



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
この記事では、ChatGPTとLLMを使って、プログラミングの知識なしでデータ分析(前処理、可視化、学習、検証)を行えるツールアプリケーションを構築してみたので、その内容をご紹介します。
こんにちは、私たちはアナリティクスサービス部の田中、林です。今回はLangChainとChatGPTを使ったアプリケーションを作成してみたのでその内容について説明します。データ分析を進めたい、進めないといけない人たちが、プログラミングの知識なしでデータ分析(前処理、可視化、学習、検証)を行えるアプリケーションです。また、今回の方法を拡張することで、さまざまな企業内の業務オペレーションを自然言語で簡単に操作できるアプリケーションも作成できます。
(※この記事の「ChatGPT」は「ChatGPT API」の意味になります)
LangChainは、言語モデルを基にした設計をするためのアプリケーション開発フレームワークです。LangChainを使った主なユースケースとしては、自律型エージェントやチャットボット、APIとの対話による最新情報にアクセスできる言語モデルの構築などを行うことができます。また、主な機能にはModel、Prompts、Memory、Indexes、Chains、Agents、Callbacksがあり、それぞれが独立して機能しながらも全体として連携させて動作させることができます。開発者はこれらの機能を組み合わせて、具体的なニーズに合ったアプリケーションを作成できます。
| Model | 大規模言語モデル(LLMs)、チャットモデル、埋め込みモデル |
| Prompts | 言語モデルやチャットモデルへの入力の構築、例の使用、出力解析 |
| Memory | 過去のチャットメッセージの管理と操作 |
