

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回は、論文をもとにChatGPTでコンテンツモデレーションモデルがどのように構築されたのかを紹介します。
こんにちは。AIソリューションサービス部の米川です。
大規模言語生成モデル(LLM)を活用したいと考えた際、モデルを準備するだけでなく運用リスクを低減を期待できる多様な技術を調査・検証することが求められます。それらの技術領域の例として「モデルの入出力の監視」があります。入出力を監視することで意図しないモデルの挙動や社会的に問題のある出力の発生頻度を減らし、LLMの運用リスクを軽減させることが期待できます。
本記事では、こちらの論文*1(以下、本論文)を基にChatGPTにおけるコンテンツモデレーションモデル*2がどのように構築されたかを紹介しようと思います。タスクの性質上、不快な表現が現れることがありますがご了承ください。
ソーシャルネットワーキングサービスやeコマースなどのwebサービスにおいて投稿された不適切なコンテンツをモニタリングし、必要に応じて投稿の削除やユーザーのアカウントを停止する作業はコンテンツモデレーションと呼ばれます。この作業によって、サービス内の健全性が保たれ、ユーザー離れやブランドイメージの低下を防ぐことができます。
このような監視作業はこれまで人手で実施されてきましたが、作業効率の向上や作業者への負担の軽減などの面から近年は様々なwebサービスにて機械学習モデルによる監視の自動化が進められています。特にChatGPTのように24時間提供され、レスポンス速度が求められるようなサービスでは人手による監視作業は難しいと思われます。
コンテンツモデレーションに関連する技術は様々なクラウドサービス上(AWS*3、Azure*4、GCP*5)で提供されており、今回紹介する本論文のように独自のモデルをせずとも取り組むことができます。
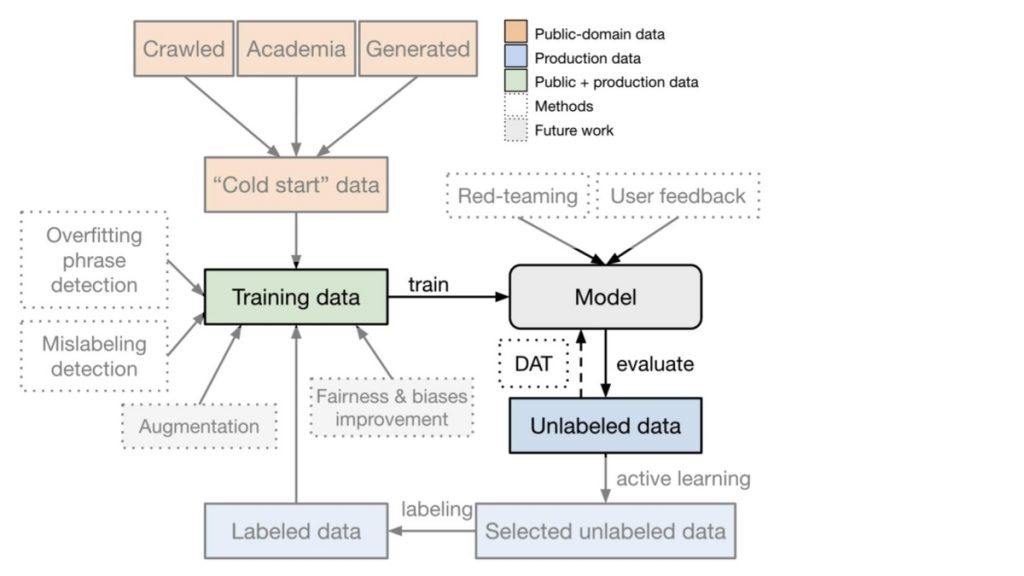
モデレーションモデルの学習フレームワークを示したものが図1となります。

サービス上に蓄積されるデータは基本的にラベルが無いものになりますが、より良いモデルを得るためには高品質なラベル付きのデータセットを構築する必要があります。そのため、図1で紹介されるフレームワークではモデルを学習するだけでなく、モデルを活用したラベリング作業を行うことで高品質のラベル付きデータセットを作成するといった取り組みを行っています。また、この取り組みを繰り返すことでよりデータセットのラベル品質が改善され、データセットのサンプル数も増やすことができます。図1にある通り、汎用的なモデレーションモデルを構築するためには多様な状況に対する課題があり、それに対処するために様々な工夫がなされています。以下では本論文にて記載されていたラベル設計とコンテンツモデレーションモデルの構築に向けた取り組み、取り組みの検証結果について紹介します。
