



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス部の辻 陽行です。
今回は、データ分析を行う際のデータの前処理や集計を行う時に非常に役に立つ、PandasというPythonの便利なモジュールを紹介したいと思います。
モジュールを紹介する前に、分析作業の流れとPandasがどのあたりに関与してくるかを先に説明しておきます。
私たちの仕事は、さまざまなデータ分析をお客さまへ提供し、それを付加価値の核としているわけですが、 行き当たりばったりでデータを分析していくのでは、到底価値のある結果を導きだすことはできません。
大抵の場合、以下の手順に沿って分析を進めていくことになります。

仮説形成の段階は、分析の各段階で修正を繰り返すものなので一概には順番を定義することは難しいですが、一般的な流れとしては上記のものになるかと思います。
お客さまの課題は、それぞれ異なっているため最終的な課題解決のための分析手法は、それに応じて変化し、その手法も多岐に渡ります。
しかし、基礎集計については、どんな課題であろうが具体的な分析に入る前に必ず実施することになります。
基礎集計という作業自体は、SQLなりExcelなりを用いて行われる比較的地味な作業です。 しかし、最終的な分析方針に大きな影響を与えることがあるため、このフェーズで手を抜くと後々痛い目にあいます。
異常値の発見やデータの分布の確認、欠損値の有無、変数の作成など、基礎集計フェーズではやるべきことがたくさんあり、実際の業務ではこの部分に一番時間がとられることが多いです。
具体的な分析手法を適用した際の成果は、この基礎集計段階で大方決まっているといっても大げさではないでしょう。
Pandasを用いて基礎集計を実施する前に、今回用いるPandasと基礎集計の対象データであるReceReco(レシレコ)のデータを紹介しておきます。
Pandasは、Pythonのモジュールの内の1つなのですが、データ処理や分析に特化した機能を提供しています。
具体的には、Rと同様にデータフレームという形式で行列の形をしたデータを柔軟に取り扱うことができ、データの大まかな特徴を掴みたい時などに重宝します。
時系列データを分析するための機能も揃っており、金融データのような時系列の情報から将来を予測する課題に取り組む時には、非常に役立ちます。
データ処理や集計レベルの分析は、Pandas以外にもSQLやRなどを用いて実施することができます。
ここで、それぞれのメリット・デメリットを簡単にまとめておきます。
| ツール | メリット | デメリット |
|---|---|---|
| R | ・統計処理に特化した環境なので、データフレーム形式のまま、さまざまなモデリングが可能・行列計算が速い | ・統計処理に特化している分、Webサービスや業務システムの構築のためのライブラリは他の言語と比べて少ない・データサイエンティスト以外にRを用いる技術者が少ないので、システム実装された際に保守が難しいことがある |
| SQL | ・記法が単純なので、学習コストが少ない・一旦DBに入れてしまえば取り扱いは容易 | ・複雑な処理や特殊な処理が必要な場合には不向き・モデリングなどを行う機能はないため、基礎集計フェーズ以外では使えない |
| Pandas | ・データ分析以外の部分にもPythonで記述することができる | ・モデリングや検定を実施する際には他のモジュールでの処理が必要 |
こうして見るとPandasのメリットが少ないように見えますが、分析以外の処理部分と言語を揃えることができるのは大きなメリットかと思われます。
上記の比較は、厳密な比較というよりも実際の業務を通して感じたものを記載させていただいているので、その点はご了承ください。
今回、Pandasを用いて基礎集計を行う際のデータは、弊社が提供する無料家計簿アプリ「ReceReco(レシレコ)」のデータを一部サンプリングしたものとなります。
ReceRecoは、スマートフォンのカメラでレシートを撮影すれば、あっという間に支出管理ができる無料家計簿アプリです。 アプリの詳細は、ここでは割愛させていただきますが、ご興味がありましたら下記をご覧いただければ幸いです。
ReceRecoのデータのうち、特定の商品を取り上げて販売点数や売上の違いについてPandasを用いて見ていきたいと思います。
対象は、2013年2月1日から2013年9月30日までのReceReco登録レシートデータをランダムサンプリングしたものを使用します。 (登録されたレシートデータを個人が特定されない範囲で二次利用することは全ユーザーに事前許諾済み。)
今回は、Pandasの使い方を中心に書かせていただいていますので、 実際の商品の購買の名称や列名は、一部変更させていただいております。
また、サンプリングによってレシート数がかなり減少しているため、集計結果に対する考察は行っておりません。
それでは、具体的にデータの読み込みをPandasを用いて行っていきましょう。
今回は、特にレシート履歴の多い商品がいいので、皆さんにも身近なコーラを取り上げてみたいと思います。
データの読み込みの方法はいくつかありますが、今回はデータの形式がtsv(タブ区切りのデータ)だと想定して処理を行っていきます。
仮に、「recereco_data.tsv」というtsvファイル形式でデータが存在したとして話を進めていきます。
データは以下のような項目で構成されています。
それでは、具体的なコードを見ていきます。 以下のコードはPython2.7、Pandas0.15.1verを想定して記載してあります。
