



ブレインパッドの社員が「数理最適化技術」に関して連載するこの企画。
記念すべき初回は、当社のCDTO(Chief Data Technology Officer)が、数理最適化に関する書籍の輪読会を通じて得たTipsをご紹介します!
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

記念すべき初回は、当社のCDTO(Chief Data Technology Officer)が、数理最適化に関する書籍の輪読会を通じて得たTipsをご紹介します!
こんにちは。CDTO (Chief Data Technology Officer) の太田です。
この記事は【連載】ブレインパッドの数理最適化ブログ(目次)の初回の記事です。
今回、「大阪大学数理最適化寄附講座」の開設に関わらせていただくことになったきっかけは、 TensorFlow User Group の有志の方々とともに主催している Optimization Night というコミュニティイベントでした。
現在、そのコミュニティのメンバー数名と週次の輪読会を開催しており、H. Paul Williams, Model Building in Mathematical Programming という書籍を読みすすめています。
この書籍は数理最適化のアルゴリズムではなく、定式化の部分にフォーカスを当てているのが特徴です。線形計画法の基本的な定式化方法から始まり、整数計画法の色々なテクニックが紹介されています。また、後半はすべて演習問題になっていますが、適度に複雑でやりごたえのある問題が揃っています。
理論面の記述が少ないため、本書だけで網羅的に理解するのは難しいですが、私のように数理最適化自身の研究ではなく実際に利用したいと考えている方にとってはとても良い本だと思います。
そこで今回は、輪読会の中で個人的に学んだこと・面白いなと思ったことを、定式化の Tips としてまとめようと思います。個人的な解釈も多分に含まれていますし、網羅的でもありませんが、このあたりをまとめた記事は少ないと思うので、定式化の際に少しでも参考にしてもらえればと思います。
輪読会で学んだことを紹介する前に、前提知識を揃えるという意味で、数理最適化の簡単な例を紹介したいと思います。
アイス生産問題
アイス屋さんが、エスプレッソアイス、ラズベリーアイス、2種類のアイスの生産を計画しています。しかし、材料の牛乳は 8000 cc、作業時間は述べ 360 分という制限があり、好きな分量だけ作れるわけではありません。それぞれのアイスに使う牛乳とかかる手間がこのようになっているとき、儲けを最大にする増産計画はどの様になるでしょうか?
引用: 「入門オペレーションズ・リサーチ」(東海大学出版会)
牛乳 作業時間 儲け エスプレッソアイス 100cc 7分 250円 ラズベリーアイス 150cc 5分 300円
数理最適化問題とは、「与えられた制約条件の下で目的関数の値を最小 (もしくは最大) にする解を求める問題」のことです。
決めたい変数(決定変数)、最小化(もしくは最大化)したい関数(目的関数)と制約で記述されます。この例題の場合、それぞれのアイスの生産量を (
は
(エスプレッソ)もしくは
(ラズベリー))、それぞれの作業時間を
とすると、
となります。ここでちょっと言葉を整理しておきます。
では、実際にフリーの汎用ソルバーを使って上述の問題を実際に解いてみましょう。使うのは PuLP というソフトです。 PuLP は
$ pip install pulpでインストールできます。
import pulp
problem = pulp.LpProblem('ice', pulp.LpMaximize)
# 決定変数を定義
x_e = pulp.LpVariable('x_e', lowBound=0)
x_r = pulp.LpVariable('x_r', lowBound=0)
# 目的関数を設定
problem += 250*x_e + 300*x_r
# 制約を設定
problem += 100*x_e + 150* x_r <= 8000
problem += 7*x_e + 5* x_r <= 360
# 最適化
problem.solve()
# 結果の表示
print(x_e.value(), x_r.value())以上は簡単な例ですが、定式化さえできれば汎用ソルバーを使うことで最適化問題を解くことができる、というのはわかっていただけたかと思います。ただし、