コンテンツが検出対象かどうかを正確に判断するためには判断基準となる分類法を参照する必要があります。この分類法の設計、つまりラベル設計が十分でない場合、アノテーターごとに特徴の異なるデータセットが構築される可能性があります。また、ノイズの多いデータセットで学習されたモデルは検出すべきコンテンツの見逃しや検出すべきでないコンテンツの誤検知が発生しやすくなり、運用リスクが高まります。しかし、コンテンツが検出対象かどうかは様々な要素(ユースケース、ユーザーの社会的・文化的背景など)で変化するため、汎用的な分類法を定めることは非常に難易度の高いタスクとなります。このようなトレードオフを認識し、フィードバックなどを基にラベル設計を都度調整することが求められます。
本論文ではトレードオフを意識した上で5つのトップカテゴリを設計しています。また、トップカテゴリに加えてミスラベルやコーナーケースの発生頻度の減少を期待し、粒度の細かいサブカテゴリを設計しています。以下が設計されたカテゴリになります。
S: Sexual content
性的な行為を描写するコンテンツを表すカテゴリになります。サブカテゴリは以下の4つを定義しており、S0のように検出対象ではありませんがラベリング作業のコーナーケースとなり得るコンテンツをカテゴリとして定義されていました。
| サブカテゴリ名 | 説明 |
|---|---|
| S3 | 未成年者を対象とした性的なコンテンツ |
| S2 | 現実社会において違法となり得る性的な行為の描写があるコンテンツ |
| S1 | 違法性は無いものの性的な描写があるコンテンツ |
| S0 | 医療や性教育などの非性的なコンテンツ |
H: Hateful content
特定の集団のアイデンティティを理由にその集団やメンバーを対象とした虐待行為を描写したコンテンツを表すカテゴリになります。サブカテゴリは以下の4つが定義されていました。
| サブカテゴリ名 | 説明 |
|---|---|
| H2 | 暴力や脅迫を助長する不快なコンテンツ |
| H1 | 軽蔑的なステレオタイプもしくは不快な発言を助長するコンテンツ |
| H0.a | 特定の集団のアイデンティティに対する中立的な発言を含むコンテンツ |
| H0.b | 解説のために引用されたヘイトスピーチを含むコンテンツ |
V: Violence
