



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス本部の三浦です。
本日はSkip-thoughtというアルゴリズムを用いた、テキストの数値ベクトル化についてご紹介したいと思います。
Skip-thoughtとはRyan Kirosらによって2015年に考案された、文書中の文の表現を数値ベクトル化する、深層学習のアルゴリズムです。アルゴリズムの特徴として教師なし学習であることが挙げられ、学習する際にラベル付けやアノテーションされたテキストは必要ありません。順序付けられた文で構成された文書*1さえ存在すれば、それを元に学習を行いモデルを構築することが可能です。
数年前に単語をベクトル化できるWord2vec*2が話題になりましたが、Skip-thoughtは単語ではなく文やフレーズをベクトル化すると思っていただくと、わかりやすいかと思います。
なお本ブログは、ある程度RNNやLSTMについて理解していることを前提としています。
RNNやLSTMについての説明は、
などに詳しくまとまっていますので、ご存じない方はまずそちらをご覧ください。
本文中では、
と順番に説明します。最後にWikipediaの文書の数値ベクトル化を行い、ベクトル同士のコサイン類似度を計算することで、入力文に類似した文の検索を行います。
説明は少し長くなりますので、Skip-thoughtでどんなことができるのか知りたい!という方は、「類似した文の検索」という項目からご一読ください。
Skip-thoughtは文のベクトル化を行いますが、そのアルゴリズムはWord2vecとは大きく異なります。Word2vec(skip-gram)では入力単語に対して、周辺に位置する単語を予測することで、単語同士の共起関係を学習します。
一方でSkip-thoughtは、エンコーダー-デコーダーと呼ばれる形式を取っており、入力文の単語の系列をエンコードし、前後の文の単語を出力として順番に予測します。Skip-thoughtでは文とその前後の文の共起関係を学習することで、文のエンコード結果である中間層の値を数値ベクトル(Skip-thoughtベクトル)として得ます。
従来の手法ではWord2vecで得られた単語ベクトルの和を取るなど、単語ベクトルの合成方法を工夫することで文やフレーズのベクトルを得ていました。しかし、Skip-thoughtは文をエンコードすることでベクトル化を行っており、その意味でSkip-thoughtモデルの学習は、単語ベクトルの合成方法自体について学習していると言うことができます。
言葉だけで説明してもわからないと思いますので、論文の実装を元にSkip-thoughtのネットワーク構造を図で説明したいと思います。
「5月になった 今日も晴れだ 洗濯が捗る」という3つの文で構成される文章があるとし、いま入力文が「今日/も/晴れ/だ」であるとします(スラッシュは分かち書きの結果を表します)。このときSkip-thoughtでは、前の文「5月/に/なっ/た」と後ろの文「洗濯/が/捗る」を次のように予測します。

図の各矢印は重み行列を表し、色が同じ矢印間では重み行列の値が共有されています。
Skip-thoughtモデルは図のように、RNNを用いた入力文のエンコーダーと、前後の文を出力する2つのデコーダーで構成されます。
このネットワーク構造について、エンコーダーとデコーダーについてそれぞれ説明します。

図のカッコ内は、論文内で設定された重み行列のサイズを表します。
エンコーダーでは、one-hotで表現された単語を入力として受け取り*3、単語のベクトル(以下、単語embeddingと呼びます)化を行います。また単語embeddingを入力とし、隠れ層のノードにGRU(図中の塗りつぶされたノード)を用いたRNNにより、入力文のエンコードを行います。入力文の単語をRNNに順次与え、最後の単語が入力された次の時点の隠れ層の出力値が、Skip-thoughtベクトルとして得られます。
入力層 → 単語embedding層の重み行列は、エンコーダーとデコーダーで共通のものを用います。また入力層の次元は20,000しかありませんが、テキスト中の出現回数が上位20,000単語*4に入力層のノードを割り当て、あまり出現しない単語は未知語としてまとめて扱います。
RNNの隠れ層のノードとして用いられるGRUはLSTM同様の働きをしますが、ゲート数が2つとLSTMより少ないという特徴があります。通常のRNNで必要な重み行列だけでなく、GRUの2つのゲート制御用にも重み行列は必要です。図では1本の矢印で示していますが、隠れ層 → 隠れ層の重み行列と単語embedding層 → 隠れ層の重み行列は、それぞれ3つずつ存在します。
