



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

DXを推進する上で、ビジネス価値の高いプロジェクト成果物を得るためにデータサイエンティストの協力を仰いだり、データサイエンティストのマネジメントをしている方に向け、データサイエンティストのモチベーションやキャリア構築を考えるヒントの提供を目指した記事の後編となります。
前編では、ビジネス価値につなげるために分析プロジェクトの成果物が備えるべき2つの実コウ性(実効性: 効果が見込めること/実行性: 実際に使われること)と、データサイエンティストが持つ元来の強みのギャップ、中編では、データサイエンティスト自身がそのギャップを埋めるようなキャリア構築の方向性はあり得るかということについてそれぞれお伝えしました。
中編公開後から間隔が空いてしまいましたが後編では、高難度化しやすい「大規模・複合型プロジェクト」の例と、そこから見出されるデータサイエンティストのキャリアの方向性についてお話できればと思います。
上記について論を進めるにあたり、そもそも、高難度化しやすい「大規模/複合型プロジェクト」とはどういうものなのか、その定義や例、なぜ高難度化しやすいかなどについて冒頭でご説明します。より詳しい内容は、別記事「大規模・複合型プロジェクトが難しいワケ」で踏み込んでお話したいと思います。

「大規模・複合型プロジェクト」について読者の皆さんと認識をすり合わせたいと思います。
まず、大規模プロジェクトとは、読んで字の如く「プロジェクトの成果物(ソリューション)の検証や実装、利用・運用に関与する部署やレイヤー、人数が多岐に渡る」ようなプロジェクトで、典型的なものとしては特定課題に対する機械学習システムの実装や運用が成果物となるようなプロジェクトが挙げられるでしょう。
次に複合型プロジェクトですが、「階層構造や並列構造にあるプロジェクトが折り重なり、全体でひとつのプロジェクトを構成している」ようなものを想定しています。
例えば、どのような課題に取り組むべきか、すなわちどのようなプロジェクトを発足させるべきかを検討するためのプロジェクトから端を発するようなプロジェクトで、一例として下図のような構成を考えることができるでしょう。
