

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

皆さん、こんにちは。研究開発室の佐藤 貴海です。
Platium Data Blogへは初投稿ですが、実は、前回エントリーの「ツール・ド・東北」には選手として登場しています。
応援する気持ちと、応援される感動がたくさん詰まった「ツール・ド・東北 2014」参加レポート – Platinum Data Blog by BrainPad
今回は、以前より気になっていた「ホフステッド指数」について、趣味と実益を兼ねて分析と考察をします。
気になったきっかけは、以下の日経BizGateの記事。
様々な国の文化(国民性)を定量的に測定し、指数化しようとしたのがヘールト・ホフステッドである。 ホフステッドは米IBMの世界40カ国11万人の従業員に行動様式と価値観に関するアンケート調査を行い、 1980年にはその国の文化と国民性を数値で表すことのできる「ホフステッド指数」を開発した。
ホフステッド指数とは、オランダの社会科学者ヘールト・ホフステッドが開発した、各国の国民性の指標のこと。
ホフステッド指数は、以下の6つの指標で構成されています。
(各指標の説明は、英Wikipediaからの超訳なので、気になる方は各自、参照をお願いします。)
1.Power distance index (PDI) 上下関係の強さ
2.Individualism (IDV) 個人主義傾向の強さ
3.Uncertainty avoidance index (UAI) 不確実性の回避傾向の強さ
4.Masculinity (MAS) 男らしさを求める強さ
5.Long-term orientation (LTO) 長期主義的傾向の強さ(俗にいう、アリとキリギリスの話)
6.Indulgence versus restraint (IVR) 快楽的か禁欲的か
日経BizGateの記事では、ホフステッド指数として最初の4つの指数を紹介しています。 近年は、それに後の2つの指標を加えた6つの指標が使われているようです。
これだけ見ると、何やらよくわからない指標なので、詳細を見ていこうと思います。
分析対象となるホフステッド指数のデータとしては、以下のページのものを使用しました。研究目的に限り使用できるとのことです。
The dimension scores in the Hofstede model of national culture can be downloaded here
元ファイルには、110の国・地域のホフステッド指数が含まれています。ただし、6指標全て揃っているのは、そのうちの65の国・地域のため、今回の分析では、この65ヶ国・地域を対象とします。
以下で、日本がどの順位に位置しているのか、各指標を見ていきます
順位:43位 (65ヶ国・地域中) 平均をやや下回る
一般的に階級社会といわれるイギリスより、日本が上位なのは違和感を覚えますが、年上・年下を必要以上に気にしてしまうあたり、日本が上位にくる理由なのかもしれません。

順位:30位 (65ヶ国・地域中) ほぼ平均
一般的によく言われていることから、アメリカが1位なのは、納得感があります。
同じアジア圏にも関わらず、日本が中国・韓国といったほかのアジアの国々に比べ2倍以上値が高い結果になっています。外資系企業に勤める日本人を対象にしているからでしょうか。

