



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/6/13時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

6月13日、SakanaAIから画期的な論文が発表されました。「DiscoPOP」というアルゴリズムについての発表です。
このアルゴリズムを用いてLLMをトレーニングすることにより、人間の介入を最小限に保ったままLLMの精度を大幅に改善できる可能性があるのだそうです。簡単に概要をご説明します。
LLMの出力には差別や偏見、有害な内容などが含まれることがあります。この課題を解決する手法の一つとして、人間の選好に基づいてLLMの出力を最適化する選好最適化(preference optimization)という手法があります。
この手法では損失関数* を人間が任意に設計してLLMをファインチューニングするのですが、この損失関数の組み合わせは膨大に存在し、人間の創造力ではすべてを試すことができません。
*損失関数:機械学習において、予測値と正しい値の間のずれの大きさを表すために使う関数です。損失関数を最小化することでモデルを最適化することができます。
本論文では、この最適な損失関数の発見を人間が行うのではなく、LLMを活用して発見させる方法を提案しました。
具体的に言うと、学習したLLMを用意した評価指標で性能評価し、その結果をもとに新たに損失関数を作成し、実装することを繰り返すことで改善するのだそうです。
そして、この発見プロセスを約100回繰り返した結果生まれたのが、選好最適化アルゴリズム DiscoPOP です。DiscoPOP は様々なタスクにおいて既存の手法を上回る性能を示しました。
一連の研究のコードは以下に公開されています。興味がある方はぜひご覧ください。
【参考】DiscoPOP
なお余談ですが、モデル自体をチューニングする他に、世の中の一部の生成AIサービスではこういった出力を防げるように悪質なプロンプトに応じないような対策(ガードレールと呼びます)を施したり、ユーザーに表示する前に何らかの手段でアウトプットをチェックしたりするような仕組みを用意して品質を担保しています。
【関連記事】LLMにガードレールを適用してビジネスリスクを抑制する
本論文のポイントはLLMを用いてLLMの性能を自己改善できるというアイディアにあります。
AIのシンギュラリティは思っていたよりも間近に迫っているのかもしれません。今後の研究に期待です。
【関連記事】2045年問題とは?シンギュラリティの意味や仕事への影響を解説
出典:
https://sakana.ai/llm-squared
https://arxiv.org/pdf/2406.08414
GitHub というプラットフォームをご存じでしょうか。
世界中の人々がプログラミングコード等を保存・編集・公開できるソースコードサービスで、今や開発者にとっては無くてはならないツールです。
この GitHub から実在する課題を集めて作られた SWE-bench というベンチマークがあります。
実在する GitHubリポジトリ上のIssueから作成された2294問の問題データセットで、人間のプログラマーにとっても難解な問題が揃っているのだそうです。
LLMのソフトウェアエンジニアリング能力を評価するにあたり、この SWE-bench を解かせることがLLMの実務適用の近道となりえます。もしもLLMがこれらの問題を自律的に解けるようになれば、いわゆる自律的なAIエージェントとして人間のエンジニアと同様にタスクを振れるようになります。
近年の論文では、単独のLLMではなく、複数のエージェントを用いたアプローチがいくつも出てきています。
このマルチエージェントのアプローチが実現すれば、モデルが自分たちで役割を分けてタスクをこなせるようになり、人間が指示しなければならない領域が減ることでできることが加速度的に増えていくでしょう。
ただし、マルチエージェントの実現にあたり、以下の課題が指摘されています。
チームの人数が増えると情報伝達がうまくいかなくなる、という点では人間のエンジニアにも似ていますね。
この課題を解決すべく、今回紹介する論文では CodeR というマルチエージェント設計を開発しました。
