



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

OpenCVを用いた「テンプレートマッチング」と、DeepLearningの物体検出アルゴリズムの一つ「SSD」使って、筆者が大好きな麻雀の牌を検出し点数を自動計算できるか試してみました!
こんにちは。アナリティクスサービス部の栗原です。
今回のブログは、筆者の大好きな麻雀をテーマに取り上げ、
1.物体検出に関わるテクノロジー
2.BrainPadの日常
(3.麻雀の面白さ)
をお伝えしたいと思います。
さてさっそくですが、皆さん麻雀経験はありますか?
おそらく、
1.「全く経験がない」
2.「アプリ等でやったことはあるが実際に卓を囲ったことはない」
3.「雀荘に行って一通りゲームを楽しめる程度」
4.「雀荘に通うほど好き」
のいずれかに該当するのではないでしょうか。
今回ブログでご紹介するのは、1.〜 3.の人向けのコンテンツです。
(4.の麻雀玄人の方からは甘いこと言うなと叱られる内容かもしれないのでご容赦ください・・・)
筆者は3.に該当します。麻雀は好きなのですが、点計算(※)が正確にできず、覚えるのが面倒くさくていつも人任せです。
そのためメンバーに点数計算が出来る人がいないと困ります。
筆者のような人間のために「自動で計算するアプリ」はあるのですが、入力が面倒だったり結局時間が3分位かかったりするので、場や流れが乱れます。なぜならば、上がった牌の14個を手動で入力しなければならないもしくは上がった役の全てを入力しなければならないからです。
(※)麻雀経験のない方はすみません。簡単に説明すると麻雀は難しいドンジャラみたいなものです。役(ルール)に則って絵柄をそろえるのですが、牌や役の種類や細かいルールが多く、非常にややこしい(* 麻雀初心者にオススメのサイト, 点計算ができるようになるサイト)。
また、1.と2.に該当する人に、みんなで卓を囲まない?と誘っても、
「お金とられるんでしょ?」
「ルールとか点数計算とか覚えることが多すぎて・・・」
「アプリだとアシスト機能があるからいいけど、実際に卓を囲んでやるのは敷居が高い」
という返答をよくされます。
まず声を大にして言いたいのは、麻雀というのはテーブルゲームの一つとしてとても面白いゲームだということ。奥が深い頭脳ゲームで、そこに運の要素が絶妙に絡む・・・。自身の決断力と状況判断力 、リカバリー力等様々な力が試され鍛えられます。初心者が上級者に勝てるのも魅力の一つです。 また、個人的にはアナログであることが重要だと思っています。戦いが終わった時、卓を囲んだ4人の中には謎の一体感が生まれていることも多々あります。
少し熱くなってしまいましたが、今回は
という2点の課題意識のもと、
「カメラで卓を取ったら自動で点数計算してくれる麻雀自動役計算くんを作りたい!」
(「パシャ!8000オール!)」みたいなイメージ)
と思い立ちました。
今回は、「OpenCV」を用いたテンプレートマッチングと、DeepLearningの物体検出アルゴリズムの一つである「SSD」を用いて自動役計算くんを構築した結果を比較してみました。
※実際にやってみた結果も掲載していますので、最後までお付き合いいただけたら幸いです!
突然ですが、当社のことをすでにご存知だった方への質問です。皆さんがブレインパッドに持っている印象はどのようなものでしょうか?
ベンチャーで若い会社?真面目な会社?最近だとAIの会社?と聞かれることもあります。
筆者は、この会社は本当に面白い会社だと思っています。
なぜならば、「色々なスキルセット/バックグラウンドを持った人が集まっている」かつ「業務外でも自分のスキルを使っていろいろなことを試みようとする人が多い」からです。
実は今回ブログを執筆するにあたり、上記のようなたくさんの有志の方の協力をいただきました。
今回はテンプレートマッチングとSSDを用いますが、昨今のテクノロジーの進歩は凄まじい勢いです。
10/22~29にイタリアで行われたICCV 2017でベストペーパーに選ばれたのはMask R-CNNでした。
一つ学んでいる間に新しい手法が発表され、キャッチアップするだけでも大変です。そしてそんな変化は、我々の身近なところでも広がっており、活用先も広がっています。
上記はすべて、画像認識のテクノロジーを使っています。
画像認識に限らない話ですが、世の中にあるサービスは誰かの身近な課題や想いで始まることが多いと思っています。きゅうりの自動仕分けマシーンを開発した農業を営む小池氏は、「仕分け担当だった母親の負担を軽減してあげたい」という想いのもと開発を始めたそうです。皆さんの身近な課題もテクノロジーで解決できるかもしれません。筆者の場合は、「麻雀を始める敷居を下げたい」「点数計算を楽にしたい」というのが想いです。
さて、前置きが長くなりましたが、今回実現しようとしている「麻雀自動役計算くん」は、かなりざっくり以下のような流れになると思います。