身体的暴力に関する描写やそれらの行為を支持するコンテンツを表すカテゴリになります。サブカテゴリは以下の3つが定義されていました。
| サブカテゴリ名 | 説明 |
|---|---|
| V2 | 生々しい暴力行為が描写されたコンテンツ |
| V1 | 脅迫などの暴力に近しい表現が描写されたコンテンツ |
| V0 | 文脈を考慮すると中立的な表現とみなすことができる暴力的表現を含むコンテンツ |
SH: Self-harm
自傷行為に関する描写やそれらの行為を支持するコンテンツを表すカテゴリになります。サブカテゴリは定義されていませんでした。
HR: Harassment
現実社会において個人を悩ませたりハラスメントを助長させるコンテンツを表すカテゴリになります。サブカテゴリは定義されていませんでした。
本論文では以上のように定義された5個のトップカテゴリと11個のサブカテゴリを対象にラベリングされています。また、公開されている評価データ*6を確認したところ、本論文には記載されていませんでしたが1つのサンプルが複数のトップカテゴリに属することを許容するラベル設計となっているようです。
図1にて紹介されていたフレークワークを4つの段階に分けて、コンテンツモデレーションモデルの構築に向けた取り組みを解説します。

プロジェクト初期は学習に用いるデータを十分に用意できていないことがあり、モデルを作成する以前にまずはデータ収集やラベリング作業を実施する必要があります(この問題はコールドスタート問題と呼ばれています)。本論文でもそのような学習に用いることができる実データ(OpenAI APIに送信されたデータ)が十分収集されていないような状況を想定した取り組みが実施されています。具体的には、初期データセットをサービス上に蓄積されたものではなく一般に公開されているもしくは比較的容易に作成可能な3つのデータセットで構成しています。1つ目はCommon Crawlデータ(図2のCrawled)、2つ目は研究向けに用いられることが多いWikipediaのようなパブリックデータセット(図2のAcademic)、3つ目は後述する合成データになります(図2のGenerated)。これらのデータセットを先ほどのラベル設計を基にラベリングしています。
合成データの利用
パブリックデータセットを用いることである程度のサンプル数を確保できますが、パブリックデータのみでは特定のカテゴリのサンプル数が少ない不均衡データとなることが確認されています。この課題に対して本論文ではGPT-3を用いて合成データを生成することで対処しています。合成データは図3のように人手によって作成されたテンプレート(図3の黒字部分の文)を入力とすることで作成されています。更に、出力された文を人手でラベル付けたされたものを初期データとして利用しています。

