関係性を決めて、レポート再定義や指標再定義を行いました。
用語集の作成
指標定義や集計仕様を決めていく段階で、「PV数とは実際には何を数えているものですか?」、「CVの定義が自分の想定と違う」といった指摘があり、人や職種によって認識にズレがあることに気がつきました。
そのためはじめに、三者のデータ認識を合わせるための用語集の作成をしていきました。
(このビジネス側とシステム開発者との認識がずれているという問題は、古今東西どこの組織においても存在する問題でありさまざまな分野で解決方法が提案されています。例えばドメイン駆動設計という開発フレームワークではビジネス側とシステム開発側の認識を合わせるためにドメインモデルやユビキタス言語を用いたり、データマネジメントにおいては組織内のデータ管理を統制してデータ認識の齟齬が生まれない仕組みを作るデータガバナンスという概念があります。今回の取り組みではこれらの手法を参考に用語集を定義していきました。)
単に用語集を作成する場合では「定義と用語」を1対1で紐づけて認識がズレないように明記すれば良いのですが、今回のケースではCS・データ分析者・システム開発者といった立場が異なる人が関わるため、必要な知識が職種によって異なってきます。(指標設計を行うシステム開発者は細かいシステム仕様を網羅していなければ正しいSQL処理が実装できませんが、レポートを利用する運用担当者様やCSは集計が指し示す内容が把握できていれば最低限のレコメンド施策の評価はできます。)
定義を厳密にしすぎて細かいシステム仕様までも用語集に書き込んでしまうと、CSが定義を理解しきれずにレポート作成に関わりにくくなり当初に考えた運用体制が構築できなくなることにもつながります。
そのため今回の用語集では以下のような知識レベルに切り分けて、自分はどのレベルまでを把握しておけば良いのかを判断できるようにしました。
Lookerでレポート実装
三者での認識が揃い用語定義や集計方法が固まってきたので、それぞれの指標やレポートをLookerというサービスを利用して実装しました。
Lookerを採用した理由としてはLookerはデータガバナンスを保つためのサービスで、組織内のデータや指標を管理する仕組みが用意されているためです。(さらにLookerではデータ・指標管理だけでなく可視化機能もあるため、BIツールとしてオンボーディングレポートの構築や運用が楽になることも決め手となりました。)
Lookerでは以下の図のように、指標Aの定義が組織内で曖昧にならないようにLookerで定義した指標を利用するようになるので一定のデータ品質を保ちつつ利用規模を大きくすることができます。またLookerのメリットは品質面だけでなく各役割の人間にも恩恵があり
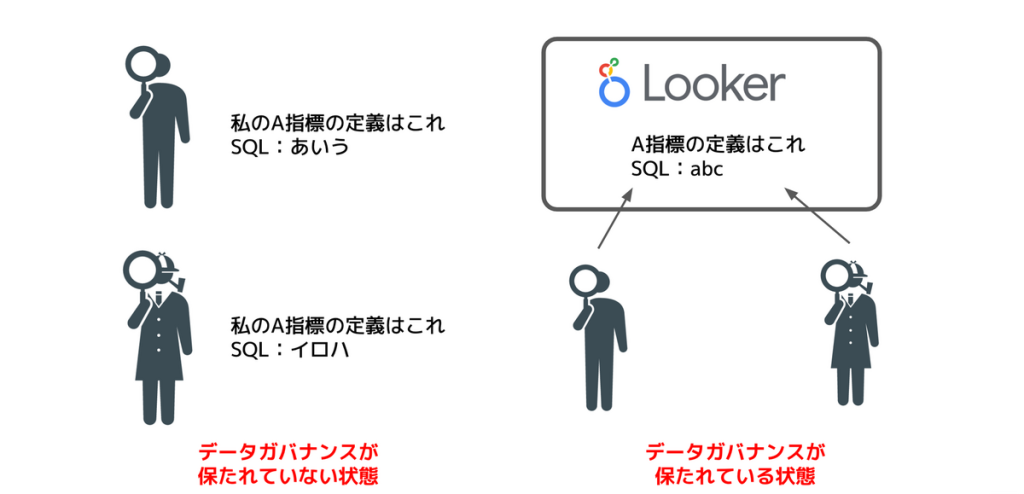
Looker導入により、これまでのようにCSがSQL実装作業やレポート出力作業を行うことがなくなり、レポート改善の要望がデータ分析やシステム開発に届くようになりました。
作成したレポートは現在社内展開中で、新定義のレポートの説明をCSに向けて行っている最中です。運用していく中で要望や改善点などが挙がってくると思うので、上記の運用体制で改善・改変に取り組んでいきたいと思います。
また今後の展開としては、オンボーディングレポートだけでなく社内の他レポートとの指標共通化や、Rtoasterプロダクトの集計定義との共通化も行って、導入企業様の運用がより簡単により効果的になるように改善を行っていきたいと思います。

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













