

メルマガ登録
ベストなDXへの入り口が
見つかるメディア


-
テーマ
から探す -
技術
から探す -
業界・事例
から探す -
関連トレンド
から探す
ベストなDXへの入り口が
見つかるメディア
テーマ
から探す
技術
から探す
業界・事例
から探す
関連トレンド
から探す

緯度経度などの位置情報を表すデータを含んだデータセットである「地理データ」。この「地理データ」を分析・活用するための前段として、「地理データの分析で何ができそうか」というイメージを掴んでいただけるよう、地理データの基礎的な概念や処理フローを解説したブログです。
こんにちは。アナリティクス本部デジタルソリューションサービス部の大道です。
突然ですが、皆さんは地理データに興味はありませんか?
もしかしたら、地理データに触ろうとしたけど、「座標系」など聞きなれない用語が出てきて難しい、ファイルフォーマットが多くあって扱い方がわからない、どんなツールでどんな分析をしたらよいのかわからない、などといった理由で諦めた方もいるかもしれません。
今回は、そのような方の諦められない気持ちに応えるため、地理データに関する内容をブログで紹介します。ニューヨーク市のシェアバイクのデータやオープン地理データを題材に、基礎的な地理空間分析についてお話しさせていただきます。この記事を読んでいただき、地理データ特有の用語や扱い方を掴んでいただければと思っていますので、少し長いですが、最後までお付き合いいただけると幸いです。
以下の表に記載のとおり、ニューヨーク市内のシェアバイクの利用実績、店舗、道路、標高を表すオープン地理データを扱います。「べクター」「ラスター」「Point」「Linestring」「Polygon」「座標参照系」「EPSG」などの用語は聞き慣れないかもしれませんが、表の後に説明しますので、ご安心ください。


ここで、地理データの種類と座標参照系の2点について説明します。
まず、地理データの種類についてですが、地理データはベクターデータ(Vector data)とラスターデータ(Raster data)の2つに大別できます。それぞれ以下のような特徴があります。
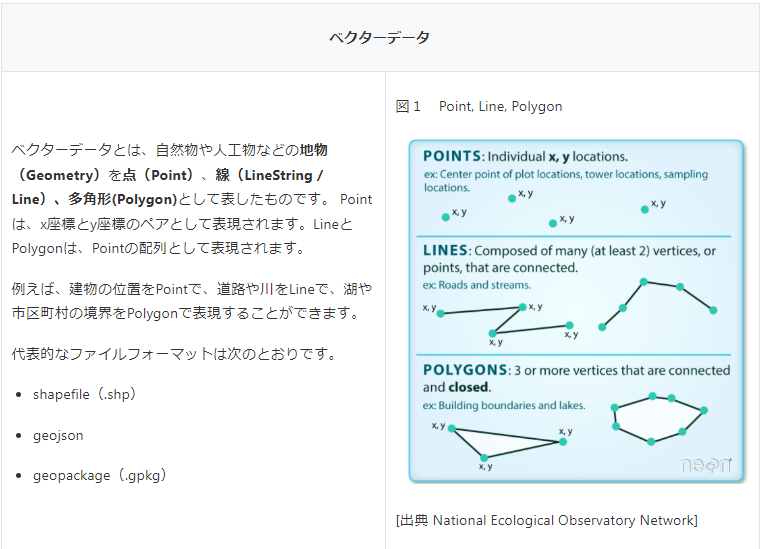

次に、座標参照系(Coordinate Reference System, CRS)について説明します。 ベクター/ラスターデータともにx座標、y座標という位置情報を含んでいます。そうした位置情報が何を基準にどのような方法で表されているかを定義しているのが座標参照系です。時代、地域により地球を表す楕円体の中心点や回転軸が異なっていたり、地図の利用目的に応じて投影法や対象地域が選択されたりするため、世界では様々な座標参照系が使用されています。EPSGコードは座標参照系を特定するためのコードです。