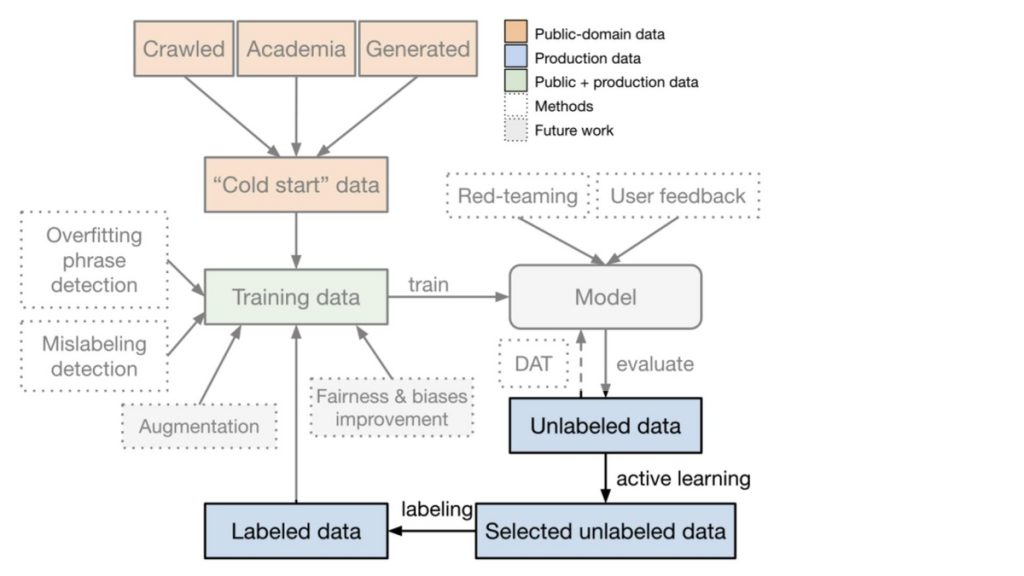
初期データセットが構築されたのでモデルの学習を行います。本論文において、コンテンツモデレーションモデルは5つのトップカテゴリとサブカテゴリの一部(S3、H2、V2)の8つのクラスを予測するマルチラベル分類タスクを学習しています。モデル構築時の学習データは前段で構築された初期データ、テストデータはプライバシー上の観点から詳細な記載がありませんでしたが実データで実施されていると思われます。したがって、初期状態では学習とテストデータでデータのソースが異なり、これに起因する問題が発生する可能性があります。この問題に対処するため、本論文では学習時にDomain Adversarial Training(DAT)と呼ばれる技術の導入を行っています。
Domain Adversarial Training
学習データとテストデータのドメインが異なる状況において機械学習モデルの性能が劣化することが知られています。この問題に対処する手法の1つとしてDomain Adversarial Training(DAT)と呼ばれる手法が用いられます。この手法はドメインの異なるデータ間で共通する特徴に着目してモデルが学習するように促すため、ドメインの変化による性能劣化が緩和される可能性があります。
本論文の初期学習データはパブリックデータで構築されているため、テストデータとなる実データと比較すると様々な点で異なる特徴が見られます。実際にこの初期データでモデルを学習させ実データで性能検証を実施したところ、性能劣化が発生したそうです。これに対して著者はDATの一つであるWasserstein Distance Guided Domain Adversarial Training(WDAT)*7を導入し、性能劣化が緩和されることを確認しています。
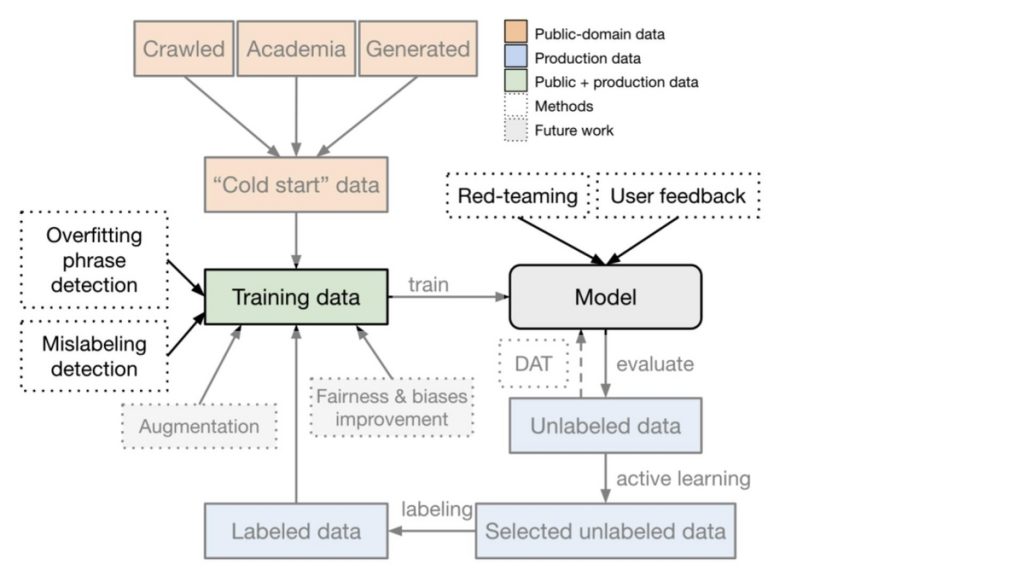
初期モデルを構築することができましたが、モデルをより良いものへとするためにはどうすればよいでしょうか?方針の一つとして学習データを増やすことが考えられます。特に検出対象となる実データを学習データに追加することで、初期データで懸念されていた問題の緩和やモデルの大幅な性能改善が期待できます。しかし、日々蓄積される大量のデータから検出対象となり得るデータを探し出すことは容易ではありません。この問題に対処するため、本論文ではアクティブラーニングによるラベリング作業の効率化が行われています。
