



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

皆さん、こんにちは。マーケティングプラットフォーム本部で広告系製品の開発を担当している田頭です。
前回の理論編ブログでは、大量のログから高速にユニークユーザー(以下、UU)数を推定するための背景やアルゴリズム、およびその実装部分について、「理論編」として解説させていただきました。
今回は「実践編」として、実際に当社内で行ったapprox_distinct関数のパフォーマンス検証について、以下の内容を皆さんにご紹介したいと思います。
今回の検証は、以下の環境で実施しました。
検証に利用したデータは、以下の通りです。
以下の内容で、厳密に集計(COUNT(DISTINCT x))した場合と、推定(approx_distinct(x))した場合の結果を取得しました。
このブログに掲載している検証結果の図は、全て横軸を真のUU数(厳密に集計したUU数)としています。
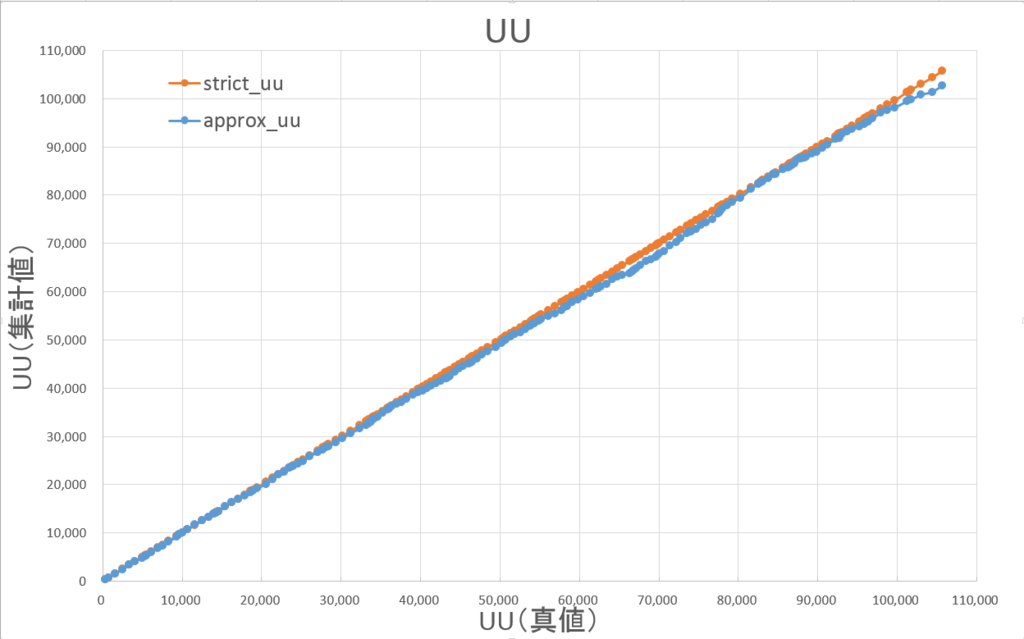
凡例の意味は以下の通りです。
両者が重なっているほど、誤差が小さいことを意味しています。
UU数が小さい場合(グラフ左側)でも、ほぼ重なっています。
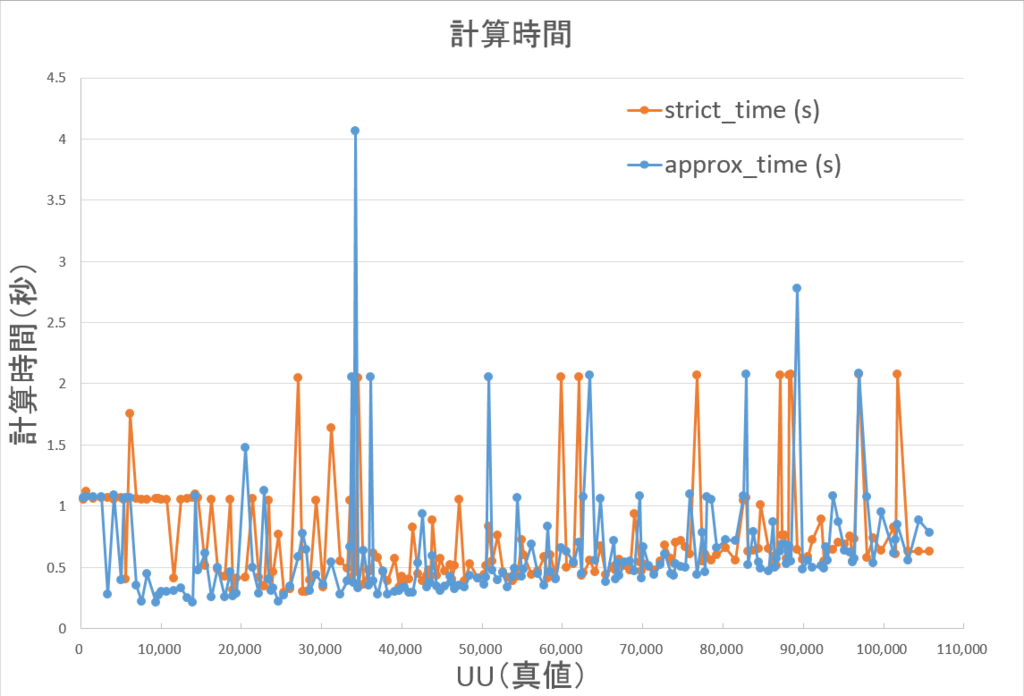
凡例の意味は、以下の通りです。
UU数が小規模な場合には、計算時間において両者にあまり差は見られません。
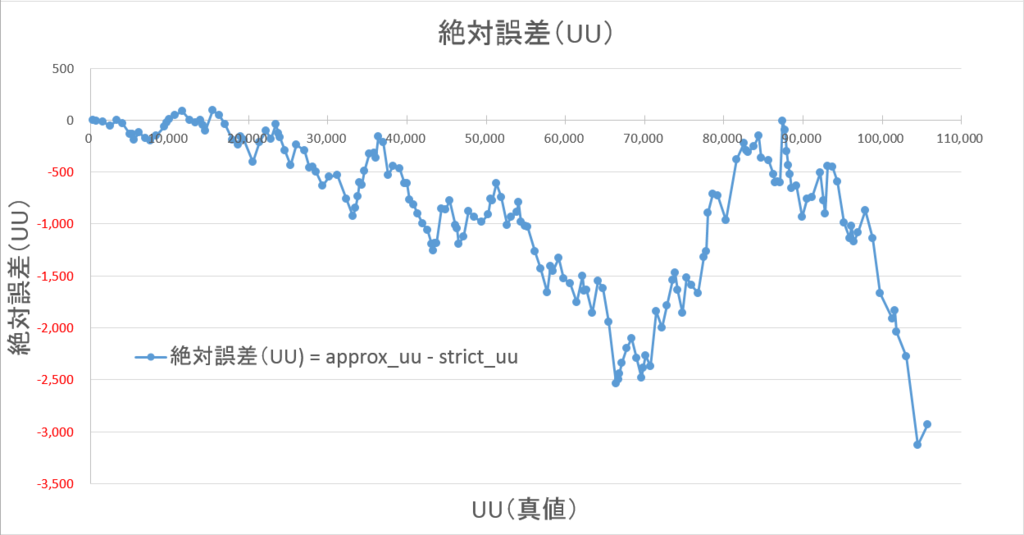
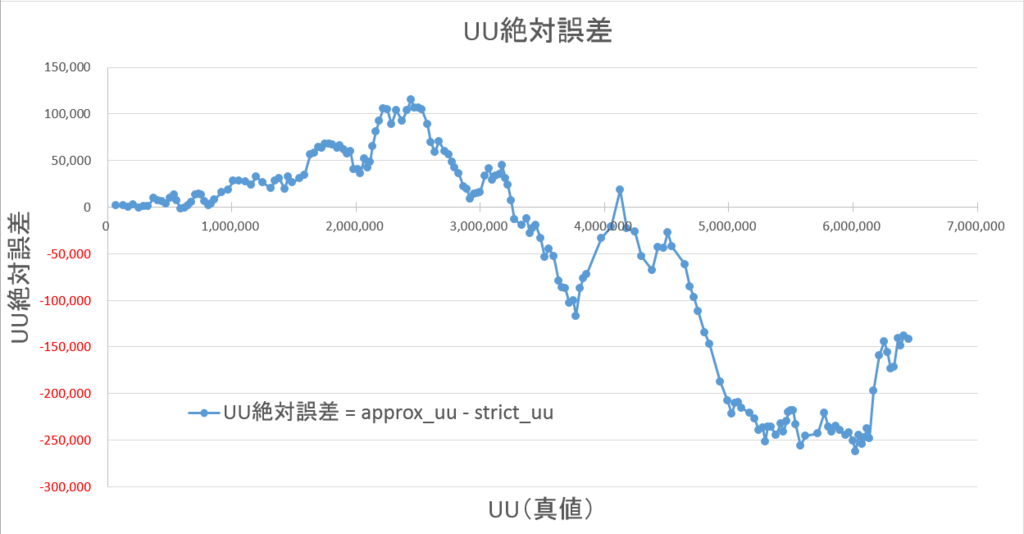
集計したUU数を縦軸にした図(4-1-1)では、ほぼ重なっていたため、「推定UU – 真のUU」で計算した絶対誤差を縦軸にプロットしました。

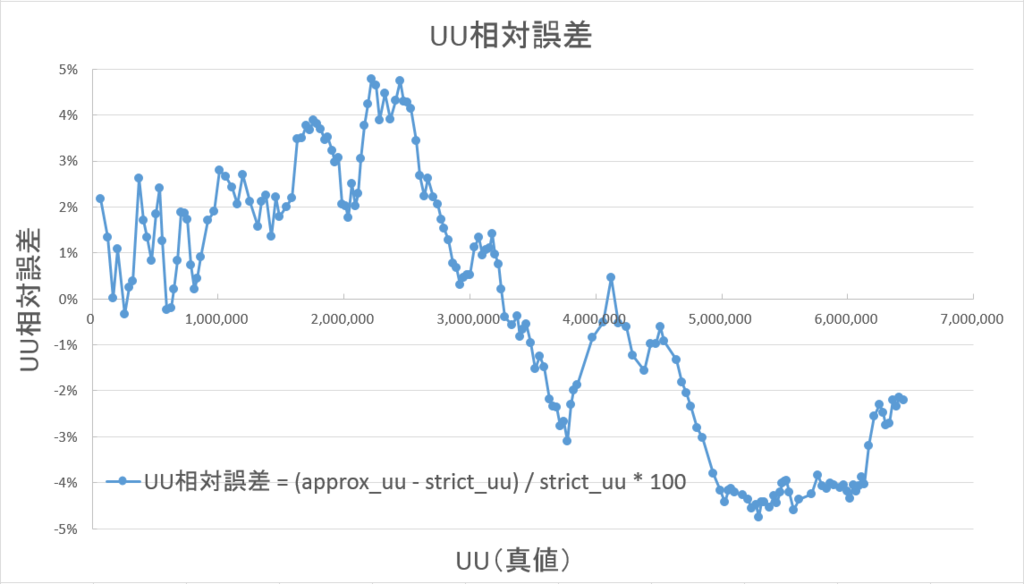
