



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/5/30時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

人間がLLMと特にビジネスの場で共存していくために、LLMの出力結果に対する評価は不可欠です。そしてビジネスをスケールさせ再現性高く評価を行うためには、AIがAIを評価することが肝要です。
【関連記事】生成AIをビジネス活用する上で押さえるべき8つの評価観点
ところがこのLLMの評価には依然として方法論的な課題が残っており、一貫した評価を行うためには多くの検討事項が残っています。
【関連記事】生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
今回紹介する論文では、言語モデルの評価において直面する課題と、それらに対処するためのベストプラクティスを検討しています。さらに言語モデル評価のためのオープンソースライブラリLanguage Model Evaluation Harness (lm-eval)を紹介します。
以下概要です。
言語モデルの評価において、以下の点が課題として挙げられます。
上記で述べたような課題に対応すべく、LLMの評価ベストプラクティスが挙げられていました。いくつかご紹介します。5つほど紹介されていましたので、興味があればぜひ論文を読んでみてください。
上記のベストプラクティスに基づき構築されたのが lm-eval というオープンソースライブラリです。
lm-eval は、研究者やユーザーが1つのコードベースをインストールすれば望む評価タスクを実行できるようになることを目標としています。
またあらかじめライブラリにベストプラクティスが組み込まれている状態ですので、ユーザーが自然とベストプラクティスに従う形で評価を行うことができます。
実際に lm-eval が有用であることを実証するため、論文ではいくつかのケーススタディの結果についても記載しています。
LLMの評価には多くの課題が伴いますが、lm-eval を使用することで、評価の一貫性と再現性を向上させることができるとわかりました。
簡単にモデルの出力結果を評価できるようになれば、人間がいちいち最終結果を担保せずともLLMに仕事を任せていけるような世界が近づきそうです。
出典:https://arxiv.org/pdf/2405.14782
LLMがある特定のタスクにおいて人間を上回るパフォーマンスを出せたという事例を見かけることがあるかと思います。「人間の仕事がAIに取って代わられる」という言説もあり、LLMが人間以上に上手くこなせるタスクの範囲は今後も広がっていくことが予想されます。
さて、LLMは言語の出力に長ける一方、数値の分析やその結果を判断するタスクをどのくらいこなせるかはあまり検証されてきていませんでした。
今回ご紹介する論文では、LLMが収益変動の予測能力において人間の金融アナリストを上回ることを実証しました。
概要をご説明します。
本研究では、GPT-4と人間のアナリスト、企業分析に特化する形で訓練された機械学習モデルのアウトプットをそれぞれ比較し、予測精度を評価しました。
今回はLLMが財務諸表に報告された数値のみから経済的な洞察を生成できるのかを調査することが目的のため、GPTー4には匿名化・標準化された財務諸表を用いて(つまり通常財務諸表に付随する文章情報は与えない)、将来の収益の方向性を判断するようモデルに指示しています。
また出力のためのプロンプトを、通常の簡単なプロンプトと、CoT(Chain-of-Thought)プロンプトを用いて予測をさせたものの2種類用意しました。CoTプロンプトとはモデルに指示を行う際に人間と同様に思考プロセスを踏んでタスクをこなすよう指示するプロンプトです。
【関連記事】プロンプトエンジニアリングの基本と応用
今回は人間の財務アナリストを模倣するように、①財務諸表の傾向を特定 ②主要な財務比率(流動性やレバレッジ比率等)を計算 ③①②を統合して将来の収益に対する期待を形成する というステップを踏ませました。
結果は以下の通りです。
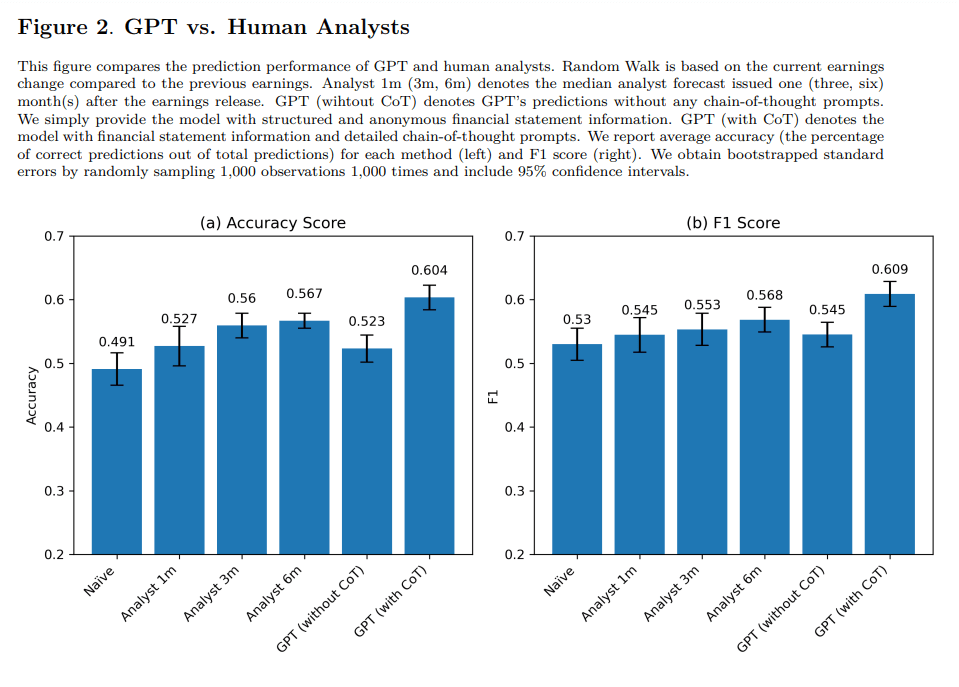