| Indexes | 様々な文書の取得、効率的な検索システムの構築 |
| Chains | モデルが複数のタスクを連続的に処理するための機構 チェーンにより、より複雑なタスクや一連のタスクを効率的に実行可能 |
| Agents | モデルが一連のタスクを自律的に達成する能力を持つ単位 「アクションエージェント」: 一度に一つのアクションを決定して実行 「プラン・アンド・エクスキュートエージェント」: アクションの計画を先に立ててから一つずつ実行 |
| Callbacks | ユーザーが自分の言語モデルアプリケーションのプロセスを監視できるようにする |
今回はLangChainを活用したアプリケーションを作成しました。LangChainを用いた理由としては、「言葉での操作」を簡単に実装でき、また他のLLMにも対応しており応用範囲が広いことにあります。そこで今回はLangChainを使い、自然言語を使ったデータ分析のアプリケーションの開発を行いました。
また、LangChainの公式ページでも、「大規模言語モデル(LLM)は、開発者がこれまでできなかったようなアプリケーションを構築できるようにする、革新的なテクノロジーとして台頭しています。しかし、LLMを単独で使用しても、真にパワフルなアプリケーションを作るには不十分な場合が多く、LLMを他の計算ソースや知識と組み合わせることができたときに、真のパワーが発揮されます。このライブラリは、このようなタイプのアプリケーションの開発を支援することを目的としています。」とあります。ChatGPTなどのLLMが昨今話題になっておりますが、現状ではビジネス現場への適応のされた例は少ないです。そのため、今後はLangChainを使い個別のユースケースに適応させることで、LLMの真の力をビジネスの様々な場面に適応できると考えています。