規模や問題によっては一筋縄ではいきません。そのため、実務ではいかに定式化するかがとても重要になります。
輪読会を始めるときに、「定式化について詳しい書籍がうれしい」という意見があがり、今の書籍を選択しました。
実応用を考えると、何らかの比率を最適化したいという場面が時々あります。例えば、費用対効果はかけたコストと得られる効果の比率のことですね。
本書では、線形計画法(LP; Linear Programming)と混合整数計画法(MIP; Mixed Integer Programming)を取り扱っており、目的関数も制約式も、決定変数について線形な式である必要があります。比率は当然線形ではありませんが、簡単な変数変換により線形な式の最適化問題に変換できます。
具体例を見てみましょう。目的関数が
$$ displaystyle mathrm{Maximize} frac{sum_{i} a_{i} x_{i}}{sum_{i}b_{i} x_{i} } $$
制約式が
$$ displaystyle sum_{i}d_{i}x_{i} leq e $$
で与えられるような問題を考えます。この問題は(分母の符号が変わったりゼロになったりしない前提で)以下の手順で線形な式に変換できます。
このあたりの話は、書籍の Chapter 3 で取り上げられています。
個人的に面白いなぁと思ったのは、最後の制約の部分です。\( x_{i} = frac{w _ {i}}{t} \) なので、一見分数が出てきてしまいそうですが、\(t \) には添字がないので右辺に移項できて、結局線形な制約に置き換わります。
最適化したい項目が複数あるときに、平準化をしつつ最適化したい、という要望もいろいろなところで出てきます。単純に定式化しようとすると、各項目の値の差分の合計を小さくしつつ、最適化して…と考えてしまいそう(少なくとも私ははじめそう思いました)ですが、最大値の最小化もしくは最小値の最大化を考えると、自動的に平準化された解が得られます。
Optimization Night #2 で梅谷先生に紹介いただいた電子ジャーナル購読計画 でも、購読雑誌の分野による偏りのない現実的な解を得るために、最小充足率の最大化を利用しています。
最大値の最小化は、割と素直に定式化できます。例えば、
$$ \displaystyle \mathrm{Minimize}\left(\max \sum _ {j}a _ {ij}x _ {j}\right) $$
を考えたい場合は、新たな変数 を使って、以下のように書けます。
$$ \begin{aligned} \mathrm{Minimize}&\ z \\ \mathrm{s.t.}& \sum _ {j}a _ {ij}x _ {j} \leq z,\quad \mathrm{for}\ ^{\forall}i.\end{aligned} $$
制約式(s.t 以降の式)によって、\( z\) は\( \sum _ {j}a _ {ij}x _ {j}\) のなかで最大のものよりも大きい値となりますが、目的関数で\( z\) を最小化しているので、結局\( \sum _ {j}a _ {ij}x _ {j}\) の最大値と等しくなります。
minimax型の目的関数を用いると求解時間が長くなったり暫定解の質が悪くなったりすることもあるらしいので、もしかすると使い所を選ぶのかもしれませんが、こういった条件を線形な式で表現できるというのはとても面白いなと思いました。
制約式で表現しづらい制約がある場合に、目的関数の性質を使うとうまく表現できることがあります。 前述のminimax型の目的関数も、目的関数が最小化されるという性質をうまく使ったものでした。
もう一つ、本書で取り上げられていて面白いなと思ったのは、演習問題にあった発電機の起動・停止問題で、以下のような設定です。
定式化の方法はいくつかあると思いますが、私は \( n _ {t}\) を時間帯 \( t\) に動いている発電機の台数として定式化しました(他には 0-1変数 \( x _ {ti}\)を使って、時間帯 \( t\) に発電機 \( i\)が動いているかを表す方法もあると思います)。
では、起動コストをどうやって表現したら良いでしょう?すぐに思いつきそうなのは、 \( a _ {t}\) を時間帯 \( t\) の起動台数(まさにその時間帯に起動した台数)として