ここではGRU自体の詳細は述べませんので、GRUについて気になる方は上で紹介した「わかるLSTM」の説明をご覧ください。

デコーダーでは、入力文をエンコードして得られたSkip-thoughtベクトルを隠れ層の初期状態として、エンコーダー同様GRUを用いたRNNにより前後の文の出力を行います。
入力層から単語embedding層までの流れは、エンコーダー時と同様です。
RNNの出力隠れ層と出力層間は全結合となっており、出力層の活性化関数はsoftmaxで、各ノードに対応する単語の出現確率を出力します。RNNの重み行列(図中の水色と紫の矢印)は2つのデコーダー間で共有されませんが、全結合層(えんじ色の矢印)の重み行列は共有されます。
目的関数は次の式で与えられます。
$$\displaystyle \sum_t \log P\left(w_{i+1}^t | w_{i+1}^{\lt t}, {\bf h}_i\right) + \sum_t \log P\left(w_{i-1}^t | w_{i-1}^{\lt t}, {\bf h}_i\right) $$
ここで \( {\bf h}_i \) は入力文のエンコード結果、つまりSkip-thoughtベクトルを表します。入力文のSkip-thoughtベクトル、およびその前後の文の出現単語を与えた際の、出力単語の確率の対数の和が最大化されるよう最適化が行われます。
以上、簡単にではありますが、Skip-thoughtモデルのネットワーク構造を紹介しました。
ちなみにエンコーダー-デコーダー形式をとる同様のモデルに、機械翻訳で有名なSequence-to-Sequenceが存在します。Skip-thoughtがSequence-to-Sequenceと異なる点として、
などが挙げられます。
モデルの適用時は入力した文のエンコード結果を、Skip-thoughtベクトルとして得ます。目的がSkip-thoughtベクトルを得るだけならば、デコーダーは必要ありません。
学習時に入力層のノード数は20,000しか用いず、出現回数上位の20,000単語以外は未知語として扱いました。そのためモデル適用時の入力文に対しても、多くの単語が未知語として扱われ、同一の単語embeddingが与えられてしまいます。
この問題を防ぐために、Word2vecなど別の方法で学習した単語embeddingモデルを用いて、このモデルで得られる単語embeddingから、Skip-thoughtモデル内の単語embeddingへのマッピングを行います。
単語embedding間のマッピングを行うのには、異なる方法により得られた単語embeddingであっても、それぞれの空間内での位置関係は類似しているという背景があります。
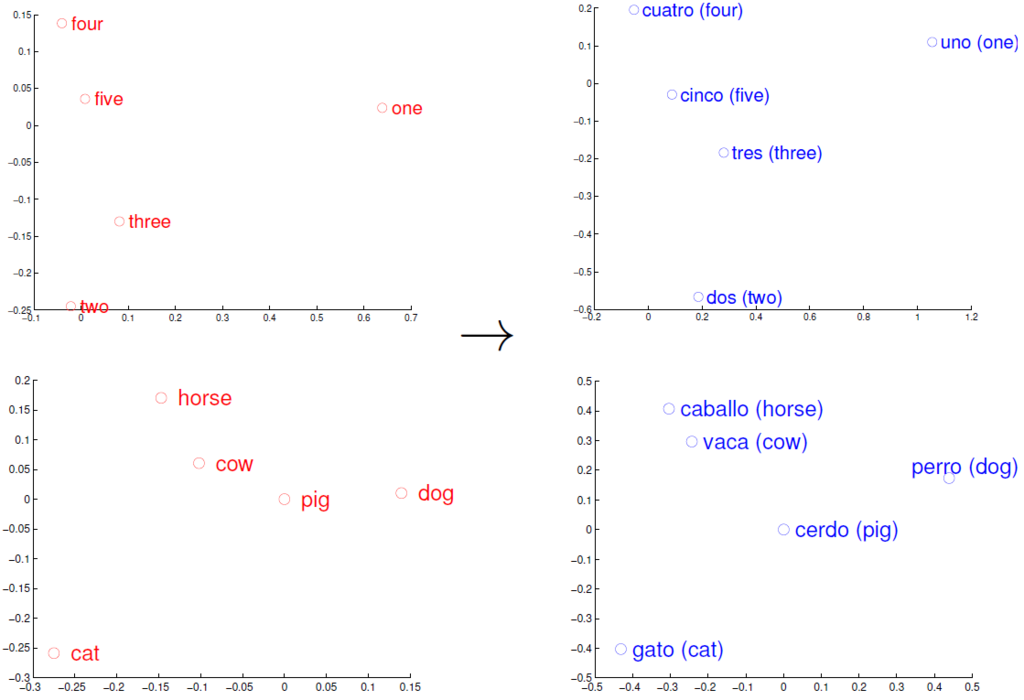
(図は Mikolov et al., Exploiting Similarities among Languages for Machine Translation., 2013 より引用)
上の図は左が英語のWord2vec、右がスペイン語のWord2vecにより得られた単語embeddingを、可視化のため2次元に圧縮して回転させたものです。英語とスペイン語という異なる言語間であっても、単語同士の位置関係が類似していることがわかります。それぞれの単語間の距離は各言語でほぼ共通であると考えられるため、単語間の共起関係を学習したWord2vecにおいても、位置関係がある程度保たれています。
図では可視化のために回転などを行っていますが、いま行列を用いた線形変換により単語embedding同士を対応付けます。
事前に学習したWord2vecの単語embeddingを \( {\bf v} \), Skip-thought内の単語embeddingを \({\bf v’} \)と置きます。このとき \({\bf v’} = {\rm W}{\bf v} \)となる射影行列 \( {\rm W} \)を、両モデルに共通して含まれる単語*5のembeddingを用いて、リッジ回帰により学習します*6。単語embeddingの次元は同じでなくても構いませんが、変換後の単語embeddingが得られなくなるので、事前学習したWord2vecの語彙数は多くなければなりません。