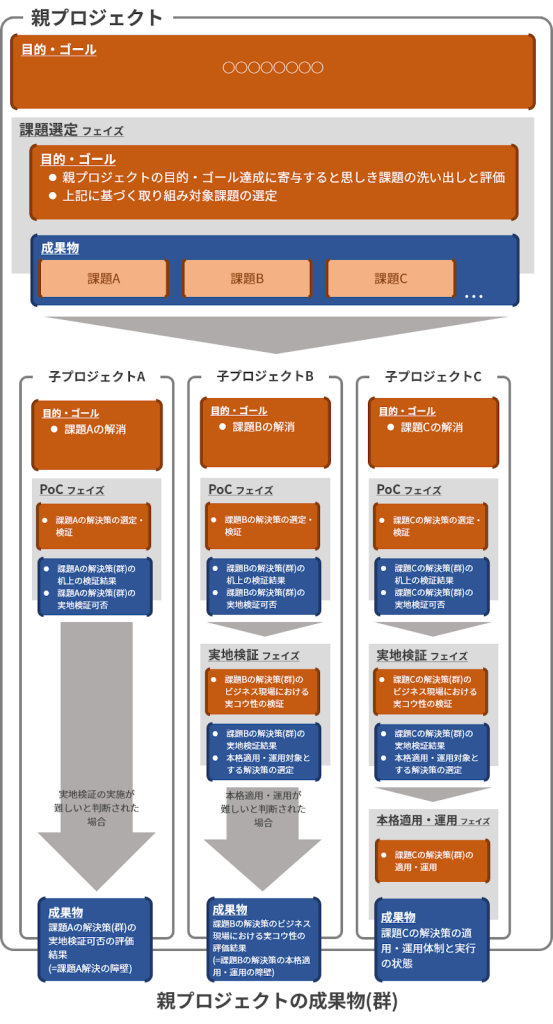
ここでは、一番大きな角丸長方形を一つのプロジェクト、灰色塗りの長方形をプロジェクトのフェイズ、濃い橙色の角丸長方形を当該プロジェクトやフェイズの目的・ゴール、濃い青色の角丸長方形を当該プロジェクトあるいはフェイズの成果物として模式的に表しています。
大まかな流れとしては、以下のように各子プロジェクトの成果物の総体が親プロジェクトの成果物となるようなイメージです。
上の図では、いくつかの子プロジェクトがペンディングされた状況を表現していますが、親プロジェクトを構成している全ての子プロジェクトが本格適用や運用に到達するわけではなく、フェイズの途中でペンディングにする方が合理的な選択になる状況も十分考えられます。階層型プロジェクトは、このように複数の子プロジェクト(より細かいプロジェクトに細分化される場合もあり得ます)から構成されているプロジェクトです。
DX推進の上流から取り組もうとされる場合には、この階層型のプロジェクトになりやすいかも知れませんね。
大規模・複合型プロジェクトについて、よりイメージの解像度を上げるために、サンプルとなるプロジェクトを考えてみたいと思います。
ある多種類の商材を取り扱う製造会社のケースを考えましょう。
この製造会社では、生産ラインの稼働率が高水準に保たれ、また、倉庫の占有率も恒常的に高い値になっているにも関わらず、欠品や納期遅延が多岐の製品に渡り、頻発していることが問題になっており、この問題を解消するためのプロジェクト(製品欠品・納期遅延解消プロジェクト)を立ち上げるとします。
このプロジェクトの目的・ゴールは、「製品の欠品・納期遅延を恒常的に解消するための仕組みが構築され利用・運用されていること」として良いでしょう。問題解消に向けたプロジェクト群の一例として、以下のようなものが考えられます。
※ なお、下表は上記のプロジェクト群を高い具体性を持ってイメージしていただくためのものであり、実際のプロジェクト群の組成は個々の状況に応じて行われるものであることから、実態に即していない可能性がある点にご留意ください。
