

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
この記事では、生成AIの中でも、テキスト、画像、動画、3Dデータ、オーディオデータ、モーションなど多岐にわたるマルチモーダル系のタスクについて、全2回の連載でご紹介します。【第1回目の記事はこちら。】
こんにちは、アナリティクスサービス部の八登です。
昨今話題をさらっている生成AIですが、その中でマルチモーダル系のタスクに大きな関心が集まっています。
ここでマルチモーダル系とは、AIが同時に複数の形式を扱うことができる、ということを表しています。
モーダルの例としては、テキスト、画像、動画、3Dデータ、モーションなど多岐にわたります。
先日の記事*1では、生成AIのマルチモーダル系タスクについて、AIのインプット/アウトプットに着目することで、全体像を概観することから始めました。今回の記事では、ひとつのタスクについて深掘りして検証することで、マルチモーダルな生成AIモデルの使い方について、より深いイメージを持っていただくことを目標としています。本記事の題材としては、画像生成のファインチューニングを扱います。では、早速始めていきましょう。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
本記事の画像生成の検証には、前回の記事でも使用したStable Diffusion version 2 *2を用います。
このモデルを検証に用いる根拠は以下のとおりです。
なお、本記事ではStable Diffusionと他の画像生成モデルとの比較は行いません。あくまでStable Diffusionを深掘りした検証を実施します。理由としては以下のようなことが挙げられます。
Stable Diffusionは下図のようなアーキテクチャとなっています。なお、Stable Diffusionのアーキテクチャの詳細についてはすでに多くの解説記事*3, *4が公開されていますので、ここではその概要をお伝えするに留めたいと思います。
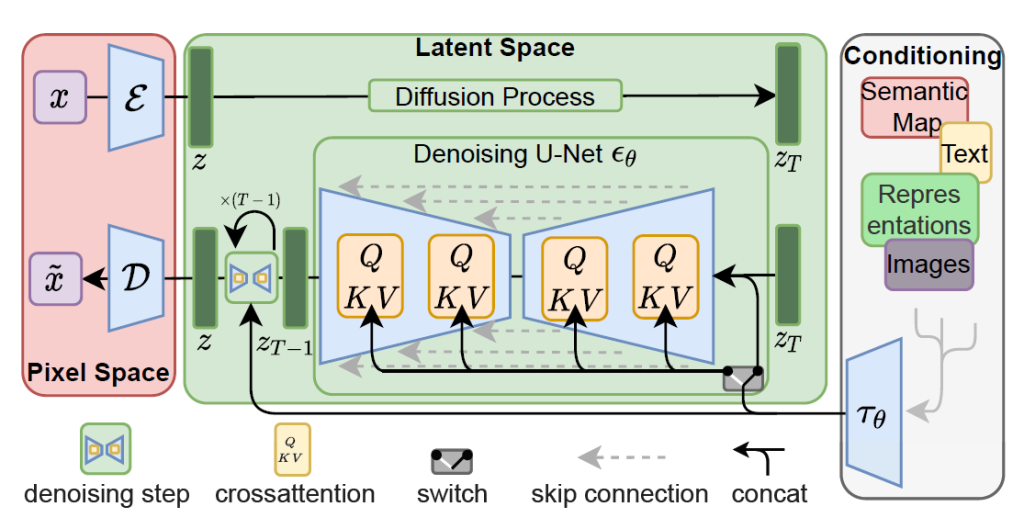
アーキテクチャの各部分は以下の役割を担います。
のちほど解説するファインチューニングでは、基本的には逆拡散過程であるU-Netのパラメータをファインチューニングすることになります。
生成AIの学習済みモデルにおいて、それがどのようなデータセットで学習されたものかを知ることは重要です。
Stable Diffusionのoriginal model(本記事ではHuggingFaceの”stabilityai/stable-diffusion-2-1″を使用*6)は、LAION-5B *7というデータセットを用いて学習されています。LAION-5Bは50億枚以上の画像とテキストのペアで構成されるデータセットです。23億組程度の画像と英語テキストのペア(laion2B-en)や、22億組程度の画像と非英語テキストのペア(laion2B-multi)などで構成されています。
事前学習において、ConditioningのCLIPモデル(上のoriginal modelではOpenCLIP-ViT/Hを使用)のパラメータは固定され、Pixel SpaceやLatent Spaceのパラメータのみが学習の対象となります。なお、OpenCLIP-ViT/Hの事前学習の際にも、LAION-5Bのサブセットであるlaion2B-enが用いられています。
Stable Diffusionは広く使われている画像生成モデルであり、多くの人がプロンプトの入力方法について研究したり、記事を執筆したりしています*8, *9。プロンプトエンジニアリングの詳細はこういったサイトをご確認いただくとして、ここではその概要のみお伝えします。
Stable Diffusionのプロンプトについては、開発元のStability AI社が公式のガイドライン*10を出しています。この公式ガイドラインによると、プロンプトの基本は以下の要素を指定することとされています。
なお、上の要素に関する記述はカンマ区切りで並べる形で通常指定されます。
Stable Diffusionではプロンプトを文章で書くメリットはあまりないとされています。
なお、DreamStudio*11やStable Diffusion web UI*12のようなUIでStable Diffusionを動かすことができるツールの中には、ネガティブプロンプト(除外したい要素の指定)や要素ごとの重みなどを細かく調整する機能を備えているものもあります。