回帰により得られた行列 \( {\rm W} \)を用いて頻出単語以外の単語をマッピングすることで、それらの単語のSkip-thoughtモデル空間内の単語embeddingが与えられ、RNNの入力とすることが可能になります。
それでは実際にテキストデータを用いて、Skip-thoughtモデルの学習を行いたいと思います。
あいにく手持ちのデータが存在しないため、ここでは日本語版Wikipediaをダウンロード*7し、前処理を行ってコーパスとして用います。
データのダウンロードは「Wikipedia:データベースダウンロード」ページ内に存在するリンク先から行います。ページのタイトルのみ、概要のみなど、取得できるファイルの種類は多数存在するので、ダウンロードページ内の記載やこちらのページをご覧ください。
ここでは全ページの本文テキストを含む jawiki-yyyymmdd-pages-articles.xml.bz2(yyyymmdd にはデータがダンプされた日付が入ります)をダウンロードして用います。容量が2.3GBあるため、ダウンロードには数十分かかります。
ダウンロードしたファイルはXMLファイルとなっており、本文のテキスト以外にもさまざまなタグを含みます。WP2TXTというツールを用いてこれらのタグを除去し、テキストへの変換を行います。
WP2TXTではタグ除去時のオプションをいろいろと指定できます。
一例を挙げると、
--no-list: 記事内のリストを除去--no-heading: 各セクションの見出しを除去--no-title: 記事のタイトルを除去--table: 表を除去しないなどです。
いま本文テキストと関係ない記事内の表やリスト、各セクションの見出しは除去しておきます。
タイトルは記事内容の識別に必要なので残しておきます。$ wp2txt –no-list –no-heading -i jawiki-yyyymmdd-pages-articles.xml.bz2 $ cat jawiki-yyyymmdd-pages-articles.xml-* > jawiki-yyyymmdd-pages-articles.txt
上記コマンドにより、1時間半程度かけてタグの除去を行います。
出力ファイルは複数生成されるので、 cat で1ファイルにまとめておきます。
WP2TXTを用いてタグを除去しても、テキスト中に記事のタイトルや画像ファイルなどのマークアップが含まれているため、これらの除去を行います。
詳しくは説明しませんが、前処理の方針としては以下のとおりです。
以上により句点単位で1行に分割し、1行を一つの文としてコーパスの作成を行います。また記事タイトルは抽出して別ファイルとし、Skip-thoughtのアルゴリズムを考慮して、3文未満で構成される記事については今回は除去します。
作成されたコーパスのサイズは、
| 記事数 | 文数 | 単語数 | ユニーク単語数 |
|---|---|---|---|
| 861,893 | 16,165,019 | 476,761,220 | 2,277,912 |
となります。
ちなみに文数の多い記事は、
| 順位 | 記事タイトル | 前処理後の文数 |
|---|---|---|
| 1 | 千夜一夜物語のあらすじ | 2,737 |
| 2 | 三木武夫 | 1,834 |
| 3 | モルゴス | 1,709 |
| 4 | 蒋経国 | 1,621 |
| 5 | 銀河英雄伝説の戦役 | 1,551 |
などです。
Skip-thoughtは論文の著者により、GitHub上にその実装が公開されています。
著者らの実装はTheanoを用いていますが、TensorFlowでの実装も存在します。
ここでは著者らのレポジトリをクローンして学習を行います。
モデルの学習および、適用時に用いるファイルは全て training ディレクトリ内に存在します。training ディレクトリ内にある各ファイルの内容を説明すると、
homogeneous_data.py: ミニバッチの作成などlayers.py: GRUなど各層のノードの振る舞いを定義model.py: Skip-thoughtのネットワークを定義optim.py: Adamなど最適化方法について定義tools.py: モデル適用時に使用train.py: モデル学習時に使用utils.py: 重み行列の初期化方法などを定義vocab.py: 単語辞書の作成であり、基本的な流れとしては
vocab.py により単語の出現回数をカウントし、出現単語の辞書を作成train.py によりモデルの学習を実行tools.py により学習したモデルをロードし、新規の文に対してSkip-thoughtベクトルを付与となります。