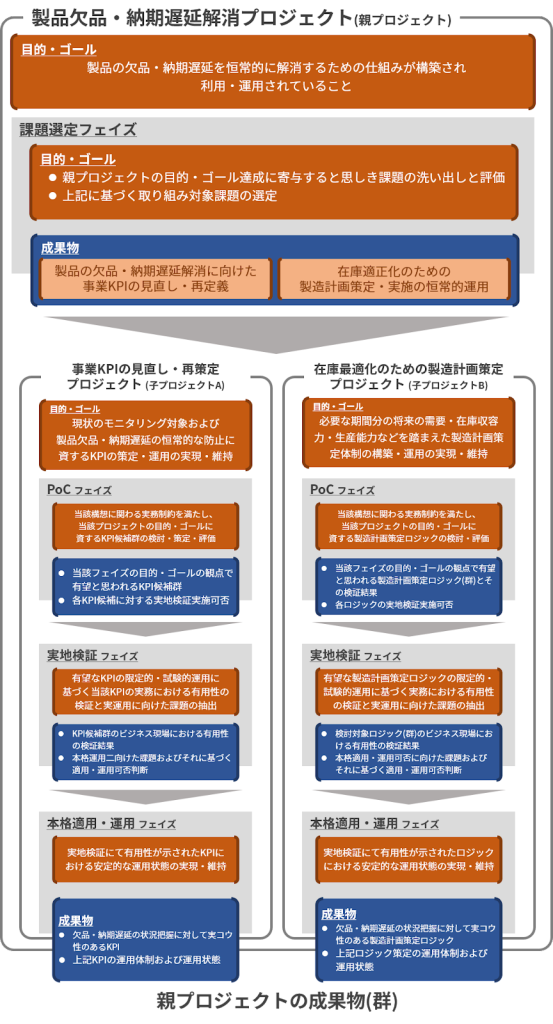
上記の「欠品や納期遅延が多岐の製品に渡り、頻発している」という問題に対して、「製品の欠品・納期遅延を恒常的に解消するための仕組みが構築され、利用・運用されていること」をゴールとしたプロジェクトを親とし、そのプロジェクト内の課題選定フェイズにて、上記ゴールに貢献すると思われる課題として、「事業KPIの見直し・再策定」(子プロジェクトA)、「在庫最適化のための製造計画策定」(子プロジェクトB)の2つが選定され、それら2つの課題を解消するための子プロジェクトが2つ組成されたような状況です。
本節では、大規模プロジェクトの具体例として、一つの抽象度が高く、その解消に臨もうとすると関連部署が多岐に渡るような「壮大な課題」の解消を目的とした親プロジェクトが、その目的達成のためにより具体化された課題の解消を目的とした複数の子プロジェクトにより構成されるようなケースを取り上げました。
前置きが長くなりましたが、ここまでをふまえて以下では、大規模・複合型プロジェクトにおけるデータサイエンティストの担当領域の典型例や、キャリア方針の一例について述べていきます。
上記のようなサンプルプロジェクトにおいて、最もわかりやすいデータサイエンティストの関与領域は「在庫最適化のための製造計画策定プロジェクト」(子プロジェクトB)、その中でもとりわけPoCフェイズとなるでしょう。
他にも、ビジネス的な観点・推進に強みを持つようなデータサイエンティストであれば「事業KPIの見直し・再策定プロジェクト」(子プロジェクトA)への参画も十分に考えられます。
PoCフェイズの成果物のうち、後続のフェイズに引き継がれるもの、具体的には「事業KPIの見直し・再策定プロジェクト」(子プロジェクトA)であればKPI候補群、「在庫最適化のための製造計画策定プロジェクト」(子プロジェクトB)であれば製造計画策定ロジック(群)ですが、これらが実地検証あるいは本格適用・運用のフェイズにおいて、ビジネスの現場にどのように落とし込むかについて各フェイズの担当者と摺り合わせを行うケースは珍しくありません。このような状況では、必然的にデータサイエンティスト自身が各フェイズの担当者と直接あるいは間接的に擦り合わせを行うことになります。
