



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

ブレインパッドの執行役員で、金融インダストリーの責任者である神野雅彦です。一般社団法人金融データ活用推進協会(以下、FDUA)では、標準化委員会 委員長代行を務めています。
FDUAでは、金融機関におけるデータ活用の標準化に資するために「金融データ活用組織チェックシート」(以下、チェックシート)の初版を2023年6月末に制定・公開しました。
チェックシートに関しては、「金融機関初となるデータ活用の標準化に向けた取り組みとは? ~FDUAと考える金融データで人と組織の可能性をアップデートする方法~」ですでに紹介しておりますが、チェックシート策定に中心メンバーの一人として参加した神野から、背景、目的および今後の取り組み目標を改めてお話ししたいと存じます。6つあるテーマの概要も併せて概説します。
金融業界は、他の業種・業態と比較して、データ活用やDXが遅れていると評価される傾向にあります。この遅れを解消し、金融業界が積極的なデータ活用に取り組めるようにすることがFDUAの設立の目的でもありました。
【関連記事】
2024年版|金融DXで主に解決される3つの課題とDX事例7選
ただ、そもそもデータ活用やDXが本当に遅れているのか、感覚値で終わっているのではないか、遅れているとしたら現在地はどの辺りなのかを確認するための手段やツールがありませんでした。
そこで項目を必要最低限に絞り込みつつ、網羅性を担保し、設問も答えやすい内容にしたチェックシートを策定することにしました。手軽かつ迅速に自社のデータ活用の現在地を確認でき、さらに今後の施策を検討できることが目的です。また各社のチェック結果を集計することで、国内金融機関のデータ活用進捗度と成熟度を可視化します。そうすることで、現在地を認識し、弱点を明確化しつつ、克服するための対策を取ることができるようになる。結果的に、業界全体のレベルアップが促進されると考えたからです。
チェック項目は、利用データ、組織、ビジネス効果、データ基盤、人材育成、ガバナンスという6つのテーマにカテゴライズされています。このうち利用データ、組織、ビジネス効果は活用レベルに、データ基盤、人材育成、ガバナンスはインフラレベルと位置づけました。活用レベル、インフラレベルのそれぞれにおいて、自社の現在地を認識できるようにしています。

1回チェックして終わりではなく、定期的に実施することで、自社の立ち位置を経時的に明確化できます。また、FDUAでは回収したチェックシートを年次など定期的に集計することで、金融業界全体の傾向を発信していくことを予定しています。
対象とする業種は金融業界全般、すなわち銀行、信用金庫、証券、保険、信託銀行、カードリースなど、金融庁の管理監督下にある機関すべてが使えるものにしました。どの業種でも膨大かつ構造化されたデータを持ち、慎重に情報を取り扱わなければならないという共通点があります。こういった金融機関に特有の状況を踏まえたチェックシートになるように検討したということです。
ただ、たとえば銀行と証券と保険では業務がかなり違うのはもちろん、同じ銀行でも都市銀行と地方銀行ではまた大きく違っています。今回は初版ということで、共通でくくれる深さまでにとどめ、業種による細分化は今後進めていきます。
今回の初版のチェックシートは組織に特化したデータ活用レベルになっています。個人のスキルは含まず、企業として評価することを念頭において項目を洗い出しました。