また、性能改善に影響する他の要素としてラベルの品質が考えられます。高品質なラベルを維持するためにはアノテーターへの明確なラベル基準の共有や継続的なラベル品質の監視が重要となります。
アクティブラーニングによるデータ抽出
本論文では前段で得られたモデルでスコアリングされたデータセットに対して、以下の3つのサンプリング手法で構成されたアクティブラーニングを適用することでラベリング作業の効率化を期待しています。
これらのサンプリング手法で収集されたデータから更にランダムサンプリングされたデータがラベリング作業の対象となります。
前段にて得たラベル有り実データを用いた新しいモデルを構築する前や本番環境にモデルをデプロイする前に、専門の分析チームによりユーザーからのフィードバックやデータセット、モデルの分析が行われます。これによって、現状のモデルに含まれる弱点の理解や弱点克服に向けた取り組みを考えられるため、様々な運用リスクを低減することが期待できます。以下は本論文に記載されていたコンテンツモデレーションモデル構築時に実施された分析例になります。これらの分析後にデータセットの更新と新しいモデルの構築を行うことでデータセットに含まれるノイズが減り、より高品質なモデルとデータセットを得ることができます。
人口統計学的属性なバイアスの分析
モデルを分析したところ、特定の人種を表現する単語の組合せに対してモデルの予測傾向が偏るといった人口統計学的属性なバイアスが発生していました。この問題に対して本論文では合成データを用いて対策を行っています。作成された合成データの例として “[subject] is selfish/foolish/narrow-minded.” というものが紹介されていました。このsubjectの部分に問題となった単語と任意の単語を組み合わせて入力、様々なラベルのデータを生成していました。この対策によってモデルに含まれるバイアスの緩和だけでなく、モデルの検出性能も改善することが報告されていました。
モデルの予測根拠の分析
機械学習モデルは人間的にはあまり意味のない特徴に基づいて予測を行うことがあります。例えば、”a short and moving film.” と “a short and moving movie.” に大きな違いはありませんが、これらを感情分析モデルのような機械学習モデルに入力すると異なる予測結果が得られたとします。この結果からモデルがfilmとmovieに基づた予測を行っていることがわかりますが、これは期待する挙動ではありません。モデルの予測根拠を理解することは、モデルの性能改善だけでなくモデルに含まれるバイアスを知ることにつながり、運用リスクの低減を期待することができます。