複数の地理データを描画したり、地理空間的な処理を施したりするためには、座標参照系を統一する必要があります。そのため、最初に、データ定義書をよく読むなどして座標参照系を確認することが重要です。
地理データを分析するためのツールはいろいろあります。今回は次のようなツールを適宜使い分けて分析を行いました。データや分析要件によって、ベストな分析環境は変わりますので、あくまで参考程度にご覧ください。
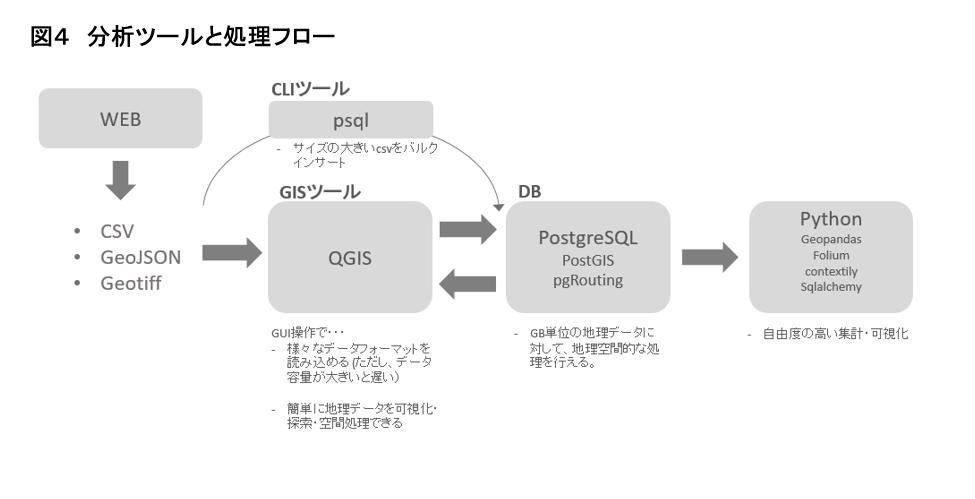
QGISは、GUI操作を基本とする地理情報システムです。PostgreSQLはRDBMS(リレーショナルデータベース管理システム)であり、PostGISは地理データを扱うための、pgRoutingは経路探索を行うためのPostgreSQLの拡張パッケージです。Pythonはプログラミング言語で、Geopandasは地理データ分析のためのライブラリです。
ここからは、上述したデータセットを用い、シェアバイクの利用回数に影響しそうな説明変数を作成する過程を通じて、いくつかの地理空間的な分析を紹介します。
地理データを効率的に扱うために次のような前処理を施します。
1. 座標参照系の統一
複数の地理データを扱うとき、座標参照系が異なる場合は、最初の段階で統一しておく必要があります。今回は、EPSG2263の標高データをEPSG4326に変換し、データセットの座標参照系を統一しました。
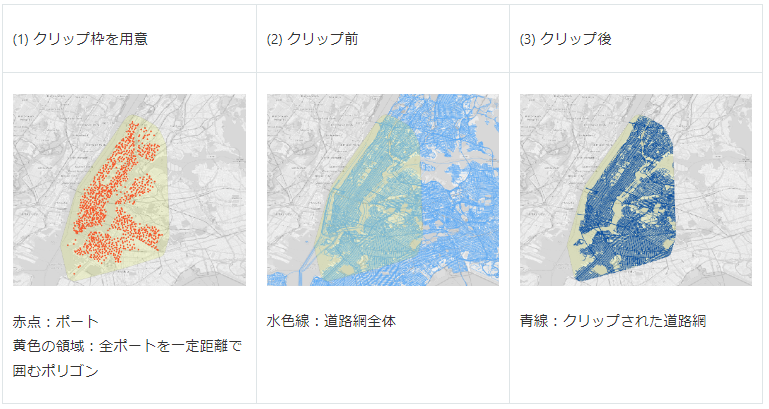
2. クリッピング(clipping)
クリッピングとは、枠となる地物を使い、別の地物から必要な範囲を切り取る処理のことです。これにより地物のデータサイズを減らし、後続の空間処理にかかる時間を削ることができます。今回、ニューヨーク市全体の店舗、道路網、標高データを入手していますが、シェアバイクのポートがあるエリアはマンハッタン島およびその付近に限られているため、その範囲でデータをクリッピングしています。
3. 空間インデックスの作成