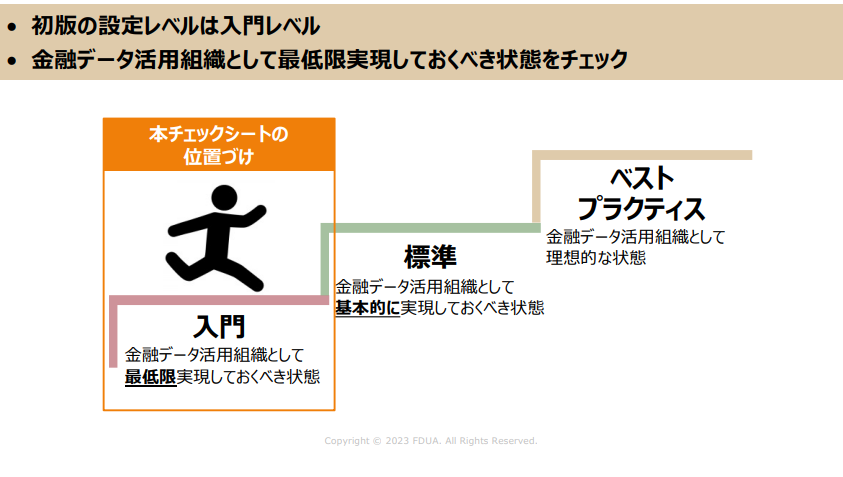
設定レベルに関しては、今回は入門編とし、最低限実現すべき状態を目指せるようにしています。今後は標準として基本的に実現すべき状態と、ベストプラクティスを併せて提示していく予定です。
結果は集計して、ベンチマークを実行します。ベンチマークをどこまで公開するか、そもそも公開するのかも含めて、関係各社による今後の合意が必要と考えています。したがってあくまで今後の目標ではありますが、標準会委員会としてはベンチマークを見ながら金融業界の現状把握をし、参加企業はベンチマークと比較することで施策が検討できるようにすることを考えています。
プレチェックにおいて、30社の金融機関に参加をいただき、その結果をベンチマークしました。見えてきたのは、ビジネス効果、ガバナンス、利用データといったカテゴリーが伸び悩んでいる中、データ基盤は整備されているということでした。
しかしデータ基盤も老朽化しつつあり、さまざまな課題を抱えていることも同時に見えてきました。ChatGPTやSnowflakeなどのツール類もかなり普及していますが、使いこなすための知見や人材、組織がまだまだ整備できていないことも明らかになりました。
評価していく上で、評価項目の分類が必要になります。今回策定したチェックシートでは、先ほど挙げました利用データ、組織、ビジネス効果、データ基盤、人材育成、ガバナンスの6つに分類しています。

それぞれの概要は以下の通りです。
原則としてDMO(Data Management Office)的な組織の方に回答していただくことを想定しています。ただし場合によっては、データサイエンティスト自身やIT部門の方などが回答することも想定しています。
各テーマで10個ずつ、トータルで60個の設問を用意しました。30分程度でセルフチェックが完了することを目標にした数です。検討時には200個強ぐらいまで膨らんだのですが、それでは煩わしくて使われないと判断し、必要最低限で網羅性を担保できるように精査しました。
回答の選択肢も答えやすさを重視して、段階的な回答ができる5択(出来ている/どちらかというと出来ている/どちらかというと出来ていない/出来ていない/対象外)にしました。選択肢に「対象外」とあるのが、必ずしもすべての事項に取り組んでいる金融機関ばかりでもなく、必須の取り組み事項ではないことも考慮して、未回答項目を無くし回答しやすくするために工夫したところです。
以下で、チェックシートをテーマ別に解説します。説明の順番は、ベンチマークのスコアが低い順、つまり課題が多そうなテーマからに始めていきます。
チェック項目の検討にあたっては、テーマごとの検討会でまず洗い出しました。その後、すべてを集めて、他のテーマとの重複を避けつつ、網羅的な内容になるよう検討しました。
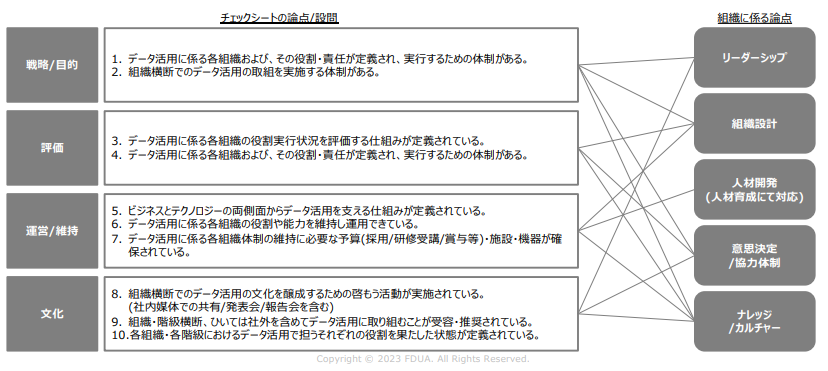
組織テーマに関わるチェック項目は、戦略/目的、評価、運営/維持、文化の4つのカテゴリーで構成しました。

戦略/目的は、データ活用に関わる組織の戦略や目的を明確化しているか、主軸としているか、あるいはその明確化、明文化、意識統一、理解浸透が全社でしっかり定義されているかなどをチェックするものです。戦略や目的が曖昧なまま取り組んでいる場合には、それに気づけるように構成しています。
評価は、DMOすなわちデータ活用の推進や実行に関わっている組織の活動がきちんと評価されているか、評価自体が仕組みとして完備できているか、データ活用に適切な予算をつけて継続的に取り組んでいるか、ビジネス効果につながっているか、業務改善につながっているかなどをチェックします。