上でStable Diffusion version 2のプロンプトエンジニアリングについて紹介しましたが、プロンプトについては英語で入力することが前提となっていました。ここで、プロンプトに日本語では使えないのか、という疑問がわいてくる方もいらっしゃると思います。
上記のStable Diffusionのoriginal modelは、CLIPモデルの学習が英語のデータセットのみで行われているため、基本的に日本語を扱えるようにはなっていません。
しかし、Stable Diffusionを拡張することで日本語を使えるようにした、Japanese Stable Diffusion *13 というモデルがrinna社*14より公開されています。このモデルは、Stable Diffusion v1.5の事前学習済みモデルを、1億枚程度の日本語のキャプションと画像のペア(LAION-5B内のデータ含む)を用いてファインチューニングしたモデルとなります。
より詳細には、このモデルは以下の2つのステップで学習が行われています。
これにより、日本語のプロンプトを入力可能になるだけでなく、日本語とペアになった日本風の画像を大量に学習することで、日本特有の対象物や画風を生成できるようになります。
ここまではStable Diffusionの基本的なトピックについていくつか紹介してきました。ここからは、本題のStable Diffusionモデルのファインチューニング手法について詳細に紹介していきます。
上記のように、Stable Diffusionはプロンプトエンジニアリングにより非常に多様な出力を行うことが可能なモデルとなっていますが、自分が出力したいテイストの画像を安定して出力することは容易ではありません。
たとえば、以下のようなテイストのピクセルアート調のイラストを生成したいとしましょう。なお、このデータは、あるピクセルアート調のデータだけを集めたデータセット*15に含まれているものです。

ピクセルアート調なので、まずはプロンプトに“pixelart”と指定することが思いつきます。上の画像と同じ対象物に対して、”pixelart”を含むプロンプトを用いて生成したされた画像の例が以下です(正確なプロンプトは“moai on easter island in the style of pixelart”です)。

たしかにピクセルアートの要素は入っていますが、本来生成したかったテイストにはなっていません。細かくプロンプトを調整していけば狙った絵に近いものが得られる可能性はありますが、その試行錯誤にはかなりの時間を要することが想像できます。
このようなときに役立つのがファインチューニングです。ある共通の性質を持った画像とテキストの組のデータを用いてファインチューニングを行うことで、そのデータの性質がモデルに学習されて、そのモデルを用いて同様の性質を持った画像を安定して生成することが可能となります。
Stable Diffusionにはファインチューニング手法がいくつか存在します。スクリプトなどを用いて比較的平易に実行できる手法として、以下のようなものがあります。
これらの手法について、アーキテクチャや実装方法、生成結果の違いを検証していきましょう。
前述のStable Diffusionのアーキテクチャのうち、逆拡散プロセスに相当するU-Netのパラメータをファインチューニングする方法です。単にStable Diffusionのファインチューニングと言った場合は通常この方法を指します。ここでは、この方法をFull FTと表記することにします。
LoRAの基本的なアイデアは、Platinum blogのPEFTに関する記事*16でも紹介しています。再掲になりますが、以下にLoRAの概要をあらためて記載します。
LoRA(Low-Rank Adaptation) *17とは、事前学習済みモデルのAttention層のクエリとバリューに対して、低ランク行列を適用することで、パラメータ数を大幅に削減しながら、元のモデルと同等かそれ以上の性能を達成する手法です。
具体的には、下図のように事前学習済みモデルのパラメータを凍結した上で、クエリとバリューの行列に対して低ランク行列を掛け合わせて新たな行列を作ります。この低ランク行列は、ファインチューニング時に学習される唯一のパラメータとなります。

この手法には以下のような利点があります。
実際、HuggingFaceやその他のサイトで、多くのStable DiffusionのLoRAモデルが公開されています*18。これらの場所からLoRAモデルをダウンロードし、手元で使っているツールに導入するだけで、スタイルを受け継いだ新たな画像を簡単に生成することができます。
上のふたつの手法では、プロンプトに用いられる既存の単語群に対して新たな学習を行うため、同じプロンプトを用いてoriginal modelと同様のスタイルを生成することは難しい手法となっています。