さらに、実際にGPTの出力に基づく取引戦略は優れたパフォーマンスを発揮し、GPTに基づく財務分析が株式市場での有用性を持つことが示されました。特に小型株のリターン予測で優れたパフォーマンスを出すことが強調されています。
本研究の結果、たとえ業界固有の情報がなくとも、LLMは収益変動の予測能力において金融アナリストを上回るほどの優れたパフォーマンスを発揮できることが分かりました。さらに人間のアナリストがLLMに代替されるのではなく、あくまで補完的な関係であることも明らかになりました。
出典:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4835311
LLMエージェントを用いたプランニングタスクを実行する試みが注目を集めているようです。
本論文は、大規模言語モデル(LLM)を活用したエージェントプランニングにおいて、WKM(世界知識モデル、World Knowledge Model)を導入することで、プランニングの精度向上を実現する方法を提案しています。
従来のエージェントプランニングでは、LLMは現実世界の理解が不足しており、無意味な試行錯誤や幻覚的な行動を起こしがちという課題がありました。この現実世界の情報を補完するのがWKMです。
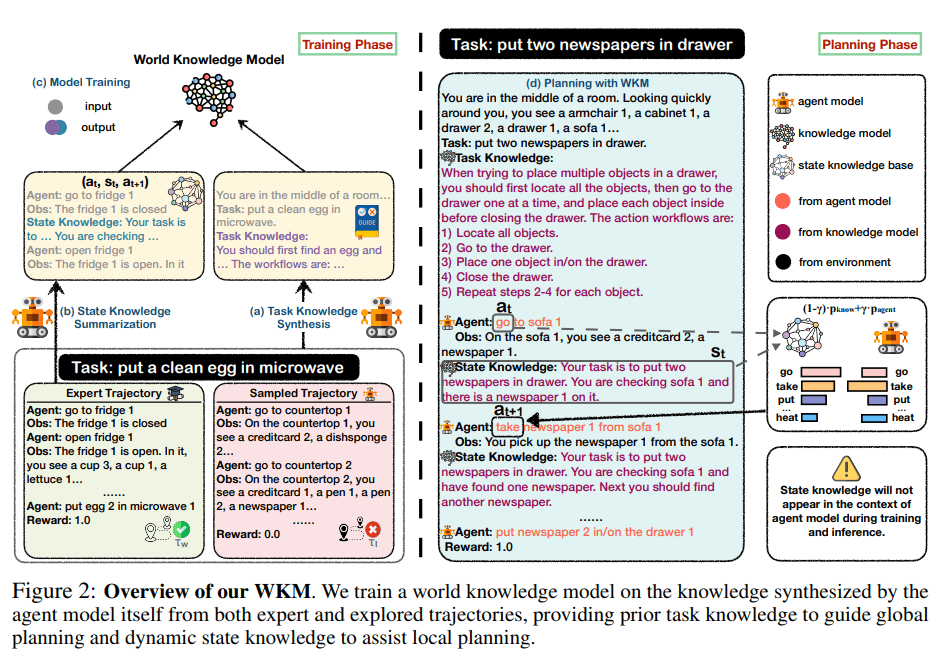
WKMとは、人間が物理環境を認知するメンタルモデルを模倣したもので、事前知識と動的な変化の両方を組み合わせることでエージェントがより正確かつ効率的にタスクを遂行できるようにしたモデルです。
実験の結果、WKMを導入したエージェントは、従来のモデルと比較して有意に高いパフォーマンスを示しました。
さらに、WKMがLLMエージェントによる無意味な試行錯誤や幻覚的行動を軽減できることや、弱いWKMでも強いLLMをガイドできることなどが明らかになりました。
出典:https://arxiv.org/pdf/2405.14205
最後まで読んでいただきありがとうございます。
今回は、言語モデル評価のベストプラクティスとオープンソースライブラリ Language Model Evaluation Harness (lm-eval) を紹介、LLMによる財務諸表分析は人間のアナリストを超えるか?、LLMエージェントに世界知識モデルを導入する の3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