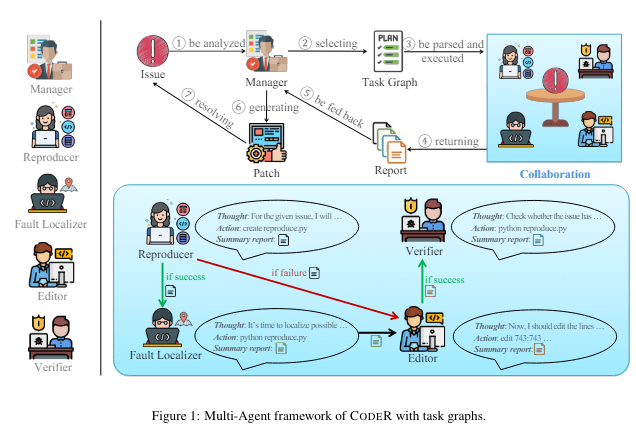
CodeR は、現実世界での人間によるイシュー解決プロセスに着想を得た設計です。
複数の役割を持たされたエージェントが作業を分担し、あらかじめ立てた計画を立てて守りながら進めることで問題解決を進めます。
CodeR に SWE-bench lite(SWE-benchの簡易版)を解かせたところ、1度目で300問中85問(28.33%)正解できたそうです。
まだまだ正解率が低いように感じるかもしれませんが、2ヶ月前にプリンストン大学が開発した SWE-bench に最適化したAIエージェントであるSWE-agent でさえ正解率が最大でも18%だったことを考えると数ヶ月の間に大きな進歩があったとも言えます。
今後の研究により、AIエージェントがチームを組んでタスクを解決できるようになっていけそうです。人間がAIを率いて仕事を任せるような未来は意外と近くに来ているかもしれません。
出典:https://arxiv.org/pdf/2406.01304
この連載でも何度か取り上げているRAGについて、デメリットを軽減する手法がまた一つ提案されました。
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。このハルシネーションという問題を軽減する方法の1つとして、RAGという技術が使われ始めています。
【関連記事】プロンプトエンジニアリング手法 外部データ接続・RAG編
RAGは「検索」と「生成」の大きく2段階で構成されています。今回取り上げるのは「検索」部分です。
RAGの検索対象は任意に設定することができるため、RAGを用いることで最新の情報や企業の内部ドキュメントなどを反映した回答生成が可能になります。
便利な反面デメリットもいくつかあり、その一つが従来のRAGは大幅に異なる内容を持つ複数ドキュメントからの検索を想定して作られているものではないということです。
論文では、化学工場で設備事故の原因をLLMで発見したい場合を例に出していました。事故の原因は備品の老朽化、労働者の管理ミス、天候、様々考えられますが、これらが1つの文献にまとまっていることは少ないのではないでしょうか。複数ドキュメントからこれらの情報をうまく検索することが必要な一方、RAGはこのようなタスクが得意ではありません。
もう少しイメージしやすい例をお出しします。例えば私が自分に付与される有給休暇の日数を調べたい時、モデルは「①社内規定」「②崎山という人間の所属組織や役職が載った資料」の2種類の資料を検索して組み合わせ、「崎山の有給休暇は〇日です」と答える必要があります。
こういった需要は業界問わずかなり多い一方、実は従来のRAGはこのようなタスクが得意ではありませんでした。
この研究では、上記の問題に対処するためのスキームとして Multi-Head RAG(MRAG)を提案しています。

RAGはユーザーの質問や要求をベクトルに変換(埋め込みといいます)し、データベース内の情報との類似度が高い情報を取得します。これがRAGの検索のしくみです。埋め込みにより、元のテキストの意味や文脈を保持したままテキストをモデルが処理できるようにします。
従来はこの埋め込みが1つの質問に対して1つ生成されていたのですが、MRAG は複数の視点から埋め込みを作成することで、より複雑で多面的な質問にも回答できるようになりました。
論文では、Wikipediaの多面的な検索を行った際に最新のRAGに対して MRAG が20%性能がよいことを示しています。
また、MRAG のコードは公開されています。興味があればぜひご覧ください。
【参考】MRAG
より実用的にRAGを使える手法が提案されたことで、より精度よくLLMを使えるようになっていくことを期待します。
出典:https://arxiv.org/abs/2406.05085
最後まで読んでいただきありがとうございます。
今回は、LLMはLLMをトレーニングするより良い方法を発明できるか?、ソフトウェアエンジニアリングにAIを活用する、複数ドキュメントからの検索に対応するためのRAG手法MRAG の3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説