上記のサンプルプロジェクトにおいて、データサイエンティストの濃淡を含めた関与領域を図示すれば以下のように表現できるでしょう。
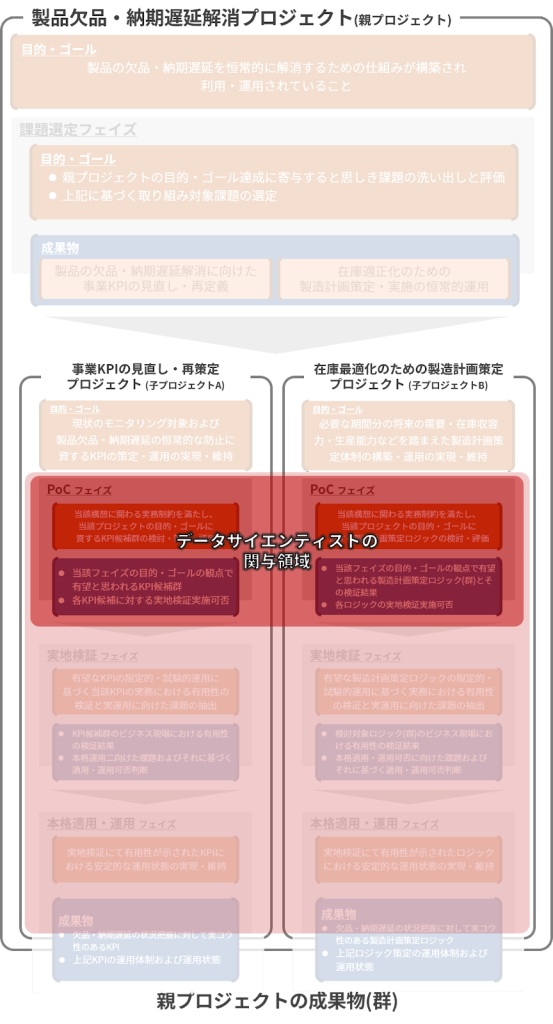
本稿のサンプルプロジェクトに限らず、データサイエンティストがPoCフェイズを担当するケースが多いでしょう。PoCフェイズの具体的なプロセスとしては、中編でお話した「要件定義」「分析設計」「分析実施・検証」「ビジネス適用」の内、「ビジネス適用」を除く3つと捉えていただいて差し支えありません。
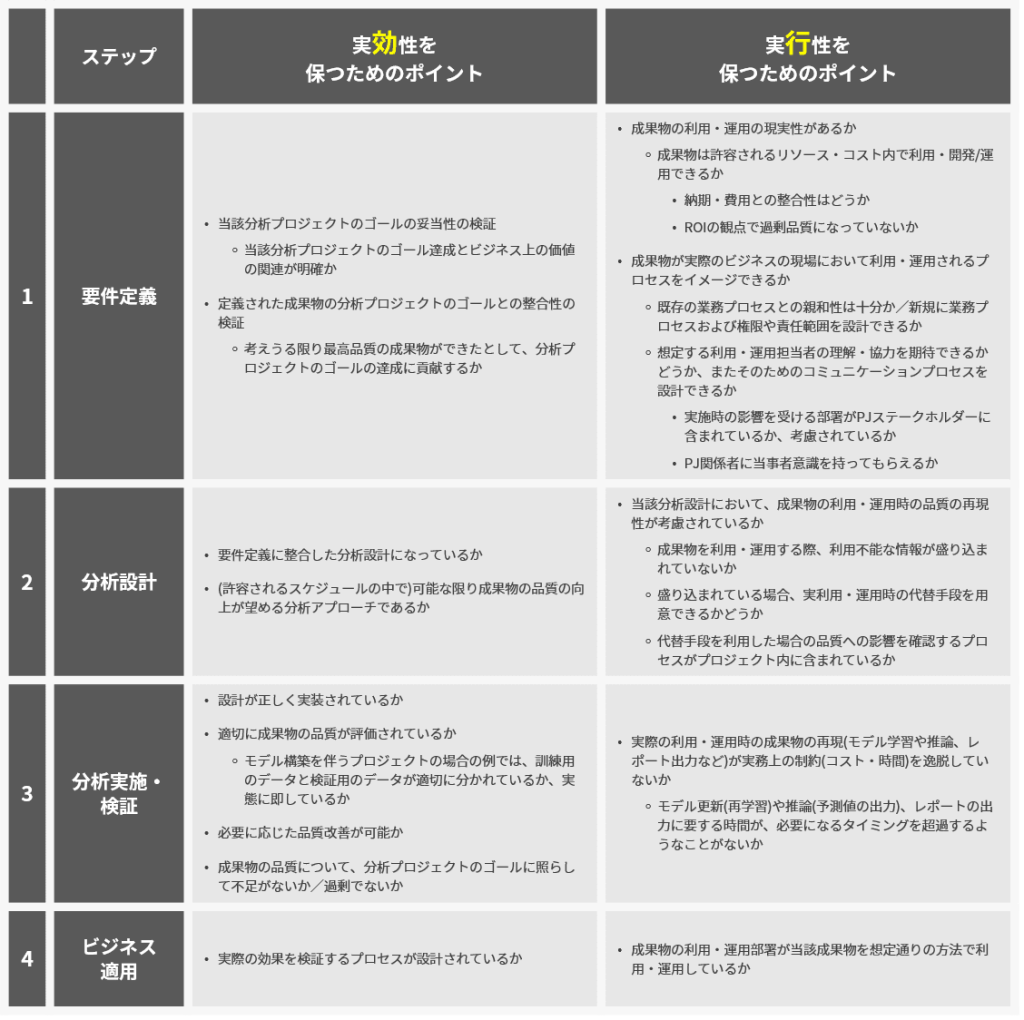
上記から、前・中編で紹介したようなデータサイエンティストの担当領域が大半となるプロジェクト(区別のために「小規模な分析プロジェクト」と呼びましょう)と大規模・複合型プロジェクトの違いは、大規模・複合型プロジェクトにおいてはプロジェクト全体に占めるデータサイエンティストの担当領域がPoCフェイズに限定されているだけのように見えます。より一般化して言えば、大規模・複合型プロジェクトでは、フェイズごとに担当する機能メンバーが異なっているだけのように見えます。
このような違いによって、なぜプロジェクトの難易度が上がるのでしょうか?そこにデータサイエンティストのキャリア展開の可能性がありそうです。
次節では、 大規模・複合型プロジェクトにおけるデータサイエンティストのキャリア方針の一例を述べます。
詳しくは別記事「大規模・複合型プロジェクトが難しいワケ」でお話ししていますが、大規模・複合型プロジェクトが難しくなりがちな理由として以下の3つが挙げられます。
これらが互いに絡み合ってプロジェクトの難易度を著しく高めていますが、現時点において筆者が考える難易度を緩和する方法は以下の2つです:
2.は比較的イメージを持っていただきやすいと思いますので、ここでは1.についてのみお話したいと思います。
プロジェクトのスコープを限定する方法として様々考えられますが、成果物の2つの実コウ性を保ちつつ、プロジェクトの難易度を抑えるという観点においては、原則として「実際のビジネスインパクトが評価できる最小のスコープにするべき」であると筆者は考えます。