一方、ここで紹介するDreamBooth*19と次に紹介するTextual Inversionは、新たに生成したいスタイルに別のプロンプトを割り当てることで、モデルがもともと持っていたスタイルを保持したまま、新たなスタイルを獲得することができるファインチューニング手法となっています。
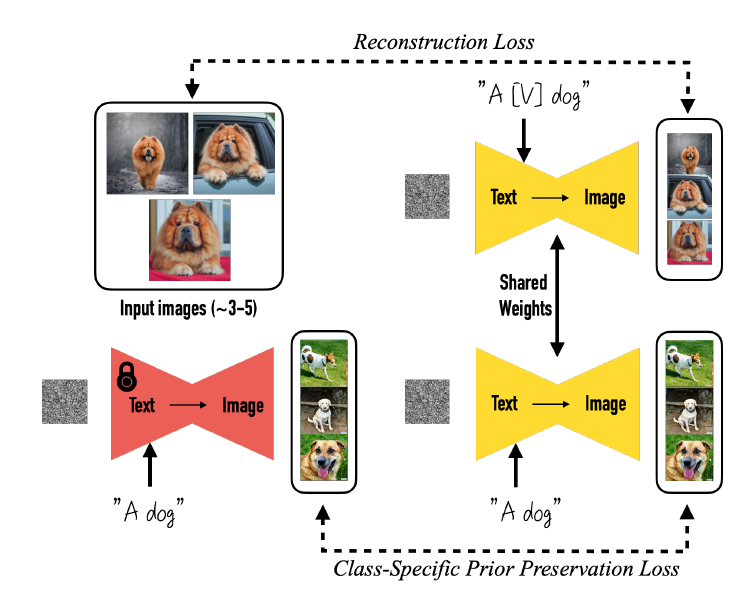
以下はDreamBoothの仕組みを解説した概念図になります。DreamBoothでは、ファインチューニングの対象とするクラス(下図では”dog”)と対になる、一意の識別子(下図では”[V]”)を用意します。そして、識別子を含む新たなプロンプト”A [V] dog”を用いた場合に、新たに学習したいスタイルの画像が生成されるようにファインチューニングを実施します。この際、元のプロンプト”A dog”からはoriginal modelと同様のスタイルの画像が生成されるようにするため、prior preservation lossと呼ばれるLoss関数を追加して同時に最小化させることで、このようなスタイルの保持を担保する、という仕組みとなっています。
このモデルの特徴は、非常に少ない枚数の画像(論文によると3~5枚)から新たな特徴を学習できる点にあります。
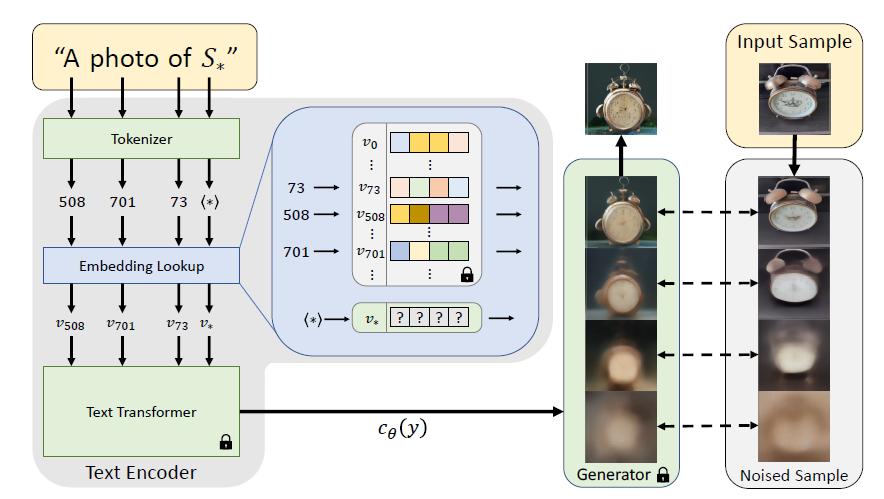
Textual Inversion *20もDreamBoothと目的は類似する手法となっていますが、その構造は大きく異なります。Textual Inversionは新たな単語の埋め込みベクトルを学習する手法です。
Textual Inversionの仕組みを説明した概念図が下図になります。下図での”S*”が新たな単語に相当します。この新たな単語を含む文(下図では”A photo of S*”)をテキストエンコーダにより埋め込みベクトルに変換します。ただし、新たな単語は事前学習済みモデルでは解釈できないため、別の単語に対応する埋め込みベクトルで初期化しておきます。
一方で、ファインチューニングに用いる画像にノイズをかけたサンプルを作成しておきます。そして、上で生成された埋め込みベクトルを条件付けに用いた場合に、ノイズをかけたサンプルから元の画像が生成されるように、新しい単語に対応する埋め込みベクトルを学習していきます。これにより、この新しい単語を用いた場合に、元のサンプル画像の性質を持った画像を生成するようにモデルが学習されることになります。
DreamBoothと同様に、Textual Inversionも数枚の画像から新たな特徴を学習できると考えられています。
ファインチューニングには、HuggingFaceのDiffusers*21というライブラリを用います。Diffusersは、事前学習済みモデルを用いた推論や既存モデルのファインチューニングを平易に実行できるライブラリです。Diffusersの公式GitHub*22には、本記事で紹介しているファインチューニング手法のためのサンプルコードやスクリプトがそのまま公開されているので、こちらを使用していきましょう。なお、ファインチューニング実行のための環境準備の方法は記事の末尾に記載していますのでご参考ください。
各ファインチューニング手法を実行するためのスクリプトは、上記のdiffusersのリポジトリの中のそれぞれ以下のフォルダに存在します。
以下では、それぞれの手法の学習・推論の実行方法について説明します。
Full FTのファインチューニングのためのコマンド実行方法は以下になります。主要なオプションの意味を合わせて記載しています。
# ファインチューニング対象の事前学習済みモデルモデルを指定
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
# ファインチューニングに用いるデータセットを指定
export dataset_name="jainr3/diffusiondb-pixelart"
accelerate launch --mixed_precision="fp16" train_text_to_image.py
--pretrained_model_name_or_path=$MODEL_NAME # 上で指定した事前学習済みモデル
--dataset_name=$dataset_name # 上で指定したデータセット
--use_ema
--resolution=768 --center_crop --random_flip # Stable Diffusion v2では解像度を"768"に変更