現時点でできている範囲にはなりますが、LangChainを用いたプロトタイプアプリケーションを開発しました。このアプリケーションは、ユーザーが自然言語で指示を出すことで、データ分析の前処理、EDA、データセット作成、モデル学習と検証、結果の可視化までを自動で行うというものです。このアプリケーションを通じて、プログラミングスキルがない人でも、自分のビジネスや研究に必要なデータ分析を手軽に実行できるようになるのではないかと考えています。
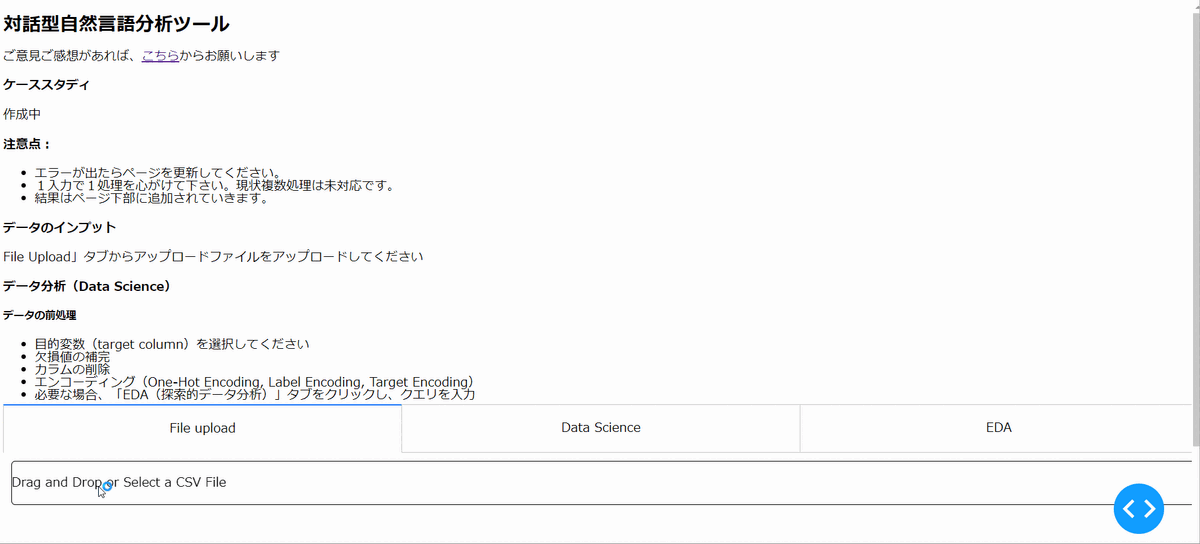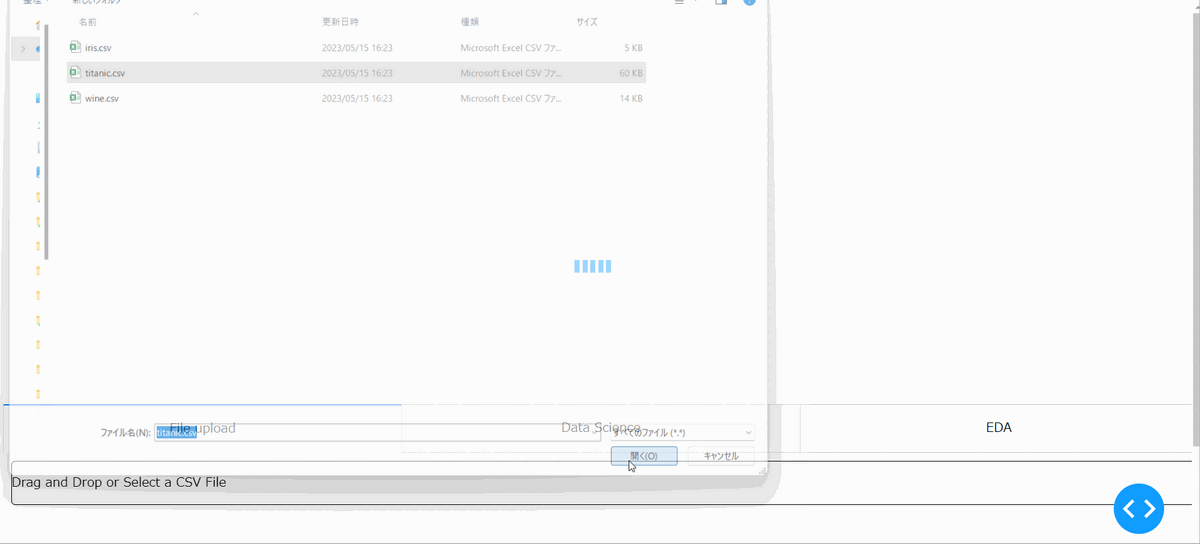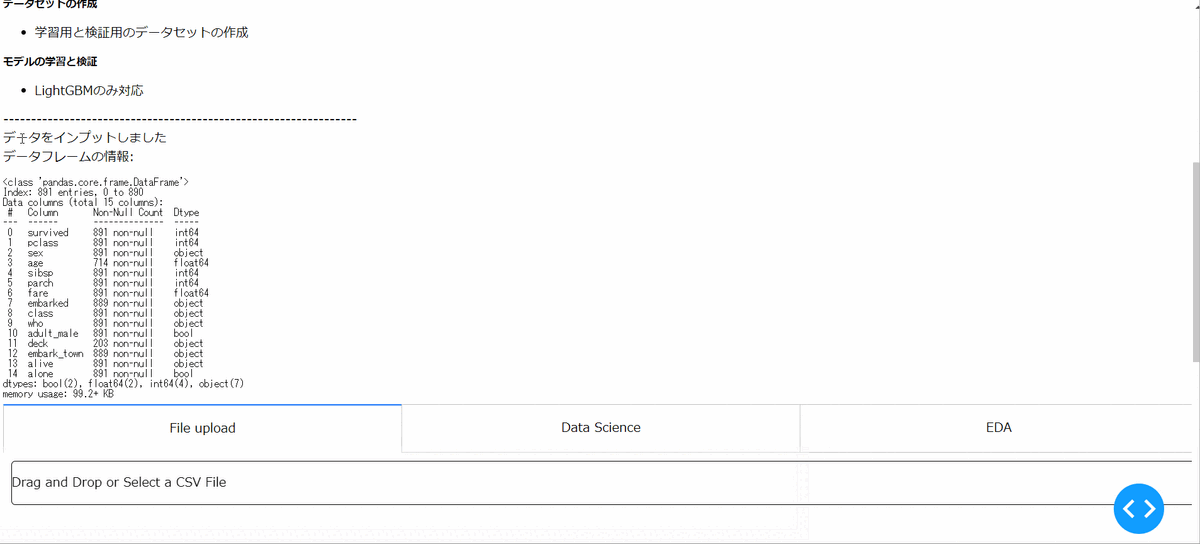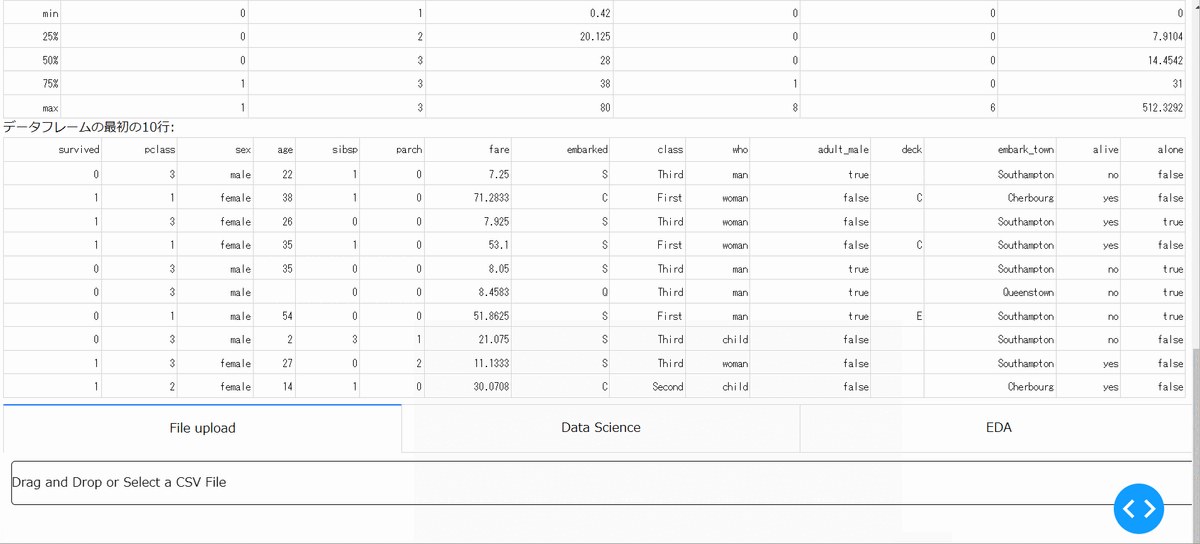
タイタニックデータを使用して、一般的なデータ分析のフローをプロトタイプアプリにて実際に実行してみたいと思います。
・データアップロード
現状はcsvファイルのみをアップロードできるようになっています。
・指定列の削除
アップロードしたファイルの中の指定した列を削除できます。以下の場合は、survived列と意味が重複しているalive列を削除しています。
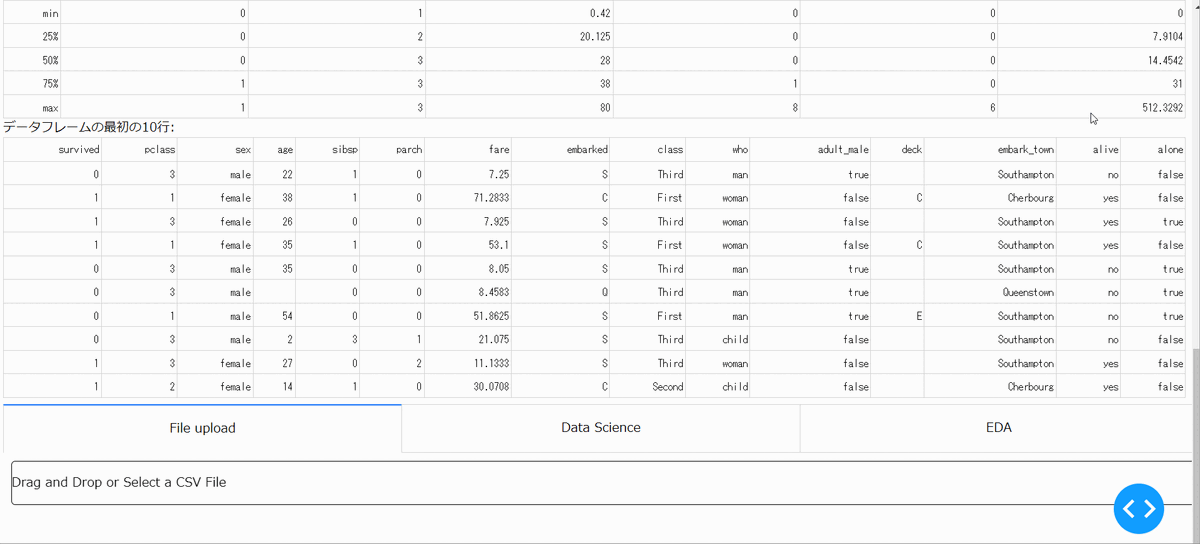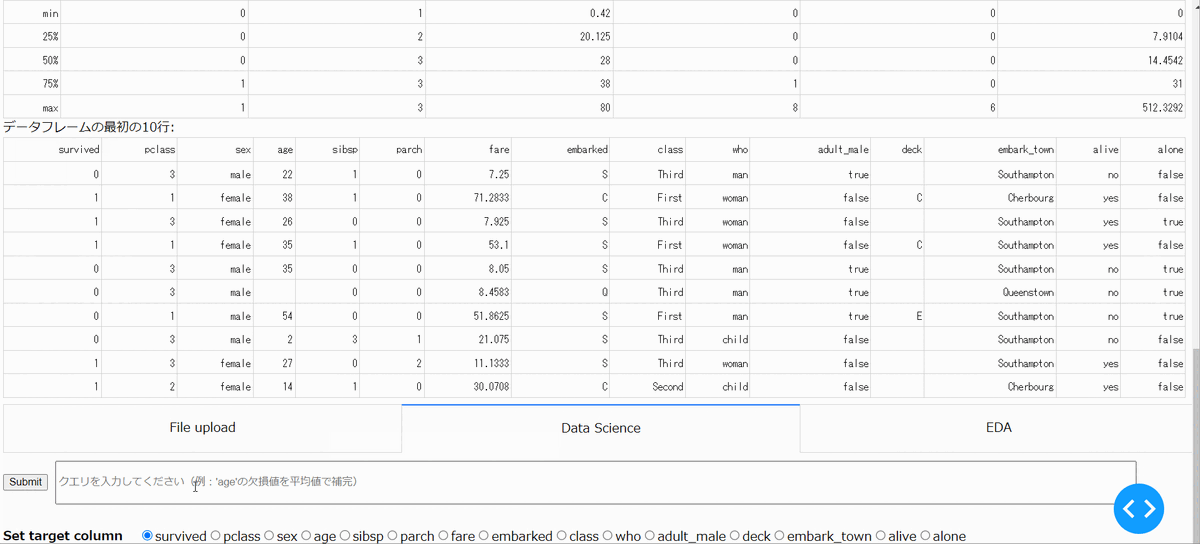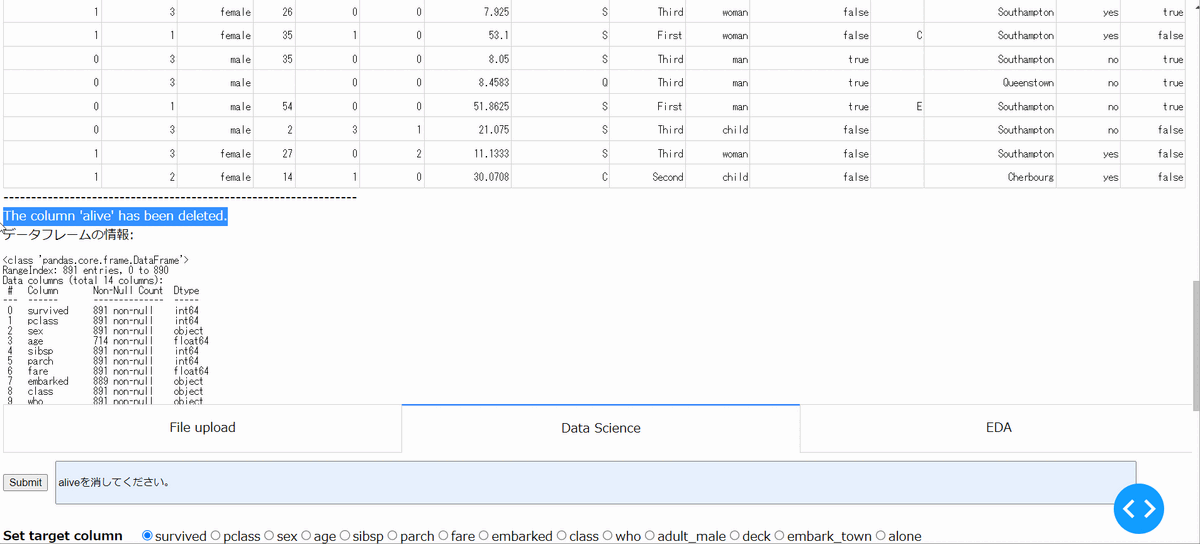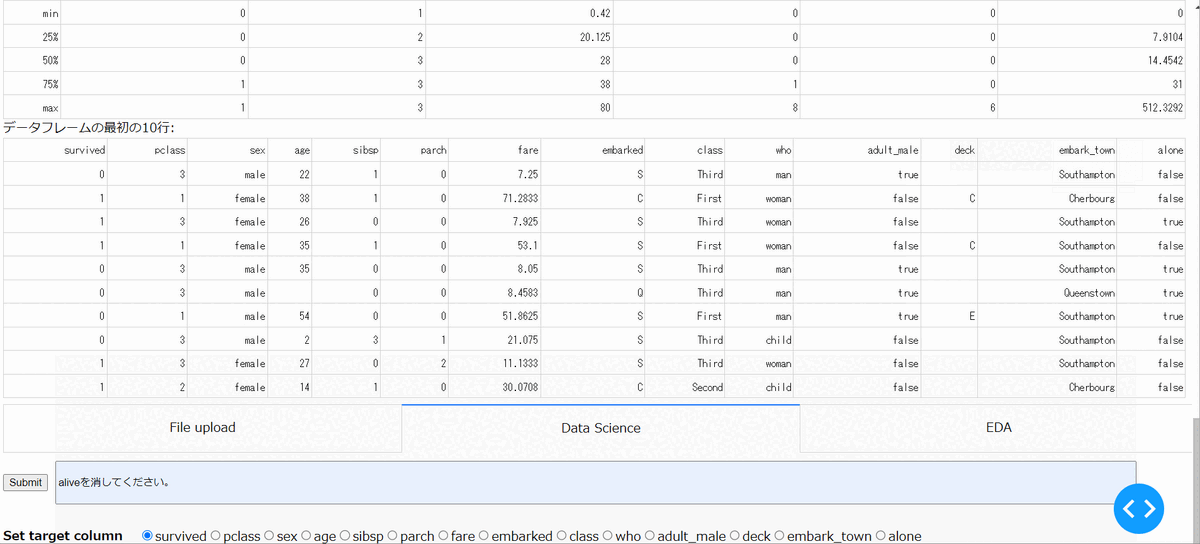
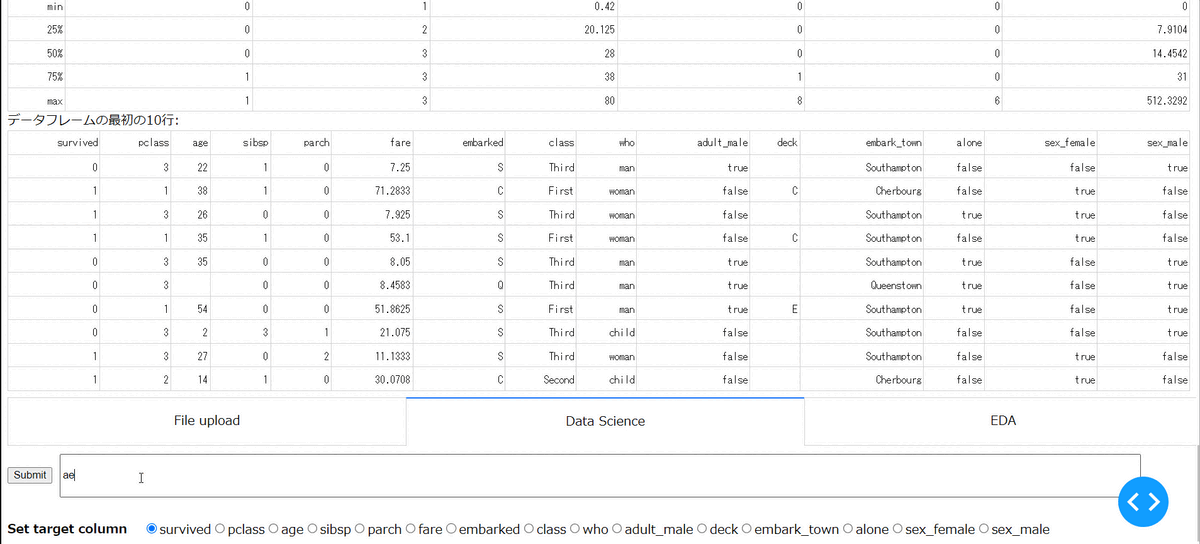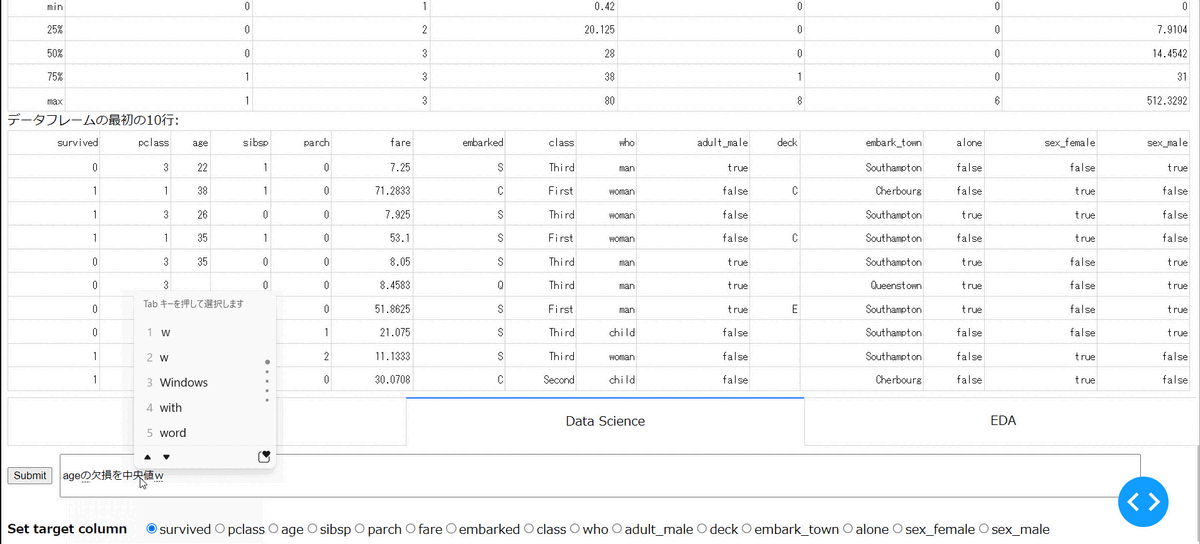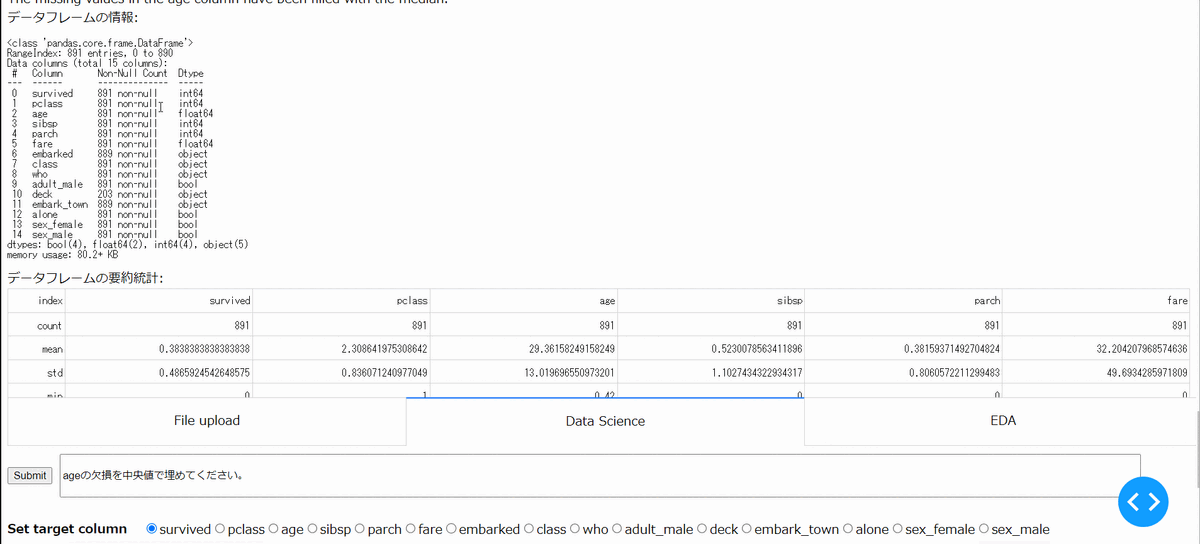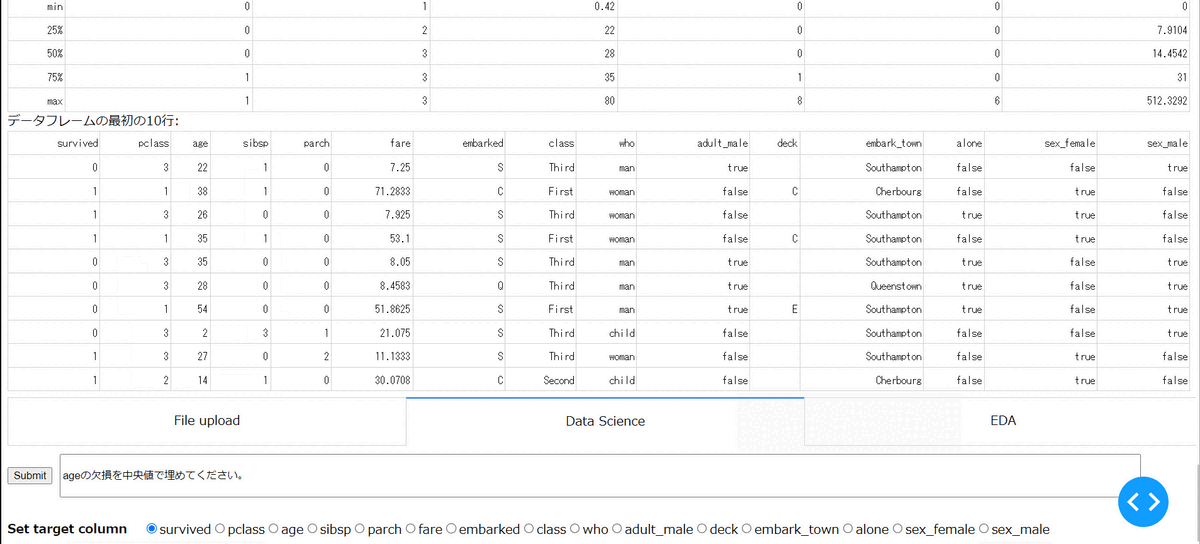