以下、GitHub上のREADMEに沿って順に説明します。
ハイフンを含むとimportが面倒なので、レポジトリ名を適当な名前にまず変更する必要があります(ここでは sent2vec とします)。その上で以下の説明では、
from sent2vec.training import train, vocab, toolsしていることを前提とします。
また学習に用いるデータは、あらかじめ以下のような分かち書きされた文のリストにしておく必要があります。
X = [u'5月 に なっ た', u'今日 も 晴れ だ', ...]プログラム実行の際には、Theanoの設定が必要となります。
こちらのページにあるように、
$ THEANO_FLAGS='floatX=float32,device=gpu0,lib.cnmem=0.5' python <myscript>.py
or
$ THEANO_FLAGS='floatX=float32,device=gpu0,lib.cnmem=0.5' jupyter notebookなどとします。device で計算に使用するデバイスの指定を、 lib.cnmem でメモリサイズの割合を指定します。
入力データから単語辞書の作成を行い、保存します。
worddict, _ = vocab.build_dictionary(X)
vocab.save_dictionary(worddict, _, loc='dictionary.pkl')ここで worddict は単語がキー、出現回数の順位が値となった辞書です。loc で保存先のパスを指定します。
次に
train.trainer(X, dictionary='dictionary.pkl', saveto='model.npz')でモデルの学習を行います。
train.trainer で指定できるオプションはいくつかありますが、主なものを挙げると
dim_word (620): 単語embeddingの次元dim (2400): Skip-thoughtベクトルの次元max_epochs (5): エポック数grad_clip (5): 勾配の規格化定数*9n_words (20000): 入力層と出力層のノード数maxlen_w (30): 1文あたりの最大単語数(タイムステップ数)saveto: モデルの保存先dictionary: ステップ1で作成した辞書のパスとなります(カッコ内はデフォルト値)。
ここでは計算時間短縮のため、 dim_word=300, dim=1200, max_epochs=1 とします。 また今回使用するWikipediaのコーパスは、1文あたりの平均単語数が29.5±18.1で、90%タイル点で52.0単語となっているため、 maxlen_w=50 と設定します。
上記の設定で学習をTesla K40c上で行ったところ、計算終了まで54.7時間(~2.3日)かかりました。
今回1エポックで学習を行いましたが、10エポックで学習を行うと単純計算して23日もかかることになります。計算時間はその他コーパスサイズ、各層のノード数 dim_word, dim, n_words, タイムステップ数 maxlen_w などに依存するので注意が必要です。
新規の入力文に対してSkip-thoughtベクトルを得る際は、 tools.encode を用います。学習時は文を分かち書きしておく必要がありましたが、適用時にはその必要はありません。しかしその代わりに tools.py 内の preprocess 関数を、あらかじめ以下のように書き換えて、日本語に対応させる必要があります。
# tools.py内の書き換え
import MeCab
def preprocess(list_sent):
tagger = MeCab.Tagger('-Owakati')
list_sent = [sent.encode('utf-8') for sent in list_sent] # unicode -> utf-8
list_sent_parsed = [tagger.parse(sent).decode('utf-8') for sent in list_sent]
return [sent.rstrip(' n') for sent in list_sent_parsed]ここではMeCabを用いて分かち書きを行っていますが、学習時と同じ辞書を使う必要があることに気をつけてください。