DMOだけでデータ活用しているのではなく、むしろDMOがビジネスサイドに入り込んでいって一緒に取り組めているか、ビジネスサイドがDMOを受容してビジネス効果を享受するといった全社的な文化醸成も含めて評価します。
運営/維持は、データ活用を実行するために必要な仕組みが整っているかを見ます。人材やテクノロジー基盤も関連しますが、テクノロジーだけに偏らず、ビジネスとテクノロジーの両側面が融合されているかを重要視しています。また一時的にプロジェクトを立ち上げるだけではなく、継続的な能力の維持向上を念頭に置いた組織作りをしているか、そのための予算取りをしているかも重要な論点です。
文化は、データ活用を組織的に浸透するための仕組みを具備できているかが論点になります。データ活用の利点、データ活用のやり方、ビジネス上でのデータドリブンな判断などはもちろん、データ活用によって恩恵を得られる風土作りや評価制度の見直し、浸透具合のモニタリングや取り組みの受容評価等も含みます。「文化醸成よりも優先度が高いものがある」という組織も結構あり、「実行あるのみ」というスタイルの組織もあります。このような組織では、原因はよくわからないがデータ活用がうまく進まないということになりがちですが、状況を把握できるように設問を設定しています。
以上が、組織テーマの4つのカテゴリーになります。これとは別にチェック項目を洗い出すための論点として、リーダーシップ、組織設計、人材開発、意思決定/協力体制、ナレッジ/カルチャーの5つを挙げました。
チェック項目は1つのテーマにつき10個ずつという制約を設けましたが、5つの論点それぞれで2つずつという考え方にはせずに、カテゴリーと論点を照らし合わせて網羅的にチェックできるような項目にしています。人材開発については、人材育成テーマで対応することにして、設問数の調節をしました。
人材育成は、データサイエンティスト協会やブレインパッドが提唱している3つの力をベースに考えました。

見つける力、解く力、使わせる力の3つを、人材育成の際には押さえなければいけないと考えています。しかし3つの力をすべて持っている人は一個人ではなかなかいませんし、育成するのも非常に難しいことです。ほとんどの人は「見つける力・使わせる力に秀でたビジネス系の人材」か、「解く力が強いデータサイエンティスト系の人材」のいずれかになります。とはいうものの、論点としてはこの3つの力を軸に考えるべきです。データ活用と聞くと解く力を思い浮かべる人が多いのですが、ある程度実用的な分析ができればよいということであれば意外と身につけやすい能力です。一方で見つける力と使わせる力に関しては、ビジネス・スキル、コミュニケーション能力、ロジカルシンキングなど高度なスキルが要求される領域になります。
以上の論点を踏まえた上で、どうやって人材を育成していくかを考えると、戦略策定、準備、育成、評価の4つのステップで進めるのがよいという結論になりました。

戦略策定は、どういう人をどうやって育てるかを定義し、また育成の期限と目標を決めるステップです。準備は、教育コンテンツの整備や育成手法の決定になります。準備したことを実行するのが育成であり、その結果ビジネス課題が解決されているのかを評価します。そして評価をフィードバックして次の育成に役立てるというPDCAサイクルを回していくことになります。
この4つのステップごとにそれぞれチェック項目を挙げていき、トータルで10個の設問を用意しました。