・指定列の補間
指定した列に欠損がある場合に、その補間ができます。以下の場合は、age列の欠損を中央値で補間しています。
・エンコーディング
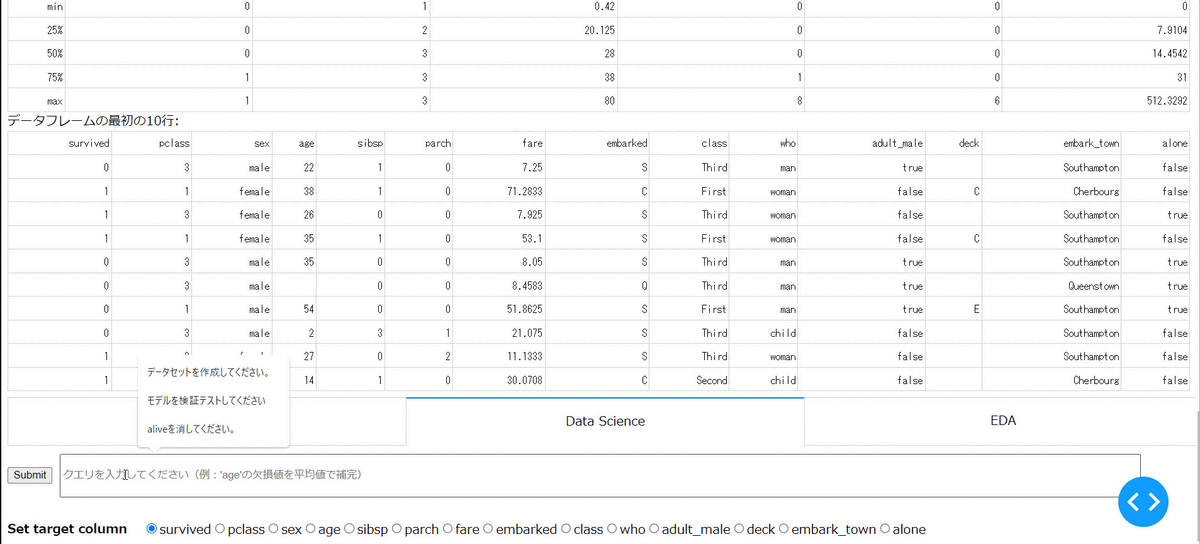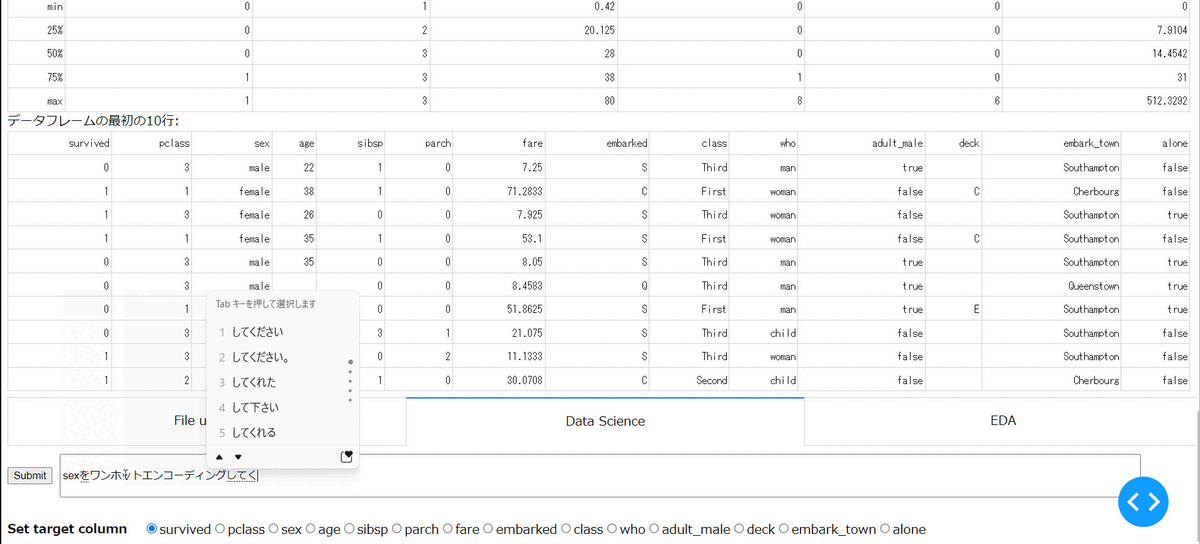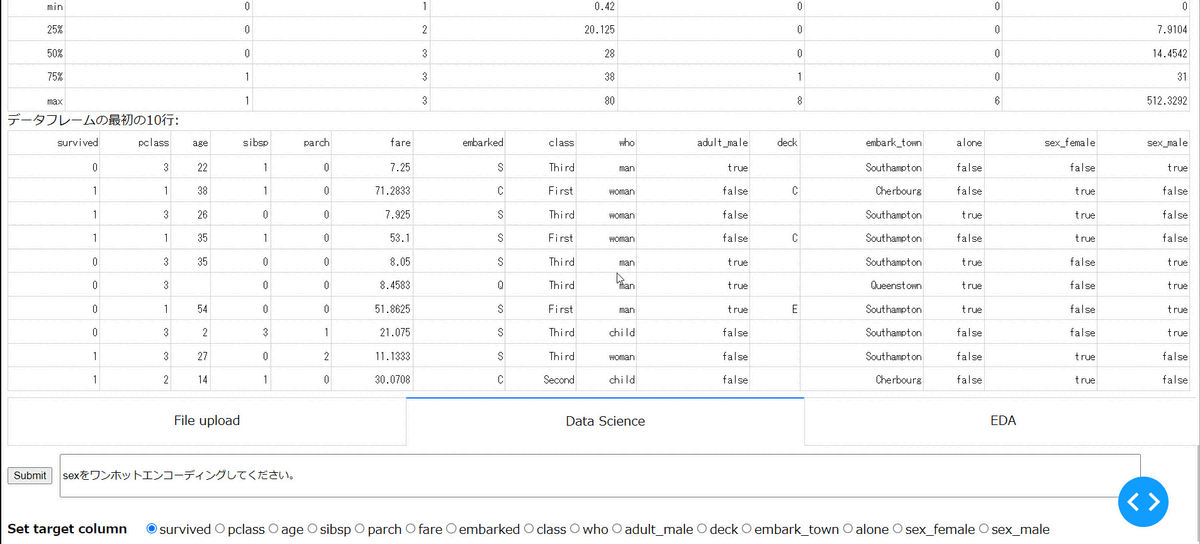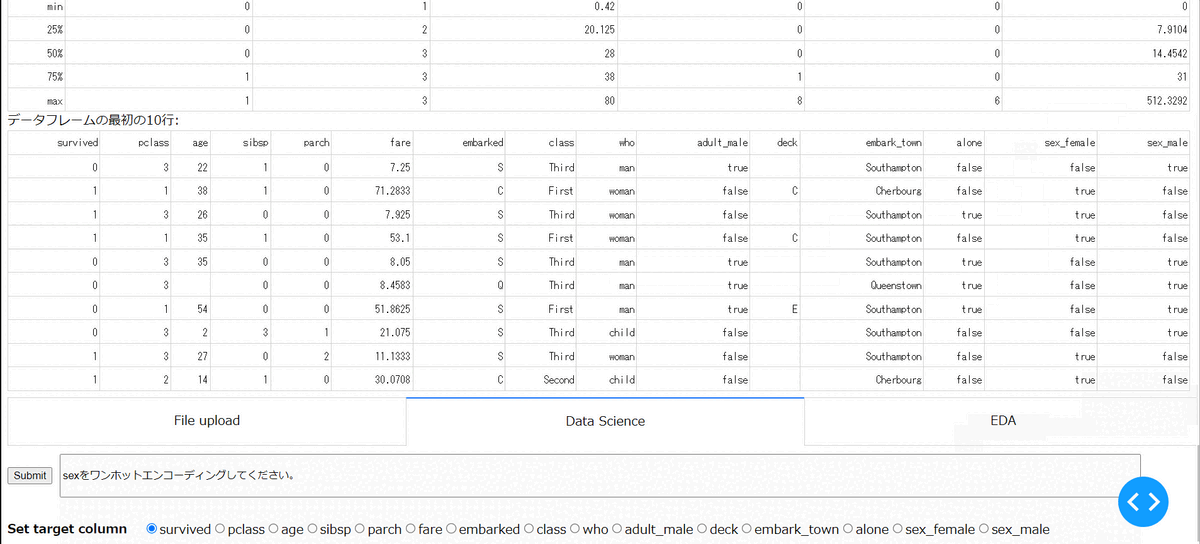
指定したカラムのエンコーディングを行えます。現状、Label Encoding, One-hot Encoding, Target Encodingに対応しており、以下では、性別のOne-hot Encodingを実施しています。
・EDA(データの確認・可視化)
作成したデータセットの探索的データ分析を実施しています。こちらは、任意のグラフを出力ができないなど課題がありますが、生き残った人の中でpclassが3だった人の数値データとカテゴリデータの分布を示しています。
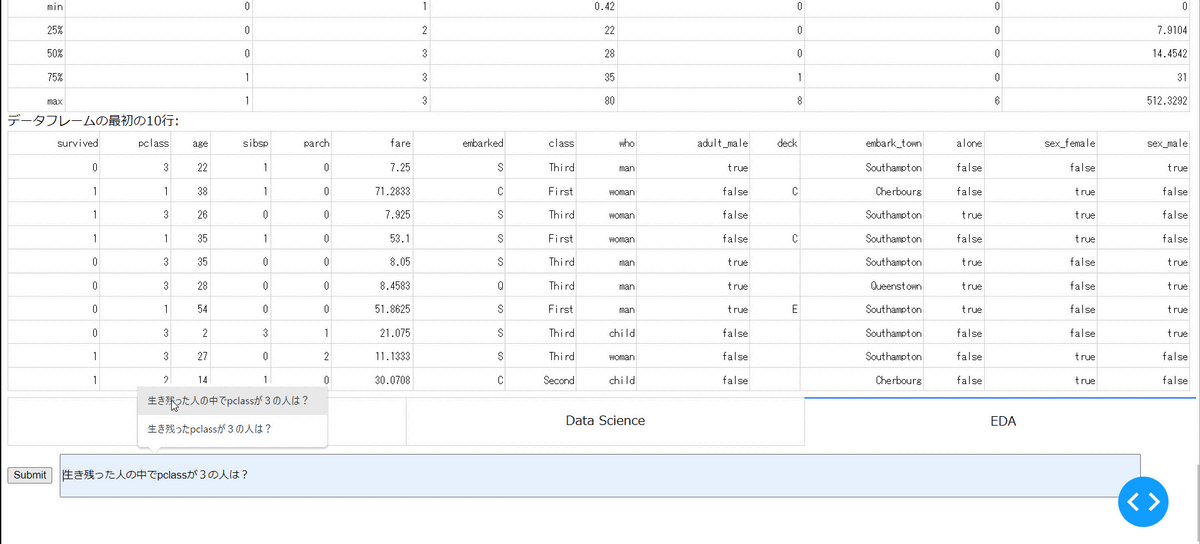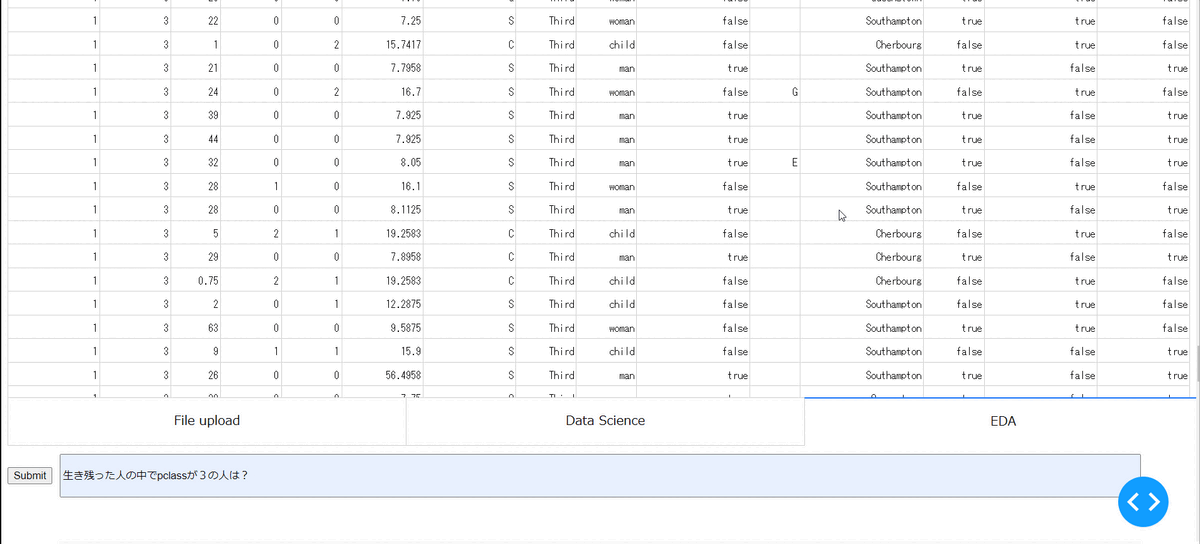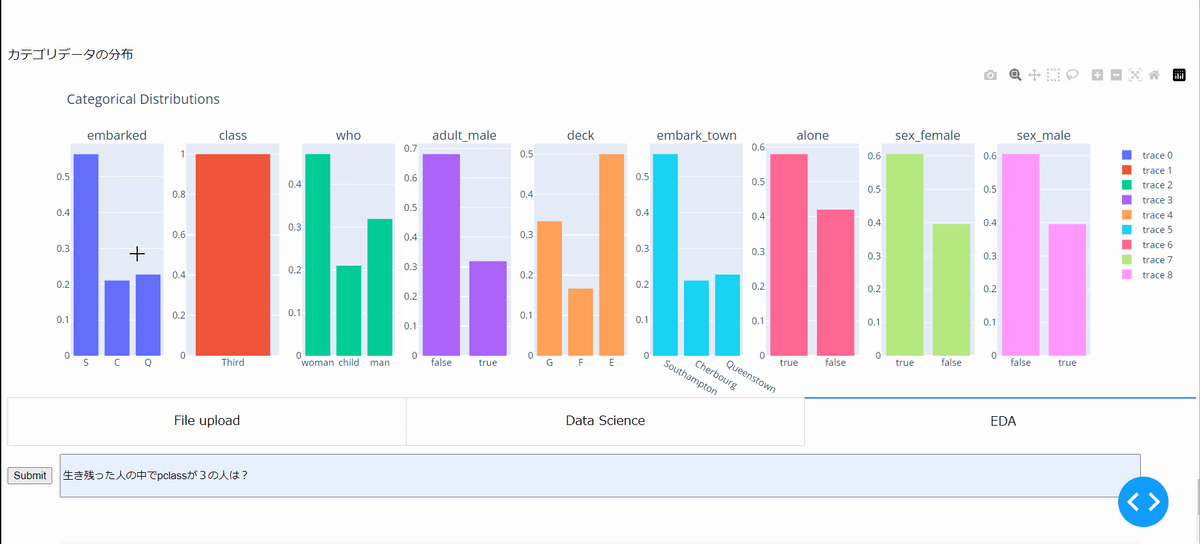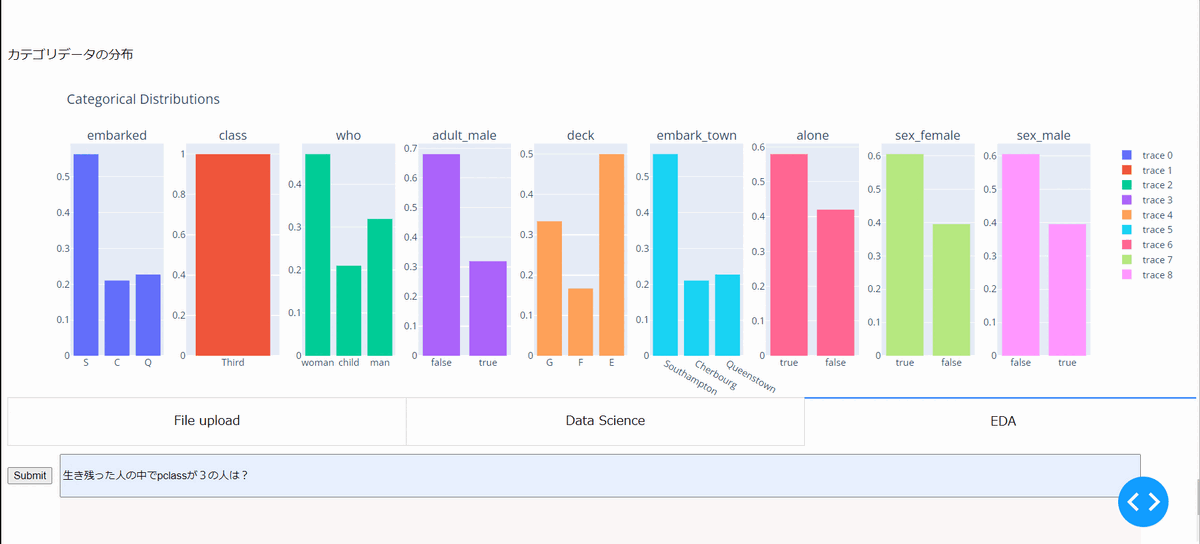
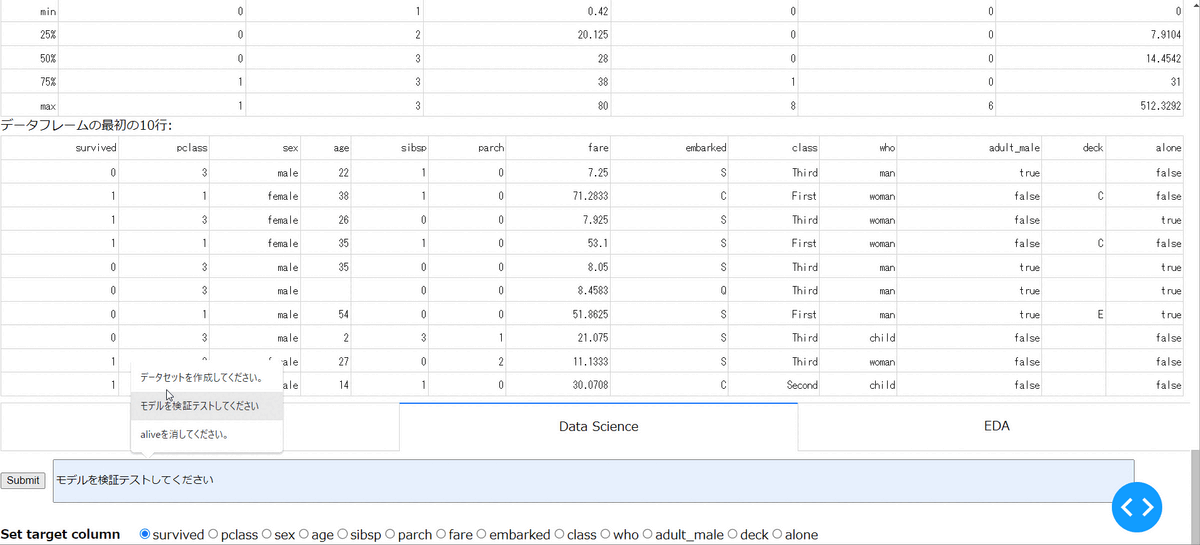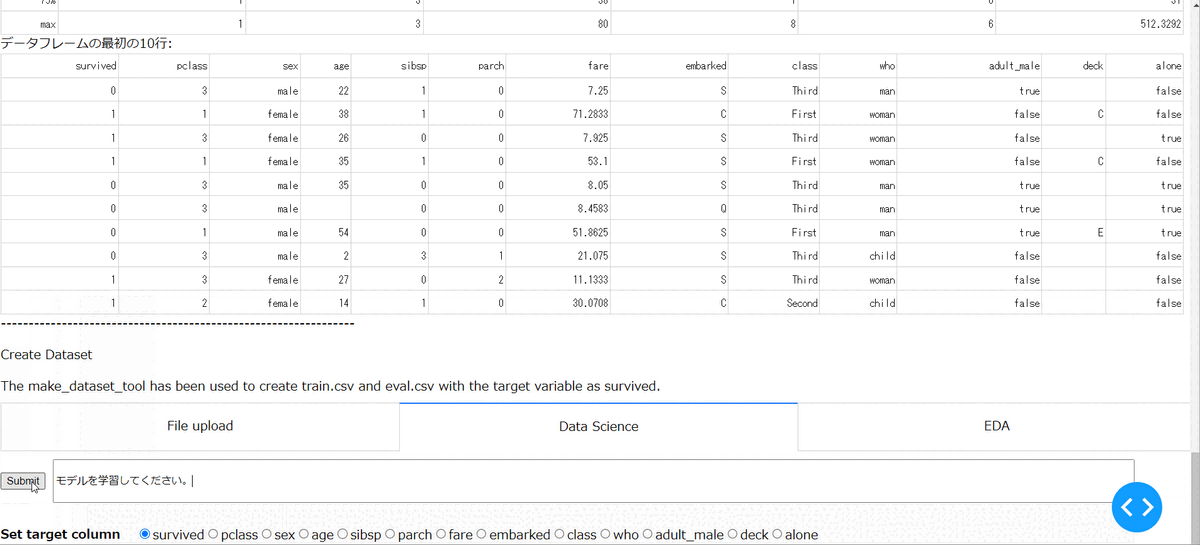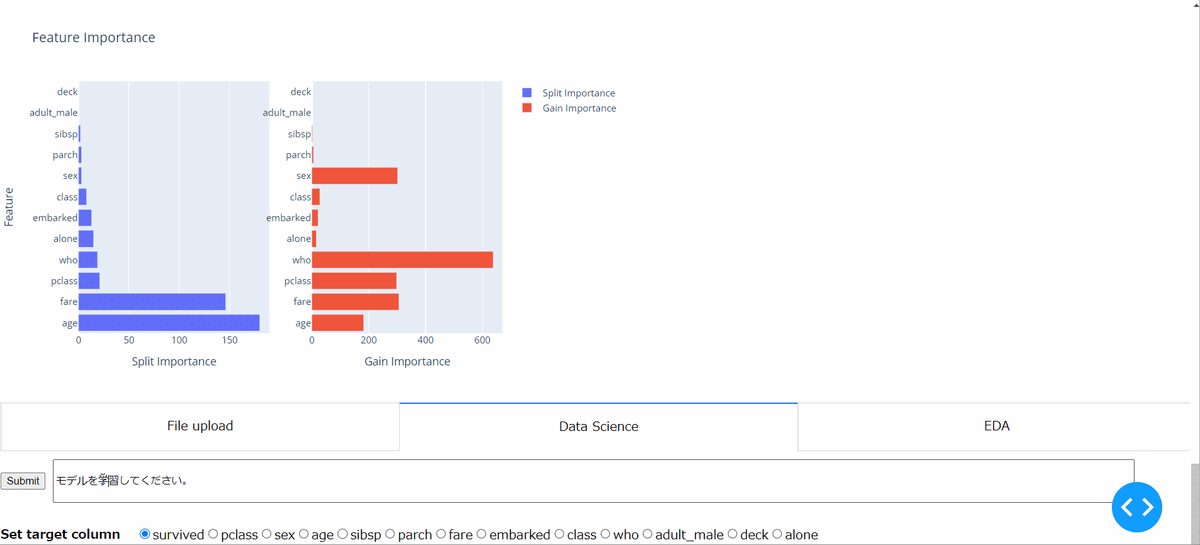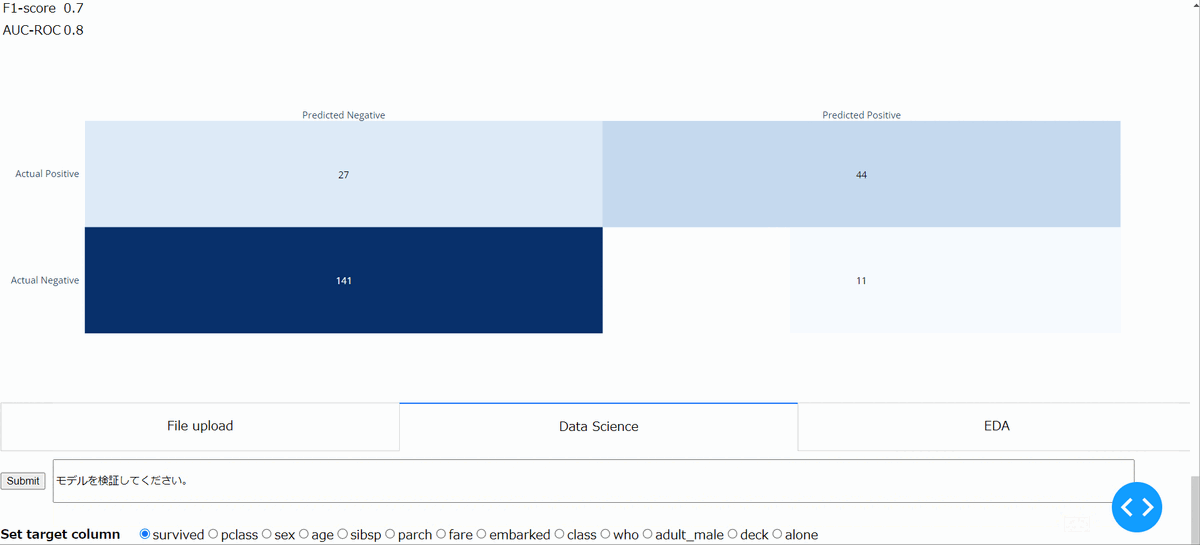