今回のブログは、上記の牌の識別にあたる部分を中心にご紹介します。
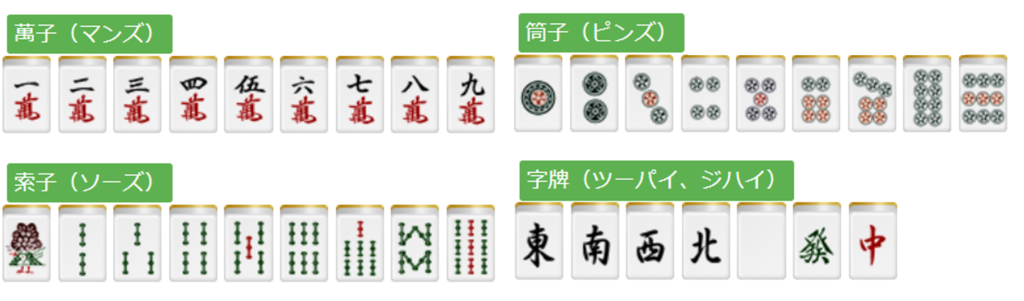
データの説明をするために、少しだけ麻雀牌の話をします。
麻雀の牌というのは商品によって微妙に大きさや書体が異なります(* https://www28.atwiki.jp/mjpai/pages/119.htmlさんより画像をお借りしました)。
どの種類の牌でも確実に検出できるようになるためには、上記のように様々な種類の牌を学習させる必要がありますが、今回はプロトタイプと割り切り、1種類の牌のみで学習します。