ここで留意すべきことは、ビジネスで実際に効果を得るのは、意外とハードルが高いということです。実際には育っていても、毎回必ずビジネス成果が出るわけではありません。データ活用はトライ&エラーの世界なので、1ラウンドや2ラウンドでは結果が出ないことのほうが多いわけです。チャレンジすることが大事であり、素早く、何度でも、あきらめずに試行できる人材に育てることが重要であり、そのことを踏まえた設問となっています。
利用データは、DAMA(データマネジメント協会)の「DMBOK2」を踏まえて、データ利用、データ品質、データ管理、データ運用の4つのカテゴリーを設定しました。
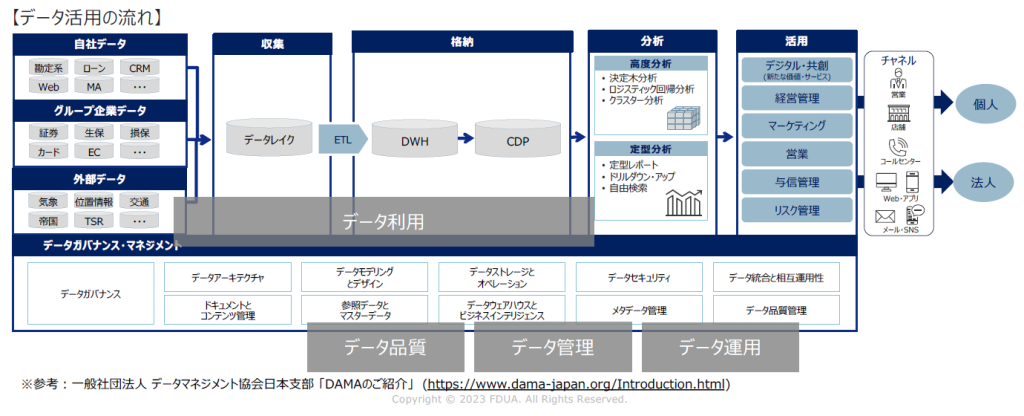
収集と格納というデータ利用の部分にフィーチャーしながらも、全体を支えるデータガバナンスやデータマネジメントの観点も踏まえて、品質・管理・運用についても取り上げた形となりました。
データ利用は、対象データの蓄積状況や活用状況で評価します。分析データのソースとなる業務システムとデータベースも含めて見ていく形になります。
データ品質は、データが直ちに分析できるところまで整理されているかを評価します。品質に関してよく言われるのが、データの鮮度の話です。データが古いがために分析結果がおかしいといったことがないように最新データが使われていなければなりません。また需要予測など傾向を予測する分析では、データの期間とボリュームが問題になってきます。
データ管理は、データの収集・管理がデータ利用の目的に則してなされているかを評価します。何のためにどのようなテーマに取り組んでいて、そのためにどんなデータソースを使っていて、それらを適切なメディア等に格納して維持しているかということです。さらに1回切りではなく、定期的に収集・管理するプロセスがしっかりと作られているかも論点になります。
データ運用は、実際に運用するためのデータ化をどうするか、データフローをどうやって可視化するか、運用手順が整備されているか等を評価します。誰が今、何をしているのかまでしっかりと把握できるのであれば、それに越したことはありません。
ビジネス効果は、その名の通り、ビジネスに対していかに効果が出せているのかを評価する内容になっています。
ビジネス効果のライフサイクルは、計画を立てて、実行・評価し、改善していくという大きな3つのステップを繰り返していくものです。データサイエンスにおいては、課題を見つけて、分析して、課題を解いていくというシーケンシャルな流れがイメージされがちですが、実際には分析結果を踏まえて高度化や効率化の精度を高めていくサイクルになります。したがってデータサイエンスとビジネス効果のライフサイクルは相似形になるわけです。

計画は、目標が明確化されていて、目標達成のための施策素案が作られ、そこから分析テーマが設定されているかを評価します。掲げた目標が企業戦略、中長期計画、事業計画といった上位層の目標から順次落とし込まれたものになっているか、その目標を達成のための施策素案や分析テーマになっているかを見ます。
実行・評価は、施策実施前に関係各所の合意形成できているかを評価します。つまりビジネスサイドとデータサイエンスサイドが同じ方向を向いて進んでいるか、また実行結果に関する評価についてもビジネスサイドが関心を持っているか等を見ることになります。ビジネスサイドはデータ活用に興味がないことが多いのですが、それではデータ活用が進みません。データ活用によって自身のビジネスが変わること、恩恵を最大化するには自身が関与すべきことを理解していただくことが必要です。