$$ displaystyle a _ {t} = n _ {t} – n _ {t-1} $$
という制約を入れることです。
ただ、これはうまくいきません。需要に応じて発電機は停止することもあるので、場合によっては、左辺が負になりえます。一方、右辺の \( a _ {t}\) は新規の起動台数、増加分を表しているので、 常に \( a_{t} \geq 0\) のはずです。このように、「だいたいそうだけど、時々違う」ような制約はいろいろなところに出てきます。
では増加分だけを数えるにはどうしたら良いでしょうか? 実はとても簡単で、今やりたいのは正確には
$$ displaystyle a_{t} = max(0, n_{t} – n_{t-1}) $$
でした。これは、minimax型の目的関数と同様で
$$ \begin{aligned} n_{t} – n_{t-1} &\leq a_{t} \ 0 &\leq a_{t} \end{aligned} $$
という制約に置き換えます。もちろん、この制約だけでは、\( a _ t\) はいくらでも大きくできてしまいますが、今回の目的がコストの最小化なので、目的関数に \( \sum _ {t} Ca _ {t}\) (\( C\) は1台あたりの起動コスト) のような項があるはずです。この項により、最適解では \( a _ {t}\) は可能な限り小さくなり、結果として \( a _ {t} = \max(0, n _ {t} – n _ {t-1})\) となります。
こういった目的関数の性質を利用して、制約をうまく表現するテクニックは、知っている人は当然知っているものだと思いますし、私自身も過去に使ったことがあるですが、当時はあまり意識していなかったということもあり、あらためて面白いなぁと思った次第です。
混合整数計画法(MIP)と比較して線形計画法(LP)は解きやすいですが、実応用では整数変数を使いたい場合が多いです。整数変数は、主に以下の3パターンで使われます。
indivisible quantities や decision variables は、イメージしやすいですが、 実は indicator variables がかなり重要で、これを使いこなすと複雑な論理式を記述できるようになります。
indicator variables の例として、 \( x \geq 0\) を連続変数、 \( \delta\) を 0-1 変数とした時、\( M\) を \( x\) の上限として、
$$ \displaystyle
x > 0 \to \delta = 1
$$
という論理式を記述したいとします。この式は、( x ) の上限を ( M ) とすると、
$$ displaystyle x – Mdelta leq 0 $$
と書けます。実際、
1.\( x > 0 \) のとき
2.\( x = 0\) のとき
となります。この論理式の書き換えは非常に混乱しやすいので、以下にまとめてみました(多分あっているはず…)。前提として、\( m,\ M\) はそれぞれ \( x\) の下限値と上限値です。
| if-then | formulation | |
|---|---|---|
| 1 | ( x ) 0 to delta = 1″> | ( x – Mdelta leq 0 ) |
| 2 | ( x geq 0 to delta = 1 ) | ( x + epsilon – Mdelta leq 0 ) |
| 3 | ( x lt 0 to delta = 1 ) | ( x – mdelta geq 0 ) |
| 4 | ( x leq 0 to delta = 1 ) | ( x + epsilon – mdelta geq 0 ) |
| 5 | ( delta = 1 to x geq 0 ) | ( x – m(1 – delta) geq 0 ) |
| 6 | ( delta = 1 to x > 0 ) | ( x + epsilon – m(1 – delta) geq 0 ) |
| 7 | ( delta = 1 to x leq 0 ) | ( x – M(delta – 1) leq 0 ) |
| 8 | ( 1 to x lt 0 ) | ( x + epsilon – M(delta – 1) geq 0 ) |
ここで \( \epsilon\) は十分小さい数で、制約式では等号なしの不等号を使えないために必要になります。また、上の表は、 \( x\) の代わりに \( \sum_{i}a _ {i}x _ {i}\) のような数式であっても成り立ちます。