--train_batch_size=1 # 学習のミニバッチサイズ
--gradient_accumulation_steps=1
--max_train_steps=1000 # 学習ステップ数
--learning_rate=1e-5 # 学習率の初期値
--lr_scheduler="constant"
--lr_warmup_steps=0
--output_dir="pixelart-model" # モデルを出力するフォルダを指定Full FTで学習したモデルを用いた推論の実行方法は以下になります。
import torch
from diffusers import StableDiffusionPipeline
model_path = "pixelart-model-3000"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="moai on easter island in the style of pixelart").images[0]LoRAのファインチューニングのためのコマンド実行方法は以下になります。
なお、LoRAのスクリプトでは、ステップ数ではなくエポック数を指定します。今回学習に用いるデータセットのサンプル数が1000のため、ステップ数はエポック数×1000となります。
# ファインチューニング対象の事前学習済みモデルモデルを指定
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
# ファインチューニングに用いるデータセットを指定
export dataset_name="jainr3/diffusiondb-pixelart"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py
--pretrained_model_name_or_path=$MODEL_NAME
--dataset_name=$dataset_name
--resolution=768 --center_crop --random_flip
--train_batch_size=1
--num_train_epochs=10 # LoRAではステップ数ではなくエポック数を指定
--checkpointing_steps=5000 # checkpointの出力ステップ間隔を指定
--learning_rate=1e-4
--lr_scheduler="constant"
--lr_warmup_steps=0
--seed=42
--validation_prompt="cute dragon creature"
--output_dir="pixelart-model-lora"LoRAによりファインチューニングしたモデルを用いた推論の実行方法は以下になります。
import torch
from diffusers import StableDiffusionPipeline
model_path = "pixelart-model-lora-10"
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe(prompt="moai on easter island in the style of pixelart").images[0]DreamBoothのファインチューニングのためのコマンド実行方法は以下になります。
なおDreamBoothでは、上のアーキテクチャ説明で述べたように、prior preservation lossを用いて元のプロンプトから元のスタイルの画像を生成するように学習を行いますが、この機能をオフにすることも可能です。
また、prior preservation lossを考慮する場合、元のクラスの生成画像が必要ですが(デフォルトでは100枚必要)、この画像がない場合は自動で必要な枚数の画像を出力してくれます。
なお、INSTANCE_DIRのフォルダには、今回対象のピクセルアート調のデータセットから、5枚の画像のみを取り出して配置しています。
# ファインチューニング対象の事前学習済みモデルモデルを指定
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
# ファインチューニングに用いるデータを格納したフォルダを指定
export INSTANCE_DIR="pixelart_images"
# 元のクラスの生成画像を格納するフォルダを指定
export CLASS_DIR="class_images"
# DreamBooth
accelerate launch train_dreambooth.py