# -*- coding:utf-8 -*-
#モジュールの読み込み
import pandas as pd
import numpy as np
#ファイルの読み込み
#ファイルに列名がない場合
#列名の指定
col_names = ['id','receipt_id','name','price']
#列名を指定して読み込み
df = pd.read_csv('recereco_data.tsv',sep='t',names=col_names)
#ファイルの1行目に列名がある場合
df = pd.read_csv('recereco_data.tsv',sep='t',header=0)read_csvという関数名ながらセパレータを指定できるため、csvファイル以外のファイルでも読み込めます。
read_tableという関数もデフォルトがタブ区切りのファイルを読み込むために存在しますが、どちらでも大きく挙動は変わらないのでどちらかを用いればよいかと思います。
また、ファイルに列名がついている場合には、header=列名が記述されている行数を指定すればそれを列名として読み込んでくれます。
具体的な集計に入る前に、簡単にどのようなデータが入っているのかを確認しておきます。
#データの冒頭5行を取得
df.head(5)
#データの末尾5行を取得
df.tail(5)
#データの型の確認
df.info()
#データの件数や統計量を確認
df.describe()
#データの型の確認
type(df)
#列のデータ型の確認
type(df['price'])
#データ型の変更
#今回はprice列が文字列だったのでfloat型に変更
df['price'] = df['price'].astype(np.float64)ちなみに、末尾にどのようなデータが入っているかを実際に確認してみると以下のようになっています。
| id | receipt_id | name | price |
|---|---|---|---|
| 11562434 | 3636601 | 大生姜(おらんく生姜) | 98 |
| 11562435 | 3636601 | カルピスウェルチスパー | 88 |
| 11563448 | 3636926 | パン | 200 |
| 11563449 | 3636926 | パン | 600 |
| 11563899 | 3637070 | カラオケ2時間 | 850 |
Rでも同様の関数がありますが、Pandasでもデータの先頭行を確認したり、基本的な統計量を確認したりする関数が用意されています。
今回は、商品名に「コーラ」が入っているものに対象を限定したいので、name列から「コーラ」が文字に含まれるものを条件抽出していきます。
条件の抽出方法はいくつか存在しますので、必要に応じて使い分けていただくのがよいかと思われます。
#日本語は普通の文字列だとうまく認識しないのでUnicode形式にして条件式に渡す点に注意
#「コーラ」という文字列そのものが該当するレコードを抽出したい場合
df_cola_only = df[df['name'] == u'コーラ']
#「コーラ」を文字列に含むレコードを全て取り出したい場合
df_cola = df[df['name'].str.contains(u'コーラ') == True]
#販売価格が130円以上のものは取り除きたい場合
df_cola_under_130 = df_cola[df_cola['price']) <= 130]コーラを含む商品名を抽出すると、以下のようなものがでてきます。
| id | receipt_id | name | price |
|---|---|---|---|
| 11682531 | 3674912 | コカコーラS | 100 |
| 11701083 | 3681182 | キリンメッツコーラ | 118 |
| 11888974 | 3742639 | コカ・コーラ缶 | 100 |
| 11945666 | 3761585 | kidsコカコーラ | 105 |
| 12073580 | 3804236 | コカ・コーラ綾鷹300ml | 105 |
基本的に条件抽出は、列名を指定して不等号を記述することで取り出すことができます。
また、指定文字列を含むものを取り出したい場合には、上記のように文字列が含まれるかどうかを判定してTrue/Falseを判断する必要があります。
基本的には上記のコードのように書いていけば、正しくデータを抽出できますが、 データの型が想定していた型と異なる場合には、意図しない抽出が行われることがあります。
例えば、数値型だと思っていた列が、実は文字型のデータだったといった状況がよくあります。
そういったことを避けるためにも、条件抽出を行う前にデータの概要をinfo関数やdescribe関数で確実に確認しておきましょう。
必要なデータが取り出せたら、次に対象商品がどれくらい存在するのかを確認してみましょう。
レシートデータをカメラで読み取っていたり、商品名の手入力ができるため、商品名のゆれなどが想定されますが、いったん、各商品の売上点数と売上額を確認してみましょう。
まずは、集計の軸となる列をキーに指定し、group関数を適用した後に自分が見たい集計関数を適用させます。
#キーとなる列を指定
key = 'name'
#指定したキーと軸にgroupby関数をデータに適用
df_cola_g = df_cola.groupby(key)
#全ての列に対して合計を求める
df_cola_sale = df_cola_g.sum()
#売上の多い順に並びかえ