また、麻雀牌は下記の通り全部で34種類あります(* http://majandofu.com/mahjong-beginner-ruleさんより画像をお借りしました)。
1牌1ファイルの画像をiPhoneで撮影し、これを正解データとします。(麻雀好きの社員に自前の牌をお借りしました!)。
また、テストデータ用に様々な条件下(明るさ、撮影角度、牌の種類等)で撮影したテスト画像を用意しました。
※実際に撮影した正解データとテストデータ
| 各牌の正解データ | テストデータ(例) |
|---|---|
 |  |
以降、テンプレートマッチングとSSDで実装してみた結果を記載していきます。
OpenCVのテンプレートマッチングで実装してみる
テンプレートマッチングは、テンプレート画像を入力画像上でピクセル単位に走査させて類似度を計算し、入力画像上のどこに検出対象があるか位置を発見する手法です。物体検出の分野では比較的古典的な手法で、アルゴリズムもわかりやすく、各言語のライブラリも充実しているため画像処理初心者には取り組みやすいかと思います。
また、学習という概念がないため深層学習と比べると処理に時間がかかりません。ただし、一方でロバスト性に欠けます。具体的には、一つのテンプレートでは色々な大きさの物体を検索することが難しく、明るさ変動や回転等の変形にも弱いです。
今回はOpenCVというオープンソースの画像処理ライブラリを用いPython3で実装しました。
結論から言うと、いまいちでした。
| 検出結果 |
|---|
どこに何の牌が検出されたか、枠とラベルを描画しています。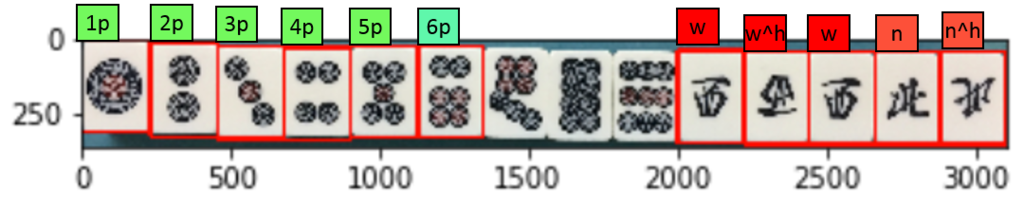 |
どの牌がいくつ検出され、検出されたもののうち適合率が最も高いスコアを記載しています。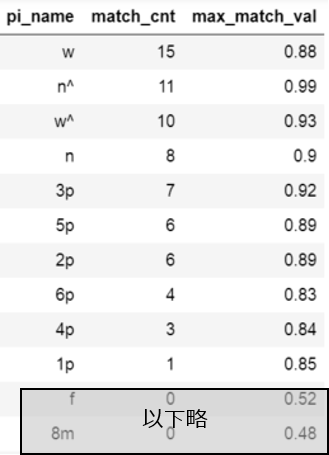 |
結果をみると、w(西)が15個、n^(北の上下反転)が11個、と1種類の牌が異常に多く検出されています。
理由は簡単で、前述の通りテンプレートマッチングはピクセル単位で入力画像上を走査しているため、1ピクセルでも異なれば1検出と判定されてしまうからです。
試しに、マッチした座標情報に対し、牌の横幅以上のピクセル数が離れていた場合にのみ、検出は有効とすることにしてみましょう。
※15個検出された「西」の場合
※なお、上記の画像のように余白が一切ない場合のみ有効
# 検出された15個のX座標を持った配列がテンプレートマッチングの結果で返ってくる
print(array_match_pixel_x)
[2000 2001 2002 2003 2004 2005 2006 2007 2438 2439 2440 2441 2442 2443 2444]
# 入力画像のwidth÷14で1牌の大体の大きさを算出した値で座標を割って少数点以下を繰り上げる
tile_size = input_img.shape[1] / 14
tmp_match_pixcel = [round(i/tile_size) for i in array_match_pixel_x]
cnt = len(np.unique(tmp_match_pixcel))
print(cnt)
2対処療法でしかないですが、これで正しく2個と判定されます。
ただし、問題はまだありそうです。

テンプレートマッチングは明るさや変形に弱いという特徴がありますが、この問題に取り掛かる前に、好条件下でも精度が悪い結果となりました。牌検出なんてサクッとうまくいくかと思っていたのですが意外とそうでもなかったので、次はSSDで試してみます。
個人的にテンプレートマッチングの結果で面白いなと思ったのは、リサイズせず画像に余白がある状態で検出して誤検出をしてしまう場合、牌の中に内包関係があるかないかが関係していそうだということでした。
下記図はどこで何に誤検出をしたかをまとめています。

確かに「三」という漢字の中には「一」も「二」も含まれています。
この結果は画像上を走査しているので当然の結果といえばそうかもしれません。
やはり、いきなり牌の判別に入るのではなく、牌の輪郭を検出をしてから判別する方が筋が良さそうですね。
麻雀の場合、1牌でも検出できなかったり誤検知があると、点数計算にダイレクトに影響し勝敗が変わります。要するに、精度ほぼ100%で牌を正しく検出できないとダメなのです。
2015年にWei Liuらが発表した物体検出(* 画像中の対象物がある範囲を四角の枠で検出して、そのカテゴリを分類する問題)アルゴリズムの一つです。アルゴリズムについては参考になる様々なQiitaや他のブログでの記事がたくさんあるので、本ブログでは細かい説明はしません。筆者も参考にさせていただいたので、興味がある方は是非それらの記事を参考にしてみてください。
細かい説明はしないとは言いつつも、簡単にまとめると以下のようになります。
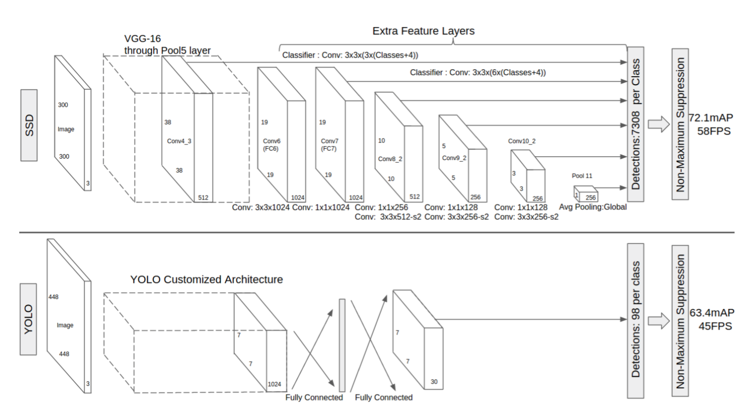
今回実装にあたり、Gitで公開されているkerasのコードを参考にさせていただきました(* https://github.com/rykov8/ssd_keras)。
冒頭でも述べた通り、入力画像には基本的には14個の牌が存在しています。
その入力画像上にどこに牌があってそれが何の牌かを知りたいので、牌の場所とラベルの情報を持った学習データを用意する必要があります。 これを人力で何千枚も用意するのは骨が折れます。
そこで今回は、適当な麻雀マット画像の上に、各牌のテンプレート画像からランダムに1牌選び、横並びで配置するジェネレータを構築しました。そうすることで1枚の画像の中に複数牌が横に並び、かつ牌の場所とラベルの情報を持ったデータが出来上がります。
なお、今回は使用している牌のみを学習することになるので牌の種類に対する汎化性がないという懸念点が出てきますが、プロトタイプとしての検証だと割り切り、気にしないこととしました。
学習データの画像のサイズは、SSD論文にも記載されていますが、試行錯誤の結果も踏まえ、高解像度の学習データがより精度が出たため、512×512でデータを作成しています。
実際に学習させたデータを例として4枚ピックアップしました。