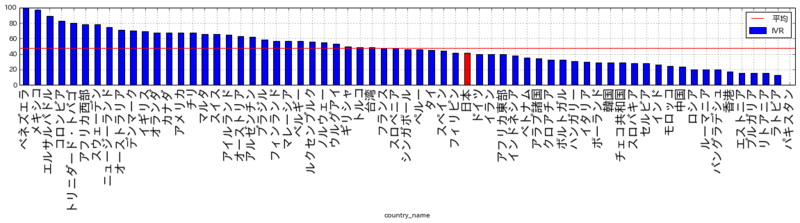
順位:10位 (65ヶ国・地域中) 平均より高い
日本人が不確実性の回避傾向が高いことを示すレポートは、ほかにもよく目にする気がします。
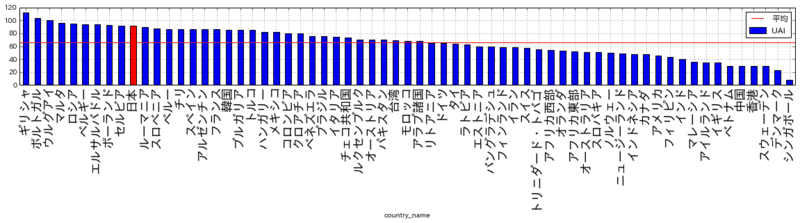
順位:2位 (65ヶ国・地域中) かなり高い
日本が2位と高い結果となっています。昨今ジェンダーフリーが叫ばれる中、その一方では男らしさが求められている結果が興味深いと思いました。
全体的には、上位ランクのスコアがかなり高く、下位ランクのスコアがかなり低くなっており、一部の国に特徴が現れるスコアとなっています。
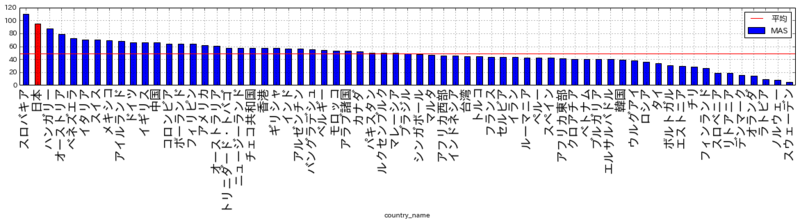
順位:3位 (65ヶ国・地域中) かなり高い
ほぼ、アジア・東欧とラテンの対比となっています。「寒いところなど気候が厳しいと、蓄えがないまま冬が越せない。」といった理由で長期主義・短期主義は、緯度でも説明できるという意見もあるようです。
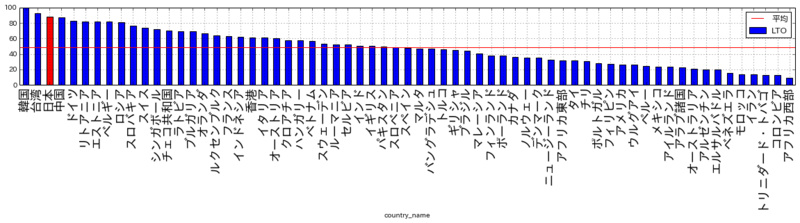
順位:3位 (65ヶ国・地域中) 平均よりやや低い
上位は、圧倒的にラテン系です。下位は、LTOとは異なりアジアと東欧で傾向が分かれています。快楽主義・禁欲的かということは、歴史的・宗教的な影響も考えられるかもしれません。
前章では各指標について、簡単に個別の考察を述べました。
しかし、分析では個々の考察もさることながら、全体の概況の説明が求められる場面が多々あります。 むしろエクゼクティブ向けの説明では、そこ以外見られない場合が多いのが現状です。
簡潔・明瞭なサマリを書くのがアナリストの仕事の本領ですが、今回は、テクニカルに全体が理解できる(と思われる)以下の2つの手法を紹介します。
両手法とも、データ間の類似度を定義して、似ている国ほど近く表示する手法となります。
各手法の詳細な説明はここではしませんが、以下でコードを公開しているので、皆さんのお手元で、再現ができるかと思います。
GitHub – tkm2261/Hofstede_analysis
データ分析においては、データ間に距離を定義する場面が非常に多く存在します。
有名な例では、協調フィルタリングによるリコメンドで、「商品間の類似度を定義して『似ている商品を買っている人が買っている商品』を推奨する手法」等があります。
また以下の議論では、便利なため類似度の代わりに、距離を定義します。 *1
距離については、さまざま提案されているものの、特別な理由がない限りは、以下のどちらかを使う場合がほとんどです。
コサイン距離は、コサインの定義からベクトルが同じ方向を向いている程近くなるので、割合の近さを定義したい場合に使います。 そのため、テキスト分析では「単語の構成割合が似ている記事は似ている。」としたいことが多く、よく使われます。
その他の場合は、ユークリッド距離を基本的に使います。変な距離にしても説明が大変な割に、効果がないことが大半です。
今回は、割合の近さを見たい場合ではないので、ユークリッド距離を選択します。 *2
最後に、類似度を計算する前に変数の標準化*3を行います。
標準化をせずに距離を計算するのは、メートルやキロメートルと言った単位が入り乱れているのと同じ状態なので忘れずに行いましょう。
標準化後のユークリッド距離で、日本に近いランキングは以下になります。以下を念頭に次の分析をみていきます。
| 順位 | 国名 |
|---|---|
| 1 | ハンガリー |
| 2 | ドイツ |
| 3 | イタリア |
| 4 | チェコ共和国 |
| 5 | ベルギー |
| 6 | スイス |
| 7 | ポーランド |
| 8 | ギリシャ |
| 9 | ルクセンブルク |
| 10 | オーストリア |
| 11 | 台湾 |
| 12 | フランス |
| 13 | 韓国 |
| 14 | スペイン |
| … | … |
| 50 | アメリカ |
| 51 | チリ |
| 52 | オーストラリア |
| 53 | フィンランド |
| 54 | トリニダード・トバゴ |
| 55 | シンガポール |
| 56 | ベネズエラ |
| 57 | エルサルバドル |
| 58 | マレーシア |
| 59 | ラトビア |
| 60 | オランダ |
| 61 | アフリカ西部 |
| 62 | ノルウェー |
| 63 | スウェーデン |
| 64 | デンマーク |
バイプロットは、データを2次元に無理やり押し込めて、平面にプロットする手法となります。
多次元(今回は6指標なので6次元)を2次元に縮約する手法は、いくつか提案されており、代表的なものでは、主成分分析(PCA)、非負値行列分解(NMF)、潜在ディリクレ分布(LDA)、Deep Learning等があります。
今回は、最も一般的なPCAを用いたバイプロットを使用します。*4
ユークリッド距離で、PCAのバイプロットをした結果が以下となります。