改善は、評価結果を受けて対応策を実行しているかを評価します。PDCAを回し続けてより高度化していくことが必要であり、さらにビジネス効果が生まれれば他の業務に横展開していくことが望ましいのです。しかし、どうしても早期の成功を求めがちになり、第1ラウンドで失敗したらそれで終わるパターンがよくあります。そうではなく、少しずつ成功確率を高めながら、あきらめずにチャレンジを継続していくことが大事なのです。そのことを意識して取り組んでいるかを評価できるようにしました。
以上3つのカテゴリーをベースに、目標設定ができているか、分析テーマと施策がひも付いているか、関係各所との合意形成ができているか、目標の達成度合いを確認できているかなどを評価するために10個の設問を考えました。また回答をサポートすることを目的として、実際にブレインパッドが関わった金融系の事例からピックアップした「分析テーマ事例一覧」も作成しています。
データ基盤は、基盤構築の要件を決める際の論点ということで、機能と非機能に分けてチェック項目を用意しています。機能も非機能もそれぞれ膨大な情報量があるので、それをトータルで10項目に落とし込むのはかなり難航しました。

そこでブレインパッドおよびIPA(情報処理推進機構)のフレームワークを元に、データソース/データ取得、データ加工/蓄積、分析/自動化、可用性、性能拡張性、運用・保守性、移行性、セキュリティー、システム環境/エコロジーといった論点で整理すれば、初版で目標とした入門レベルとしては十分ではないかと考えたのです。
なおデータ基盤テーマとすでに説明した利用データテーマとでは、近しいところがどうしても出てきてしまいますので、そこをできるだけ分けて構成しています。
ガバナンスは、組織・態勢、利活用プロセス、個別論点の3つのカテゴリーに分けました。ここで「組織のリスクマネジメントにおける3つのディフェンスライン」という少々難しい話が出てきます。事業部門を1線、管理部門を2線、内部監査部門を3線として、それぞれにリスク管理上の役割を負わせることで内部統制をしっかりやろうという考え方です。

まず3つのカテゴリーごとに、1線、2線、3線でそれぞれ何が求められるのかを整理しました。しかしそのまま使うと10個の設問に落とし込むことは難しいので、DMOサイドが評価できることを第一に整理しました。たとえば組織・態勢では、ガバナンスに関わる組織体制の構築ができているかどうか、つまり経営層がしっかり関与しているか、組織設計ができているか、ポリシーや人材像がきちっと定義できているか等について。利活用プロセスでは、データ活用プロセスの定義がしっかりできているか、企画・データ分析・モデリング・運用における仕組み作りにおいて会社としてガバナンスを効かせられているか。個別論点に関しては、金融機関にとって特に重要なセキュリティー、プライバシー、倫理、さらに外部リソース管理を取り上げて設問を構成しました。
なおブレインパッドでは、攻めのガバナンスと守りのガバナンスという言い方をよくしますが、チェックシートの質問項目に関しては、どちらかと言えば守りが中心になっています。
今後の取り組みついては、1つ目が第2版に向けてどういった内容で構成するかです。FDUAの年度は7月から始まるので、新年度計画ということで6月末までにすでに計画を立てています。