・データセットの作成~モデルの学習と検証
最後に上記で加工したデータセットを用いて、学習用のデータセットを作成し、モデル(現状はLightGBM)を用いて学習し、そのモデルの検証を行っています。
実験段階では、より複雑な処理(例:特徴量エンジニアリングやグループ化処理など)も実行できましたが、実装面での課題がありました。一例を挙げると、入力表記によっては動作に問題が生じるため、より汎用的な実装に改善を進める必要があります。
具体的には、カラム名が正確に入力されていない場合、動作しないなどです(例:○age、×Age、年齢)。しかし、Pandas Dataframe Agentというエージェントを使用することで、上記のカラム名の問題や複雑な処理にも対応できます。ただし、現時点では以下に示すToolsとAgentsをカスタマイズすることができておらず、アプリケーションとして実装には至っていません。今後、ToolsとAgentsをカスタマイズすることで、柔軟で汎用性のある実装が可能となり、様々な処理に対応できるアプリケーションを開発することを目指しています。
次に、実際に上記内容をどのように実装しているかについて説明します。
以下では今回実装したLangChainを使ったアプリケーションの主な実装方法について説明します。
https://python.langchain.com/en/latest/modules/agents/tools.htmlpython.langchain.com
LangChainの一つの機能としてToolsというものがあります。ToolsではLLMに使わせたい様々な道具が用意されており、例えば「検索をするための道具」や「簡単な計算ができる道具」などがあります。また、このToolsには自作のToolsの作成方法も記載されています。今回はデータサイエンティストがよく使いそうな以下のようなToolsを作成しました。