SSDでは512×512のサイズで学習しているため、検出する際はそのサイズに入力画像がリサイズされます。今回撮影したテスト画像は横長の画像なので、モデルにインプットする際は牌が少し縦に伸びた形の画像となります。この現象が起きないよう、画像全体の上下にmarginを追加してアスペクト比が合うようにし、牌が引き伸ばされないようにリサイズした上で、モデルへのインプットとすることにしました。
入力画像(margin追加前)

入力画像(margin追加後)

– 学習にはGPUを使用しました
– GeForce GTX 960
– コア数:1024
– コアクロック:1127MHz
– メモリ容量:2GB
– バッチサイズ10、学習データ1000枚、バリデーションデータ200枚、50エポックで学習
– 学習にかかった総時間は10時間程度
– モデルのロバスト性を高めるための手法で、手元のデータに対して回転、拡大、縮小など人工的な操作をしてデータ数を水増しするテクニックのことです
– 今回は、元データに加えて、下記の操作を行いAugmentationしました
– グレースケール化
– 輝度変更(明るめ、暗め)
– コントラスト変更
– 向きの変更(上下左右のフリップ)
– サイズの変更(ランダム)
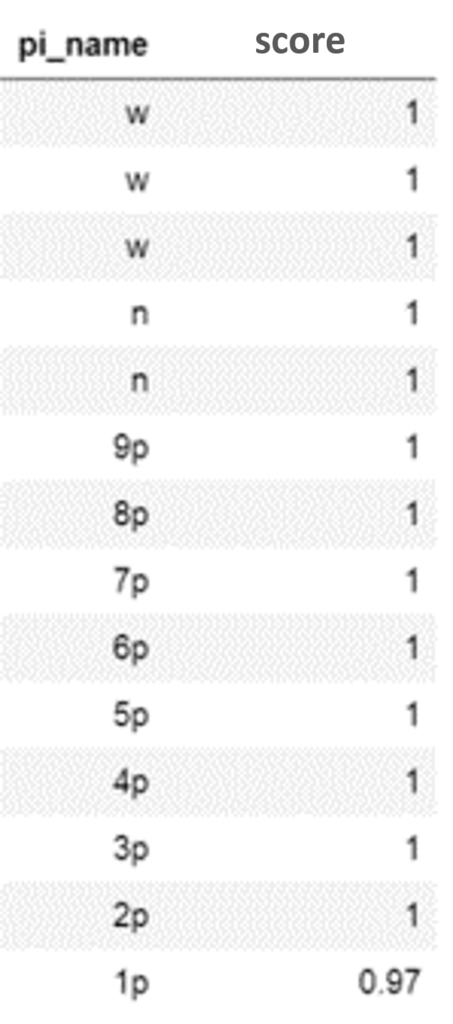
早速検出してみました。
| 検出結果 | 分類スコア |
|---|---|
 |  |
 | 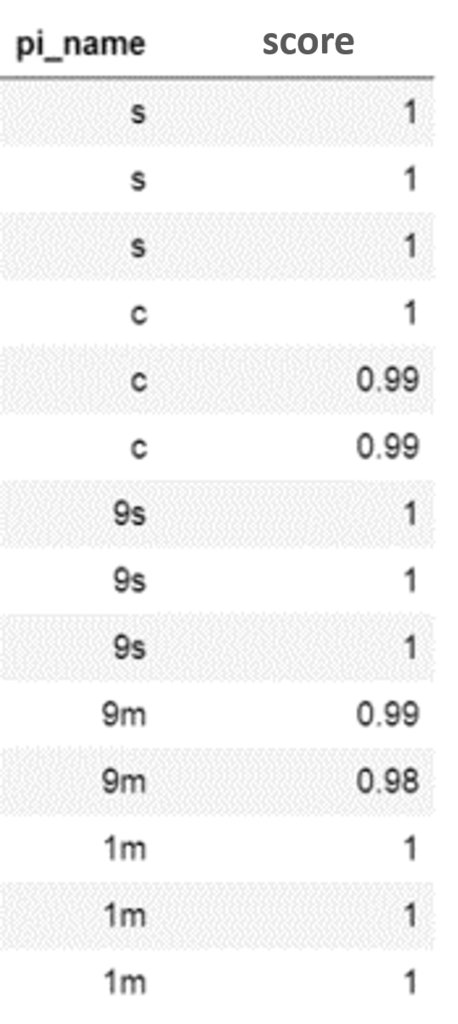 |
全牌ほぼ100%で検出できています。
ただし、前述の通り学習に使った種類の牌をテストデータで使っているため、他の牌だと精度が下がる可能性は高いです。
汎化性があるかどうか、様々な条件で試してみましょう。
まずは明るさを変更してみます。
| 明るめの画像 | 暗めの画像 |