df_cola_sale = df_cola_sale['price'].order(ascending=False)
df_cola_sale.head(5)具体的に売上の多い上位5つの商品を見てみると、メーカーの分からないコーラやメッツコーラ、コカコーラといったさまざまな商品があるようです。
| name | price |
|---|---|
| コーラ | 22,307 |
| メッツコーラ | 21,897 |
| コカコーラ | 15,243 |
| コカ・コーラゼログリップボトル | 13,039 |
| コカ・コーラ | 11,804 |
販売点数については、レシートに記載されていた数をカウントすることで集計します。
#NAでない要素数をカウントして販売点数を確認
df_cola_amount = df_cola_g.count()
df_cola_amount = df_cola_amount['id'].order(ascending=False)
df_cola_amount.head(5)こちらも具体的にどのような商品があったかを確認しておきます。
| name | count |
|---|---|
| コーラ | 116 |
| コカコーラ | 98 |
| コカ・コーラ | 89 |
| コカ・コーラゼログリップボトル | 71 |
| キリンメッツコーラ480ML | 65 |
ちなみに、今回用いた要約統計量以外にもPandasにはいろいろとメソッドが用意されているので、必要に応じて使いわけるといいでしょう。
#要約統計量
#グループ化されたものに適用できるメソッドは以下のようにたくさん用意されている
#合計
df_cola_g.sum()
#平均
df_cola_g.mean()
#中央値
df_cola_g.median()
#分散
df_cola_g.var()
#標準偏差
df_cola_g.std()
#歪度
df_cola_g.skew()
#尖度
df_cola_g.kurt()
#累積合計
df_cola.cumsum()先ほど確認した売上の上位5商品のうち「コカ・コーラ」と「メッツコーラ」の2つに絞って店舗別の販売点数を見ていきたいと思います。
それぞれの商品のみを抽出したものを先に作成して、再度1つのデータにまとめるという処理を行います。SQLでいうところのUNIONと同じような処理を想定していただけると良いかと思います。
Pandasではappendやconcatを用いて行の結合を行います。
#商品を「コカコーラ」と「メッツコーラ」に限定
df_cola_coca = df_cola[df_cola['name'] == u'コカコーラ']
df_cola_mets = df_cola[df_cola['name'] == u'メッツコーラ']
#それぞれのデータを1つのデータに結合
df_cola_twoitem = df_cola_coca.append(df_cola_mets)
#もしくは、concatを用いる
df_cola_twoitem = pd.concat([df_cola_coca,df_cola_mets],ignore_index=True)店舗別に売上を確認するためには、店舗の情報が必要ですが現状の商品データには存在しません。
そこで、別のデータから店舗情報を商品データに結合する必要があります。
SQLなどに慣れ親しんだ人にとっては、table1 as a left join table2 as b on a.key = b.keyのように指定するものを 思い浮かべていただけると良いかと思います。
具体的には、レシートの発行時刻や店舗名が記載されたレシート情報を読み込んでデータを結合したいと思います。
レシートデータが「recereco_data_receipt.tsv」という名称で存在しており、以下の項目で構成されているとします。
※店名については、マスキングしてどのような店舗か分からないようにしてあります。
紐づけの条件としては、商品のデータではreceipt_id、レシート情報のデータではidをキーに結合を行います。
Pandasではmergeを用いて列の結合を行います。
#レシートデータのあるテーブル
df_receipt = pd.read_csv('recereco_data_receipt.tsv',sep='t',header=1)
#レシート情報が記述されたテーブルとreceipt_idをキーに結合
df_merge = pd.merge(df_cola_twoitem,df_receipt,left_on = 'receipt_id', right_on='id',how='inner',suffixes=('_x','_y'))
df_merge.head()具体的には、このようなデータがマージされます。
| id_x | receipy_id | name | price | id_y | shop_name | paid_date |
|---|---|---|---|---|---|---|
| 11945667 | 3761585 | コカコーラ | 157 | 3761585 | shop1 | 2013-05-02 07:34:00 |
| 13742828 | 4334152 | コカコーラ | 150 | 4334152 | shop2 | 2013-05-12 10:30:00 |
| 13936217 | 4394524 | コカコーラ | 198 | 4394524 | shop3 | 2013-05-13 05:42:00 |