・欠損値の埋め込みをするTool
・ラベルエンコーディング、ターゲットエンコーディングをするTool
・LightGBMを学習するTool
・…
以下はラベルエンコーディングのためのToolの作成例です。
class LabelEncodingTool(BaseTool):
name = "label_encoding_tool"
description = """It is useful for label encoding when column names are given. The input should be a column name."""
def _run(self, query: str) -> str:
"""Use the tool."""
query = text_processing(query)
df = pd.read_csv(f"{INPUT_DIR}/{STORED_DF}")
le = LabelEncoder()
df[query] = le.fit_transform(df[query])
df.to_csv(f"{INPUT_DIR}/{STORED_DF}", index=False)
result = f"{self.name} label encoding {query} has been completed. "
return result
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("LabelEncodingTool does not support async")https://python.langchain.com/en/latest/modules/agents/agents.htmlpython.langchain.com
またLangChainで使うもう一つの機能としてAgentsというものを使いました。Agentsでは上記のToolsをLLMに使いこなしてもらうような実装をすることができます。具体的にはLLMが入力を受け取った際にToolsを使うべきか判断し、必要なタイミングで呼び出しを行い、Toolsの実行結果を踏まえて回答を行います。
以下は実際にAgentsを使う方法の例になります。
def run_mltools(query: str, target: str, num_class: int):
# Toolの設定
tools = [
mltools.LgbmtrainTool(),
mltools.LgbminferenceTool(),
ppt.DropColumnTool(),
ppt.OnehotEncodingTool(),
ppt.LabelEncodingTool(),
ppt.TargetEncodingTool(),
ppt.Fill0Tool(),
ppt.FillMeansTool(),
ppt.FillMedianTool(),
ppt.MakeDatasetTool(),
]
# 通常のLangChainの設定
llm = OpenAI(temperature=0)
agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
prompt = """
{input_}一度toolを使ったら必ず終了してください.
目的変数は{target_}です.
""".format(
input_=query, target_=target
)
# LLMが入力を受け取った際にToolsを使うべきか判断
results = agent.run(prompt)
return results以上の二つの機能を主に活用し、アプリケーションの開発を行いました。