通常のデータベースにおいて、効率的な探索を行うためにインデックスを作成することがあります。空間データベースにおいても、地物の座標情報を基にした木構造のインデックスを作成することができます。詳しいことは後述しますが、地理空間分析では、地物同士の重なりの有無を判定する処理を頻繁に行います。そして、地物の数が多いとき、すべての組合せについてしらみつぶしに探索すると、計算量が膨大となり、現実的な処理時間に収まりません。そのため、事前に空間インデックスを作成しておくことが必須となります。代表的な空間インデックスの構造としてR-treeがあります。PostGISには通常のインデックスと同じように、こうした空間インデックスを作成する関数が用意されています。
4. ラスターデータの空間解像度の変更
標高データは、各ピクセルの1辺が1フィート(約30.4㎝)と短く、解像度が高いため、データサイズが3GBを超えています。不必要に解像度が高いデータを使うと、記憶容量が取られる上に、計算時間もかかります。そこで、今回の分析では、データサイズが1GB未満になるように解像度を下げる処理を行いました。
ここから地理空間的な処理を施していきます。最初に利用回数が多いポートが地図上でどのように分布しているかを確認してみましょう。
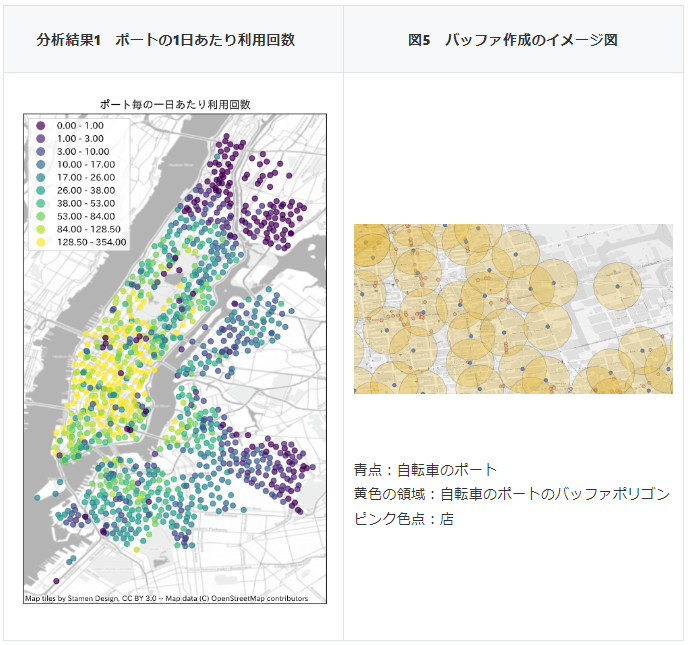
分析結果1を見ると、タイムズスクエアなどがあり、商業施設や店舗が密集しているミッドタウンマンハッタン付近にあるポートの利用回数が多いことが分かります。もしかしたら商業施設が多いエリアはシェアバイクの利用回数が多くなる傾向があるかもしれません。この仮説について、Open Street Mapから取得した店舗の位置情報を使って検証してみます。
ポート付近の商業の指標を表す指標として、ポートから一定距離内にある店舗数を作成してみましょう。最初に、ポートを表すPointから一定の半径を持つ、ほぼ円形のPolygonを取得します。そして、Polygon内に存在するPoint数をカウントします(図5参照)。このように、ある地物から等距離にある領域を作成することをバッファを取る(buffering)と言います。
また、地物同士の位置関係を基に属性テーブルを結合することを空間結合(Spatial Join)と言います。図6の例では、Polygon内に存在するPointの属性テーブルを結合しています。結合してできたテーブルにおいて、ポリゴンIDをキーとして、ポイントの各属性を集計することで、新たな変数を作成することができます。シェアバイクの例で言えば、バッファポリゴンと結合した店舗のポイントのID数をカウントすることにより、自転車ポートから一定範囲内の店舗数という変数を作成することができます。
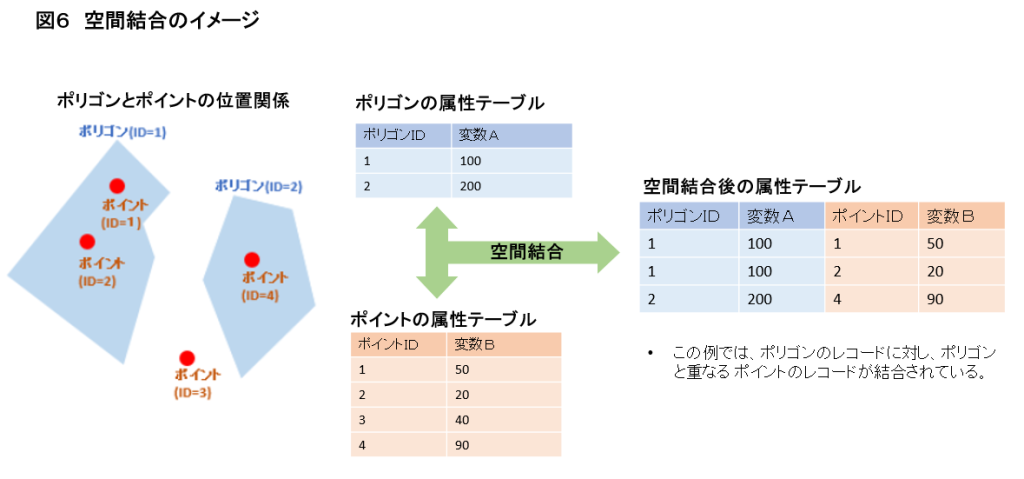
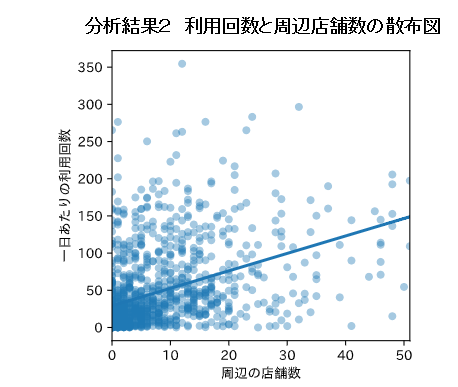
