

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回は、LLMをお手元のPCで扱ってみたい方々に知っていただきたい、2023年2月にリリースされたLLMの処理を行うための生成エンジン「FlexGen」を解説します。
こんにちは。アナリティクスサービス部の杉山です。
現在大変注目を集めているChatGPT*1、多くの方が使っていることかと思います。ChatGPTは、大規模言語モデル (Large Language Model; LLM) を用いたAIチャットボットの1つです。この分野の研究や開発はここ最近で大きく発展しています。
そもそも、LLMとは何かというと、大量のテキストデータを学習させた自然言語処理モデルになります。このモデルに対し、テキスト文字列を入力することで、例えば翻訳や、要約、疑問文に対する回答テキストを出力として返すことができるようになります。この工程を連続で行えるようにしたものが、会話形式で利用できるチャットボットです。
ビジネス面において大きな可能性を感じるLLMですが、LLMの多くで生じる問題点の1つは、処理に極めて大きな計算量とメモリ量を必要とすることです。これまでは、企業レベルで購入する高価なPCや、大規模なレンタルサーバーやクラウドでは実装できても、一般的なPCで実装を行うことはとても困難でした。しかし、FlexGenという技術がそのような環境を大きく変えました。
今回の記事は、LLMをお手元のPCで扱ってみたい方々に知っていただきたいFlexGen*2について解説いたします。
FlexGenは2023年2月にリリースされた、LLMの処理を行うための生成エンジンです。FlexGenには大きな特徴が2点あります。
特に一点目のインパクトが強いです。パラメータ数が特に多いLLMの処理は、GPUを並列したPCや大規模なレンタルサーバー・クラウド上で行うことが主でした。しかし、FlexGenによって一般的なPCでもそのようなLLMの処理を行えるようになりました。
FlexGenの主なメカニズムとして以下の3つを解説していきます。
1. GPU、CPUメモリ、ディスクを利用した分散処理 (オフローディング)
2. LLMの重み、キー、バリューを4ビット整数に圧縮する処理 (量子化)
3. 従来の処理手法と異なるジグザグ処理
FlexGenはPCの主なリソースであるGPU、CPUメモリ、そしてディスクを使ってLLMを処理することができます。このような分散処理をオフローディングと呼びます。利用するリソースはよく聞くPCリソースであると思いますが、簡単にそれぞれのリソースについてまとめます。
LLMはGPUに全て処理させる方法が一般的です。しかし、LLMの多くは莫大なメモリ量を必要とします。例えば、Meta社からリリースされたOPT-175B*3というモデルをGPUのメモリにロードしたい時、必要なメモリ量は325GBとなります。このモデルを利用するには、例えばNVIDIA A100 (80GB) といった高性能なGPUが5枚必要となります。しかしFlexGenではオフローディングを採用しているため、LLMのサイズがGPUのメモリを超えていたとしても、LLMの処理を行うことが可能です。
LLMには重み、キー、そしてバリューというパラメータが含まれます。これらは、入力された文章に対する回答を出力する際に必要となるパラメータです。FlexGenはこれらのパラメータの精度を維持しつつ、4ビットの整数に圧縮する手法*4を用いています。このように、データやパラメータをより小さいビット数に圧縮することでデータ容量を下げる手法を量子化と呼びます。
この手法を用いた場合、出力に悪影響を及ぼすことが危惧されます。FlexGenの論文では、OPT-175Bの重み、キー、バリューを4ビットに圧縮した場合と圧縮しない場合の出力結果の比較を行っており、圧縮の影響は無視できるレベルであることが示されています。さらに、3ビット量子化も試験しています。しかし、3ビットまで圧縮すると精度を保てないことが示されています。
FlexGenのもう一つの特徴として、従来の生成エンジンの処理の順序と異なる順序を用いることで、PCにかかる負担を減らしています。
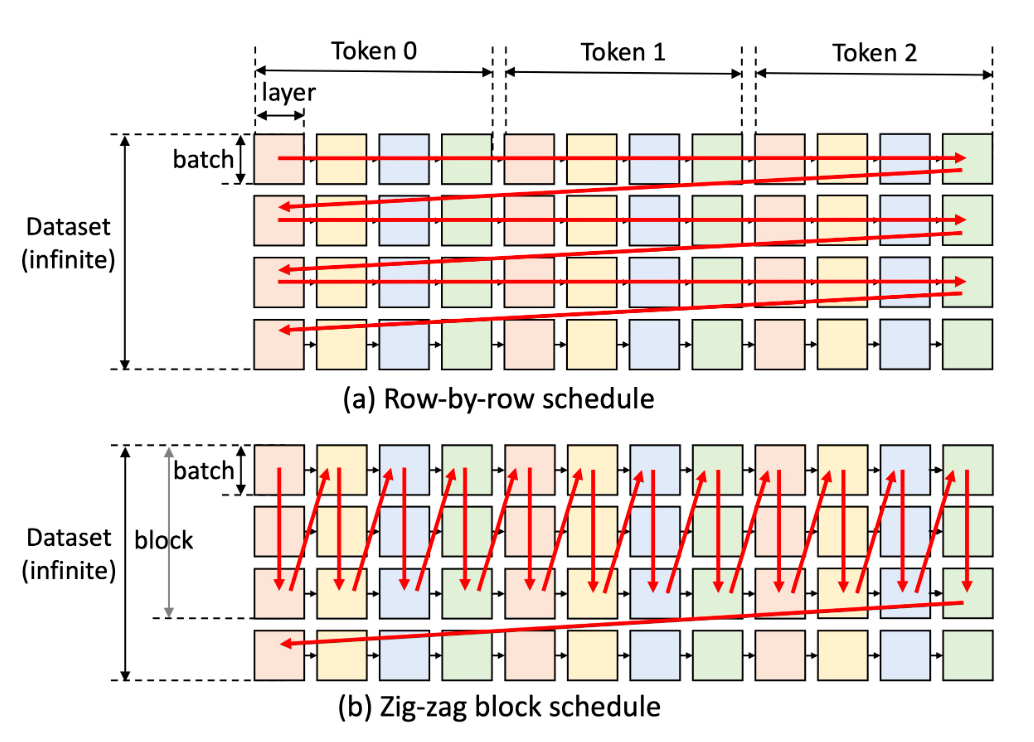
図1は従来の生成エンジンの処理の順序(a)と、FlexGenの処理の順序(b)を表します。この図は、ある入力テキストからトークンを3つ生成する状態を考えています。それぞれの色の四角はGPUの層とバッチごとの計算を示します。