もう少し具体的にご説明しましょう。
子プロジェクトは、典型的には、PoCフェイズ、実地検証フェイズ、本格適用・運用フェイズの3つに大別できることは前述の通りです。子プロジェクトにおいて、3フェイズのどこまでを対象にするかという点を縦のスコープ、対して子プロジェクトの成果物のユーザ部署をどこまで広げるかという点を横のスコープと便宜上呼ぶとするならば、「横のスコープを限定するべき」というのが筆者の考えです。
また、適用や活用を考える以上、業務プロセスを考慮しなければなりませんが、子プロジェクトの成果物の業務適用・運用しようとする際、影響がある業務プロセスも可能な限り小さくするのが望ましいと考えます。
横のスコープを限定し、ユーザ部署や業務プロセスの影響範囲を小さくしてしまうと、それらが活用・運用された際のビジネスインパクトも限定されやすくなるため、適切な意思決定でないように思われるかもしれません。それでも、筆者が上記のように考える最も大きな理由は「プロジェクト内で行われる試行錯誤1サイクル当たりのスピードが、時間当たりのプロジェクトの費用対効果に最も大きく作用するから」です。
試行錯誤のスピードに最も大きな影響を与える要因は、プロジェクト上の意思決定を行う上で必要になる情報の量と各情報のアクセススピード、加えてプロジェクト関係者間の合意形成や調整に係るコミュニケーションコストです。このコストを必要最低限にしようというのが横のスコープを限定することの狙いです。
ここまでお話したことも含め、横のスコープを限定することで得られる具体的な効能を以下に列挙しましょう。
別記事「大規模・複合型プロジェクトが難しいワケ」でお話ししている3つの理由との対応関係でお話すれば、「高難度要因(2) プロジェクト進行の合意形成に掛かるコミュニケーションコストの大きさ」と「高難度要因(3) 『重視される実コウ性』のシフト」を抑制する対策と言えます。「高難度要因(1) PoCフェイズに関わる不確実性」は分析による検証フェイズを含むプロジェクトにおいて本質的に低減出来ないので、そのほかの要因を低減し、プロジェクト内で許容される試行錯誤の回数を増やすことで対応しようというのがスコープ限定の狙いとも言えます。