--pretrained_model_name_or_path=$MODEL_NAME
--instance_data_dir=$INSTANCE_DIR
--class_data_dir=$CLASS_DIR
--with_prior_preservation --prior_loss_weight=1.0 # prior preservation lossを用いない場合は削除
--instance_prompt="an image in the style of sks pixelart" # sksがアーキテクチャ説明の識別子に対応
--class_prompt="an image in the style of pixelart" # 元のスタイルで画像を生成するためのプロンプト
--resolution=768
--train_batch_size=1
--gradient_accumulation_steps=1
--max_train_steps=400
--learning_rate=5e-6
--lr_scheduler="constant"
--lr_warmup_steps=0
--output_dir="pixelart-model-dreambooth"DreamBoothによりファインチューニングしたモデルを用いた推論の実行方法は以下になります。
import torch
from diffusers import StableDiffusionPipeline
model_id = "pixelart-model-400"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
image = pipe(prompt="moai on easter island in the style of sks pixelart").images[0]Textual Inversionのファインチューニングのためのコマンド実行方法は以下になります。
Textual Inversionで特徴的なのは、placeholder_tokenで新しいスタイルを識別するための新しい単語を指定することと、学習時の上の新しい単語に対する埋め込みベクトルの初期値をinitializer_tokenで与えることです。つまり、placeholder_tokenの単語に対して、initializer_tokenのスタイルをファインチューニングに用いる画像のスタイルに変化させるように学習を行うということになります。
なお、DATA_DIRのフォルダには、DreamBoothと同様に、今回対象のデータセットから5枚の画像のみを取り出し配置しています。
# ファインチューニング対象の事前学習済みモデルモデルを指定
export MODEL_NAME="stabilityai/stable-diffusion-2-1"
# ファインチューニングに用いるデータの格納フォルダを指定
export DATA_DIR="./pixelart_images"
accelerate launch textual_inversion.py
--pretrained_model_name_or_path=$MODEL_NAME
--train_data_dir=$DATA_DIR
--learnable_property="style" # 画風の学習の場合は"style"、対象物の学習の場合は"object"を指定
--placeholder_token="<diffdbart>" # 新しいスタイル用の新しい単語を指定
--initializer_token="art" # 新しい単語の埋め込みベクトル学習の初期値を与える単語を指定
--resolution=768
--train_batch_size=1
--gradient_accumulation_steps=1
--max_train_steps=10000
--learning_rate=5.0e-04
--scale_lr
--lr_scheduler="constant"
--lr_warmup_steps=0
--output_dir="textual_inversion_pixelart"Textual Inversionによりファインチューニングしたモデルを用いた推論の実行方法は以下になります。
import torch
from diffusers import StableDiffusionPipeline
model_id = "stabilityai/stable-diffusion-2-1"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