さて、一日あたり利用回数と周辺店舗数の散布図を描くと分析結果2となり、ピアソンの相関係数は0.40でした。利用回数と周辺店舗数には弱い正の相関があることが分かりました。
自転車ポートの利用回数に対し、周辺店舗数は影響していますが、その程度は限定的なようです。散布図からは、周辺店舗数が少なくても利用回数が高いポートが存在することも読み取れます。
次に、道路ネットワークデータを扱ってみましょう。ここでは、道路上を移動した場合に2点間がどのくらい離れているのかを表す変数を道路ネットワークから作成した上で、ルートごとの利用回数と距離との関係を見てみます。
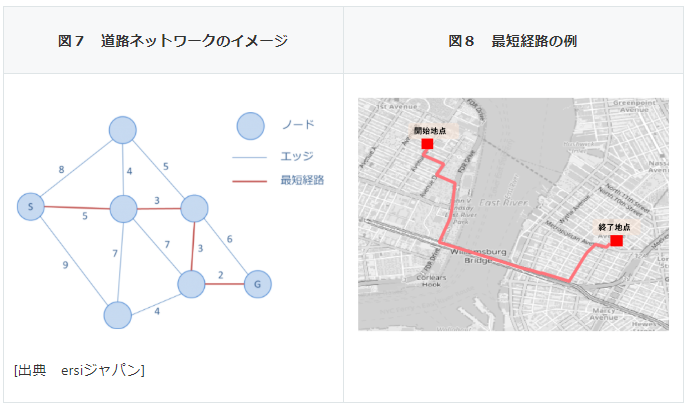
道路ネットワークデータは、網の目のようにつながりあった道路を、図7のようにノードとエッジから構成されるトポロジーとして表現したものです。エッジに相当するのが道路であり、ノードに当たるのが道路同士がつながる交差点だとイメージするとわかりやすいと思います。それぞれのエッジには、数値が付与されていますが、これはエッジを移動する際にかかるコストを表しています。例えば、単純にノード間の距離をコストと考えることができます。
このような道路ネットワークを使って、あるノードから別のノードまでの最短経路を探索することができます(図8参照)。経路探索のアルゴリズムはいろいろとありますが、ここではダイクストラ法による最短経路探索を行いました(アルゴリズムの詳細は割愛させていただきますが、詳しく知りたい方は「最短経路探索」「ダイクストラ法」などのキーワードで検索してみてください)。
最短経路を特定できたら、最短経路を表すLinestringを作成し、その距離を算出しました。ルートの距離のヒストグラムは分析結果3、ルートの距離と利用回数の散布図は分析結果4のようになりました。
ルートの距離のヒストグラムを見ると、3㎞~10㎞の範囲の度数が高いことが分かります。一方、距離と利用回数の散布図を見ると、だいたい5㎞以下のルートの利用回数が多く、10㎞以上になると利用回数はほどんどないことがわかります。シェアバイクの利用は、5㎞以下の利用で大半が占められていると考えてよさそうです。
今回は、道路ネットワークデータを用いて経路探索を行う処理しかしていませんが、道路ネットワークデータの活用方法は他にもたくさんあると思います。例えば、エッジとなる道路ごとの利用回数を重みとし、ネットワークの中のコミュニティを検出をするという分析も有用かもしれません。