アルゴリズム紹介時に述べたように、モデルのロード時には事前に学習したWord2vecモデルを必要とします。また、 tools.path_to_dictionary と tools.path_to_model を作成した単語辞書とモデルのパスで置き換える必要があります。
from gensim.models.word2vec import Word2Vec as word2vec
tools.path_to_dictionary = 'dictionary.pkl'
tools.path_to_model = 'model.npz'
embed_map = word2vec.load_word2vec_format(word2vec_model_path, binary=True)
model = tools.load_model(embed_map=embed_map)tools.load_model 時に単語embedding間のリッジ回帰が行われるため、上記コードの実行には数分かかります。以上を行った上で、
vectors = tools.encode(model, [u'ここで入力した文にskip-thoughtベクトルが与えられます。'], verbose=False)と文をリストで与えることで、Skip-thoughtベクトルが文数×ベクトル次元の numpy.array の形式で得られます。
ここでは学習したSkip-thoughtモデルを用いて、Skip-thoughtベクトル間のコサイン類似度を計算することにより、検索クエリとして与えた文に最も類似したWikipediaの文を検索したいと思います。事前学習したWord2vecモデルとして、同じWikipediaのコーパスを用いて学習した、次元数300のモデルを使用します。
まず記事冒頭の 「こんにちは、アナリティクスサービス本部の三浦です。」 をクエリとして与えた際の、類似度が高い文は以下のとおりです。
| 順位 | 記事タイトル | 本文 | 類似度 |
|---|---|---|---|
| 1 | 林家三平 (初代) | 奥さんどうもすいません、三平です。 | 0.799 |
| 2 | チューバッカ弁論 | みなさん、これがチューバッカです。 | 0.779 |
| 3 | 大村小町 | 33歳みんなの妹、大村小町です。 | 0.773 |
| 4 | Friend-Ship Project | ~こんにちは、女優の相楽樹です。 | 0.771 |
| 5 | クリスマスの約束 | つなげてくださったのは小田さんです。 | 0.768 |
「呼びかけ」+「、」+「名前」で高い類似度となることがわかります。
事前学習したWord2vecモデルを用いているということもあり、名前らしき単語がきちんと認識され、Skip-thoughtベクトルに反映されているということがわかります。
ちなみに「~こんにちは、女優の相楽樹です。」の方が類似度が高そうに思えますが、これはテキストの前処理が不完全で、本文にチルダを含んでしまっているためです。チルダを除去した「こんにちは、女優の相楽樹です。」との類似度は0.801となり、1位の文よりもこちらの方が類似度が高くなることがわかります。
次に物理学者の久保亮五氏の名言 「研究会もいいですけど、研究もしたらどうですか。」 を検索クエリとして与えます。
| 順位 | 記事タイトル | 本文 | 類似度 |
|---|---|---|---|
| 1 | 赤報隊事件 | 思想的に世の中を変えたと思っているじゃないですか。 | 0.803 |
| 2 | サマー・ソルジャー | そういうのがいいじゃないですか。 | 0.800 |
| 3 | 東京 (サニーデイ・サービスのアルバム) | そういうほうが盛り上がるもんじゃないですか。 | 0.792 |
| 4 | 張軌 | 越地の人が来るのを期待しているようですが、力不足ではないでしょうか。 | 0.783 |
| 5 | 放送法遵守を求める視聴者の会 | 本当に批判するんだったら、ぐうの音も出ない批判をすればいいじゃないですか。 | 0.781 |
語尾が「じゃないですか。」で終わる文が、高い類似度となっています。4位と5位の文の方が言い回しとしてはクエリに似ている気がしますが、登場する単語がクエリに似ていないために、そこまで類似度が高くなっていないものと思われます。
例えば5位の文を「本当に研究するんだったら、ぐうの音も出ない研究をすればいいじゃないですか。」と、単語を置換することで類似度は0.870まで増加します。また「研究」を「勉強」にすると、クエリとの類似度は0.810となります。