本論文で構築されたモデルでも、例に挙げたような特定の単語による挙動の変化が見られたようです。この問題に対して著者はリスクのある単語の削除*8を行うことで、特定の単語による予測スコアへの影響を低減していました。
モデル性能
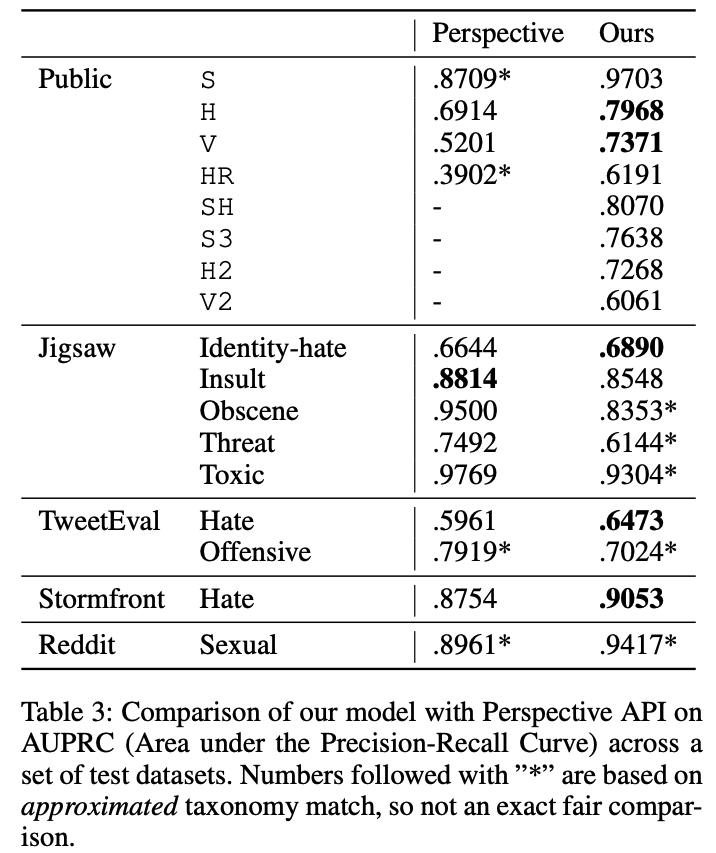
図6は提案手法(本論文にて構築されたモデル)とコンテンツが有害なものかを判別する既存手法の1つであるPerspective API*9 に対する評価結果になります。提案手法はPublic、Perspective APIはJigsawというデータセットに対応することを目的として構築された手法であるため、各データセットに対応した手法が良い結果となっています。この結果からより良い分類法を設計することが、特定のドメインのデータセットでのタスクを正確に解くための要因の1つであることが考えられます。残りのTweetEval、Stormfront、Redditについて各手法を比較すると、提案手法はPerspective APIを上回る性能を示しておりより汎用的なコンテンツモデレーションシステムとなっていることがわかります。
アクティブラーニングの効果
次に、アクティブラーニングを単純なランダムサンプリングと比較し、構築されるデータセットやモデルについて分析を行います。
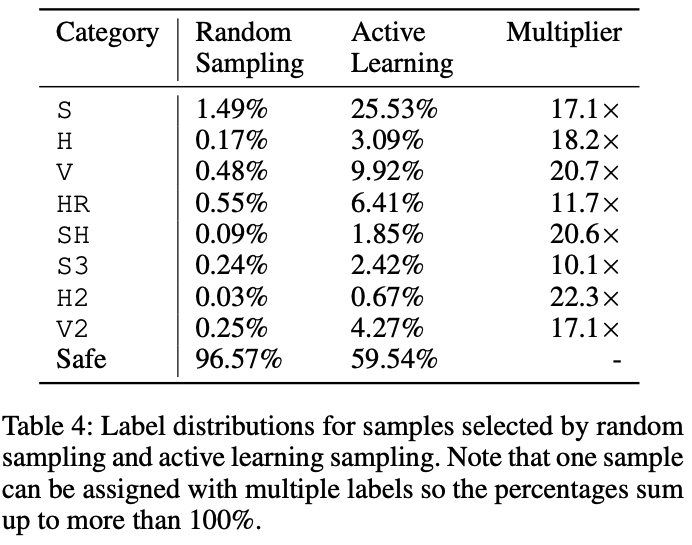
図7はアクティブラーニングとランダムサンプリングで構築されたデータセットのラベル分布を示しています。ランダムサンプリングではほとんどのサンプルが検出対象ではないSafeとなっている一方で、アクティブラーニングでは様々なカテゴリにおいてラベル付きのサンプルがランダムサンプリングよりも収集されていることがわかります。
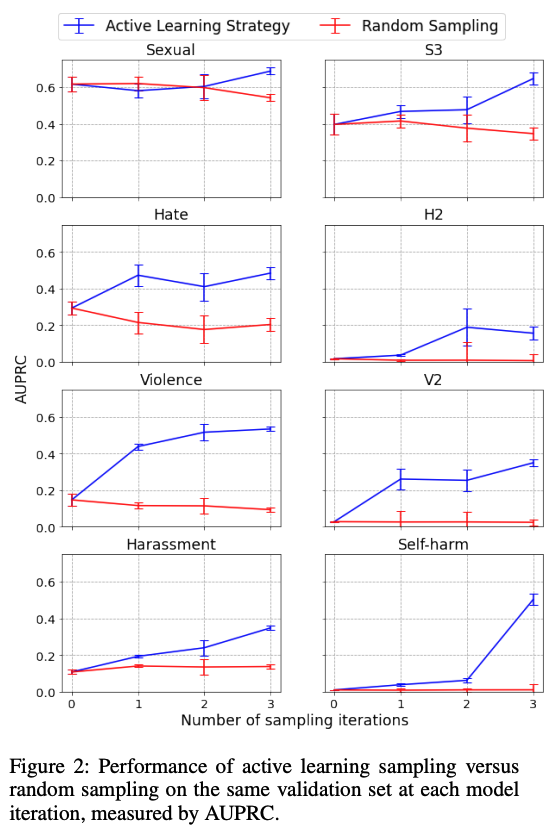
図8は各手法で構築されたモデルの性能を示したものになります。縦軸はAUPRC、横軸はデータセットとモデルの更新回数を表します。青線がアクティブラーニング、赤線がランダムサンプリングによる結果を示しています。ほとんどのカテゴリにおいて更新回数に対するアクティブラーニングの改善幅がランダムサンプリングよりも大きいことがわかります。以上のことから、より良いサンプリング手法の選定がモデルの性能に大きく影響することが考えられます。
Domain Adversarial Trainingの効果
最後に、Wasserstein Distance Guided Domain Adversarial Training (WDAT) の有効性を確認します。DATの導入目的は学習データとテストデータのドメインが異なる状況を対処することにあるので、学習・テストデータのドメインの差異が小さくなった状況についても効果を検証しています。具体的には、以下の3つの状況を想定した実験が行われています。