従来の方法 (図1 (a)) は、全トークンのバッチを行ごとに処理を行います。この手法のメリットは、1バッチ分の計算を最も速く終わらせることができることと、行単位で保持する必要があるキー・バリュー等のパラメータの容量をバッチの計算終了後に解放できることです。したがって、行の計算を完了させメモリを解放し、次の行へ移動するというプロセスを繰り返し行う手法となります。しかし、行方向に連続する2つのバッチは重みを共有しないため、この手法では重みを繰り返しロードする必要があり、PCに負担がかかります。
このロードの繰り返しを削減するために、FlexGenは複数行のバッチ (ブロック) を列ごとに処理します(図1 (b))。列内のすべての正方形は重みを共有しているため、重みをGPUに残して再利用することができます。しかし、行ごとのパラメータの容量を保持する必要があるため、列の最後まで処理を行おうとすると全行のパラメータをメモリに残す必要が出てきます。そのため、CPUメモリとディスクを溢れない程度の行数に絞って処理を行います。FlexGenの論文上ではこの手法をZig-zag block scheduleと呼んでいます。この手法により、PCにかかる負担を減らしています。
以上の内容が、FlexGenのメカニズムとなります。
LLMに利用できる生成エンジンはFlexGen以外も存在します。オフローディングを採用している生成エンジンの例として、DeepSpeed Zero-Inference*5と Hugging Face Accelerate*6があります。これらは、お手元のPCでLLMを処理したい際に利用する生成エンジンの候補となることが考えられます。
では、FlexGenは他の生成エンジンと比較してどの程度優れているのでしょうか。FlexGenの論文では、FlexGen(圧縮を使う場合(c)と使わない場合)、DeepSpeed Zero-Inference、そして Hugging Face Accelerate の生成スループットとレイテンシ (処理を開始してから応答までかかる時間) を比較しています (図2)。なお、比較した際に用いられたコンピュータのリソースは、GPU: NVIDIA T4 (16GB)、メモリ: DRAM 208GB、ディスク: SSD 1.5TB となっています。

OPT-175Bの結果が顕著であり、同等のレイテンシである場合、既存の生成エンジンよりFlexGenのスループットが向上していることがわかります。複数データ点がある理由としては、用いたオプションや生成しようとしたトークン数等が異なるためです。圧縮を利用し、ディスクのオフロードを取り除いた場合、スループットは最も高くなり既存の生成エンジンの最大スループットの約100倍ほど向上します (青線、レイテンシが212秒 (~ 4000秒))。
つまり、利用したコンピュータリソース要件やモデル、そしてスループットにおける比較では、FlexGenが最も優れていると言えます。
今回は、大規模言語モデルを1つのGPUを搭載したPCで扱えるFlexGenという技術について紹介させていただきました。
FlexGenのメカニズムとして、オフローディング、パラメータの量子化、そして従来とは異なるLLMの処理方法を採用していることがわかりました。
また、FlexGenの性能として、LLMであるOPT-175Bを用いた際に、スループットが従来の生成エンジンに対し最大100倍まで向上することがわかりました。
*1:OpenAIが2022年11月にリリースしたAIチャットボット:
https://openai.com/product/chatgpt
*2:FlexGen: 参考文献を参照
*3:OPT:
https://github.com/facebookresearch/metaseq/tree/main/projects/OPT
*4:FlexGenで用いられているGroup-wise quantization:
https://arxiv.org/abs/1909.05840
*5:DeepSpeed Zero-Inference:
https://arxiv.org/abs/2207.00032
*6:Hugging Face Accelerate:
https://huggingface.co/docs/accelerate/index
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