赤矢印は、各指標の因子(主成分)負荷量を二次元表示したものとなります。
矢印が大きいほど、その方向での指標が大きくなります。そのため国名の位置と絡めて、定性的な考察をすることができます。
日本は、LTO(長期主義的傾向の強さ)が大きいことが特徴となっている国のグループだと思われます。
今回は、6指標のユークリッド距離で図を書きましたが、類似度だけがわかっている場合は多次元尺度構成法でも似たような図を書くことができます。 ここで紹介することはできませんが、興味のある方は調べてみてください。
階層的クラスタリングは、「似ているものをくっつけて、最後のひとつまでどうくっつくか」を分析する手法です。
結果を見た方が早いので、先に表示します。

樹形図の高さが、距離を表しており適度な高さで切るとクラスタを作ることができます。
ここでは、日本は東欧系の国が多い水色クラスタに属しています。
階層的クラスタリングは、似ているものをくっつける性質上、2点間の距離だけでなく、2グループ間の距離も定義する必要があります。
今回は最も使われるWard(ウォード)法を用いてグループ間の距離を定義しました。
Scipyにも幾つか実装されていますので、色々試すとよいかと思います。
scipy.cluster.hierarchy.linkage — SciPy v0.14.0 Reference Guide
今回は、ホフステッド指数の各指標を眺めながら、バイプロットと階層的クラスタリングという2つの手法を説明しました。
手法については、説明はほとんどできていませんが、限られた紙面で紹介するよりは、コードも共有していますので、改めて調べていただいた方が良いと思います。
(あまりブログに数式は書きたくないですし・・・。)
ホフステッド指数で検索すると、さまざまな考察があるものの数字は少なく、結果だけがひとり歩きしている感じを受けました。
国民性の指標という、デリケートな面のある指標なだけに。扱いは慎重にしたいところです。
*1:類似度は似ているほど大きくなる指標ですが、距離は似ているほど小さい指標になります。そのため距離の逆数を取るなどをして類似度とすることもできます。今回は距離さえ分かっていれば使える手法なので、類似度を定義しませんが必要に応じて定義してみてください。
*2:ホフステッド指数を元に文化間の距離を算出する先行研究として、コグート=シン指数と言うものがあります。そちらを用いても同様の分析ができますが、コグート=シン指数は4指標で算出している、計算式の妥当性が不明等を考えて、最も一般的なユークリッド距離を使っています。
*3:変数を平均ゼロ、分散1に変換する。Z変換とも言います。
*4:狭義にはバイプロットは、PCAのバイプロットを示します。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