ところで、試行錯誤のスピードを上げることが、なぜそれほど重要なのでしょうか。
一言で言うなら「PoCフェイズを伴うプロジェクトの『成果』は、プロジェクト時間に比例して大きくなるとは限らない」、もう少し踏み込んでいえば、「PoCフェイズを伴うプロジェクトの『成果』は、プロジェクト時間に関して線形で積み上がらず、当該時点までの最大値で規定される」ことが最も大きな理由です。
説明が複雑になってしまうので進行中のプロジェクトにおける「成果」をどのように定義するかについては別の機会でお話できればと思いますが、大まかには当該時点で見込めるビジネスインパクトと考えていただければここでは十分です。
プロジェクト時間に関して線形に成果が積みあがる代表例は建築でしょう。建造物が立ち上がるまでの具体的な手順やスケジュールが明確に規定されており、時間の経過に従い、建造物は徐々に出来上がっていきます。
これに対して、PoCフェイズを含むプロジェクトではそのようには進捗しません。
時間の経過によって着実に蓄積するのは「これまで検証した中で最も有望だったアプローチ」と「それ以外のうまくいかなかったアプローチ」、加えて「より有望と思われるアプローチの候補」です。ところが、プロジェクトの「成果」として規定されるのは「これまでで最も有望だったアプローチの実装によって見込めるビジネスインパクト」であるので、時間の経過とともに逐次的に『成果』が更新される可能性があるだけで、必ず更新されるとは限りません。
このように「成果」が最大値で規定されるという性質から、より大きな「成果」を得るためには試行錯誤の回数を増やすより他ないというのが、筆者の考えの最も大きな要因です。
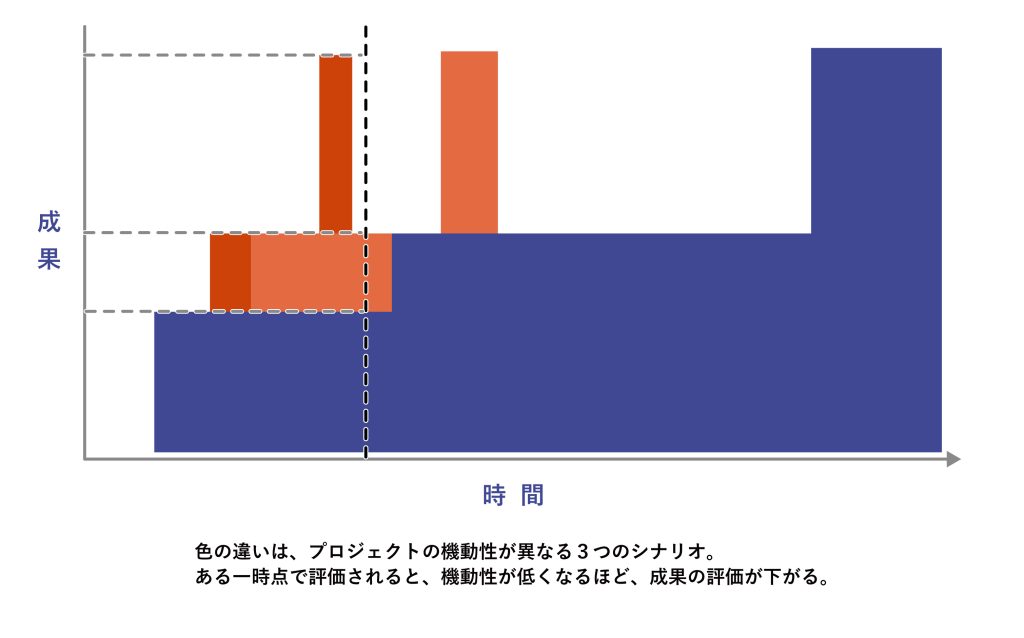
下図は、試行錯誤1サイクル当たりの検証時間が長い場合とそうでない場合のプロジェクトの成果の比較を模式的に表したものです。単純に試行錯誤1サイクル当たりの期間が延びているだけですが、ある一時点の成果で評価すれば、当然1サイクル当たりの期間が短い方が常に同等以上の成果を生めることが直感的にお分かりいただけるのではないでしょうか?