今度は、「絶対誤差 / 真のUU * 100」で計算した相対誤差を、縦軸にプロットしました。
相対誤差は最大でも±±4%以内に収まっています。
絶対値平均で1.6%ほどであり、±±3%以内に90%以上が収まっています。
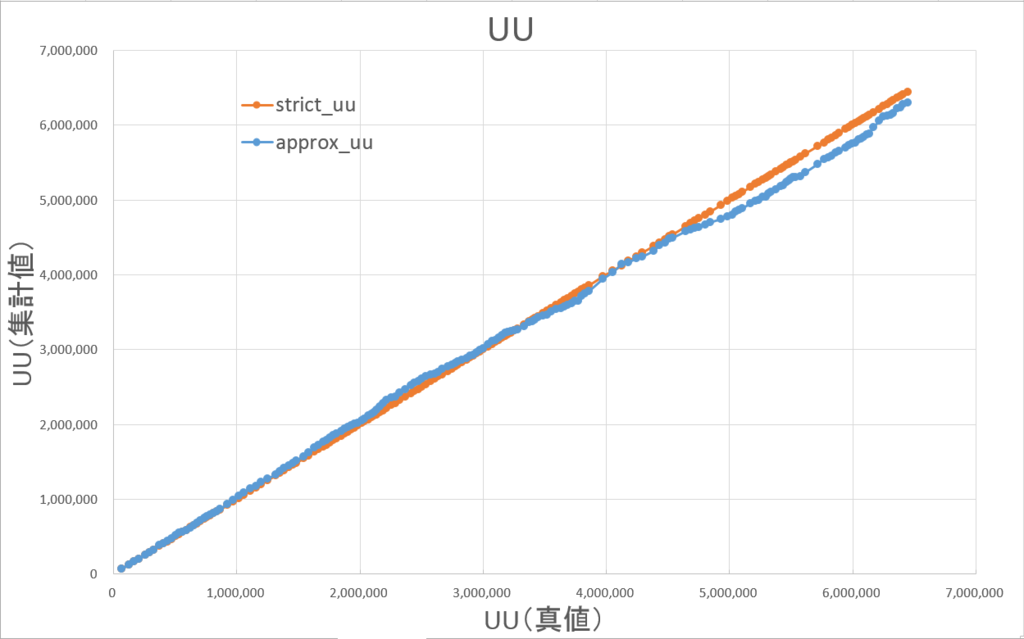
小規模検証結果と同様です。
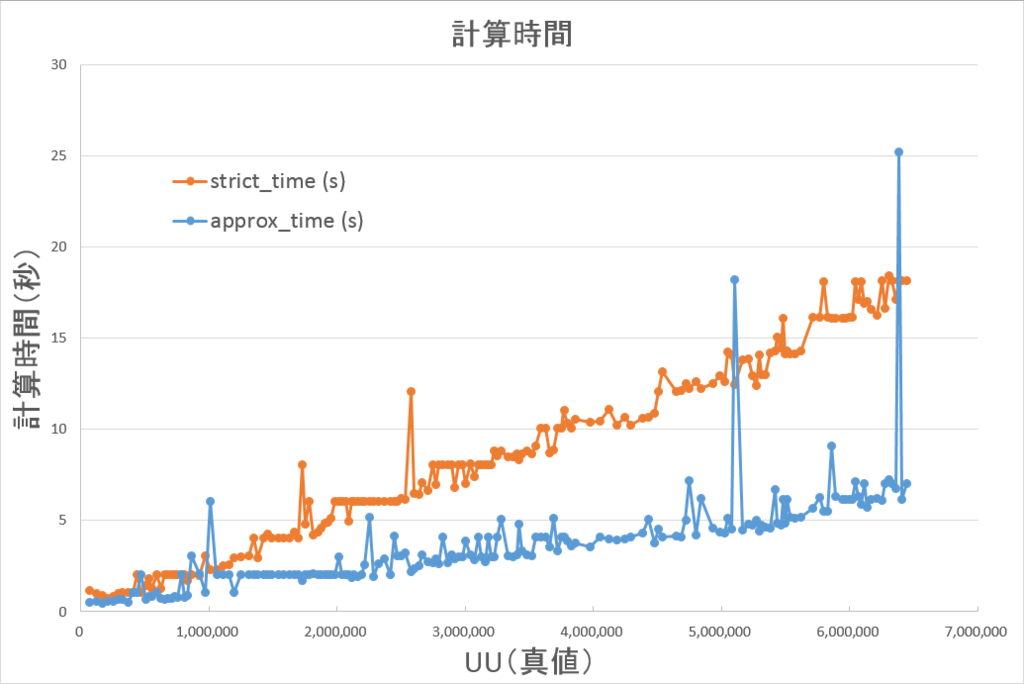
いくつか外れ値のようなものが含まれますが、手動で再実行したところ、外れ値前後の条件と同程度の速度でした。
基本的にUU数が増加するほど差が大きくなっており、外れ値を除いて最大で1/3まで短縮されています。
平均でも1/2まで短縮されています。
小規模検証結果と同様です。
誤差は最大でも±±5%以内に収まっています。
絶対値平均で2.4%ほどであり、±±4%以内に75%以上が収まっています。

小規模検証結果と同様です。
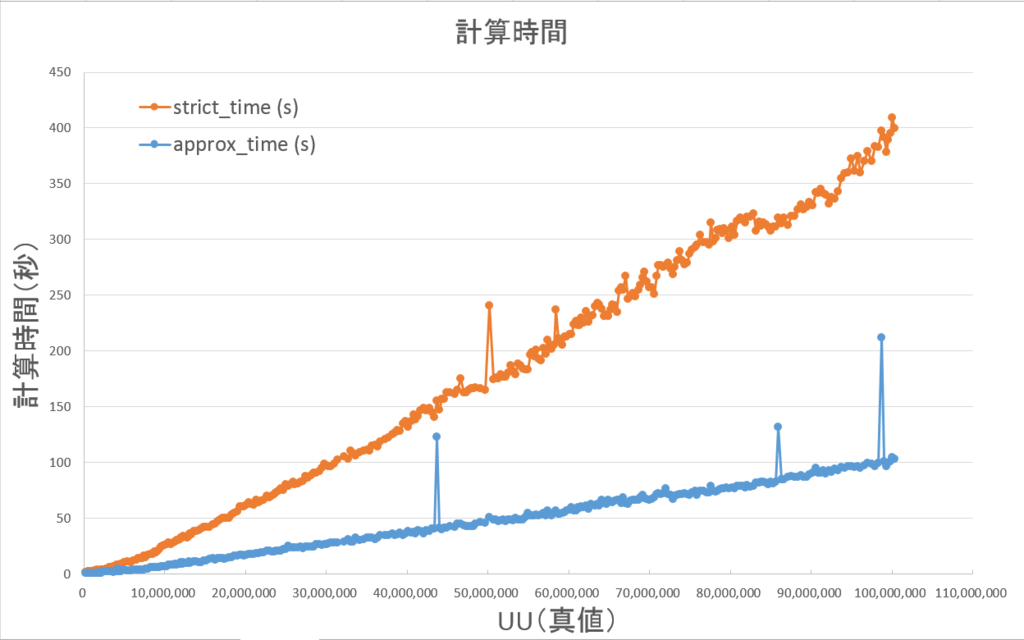