最後に、ベクターデータとラスターデータを組み合わせる処理をご紹介します。今回は、ラスターデータである標高数値モデルから、ベクターデータであるルートに対し、標高の値を付与し、傾斜に関連した変数を作成してみます。
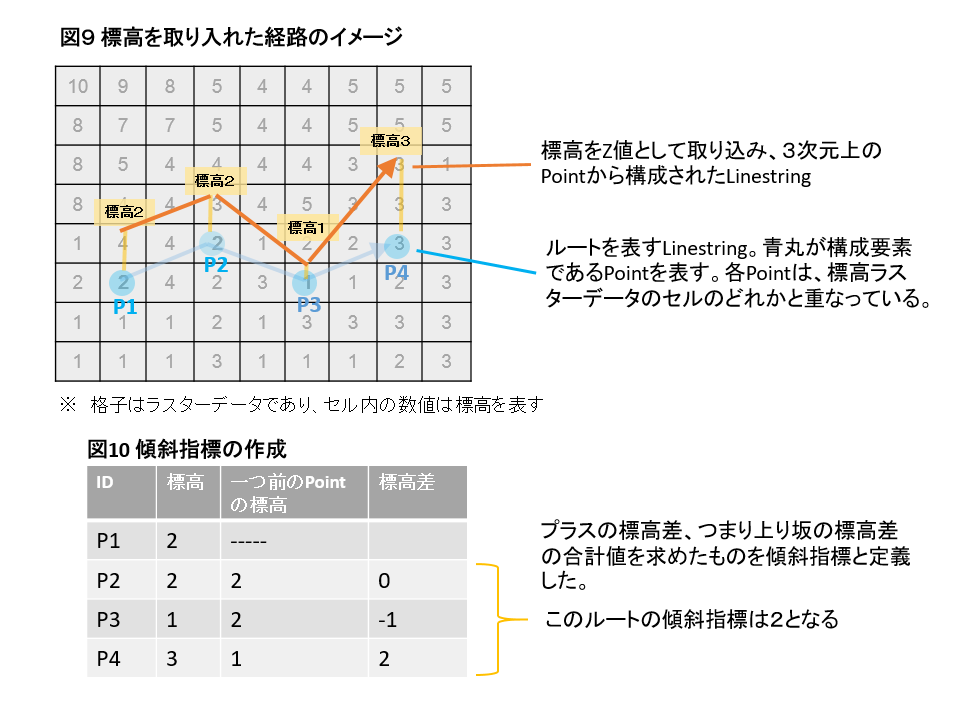
具体的な処理のイメージは図9のとおりです。ルートの最短経路を表すLinestringの構成要素である各Pointと、標高数値モデルのセルを空間結合し、位置が重なったセルの標高をPointに付与します。このとき、x座標値、y座標値を持つPointがZ座標値として標高値を取り込み、LineStringが平面ではなく立体空間に存在することを表現した形に変えます。
その上で、各ルートについて、構成要素のPoint群からZ値を抜き出し何らかの集計をすることで、経路の傾斜と関連した変数を作成することが可能になります。傾斜指標の作り方はいろいろあると思いますが、とりあえず今回は、図10のように「経路上のポイントの標高差がプラスである(つまり登坂である)場合にその合計値をとる」という方法で傾斜を表す変数を作成してみました。
ルートの傾斜指標のヒストグラム及び利用回数との散布図を描くと次のようになりました。

傾斜指標は経路上の登坂の標高差の合計値であり、単位はメートルにしてあります。分析結果6から、傾斜指標の値が増えると、利用回数が少なくなる傾向がうかがえます。自転車で坂道を上るのを避ける傾向があるのは納得できることですね。一方で、傾斜指標が50m以下であれば、利用回数は一定程度あることが分かります。傾斜指標の作り方は改善の余地があるでしょうが、こうした標高数値モデルから生み出した知見はポートの設置場所を検討する際に役に立つかもしれません。
余談になりますが、最近は Google Earth Engine など世界中の衛星画像・リモートセンシングデータを扱うプラットフォームが登場しており、様々な種類のラスターデータを比較的容易に、無料で入手できるようになっています。ラスターデータをビジネスで扱うニーズは今後増えるかもしれませんね。
今回は、シェアバイクやオープン地理データを題材としながら、地理データの基礎的な概念や処理をご紹介しました。本記事から「地理データ分析で何ができるのか」イメージを掴んでいただき、ビジネスに活用していただけたら幸いです。地理データ分析による新しい知見がビジネスに大きな貢献をもたらすかもしれません。ご興味を持たれた方はぜひ地理データの活用を始めてみてください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