pipe.load_textual_inversion("textual_inversion_pixelart_3000")
image = pipe(prompt="moai on easter island in the style of <diffdbart>").images[0]それでは、各手法の生成結果にどのような違いが出るか見ていきましょう。
ファインチューニングの目標は、モデルの生成画像のスタイルをどれだけ学習データのスタイルに近づけられるかという点でしたので、その観点で見ていきます。
Full FTでの生成結果は以下になります。それぞれ100step, 1000step, 3000stepの学習を行った結果となっています。なお、ここで評価したいのはあくまでスタイルであり、対象物の造形としての品質は問題にしないこととします。プロンプトはすべて“moai on easter island in the style of pixelart”を用いています。
この結果が示すように、ファインチューニングのステップ数を増やすほど、学習に用いたデータセットのスタイルに徐々に近づいている様子が見て取れます。

LoRAでの生成結果は以下になります。1epochと10epochの学習を行った結果になりますが、データセットの訓練データのサンプル数は1000のため、ステップ数で数えた場合、それぞれ1000step, 10000stepに相当します。プロンプトは、Full FTと同様に“moai on easter island in the style of pixelart”を用いています。
U-Netのファインチューニングと同様に、学習によりデータセットのスタイルを正しく捉えられていると判断できます。LoRAは低ランク行列に対する学習を行いますが、それでも十分な学習ができていると考えてよいでしょう。

DreamBoothの生成結果は以下になります。なお、こちらはprior preservation lossを考慮した結果になります。プロンプトは、新しいスタイルのための識別子を含む“moai on easter island in the style of sks pixelart”を用います。この“sks”が、”pixelart”というクラスと対になる固有の識別子に相当します。”sks”を付けた場合は新しいスタイルの画像が、付けない場合は従来のスタイルの画像が生成されるように学習しているということになります。
以下のとおり、たしかに少しずつ狙ったスタイルを獲得しているようにも見えますが、完全にデータセットの画像の特徴というよりは、ややoriginal modelのスタイルとの中間的な結果にも見えます。これは、prior preservation lossを考慮することで元のスタイルも保持しようとした結果の表れと読み取ることもできそうです。そこで、次はprior preservation lossを考慮しない場合にどのような生成結果が得られるのかを見てみましょう。

DreamBoothのprior preservation lossを考慮しない場合の結果が以下のとおりです。見てのとおり、高々400step程度の学習でも、prior preservation lossありに比べてかなりスタイルをデータセットに近づけることができています。

新しいスタイルは獲得できましたが、prior preservation lossを考慮していないため、識別子を含まない元のプロンプト“moai on easter island in the style of pixelart”の出力のスタイルも合わせて変化しているのではないかということが危惧されます。そこで、この元のプロンプトを用いて、prior preservation lossを考慮した場合としない場合で結果がどう異なるかを確認してみましょう。
下の結果のように、prior preservation lossを考慮しない場合は元のプロンプトを用いた場合もスタイルが変化してしまっていますが、考慮した場合はその変化は抑えられて、よりoriginal modelに近いスタイルで生成されていると言えそうです。このように、仕組みどおりの生成結果が得られることが確認できました。

最後に、Textual Inversionの生成結果が以下になります。Textual Inversionでは新たな単語に対してスタイルを学習させることを目指しますが、ここではその単語は“<diffdbart>”としています。そのため、指定するプロンプトは“moai on easter island in the style of <diffdbart>”になります。
