メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/6/6時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

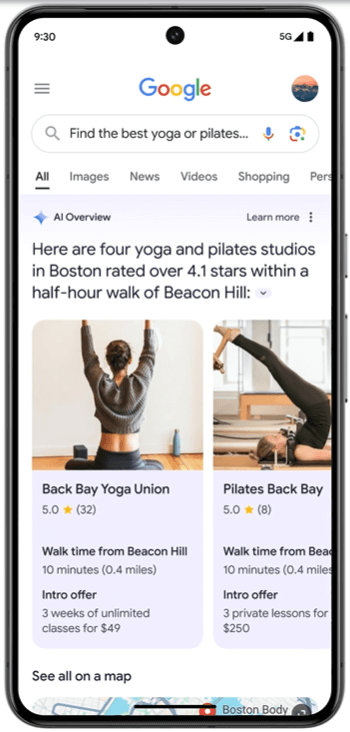
みなさんはGoogle検索の AI Overview という機能を使ったことはありますか?AI Overview は、生成AIを用いてGoogleの検索結果の要約を生成する機能です。似たようなサービスにMicrosoftの Bing AI があります。
下図のように検索窓に質問文を投げると、瞬時に回答文が生成されます。
日本語にも対応していますので、もし興味があれば一度使ってみてください。
いくつもウェブページを自分で開かずとも欲しい情報が手に入るのはとても便利ですが、一方でもっともらしい嘘をつき(ハルシネーションと呼びます)誤回答をでっちあげてしまうのが課題でした。
【関連記事】生成AIをビジネス活用する上で押さえるべき8つの評価観点
特に、人間がまともに取りあわないような意味のない質問に回答したり、または風刺的な回答を行ってしまうような事例が報告されていました。
例えば「私は何個の石を食べるべきですか?」という無意味な質問に真面目に答えてしまったり、「接着剤を使ってチーズにピザをくっつける」というアドバイスを生成してしまうなどの例が挙げられています。
Googleはこれらの課題に対し、風刺的やユーモアのあるコンテンツを含めることを制限して、無意味なクエリを検出するようにして対応することを発表しました。
これらの改善で本当にハルシネーションが無くなるかは今後ユーザーが使って確かめていくしかありません。
ユーザーが目視で情報を取捨選択できる検索とは異なり、質問への回答という形式で出てくる AI Overview やその他チャットボット形式のサービスに対してはどうしてもユーザーの期待値やエラー許容度が厳しくなる傾向にありそうです。今の技術では、得られた情報が誤っている可能性を常に考えながら上手に付き合っていけるとよいですね。
出典:https://blog.google/products/search/ai-overviews-update-may-2024/
大規模言語モデル(LLM)を広範なタスクに使っていくためには出力の信頼性担保が不可欠ですが、基本的にLLM単独では自分の回答にどれほど自信があるかを表現しません。
今回ご紹介する論文ではLLM自体を訓練し、その結果としてLLM自身に信頼度を表現させるアプローチをとっています。概要をご説明します。
LLMの信頼性を評価するために、これまでの研究では、プロンプトベースでのアプローチ(特定のプロンプトを使って信頼度スコアを生成。または同じ質問への回答を複数回行わせることで、回答の一貫性を信頼度の指標とする)、またはトレーニングベースのアプローチ(専用のデータセットを構築し、ファインチューニングを通じてLLMに信頼度を表現するように指導)を使ってきました。
しかし、プロンプティングベースのアプローチは性能が十分に良くなく、トレーニングベースのアプローチは二値的または不正確なグループ分け程度のレベルの信頼度推定に留まることが課題でした。
本研究では、LLMに信頼度を正確に推定できるよう学習させるトレーニングフレームワークである「SaySelf」を提案しています。