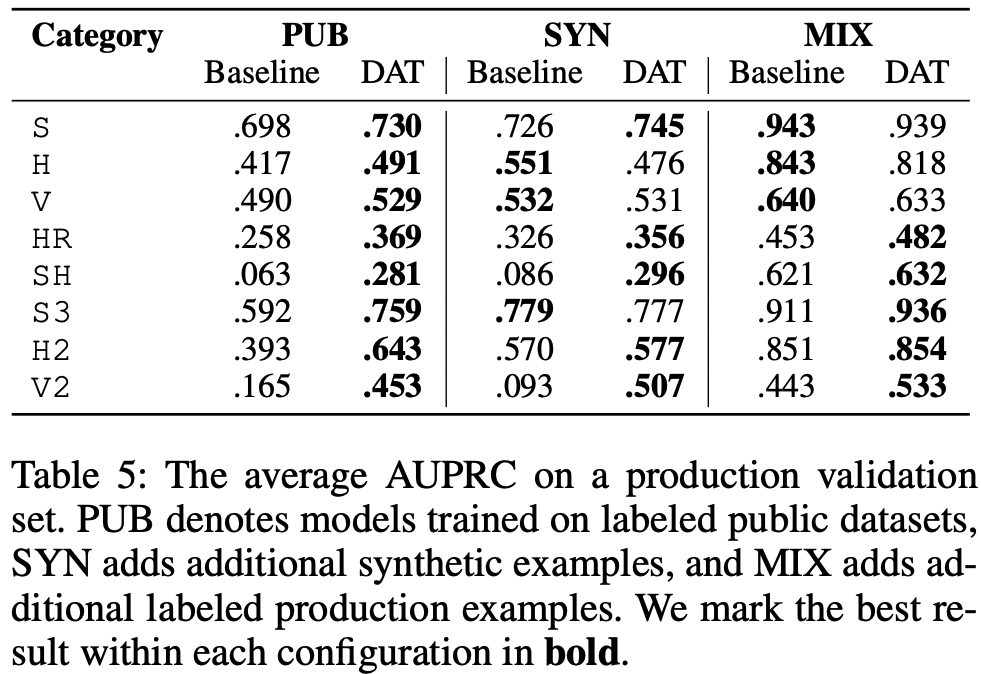
図9は各状況におけるDATの検証結果を示しています。BaselineはDATが導入されていないモデルになります。プロジェクト序盤(PUB)ではDATを導入することによる効果がどのカテゴリにおいても見られます。しかし、ラベルが付いた実データが蓄積された状況(MIX)ではPUBほどの効果が得られませんでした。特に、他のカテゴリに比べてデータ量の多いHやVではDATを導入することでモデルの性能が劣化する傾向がみられます。
今回はLLMの運用時に活躍が期待される「機械学習によるコンテンツモデレーション」の一例を紹介し、運用に耐えうるコンテンツモデレーションモデルを構築するためには「汎用的な分類法の設計、データセットの状態の分析、データセットの状態を改善する手法の考案」の3つの要素が重要であることがわかりました。これらの要素は機械学習モデルを構築するうえで一般的に必要とされるものではありますが、実運用されている特定の技術(今回はLLM)に関するシステムがどのように構築されているかを知ることは非常に重要な取り組みであると思います。
今後もLLMに関連する技術のキャッチアップを続け、より良いLLMの活用ができればと思います。
*1:https://arxiv.org/abs/2208.03274
*2:https://platform.openai.com/docs/guides/moderation
*3:https://aws.amazon.com/jp/machine-learning/ml-use-cases/content-moderation/
*4:https://azure.microsoft.com/ja-jp/products/cognitive-services/content-moderator/
*5:https://cloud.google.com/vision/docs/detecting-safe-search?hl=ja
*6:https://github.com/openai/moderation-api-release/tree/main
*7:https://aaai.org/papers/11784-wasserstein-distance-guided-representation-learning-for-domain-adaptation/
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