20000stepとかなりのサイクル数の学習を行うことにより、徐々にピクセルアート調の画風に変化していますが、完全に学習データと同様のスタイルを獲得するには至っていません。この要因としては、Textual Inversionがあくまで単語に対する埋め込みベクトルを学習する仕組みとなっており、画像生成プロセス(逆拡散プロセス)のパラメータ自体は学習で変化させていない、という点が関係しているかもしれません。
なお、10stepの結果が、ほとんどピクセルアート調になっていないこともこの手法の重要なポイントです。これは、今回対象の単語“<diffdbart>”の埋め込みベクトルの初期値に、ピクセルアートの要素を含まない“art”に対応する埋め込みベクトルを用いているためです。このように、埋め込みベクトルのみの学習を通して、ここまで新たなスタイルを獲得できるのは十分な結果と言えるかもしれません。

ここまで各ファインチューニング手法の生成結果について説明してきました。ここでは、それぞれの手法のVRAM消費量、学習・推論時間、モデルサイズといったスペックについて測定結果を記載していきます。
まず、各手法の学習・推論時のVRAM消費量は以下のようになっています。なお、学習・推論時のGPUはいずれもNVIDIA A100を用いています。また、DreamBoothはprior preservation lossを考慮した場合の結果です。下表から、LoRAの学習ではFull FTより若干VRAM消費量が抑えられていること、Textual Inversionによる学習時のVRAM消費量が小さいことが読み取れます。なお、最終的に推論に用いられるモデルは同等のものとなるため、推論時に消費されるVRAM量も手法によって違いはありません。
| 手法 | 学習時のVRAM消費量 | 推論時のVRAM消費量 |
|---|---|---|
| U-Net(Full FT) | 31GB | 6.3GB |
| LoRA | 25.7GB | 6.3GB |
| DreamBooth | 28.8GB | 6.3GB |
| Textual Inversion | 11GB | 6.4GB |
次に、各手法のファインチューニング時の学習時間、学習後のモデルを用いた推論時間は以下のようになりました。なお、こちらもすべてNVIDIA A100で計測した結果となっています。この結果を見ると、LoRAが他の手法と比べて1stepあたりの学習時間が短くなっていることが分かります。VRAM消費量と同様に、推論時間についてはどのモデルも違いは出ないという結果となっています。
| 手法 | 1stepあたりの学習時間 | 推論時間 |
|---|---|---|
| U-Net(Full FT) | 1.03秒 | 4秒 |
| LoRA | 0.42秒 | 4秒 |
| DreamBooth | 1.19秒 | 4秒 |
| Textual Inversion | 1.87秒 | 4秒 |
最後に、ファインチューニングの学習対象となっているモデルのサイズを確認しておきましょう。こちらが、新たなスタイルを獲得するために追加で導入が必要になるモデルサイズということになります。以下で分かるように、LoRAは低ランク行列を学習するためFull FTやDreamBoothと比べて非常にサイズが小さくなっています。また、Textual Inversionについては、新しい単語に対応する埋め込みベクトルのみが学習対象なので、極めて小さいサイズとなっています。
| 手法 | モデルサイズ |
|---|---|
| U-Net(Full FT) | 3.3GB |
| LoRA | 3.3MB |
| DreamBooth | 3.3GB |
| Textual Inversion | 4KB |
ここまで各手法の様々なスペックを紹介してきました。生成結果も合わせて考えると、LoRAが生成結果、モデルの軽量性、学習時間、必要スペックなどの多くの点でバランスが良くメリットがある方法と言えそうです。
本記事では、画像生成のファインチューニングに特化して、手法のアーキテクチャや実行方法、生成結果について幅広く検証してきました。画像生成のようなマルチモーダルタスクに対して、ファインチューニングが具体的にどのように行われ、どのような結果を生むのか、少しでもイメージを持っていただけたとしたら幸いです。
ここでは、Diffusersを用いたファインチューニングのための環境準備の方法について記載します。
Diffusersのインストールには、大きく分けて、
のふたつの方法がありますが、ファインチューニングでGitHubのリポジトリに含まれるスクリプトを利用するので、ここではGitHubのソースコードを用いる方法でインストールを行います。