さらに、 indicator varibales 同士の条件を記述することで複雑な条件を記述できます。例えば、 \( R_1, R_2\) という制約があった場合に \( R_1\ \mathrm{or}\ R_2\) という制約を表現するには、上の表を参照して、
$$
\begin{aligned}
\delta_1 = 1 \to R_1 \\
\delta_2 = 1 \to R_2 \
\end{aligned}
$$
となるような indicator variable \( \delta_1,\ \delta_2\) を用意して、
$$
\displaystyle
\delta_1 + \delta_2 \geq 1
$$
という制約を追加します。\( \delta_1 + \delta_2 \geq 1\) であれば \( \delta_1 = 1\) もしくは \( \delta_2 = 1\) なので、\( R_1\ \mathrm{or}\ R_2\) となるわけです。indicator variable をチェインのようにつなげることで、もっと複雑な条件も記述できます。例えば、
$$ \displaystyle
R_1\ \mathrm{or}\ R_2\ \to\ R_3
$$
を表現するには、
$$
\begin{aligned}
R_1 &\to \delta_1 = 1 \
R_2 &\to \delta_2 = 1 \
\delta_3 = 1 &\to R_3
\end{aligned}
$$
となるような indicator variable \( \delta_1,\ \delta_2,\ \delta_3\) を用意して、
$$ \displaystyle
\delta_1 + \delta_2 \leq \delta_3
$$
とすればよいでしょう。論理式の indicator variable による表現をまとめると、以下になります。
| 論理式 | 表現 |
|---|---|
| \( X _ 1 \vee X _ 2\) | \( \delta _ 1 + \delta _ 2 \geq 1\) |
| \( X _ 1 \cdot X _ 2\) | \( \delta _ 1 = 1,\ \delta _ 2 = 1\) |
| \( \sim X _ 1\) | \( \delta _ 1 = 0\) |
| \( X _ 1 \to X _ 2\) | \( \delta _ 1 – \delta _ 2 \leq 0 \) |
| \( X _ 1 \leftrightarrow X _ 2\) | \( \delta _ 1 – \delta _ 2 = 0\) |
ここで、それぞれの記号の意味は、下記のとおりです。
| 記号 | 意味 |
|---|---|
| \( \vee\) | or (A or B or both) |
| \( \cdot\) | and |
| \( \sim\) | not |
| \( \to\) | implies (if … then) |
| \( \leftrightarrow\) | if and only if |
目的関数や制約式が、線形だったり比率の形になっていなかったとしても、区分線形近似をつかってMIPで定式化できます。具体的には、下図のように曲線を折れ線で近似してあげればよい、ということです。
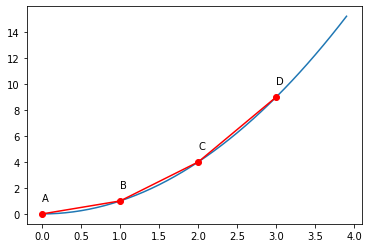
定式化のポイントは、線分 \( \boldsymbol{AB}\) 上の点は、\( \lambda \in [0, 1\)[/latex] を使って、\( \lambda \boldsymbol{A} + (1 – \lambda)\boldsymbol{B}\) とかけることです。例えば \( x ^ 2\) を区分線形近似するには、以下のようにします。
$$
\begin{aligned}
x &= 0\lambda_A + 1\lambda_B + 2\lambda_C + 3\lambda_D, \\
y &= 0\lambda_A + 1\lambda_B + 4\lambda_C + 9\lambda_D, \\
& \lambda_A + \lambda_B + \lambda_C + \lambda_D = 1.