スコープの限定のご説明のお話が長くなってしまいましたが、この節では、階層型・大型プロジェクトの難易度を緩和する方法として以下の2つを紹介しました。
DX推進の気運の高まりに従って、プロジェクトの大規模・複合型化していく傾向にあります。基本的なプロジェクト進行のプロセスとしては大きく変わりませんが、プロジェクトが大規模・複合型化すると関係者の多さ・利害の多様さに由来して、2つの実コウ性を担保すること極めて難しくなります。
こちらについては、別記事「大規模・複合型プロジェクトが難しいワケ」にて、詳しく触れておりますので併せてご覧くださいませ。
前節にて、上記の困難に対する向き合い方の一例として、以下の2点についてお話しました:
プロジェクトを取り巻く環境によって上記の各オプションが採用できるかどうかは変わるかと思いますが、上記のオプションの共通要素は、プロジェクト設計のタイミングやプロジェクト進行における意思決定を伴う局面において、どのようにプロジェクト全体の2つの実コウ性を担保できる視点を保つかという点です。
より踏み込んで言えば、大規模・複合型プロジェクトにおいては、上記のような視点を持っている人材、あるいはそのような視点をプロジェクト関係者に提供したり、都度共有・リマインドさせることが出来るような人材が重要であると言い換えられます。プロジェクト内の具体的な役割で言えば、プロジェクト全体の意思決定に関するかなり大きな発言権と決定権と責任を負う役割・人材、例えば、統括プロジェクトマネジャーなどがそれに当たるでしょう。
データサイエンティストこそ上記の働きができる数少ない人材であるというのが私見です。
上記の働き、具体的には、プロジェクトの全体に渡り、2つの実コウ性の観点を反映させるためには、
の2つが必要となりますが、これら2つの要件は両実コウ性を保つことが実務として求められない限り、なかなか備わるのは難しい類の要件です。
中編においても触れたように、データ分析を含むプロジェクトではどのような規模のものであっても2つの実コウ性を保つことが求められますし、別記事「大規模・複合型プロジェクトが難しいワケ」の高難度化要因(3)で触れた「A. ビジネスKPI責任者」「B. ビジネス実務担当者」「C. データサイエンティスト」「D. 機能準備・実装担当者」の4つの人格においても、その役割の遂行にあたり2つの実コウ性の両方が求められるのは、唯一データサイエンティストだけです。
以上が、筆者が「プロジェクト全体に渡り2つの実コウ性の観点を提供し続ける役割」の一候補としてデータサイエンティストを推す大きな理由です。
この名前もまだ付けづらいような役割は、データサイエンティストのキャリア構築の一つの方向性として考えられるでしょう。この役割は、DX推進という現在のビジネストレンドにおいて、中核の一つとなる存在であることから需要の高まりが予想されますし、同時にその遂行に求められる能力発揮の範囲や「データ分析」への関心・興味を基点とするデータサイエンティストの志向性の整合性の観点から、その希少性は極めて高いものになるでしょう。
本稿では、横断型・階層型プロジェクトの高難度化しやすい理由を大まかにご説明したのち、その成功に貢献する重要かつ希少な役割に対するデータサイエンティスト人材の適性の観点から、データサイエンティストのキャリア構築の方向性について触れました。
また、シリーズ全編を通じて、データ分析を含むプロジェクトにおけるデータサイエンティストの能力発揮領域を広げる形でキャリア構築の方向性についてお話してきました。
最後に直近のビジネストレンドとデータサイエンティストのニーズについてお話して締めくくりたいと思います。
データ分析はもはや、ビジネスにおいて要不要を検討するフェイズではなく、実施して当たり前と言えるほど無くてはならないものになりつつあり、昨今のDX推進の気運の高まりはその後押しとなっています。この観点において、データサイエンティストのニーズは今後も高まるように見えます。
一方で、昨今のChatGPTなどのLLMモデル等、生成系AIの登場に代表されるAIの民主化も一般の生活者にとってさえ身近な形で世に現れ始めており、分析技術の選定や実装というプロセスにおいてAIが提供する品質やスピードを人力のみで超えるのは日々難しくなっていくように思われます。
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
このAIの民主化に関連して、プロジェクトの成果物がビジネス価値を生めるかどうかは、分析技術の選定や実装の品質やスピードだけで直ちに決まるものではないというのは重要な視点です。シリーズ全体を通じてお話してきたように、分析技術を一部とするプロジェクトの成果物が、ビジネス上の目的・目標(実効性)と、ビジネス実務における実行可能性(実行性)の両方を備えられるようにして初めてビジネス価値が生まれる点についてはいくら強調してもしすぎることはないでしょう。
上記のトレンドの中で、世の中全体のデータ活用リテラシーが成熟するにつれて、どのような規模のプロジェクトであれ、分析技術の制約や限界を理解しながら成果物を設計、実装していくことのできるデータサイエンティストのような役割は今後ますます求められるものになると筆者は考えています。
データサイエンティストやそのリード・マネジメントの役割を担われる方、データサイエンティストのキャリアや育成を検討される方にとって参考になれば幸いです。
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