| 14316119 | 4512460 | コカコーラ | 504 | 4512460 | shop4 | 2013-05-15 02:13:12 |
| 14596506 | 4602037 | コカコーラ | 158 | 4602037 | shop5 | 2013-05-16 04:56:00 |
suffixesで文字を指定しておくと、双方のデータに同じカラム名があってもそれぞれを指定文字で別々に認識してくれます。
指定しておかなくてもPandasが勝手にリネームしてくれます。
では、商品別・店別の売上額を集計してみます。
#商品別、店別に売上額を集計
#複数の軸で集計したい場合には、リストで列名を渡すことで集計可能
key_list = ['name','shop_name']
#集計関数をメソッドチェーンでつないで書くことも可能
df_item_shop = df_merge.groupby(key_list)['price'].sum()
#売上順に並べ替え
df_item_shop = df_item_shop.order(ascending=False)
df_item_shop.head()具体的には、下記のような結果が返ってきます。
| name | shop_name | sale |
|---|---|---|
| メッツコーラ | shop1 | 15,811 |
| コカコーラ | shop2 | 1,176 |
| コカコーラ | shop3 | 571 |
| メッツコーラ | shop4 | 556 |
| メッツコーラ | shop5 | 511 |
データを結合するときのポイントは、
列の結合を行う際の注意点としては、それぞれのデータのキーの名称を記載しないと意図しない結合が行われてしまうことがあるため、 必ずキーは双方記載するようにしましょう。
howオプションで「left」「right」「outer」などの結合方法を指定できます。
最後に、データを数字だけ眺めていても全体像は掴みづらいので、集計したデータをグラフ化することで大まかな傾向を掴みたいと思います。
今回は、「コカコーラ」と「メッツコーラ」の平均単価と単価の分布を棒グラフを用いて確認します。
#plot機能は、そのままでは日本語に対応してないので、名称を変えておく
#要素の置換はreplace(対象,置換文字)を用いる
df_merge['name'] = df_merge['name'].replace(u'コカコーラ',u'coca-cola')
df_merge['name'] = df_merge['name'].replace(u'メッツコーラ',u'mets-cola')
#平均単価を棒グラフで確認
df_merge_g = df_merge.groupby('name')
df_merge_price_mean = df_merge_g['price'].mean()
df_merge_price_mean.plot(kind='bar')
#異常にメッツコーラの単価が高いので、中央値を取ってみる
df_merge_price_median = df_merge_g['price'].median()
df_merge_price_median.plot(kind='bar')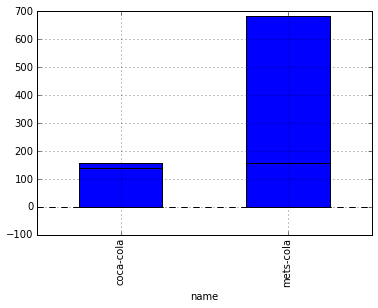
#やっぱりメッツコーラの中央値も高いままなので、分布を見てみる
df_merge[df_merge['name'] == 'mets-cola']['price'].hist()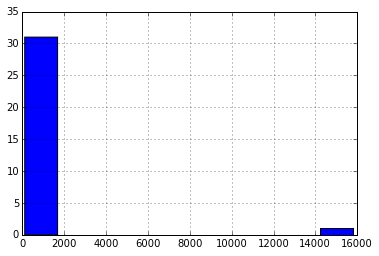
#異常に高い値を付けている異常値があるのでそれを削除して再度分布を見てみる
df_merge = df_merge[df_merge['price'] < 2000 ]
df_merge[df_merge['name'] == 'mets-cola']['price'].hist()
#同様にコカコーラの方も分布を確認しておく
df_merge[df_merge['name'] == 'coca-cola']['price'].hist()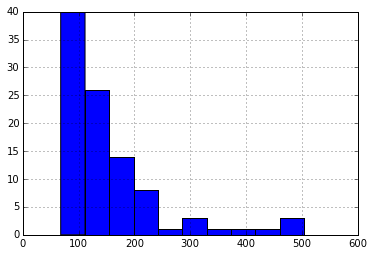
Pandasを用いずにmatplotlibのモジュールからも作成することが可能ですが、 上記の例ではpandasのデータフレームにhist()やplot()のメソッドを用いて表示しています。
plot()のオプションでkindを指定すると、棒グラフ以外にもさまざまなグラフを描画できますので、必要に応じて以下のオプションから必要な種類のグラフを選択するといいでしょう。
| グラフの種類 | 概要 |
|---|---|
| bar | 棒グラフ |
| hist | ヒストグラム |
| box | 箱ひげ図 |
| kide | 密度分布 |
| area | 面グラフ |
| scatter | 散布図 |
| pie | 円グラフ |
グラフの描写には、他にもいろいろなオプションがありますので、ここでは語りきれませんが、折を見てグラフ化に関する記事をご紹介できればと思っています。
簡単な例にはなってしまいましたが、データを読み込んでから簡単な基礎集計をPandasを用いて実施するところまでをなぞることができたかと思います。
今回紹介したもの以外にもPandasは多くの機能を備えておりますので、今後ご紹介させていただければ幸いです。
ここまで読んでいただきありがとうございました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