\end{aligned}
$$
ただし、高々2つの隣り合う \( \lambda_{i}\) だけが非ゼロ
最後の「高々2つの隣り合う…」というのが厄介ですが、 \( \delta_{\alpha}\) を、線分 \( \alpha \)上であることを示す 0 – 1 変数とすれば、
$$
\begin{aligned}
\lambda_A – \delta_{AB} &\leq 0, \quad (\lambda_A は線分 \boldsymbol{AB} 上の時のみ非ゼロ)\\
\lambda_B – \delta_{AB} – \delta_{BC} &\leq 0, \quad (\lambda_B は線分 \boldsymbol{AB} もしくは \boldsymbol{BC} 上の時のみ非ゼロ)\\
\lambda_C – \delta_{BC} – \delta_{CD} &\leq 0, \quad (\lambda_C は線分 \boldsymbol{BC} もしくは \boldsymbol{CD} 上の時のみ非ゼロ)\\
\lambda_D – \delta_{CD} &\leq 0, \quad (\lambda_D は線分 \boldsymbol{CD} 上の時のみ非ゼロ)\\
\delta_{AB} + \delta_{BC} + \delta_{CD} &= 0. \quad (どれか一つの線分上にある)
\end{aligned}
$$
と書けます。「高々2つの隣り合う…」という制約に従う変数の組は SOS2 (Special Ordered Sets of type 2)と呼ばれています。 上記のように愚直に制約を書き下すのではなく、SOS2であることをソルバーに明示的に示してあげる(ソルバー毎にそういった機能が実装されています)ほうが計算効率が上がるそうです。
なお、上記の区分線形近似は、単変数もしくは分離可能な関数(単変数関数の和となっているような関数)に対しては有効ですが、例えば \( xy\) のように2つ以上の変数が絡み合っているような関数は、補完の方法が自明でなかったり、変数の数が膨大になってしまうという問題があります。輪読会に参加する前までは「区分線形近似最強だろう」と思っていたのですが、それはちょっとあまかったようです。
書籍では shadow price(潜在価格)や reduced cost(被約費用)といった、感度分析に関係するような話題が随所で取り上げられています。私は今までこのあたりをちゃんと勉強したことがなかったので、とても勉強になりました。
ここで感度分析とは「問題が少し変わった時に、どういう挙動を示すか」を分析することを言います。例えば、需要をもとに配送計画を立てる場合に、需要が少し違ったら、最適解にどういう影響が出るのか、を分析することです。 shadow price や reduced cost は大まかに言って
という意味を持ちます。はじめは、単に微分すればよいだけでは?と思ったのですが、制約式は不等式なので、単純に微分することはできません。手計算するのであれば、最適値のまわりで有効な制約(等号が成立している制約)だけに絞って変数を動かす必要がありそうです。
これらの値は双対問題と関係しており、汎用ソルバーが求解時に自動的に求めてくれます。 pulp では、 shadow price は LpConstraint.pi、reduced cost は LpVariable.dj で取り出せるようです。ドキュメントを探しても見つからなかったのですが、 公式のサンプルコード で利用されています(ファイル名が気になります)。
また、下記のリンクにあるように、MIPの場合の解釈には注意が必要そうです。
https://support.gurobi.com/hc/en-us/articles/360034305272-How-do-I-retrieve-the-Pi-values-for-a-MIP-problem
現実的な問題では、1つの値を最適化したいわけではなく、複数の観点で最も良いもの、バランスの取れたものを選びたい、という要望がよくあります。例えば、売上を上げつつコストを減らしたいとか、CVRとCTRを同時に上げたいといった状況で、いわゆる多目的最適化と呼ばれるものです。
最もシンプルですぐに思いつく方法は、それぞれ最適化したい指標に適当な重みをつけて足し合わせたものを目的関数とすることだと思いますが、輪読会では「重みの調整大変では?」という話になりました。実際項目が多い場合は大変だと思います。
その場で出た意見として「経験上は3〜4個程度までならうまく調整できることが多い。それ以上だと厳しかったりする」というのがあり、目安として良さそうだと思いました。
ちなみに、書籍では多目的最適化と関連してゴールプログラミングについても結構触れられていました。ゴールプログラミングは、トレードオフ関係のある制約がたくさんあり、全てを満たすのは困難な状況において、可能な限り制約を満たしたいという話で、後に紹介するように、制約を「ソフトな制約」と捉えて制約の違反量を最小化する問題に落とし込む方法です。
順列を決めるような問題のときに、実現可能なパターンを予め列挙してしまって、どのパターンを選ぶか、という問題に帰着させると解きやすくなることがあります。知っている人はみんな知っているんだろうと思いますし、確かに色々な事例を調べていると、パターンを列挙する解法はいろいろなところで使われています。
例えば最近読んだ文献 「ローリー車による液化天然ガス(LNG)販売事業のロジスティクス最適化の実現 」では、液化天然ガスの配送パターンを予め列挙しておき、どのパターンを選択するかという問題に帰着させることで、計算量を削減しています。
書籍の Chapter 8 で触れられていますが、いわゆる組合せ最適化問題には、順列を求めるタイプの問題と割当てを求めるタイプの問題があり、後者のほうが解きやすいことが多いようです。
パターンの種類が多すぎて列挙できない場合には、有用そうなパターンの候補を徐々に増やしていく、という方法もあります。これは列生成法と呼ばれるテクニックで、書籍では Chapter 9 で取り上げています。
私は列生成法に詳しいわけではないですが、興味のある方にはオペレーションズ・リサーチの はじめての列生成法 がとてもわかりやすいので、とてもとてもおすすめです。
“As such programs are often highly efficient and well-designed, their speeds outweigh the algorithmic efficiency of less well-designed but more specialized programs.”