一方で2位や3位の文にはクエリと共通する単語もあまりなく、類似度が高くなる理由がよくわかりません。いま検索クエリと「じゃないですか。」という文の類似度は0.780となるため、そこから下手に単語を追加しないことで、高い類似度をキープしていると考えることができます。
最後に長い文の例として、 「いつの時代でも必ず立ちはだかる逆境に遭遇したとき、その中でも力強く生き抜く、やり遂げる、という意志を持って立ち向かってほしいと願っています。」 をクエリとして与えます。これは当社の社内報に掲載された、代表の佐藤から今年入社した新卒社員に向けたメッセージ中の一文です。
| 順位 | 記事タイトル | 本文 | 類似度 |
|---|---|---|---|
| 1 | 秋元義孝 | だから、成功している時も奢らず、失敗した時も落ち込まず、という風に自分なりに理解しています。 | 0.856 |
| 2 | オリーヴ・トーマス | 私たちは一緒にいることができないというだけの理由で、団らんの時を頻繁には持てないのだと理解しています。 | 0.837 |
| 3 | 八木秀次 (法学者) | 戦争で荒廃した国土を立て直し、かつ、改善していくために当時の我が国の人々の払った努力に対し、深い感謝の気持ちを抱いています。 | 0.837 |
| 4 | ACTION | 例え誰も見てくれていなかったとしても、将来の自分、10年後、20年後の自分が見てくれています。 | 0.837 |
| 5 | 本因妙大本尊 | 衆生の一切の悪因縁を絶ち、終世に一切の至福をもたらす事の出来る大法が秘められているといわれています。 | 0.835 |
そもそもクエリが長い場合、どのような文が似ているのか直感的に把握するのは難しくなります。いま文をベクトル化して類似度を算出しているだけなので、文中のどの部分が特に類似しているかを可視化することはできません。
しかしそのような中でも名言らしき文や、スピリチュアルな文を類似度が高いとして抽出できていることがわかります。これらの文が登場する文脈(前後の文の内容)というものがある程度決まっており、結果として同じようなベクトルになるのではないかと推察されます。
長くなってしまいましたが、いかがだったでしょうか。
Skip-thoughtベクトル同士のコサイン類似度を計算することで、構文・意味的に近い文の抽出が可能となることが理解いただけたかと思います。
今回は類似した文の検索だけに留めましたが、文を数値ベクトル化することで検索の他にもさまざまな場面で応用が可能です。前後の文との関係性を考慮するというアルゴリズムの特性上、会話文などと相性が良いのではないかと思います。
しかし、データが自然言語である必要はありません。アイテムを単語とみなし、1回の購買アイテムを文とみなせばSkip-thoughtを適用できることから、POSデータを用いたマーケティングなどにも応用できるかもしれません。
さまざまな場面に応用できそうなSkip-thoughtですが、デメリットとしては学習に長い時間がかかることが挙げられます。論文中では計算を回せば回すほど良いベクトルが得られるとありますが、数十日計算を実行するのは現実的ではないと思います。
学習を高速化した手法としてFastSentなど後続の手法が次々と考案されており、機会があればここでまたご紹介させていただきたいと思います。
当社は、深層学習などの技術をビジネスに活用するべく、最先端の取り組みを積極的に実施しています。実際のビジネスで、最先端の技術を活用してみたいという方は、ぜひエントリーください!
*1:逆に単文で構成されるTwitterなどは難しいと思います
*2:King – Man + Woman = Queen と表せる例がよく挙げられます
*3:値が0-1ということもあり、図で入力層のノード表記は省略しています
*4:正確には未知語(UNK)とゼロパディング(<eos>)で2ノードは予約されているので、19,998単語となります
*5:したがって回帰に用いるデータ数は、入力層のノード数より少なくなります
*6:ネットワークの学習後に行われます
*7:「フリー百科事典 ウィキペディア日本語版」(http://ja.wikipedia.org/)2017年4月27日12時(日本時間)時点での最新版を取得しました。分析結果記載時の引用も全てここから行っています
*8:半角カナを全角へ、全角数字記号を半角へなどの変換を行います
*9:勾配の2乗和がこの値以下になるよう規格化が行われます
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