今回作成したアプリケーションは現状の状態ではまだ利用ケースが限られています。今後は、様々な入力に対して実行することができる汎用性が重要になると考えています。さらに、このようなアプリケーションを作る上で、既存のAutoMLやデータ分析ツールとの差別化も重要になってきます。
汎用性の課題の解決策として、Toolsの自動生成にも取り組んでいます。あらかじめToolsを作成していなくても、内部で必要なToolsを自動で作成し処理を実行することにも成功しました。これにより、「プログラムとして実装できるほとんどすべてのことがChatGPTにより実行できる」ようになると考えています。
また既存のAutoMLやデータ分析ツールとの差別化戦略としては、LangChainの強みを活用した自然言語によるユーザー体験の向上や、特定の産業向けにカスタマイズされた機能の開発などです。私たちが今回作成したものはデータ分析のアプリケーションですが、これを拡張することで企業内の業務オペレーションを自然言語で簡単に操作できるアプリケーションも作成することが可能です。
今回私たちが作成したLangChainを活用してアプリケーションは、その手軽さと導入範囲の広さから、プログラミングが得意でない人たちでもデータ分析を進められる環境を提供できます。今後、LangChainを活用したプロトタイプアプリケーションを通じて、より多くの人々がデータ分析の恩恵を受けられるとよいと考えています。
プログラミングはやりたくないけど、データ分析を進めたい、進めないといけないような方々、また、この記事に関心がある方、ぜひお気軽にご連絡ください。共に新しいデータ分析の可能性を探りましょう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