(訳: そのようなプログラム(汎用ソルバー)は高効率で良く設計が洗練されていることが多いため、その計算速度は、設計の洗練されていない、より問題に特化したプログラムのアルゴリズムの効率を凌駕する)
読んでいて「ぐふっ」となったので挙げておきました。数理最適化問題を効率的に解くには、問題の構造をうまく利用する必要があります。例えばネットワーク構造があるような問題は、その構造に特化したアルゴリズムを使うことで、汎用的な方法と比べて非常に高速に解ける可能性があります。
が、しかし、汎用ソルバーも結構早いということを忘れてはいけません。自分が独自に実装した、問題に特化したプログラムは、日々改善され続けている汎用ソルバーに勝てるでしょうか?
ちなみにネットワーク問題は、流量の保存(各ノードに入ってくる量と出ていく量が等しい)を制約とすることで、素直に LP もしくは MIP として定式化できます。その際、一見MIPに見えるが実はLPとして定式化できる(連続変数であっても、最適解では自動的に整数値になるため、MIPとする必要がない)ようなことが多くあるため、求解が高速であるという事情もあるようです。
これは本書でも少し触れられていますし、 Optimization Night #2 でも取り上げられています。
数理最適化問題を解くには、ざっくりと以下の2種類の方法があります。
1.汎用ソルバーを使う
2.独自に最適化のアルゴルズムを組む
汎用ソルバーを使う場合は、問題に特化したアルゴリズムと比べて求解に時間がかかったり、問題の規模が大きくなると突如現実的な時間で解が求まらなくなることがある一方で、独自にアルゴリズムを組むと、コードのメンテナンスや仕様の変更への対応が難しいという問題があります。
数理最適化に限らず、プロジェクト初期に仕様が確定していることはほとんどありません。計画段階ではルールとして定めていたが、実際には少し破っても多めに見ているものがあったり、ルールには載っていないが暗黙的な制約や考慮しないといけない点があったりするのが通常なので、予めすべての制約を過不足なく洗い出しておく、というのはほぼ不可能です。そのため、実際のプロジェクトでは、要件の抽出と定式化のループを繰り返すことが多そうです。
さて、要望が変わる毎に継ぎ接ぎされた独自アルゴリズムのコードをメンテナンスしたいでしょうか? 私はできれば避けたいです。もちろんプロジェクトによって状況はさまざまですし、明らかに汎用ソルバーが向いていない問題も多いので、一概には言えませんが、特にプロジェクトの初期においては、速度が多少気になったとしても、まずは汎用ソルバーの利用を検討する、という方針はよさそうです。
当然といえば当然のことですが、輪読会の雑談の中もこういう話になり、確かになぁ、と思ったので挙げています。
先述のとおり、お客さんが教えてくれるルール(制約)には過不足があるのが一般的です。正しく定式化するには、どのルールが本当で、どのルールが偽物か、なんとかして判別しなければいけません。そこで、まずは過去データを制約式に入れてみる、という方法があります。過去データを投入することで、そのルールが「本当に守られているルールか」がわかるようになります。また、デバグという観点からも、過去データを代入してみるというのはとても重要です。
少し蛇足ですが、お客さんから言われたルールをとりあえず「ソフトな制約」として取り込んでみてると、どれくらいルール違反しているかがわかりやすい、というテクニックもあるようです。
制約式
$$ \displaystyle
\sum_{i}a_{i}x_{i} \leq b
$$
があった場合に \( u \geq 0\) を使って
$$ \displaystyle
\sum_{i}a_{i}x_{i} – u \leq b
$$
と書き換え、目的関数に \( u\) を追加します。すると、\( u\) は、ちょうど元の制約式の違反量に対応します。制約違反があった場合、元の定式化だとソルバーに infeasibleだと言われて困ってしまうのですが、ソフトな制約であれば、できる限り制約を満たしている解が得られるため、その後の検証がしやすくなります。