SaySelfは大きく、①学習用データセットを生成し、ファインチューニングを実施する ②データセットを用いて強化学習 の2段階で構築されています。
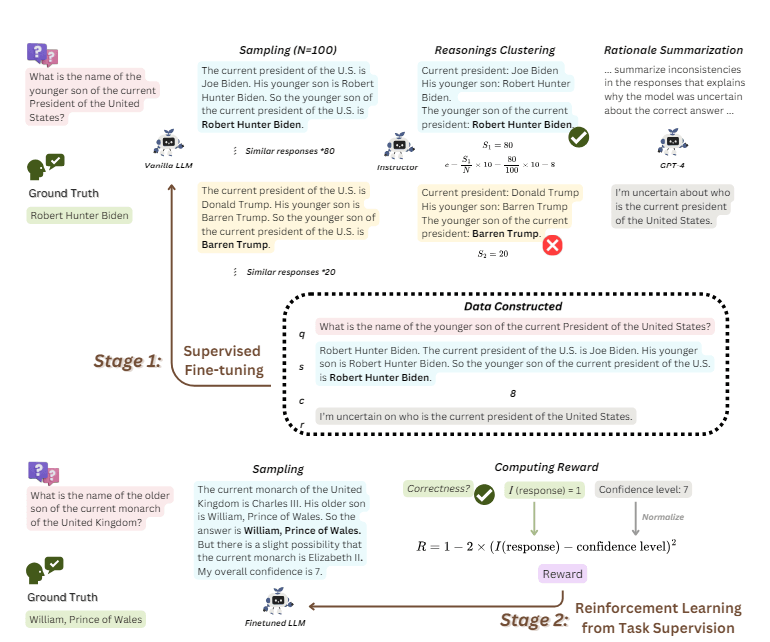
このアプローチのポイントは、単にLLM をトレーニングして出力を生成するだけでなく、LLM自身の回答に理由付けしたり正当化したりできるようにすることで、ユーザーがモデルの信頼性と推論のレベルをよりよく理解できることです。
このアプローチにより LLM の信頼度推定能力が改善され、より信頼性が高く透明性の高い言語モデルにつながることを実証しています。
なおコードは全て以下に載っているとのことです。興味があればぜひご覧ください。
【参考】SaySelf|GitHub – xu1868/SaySelf: Public code repo for paper “SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales”
出典:https://arxiv.org/abs/2405.20974
2つ目のトピックでも触れましたが、LLMを信頼して使っていくためにはモデルの出力に対する評価が不可欠です。この評価をスケーラブルに行っていくには人手で行うのではなく、AIを用いて評価するのが最も望ましいかたちです。
この評価をLLMに行わせるにあたって、評価を行うモデルが公正であることを証明するには、モデルの中身を誰でも知ることのできるオープンソースのモデルである必要があります。
というのもOpenAI社の ChatGPT を始めとするクローズドモデルは、訓練に用いたデータセットも実装のためのコードも非公開です。
現在高精度と言われているモデルの多くはクローズドモデルですが、果たしてクローズドモデルを使った評価は本当に公正だと証明できるでしょうか?
今回ご紹介する PROMETHEUS 2 は、他の言語モデルの出力評価に特化したオープンソースモデルです。簡単に概要をご説明します。
従来のオープンソースのモデルを用いた評価モデルには以下のような課題がありました。
*「直接評価」とは、モデルの生成結果を直接評価する手法。
「ペアワイズランキング」とは、いくつかのモデルのアウトプットを比較して優劣をつける評価手法です。
直接評価とペアワイズ評価の両方に対応できるように訓練されたモデルが PROMETHEUS 2 です。
このモデルは上記課題を解決し、人間やクローズドモデルであるGPT-4と類似した評価スコアを出すことができました。
モデルの出力を正しく評価できることで、業務にLLMを適用できる範囲を安心して広げることができそうです。PROMETHEUS 2 を用いた評価モデルが一般的になる日が来るかもしれません。
出典:https://arxiv.org/abs/2405.01535
最後まで読んでいただきありがとうございます。
今回は、Googleの AI Overview ハルシネーション防止策、LLMの信頼性を推定させるトレーニングフレームワーク SaySelf のご紹介、言語モデルの出力評価に特化したモデル PROMETHEUS 2 のご紹介、の3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説