中規模検証結果の図(4-3-1)と同様にいくつか外れ値のようなものが含まれますが、手動で再実行した場合は前後の条件での集計と同程度の速度でした。
こちらもUU数が増加するほど差が大きくなっており、外れ値を除いて最大で1/4まで短縮されています。
平均でも1/3まで短縮されており、中規模の場合よりも更に短縮効果が大きくなっています。

小規模検証結果と同様です。
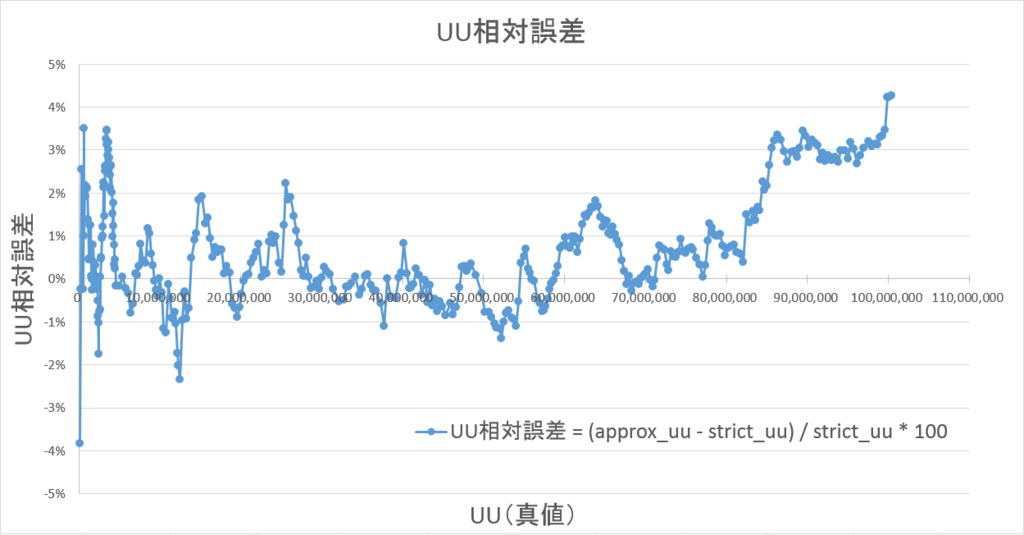
誤差は最大でも±±5%以内に収まっています。
絶対値平均で1%ほどであり、±±4%以内に99%以上が収まっています。
今回のブログの内容とほぼ一致していますが、興味のある方はスライド資料もぜひご覧ください。
https://www.slideshare.net/slideshow/embed_code/key/HIxqefYpRoSoT1
今回は「実践編」として、大量ログからUU数を高速に推定するために、Prestoのapprox_distinct関数のパフォーマンス検証について、簡単にご紹介しました。
懸念していたUU数が小規模な場合についても、かなりの精度で推定できており、実用的で使いやすそうですね!
さらに、目標としていた「高速化」という点についても、データが小規模な場合は変化がありませんでしたが、データが大規模であるほど効果が大きいという結果を得ることができました。とはいえ、更に高速化できれば更に使いやすさは向上するため、引き続き高速化には取り組んでいきたいと思います。
また、Prestoはリリースのスピードが速く、この検証中にも新バージョンが公開されていました。
今後も、継続的に情報収集していくとともに、それらを当社製品のさらなる利便性向上・機能改善につなげていきたいと考えています。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