書籍の 6.1 Validating a model で学んだ内容です。機械学習のモデルがそうであるように、数理最適化のモデルもきちんと検証する必要があります。検証する、という観点から、数理最適化のモデルは大きく 3 つに分けることができます。
実行可能解が存在しないような状況です。この場合は定式化を間違えている可能性が非常に高いといます。なぜなら数理最適化は、今まで人手でやっていた仕事を置き換える、という状況で利用されることが多いためです。いま人手でやっているということは、最適とは限らないが実行可能解があるはずだということです。そのため、実行可能解がないということは、定式化が間違っている可能性が高いと考えられます。
実行可能解が存在しない場合、暫定的な解がどの制約を違反しているのか列挙するのは簡単です(代入して、制約を満たしているか確認していけば良いので)。ただし、その原因を見つけるのはとても難しいです。個々の制約によって実行不可能となるのではなく、複数の制約の組合せによって実行不可能となるためです。
だからこそ、制約をヒアリングしつつ過去データ(人手でやってきた記録)を入手しておくことがとても大事です。過去データを代入することで、違反している制約がないか確認できるからです。
次のパターンは、実行可能解は存在するが、いくらでも解を良くできてしまうような場合です。たいていの場合、制約の追加し忘れによって発生します。この場合は、ソルバーがある程度頑張った結果の解を出力してくれるので、その解を見ながら、抜けている制約を検討することになりますが、ソルバーの出力してくれる解は極端な値となっていることが多いため、制約を見つけるのは比較的簡単だと思われます。
最適解が得られたとしても油断してはいけません。現実的な解が得られているか見極める必要があります。ただ、ひとまず最適解が得られていれば、それを元に結果がおかしくないか検証したり、追加し忘れている制約がないか確認したりできます。前述の通り、初めから正しい定式化をできることは殆どないので、最適解が得られたとしても、検証を繰り返し、イテレーションをまわしながら定式化していくのが重要です。
検証の方法の一つに目的関数を設定せずに(もしくは目的関数を色々変えてみて)最適化計算をしてみるとよい、というテクニックがあるそうです。機械学習もそうですが、数理最適化モデルは、定式化が間違っていたとしても、それらしい解が得られてしまうことがよくあります。
目的関数を設定しなかったとしても、ソルバーは実行可能解を返してくれますが、目的関数に引っ張られることがないため、極端な解が出てきやすい傾向があるそうです。極端な解が得られれば、定式化の間違いに気づきやすくなります。
長い記事となってしまいましたが、最後まで目を通していただき、ありがとうございます。大阪大学の数理最適化寄附講座開設に関わるきっかけとなった Optimization Night の有志ですすめている輪読会で学んだことの中で、個人的に面白いなと思った Tips をピックアップして紹介しました。輪読会は現在進行中なので、 Tips ももう少し増えるかもしれませんが、その際はここに追記しようと思います。
Optimization Night はブレインパッドの太田としてではなく、太田個人として取り組んでいる活動です。(一企業のためではなく)技術者コミュニティを育てていけたらいいな、という思いでやっている活動で、まずは数理最適化界隈の方々が色々な情報を発信したり雑談したりできるような場を提供できたらなと思っているので、興味のある方はぜひご参加ください。
最後にお約束ですが…プレインパッドは今、数理最適化に真剣に取り組んでいます。こういった取り組みに興味のあるエンジニア・データサイエンティストを募集しています。数理最適化に興味のある方は、直近の転職意向の有無に関わらず気軽にお声がけください!
あと、輪読会やりましょう!一人で本読むよりたのしいよ!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