まず、新たなプロジェクトには、専用の仮想環境を用意してその中で行うのがよいでしょう。以下を実行して仮想環境を作成します。
conda create -n python38_diffusers python=3.8そして、作成した仮想環境をアクティベートします。
conda activate python38_diffusersDiffusersのGitHubリポジトリをローカルにクローンしたのち、以下のコマンドでインストールを行います。
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .実行にあたって必要なその他のライブラリは、以下のように各手法のexampleフォルダ下のrequirements.txtを用いてインストールします。実施したい手法によって必要なものを実行すればよいでしょう。
pip install -r requirements.txt
最後に以下を実行して、HuggingFaceのAccelerate*23に関する設定を行います。Accelerateとは、PyTorchで推論やファインチューニングを実行するための環境(例えばMulti-CPUかMulti-GPUかなど)を簡易に変更するための仕組みです。これにより、コードを変更することなく実施環境をカスタマイズすることができます。
accelerate config*1:https://blog.brainpad.co.jp/entry/2023/06/06/160003
*2:https://github.com/Stability-AI/stablediffusion
*3:https://tech-blog.abeja.asia/entry/advent-2022-day19
*4:https://qiita.com/omiita/items/ecf8d60466c50ae8295b
*5:High-Resolution Image Synthesis with Latent Diffusion Models, https://arxiv.org/abs/2112.10752
*6:https://huggingface.co/stabilityai/stable-diffusion-2-1
*7:https://laion.ai/blog/laion-5b/
*8:https://blogcake.net/stable-diffusion-prompt/
*9:https://prompthero.com/stable-diffusion-prompt-guide
*10:https://beta.dreamstudio.ai/prompt-guide
*11:https://beta.dreamstudio.ai/generate
*12:https://github.com/AUTOMATIC1111/stable-diffusion-webui
*13:https://github.com/rinnakk/japanese-stable-diffusion
*15:Stable Diffusionで生成した画像を集めたDiffusionDBとよばれるデータセットから、ピクセルアート調の画像だけ取り出したデータセット, https://huggingface.co/datasets/jainr3/diffusiondb-pixelart
*16:https://blog.brainpad.co.jp/entry/2023/05/22/153000
*17:LoRA: Low-Rank Adaptation of Large Language Models, https://arxiv.org/abs/2106.09685
*18:https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads&search=lora
*19:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation, https://arxiv.org/abs/2208.12242
*20:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion, https://arxiv.org/abs/2208.01618
*21:https://huggingface.co/docs/diffusers/index
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