|---|---|
  |   |
問題なさそうです。
ただ実際に麻雀中にここまで綺麗な写真を撮らないといけないとなると、冒頭で述べたように場が乱れてしまいます。ユースケースを考えると、以下のように少し斜めから撮ることが多いかと思いますので、それも試してみます。
| 検出結果(斜めからの撮影) | 分類スコア |
|---|---|
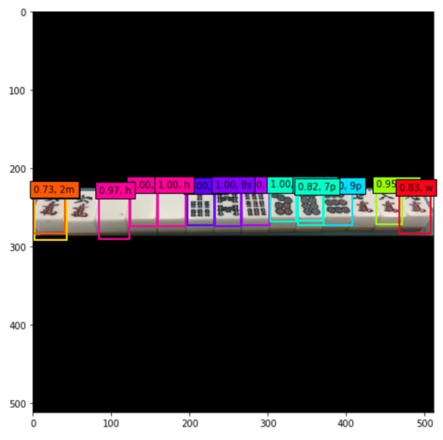 | 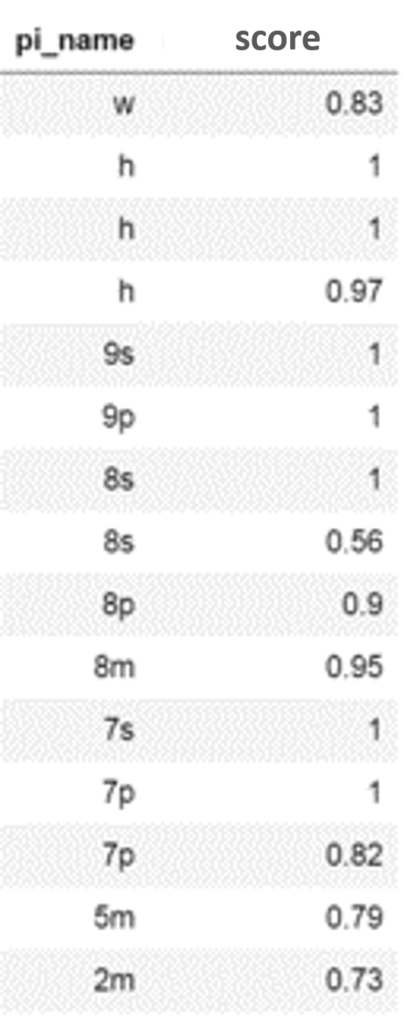 |
検出できている牌もありますが、できていない牌もあります。
上記の例だと分類スコアの閾値を0.7で切っていますが、牌によって検出のしやすさがありそうです。
牌毎に閾値を決めることも考えられますが、そもそも今回は斜めからみた牌は学習させていないので、セオリーとしてはアフィン変換等で斜め画像を生成して学習データに含めるのが良いかと思います。
最後に、違う種類の牌でも試してみましょう。
| 検出結果(非学習牌) | 分類スコア |
|---|---|
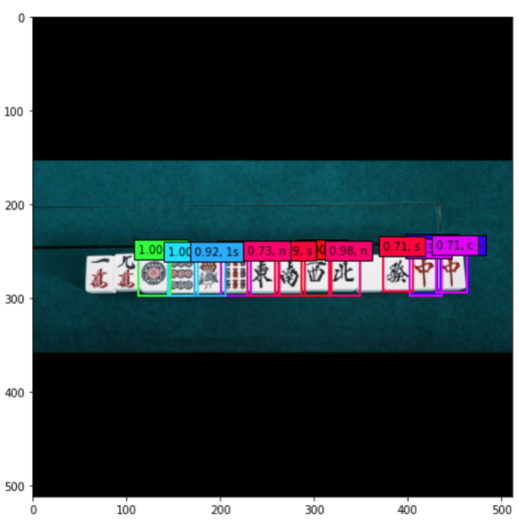 | 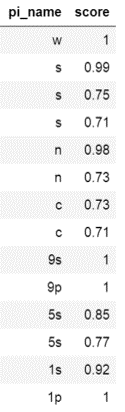 |
やはり牌に対する汎化性能が十分でないようです。
今回の場合、プロトタイプのため1種類の牌で完全に検出できれば良かったのですが、今後は学習データに色々な種類の牌を増やしていこうと思います。
特定の牌で、大体真上から撮影された画像であればほぼ100%検出ができ、自動役計算くんがなんとなく形になったことを休憩スペースでよく会う他本部の先輩に伝えたところ、
「試しにやってみようぜ!」
との声がかかり、実際に本アルゴリズムを使って点計算をすべく、フィールドワークという名のただの麻雀をしました。
※学習に使った牌を使って麻雀中です