まず2023年7月から12月までにチェックシートに回答してくださる金融機関の数として100社を目指していきます。100社のデータが集まればかなりしっかりしたベンチマークができますので、そこまで持っていければと思っています。
続いて、年明けの1月から6月に第2版の策定をします。よりわかりやすく、かつ客観性を持って回答できるようにチェック項目や回答方法を改善します。また金融機関への特化をさらに推し進めます。さらにチェックしながらアクションにつながる気づきが得られるようにします。並行して、金融データに関する規制や他のガイドラインとの整合性も可能な限り追求していく所存です。
それから、現在のチェックシートはExcelで提供されていますが、これをWebシステム化します。Web化に伴い、経年蓄積による変化の把握やベンチマークも実現できるようにします。
ベストプラクティスも定義していきます。各種成功体験や失敗体験をベースに、このようにすると良い、あるいはこのようにするのが望ましいといった、あるべき姿が提示できるといいと考えています。それに伴い、認定制度を設けて、企業のブランディングに活用できるようにしていきたいと考えています。
金融機関の細分化にも取り組みます。銀行、証券、リースなどそれぞれの業種に特化したチェックシートを作る予定です。
チェックシート策定は中長期的に推進していくテーマであると考えています。金融業界のデータ活用組織を高みに導いていくだけではなく、業界全体の業務の高度化や効率化といった新しい領域への展開を目指しています。
データ分析プロセスやデータ活用プロセスの標準化、AI開発プロセスの標準化、データモデルおよび項目の標準化などが主なテーマで、標準化委員会として、まさしくデータ活用標準化の推進を考えているのです。そのためには、ハンドブックやガイドラインを制定して発信し、データ活用の標準を浸透させていくことが重要だと言えます。
最終的に目指すところは、「真の民主化」です。データ分析官やDMOに所属する方々は、誤解を恐れずに言えば「選ばれた民」です。「民主化」の意味は、「誰もが」という意味だと理解しています。誰もが能動的に気軽に、スマートフォンやタブレットでちょんちょんとタップすればデータを活用できるようにならないと、「真の民主化」とは言えません。そのような状態の実現に寄与できるのがFDUAであり、標準化委員会です。したがってそこに参加している私たちが、意識して「真の民主化」を目指すことは非常に重要だと考えます。
今回、初版策定において、多くの検討メンバー、標準化委員会のコアメンバーおよび事務局の方々が毎日夜遅くまで、強いパッションを持って取り組んでくださいました。そのことに改めて深く感謝いたします。
おかげさまで初版として満足のいくチェックシートができあがったと思っております。これからも高度化を目指してまい進していく所存ですので、引き続きご協力をお願いできればと思っております。
また、是非金融機関の方々には、チェックシートの利用を推進していただければと思います。特に、年1回でも十分ですので、定期的にチェックを実行し続けてみてください。現在地の変化を認識できるとともに、結果をFDUAに提出いただければ管理の上、経年で状況を見える化させていただきます。また、次に取るべきことへの相談もいただければ、ご支援をさせていただきます。
不明点やご要望については、金融データ活用推進協会/FDUAのWebサイト(https://www.fdua.org/)にご連絡いただければと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