某Yさん「ロン!満貫かな!?(嬉)」
某Oさん「いやいや、この自動役計算くんが全てだからね?」
早速計算させてみると・・・

某Yさん「ロン0点!?」
全員「wwwww」
物体検出と役判定は確実にできていましたが、どうやらその後の点数計算(ルールベース)コードにバグが残っていたみたいです。。
※後から知ったのですが、Pythonにはmahjongライブラリがあって、上がり牌と諸条件をインプットすると点数計算してくれるメソッドがあるので、今後はそれを使おうと思います。(* https://pypi.org/project/mahjong/1.1.2/)
今回はここまでですが、以降も引き続き改良を重ね、まだまだ改善の余地がたくさんあるものの、ゆくゆくはサービス化出来たらいいなぁと密かな野望を抱いております。
今回は麻雀をテーマに進めてまいりましたが、当社の分析業務も上記と基本的な流れは変わりません。
お客様の課題・要望を聞き、ユースケースを考えて求められる精度や制約を考慮した上で、データの前処理方法やモデリング手法を決定します。深層学習、AIはあくまでもツールに過ぎません。また、弊社の場合は初期段階で精度が芳しくなかった場合にどうやったら改善するか、このノウハウや経験を持った人間がたくさんいます。
本ブログで少しでもブレインパッドって面白い会社だな(ついでに麻雀面白いな、久しぶりにやろうかな)と思っていただけたら幸いです!
当社は、深層学習などの技術をビジネスに活用するべく、最先端の取り組みを積極的に実施しています。実際のビジネスで最先端の技術を活用してみたいという方、社員同士で一緒に切磋琢磨したい方は、ぜひエントリーください!
http://www.brainpad.co.jp/recruit/
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













