



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

ChatGPTをはじめ、大規模言語モデル(LLM:Large Language Models)に代表される生成AI(GenAI:Generative AI)は、インターネットを通じて簡単に利用することができ、今や私たちの生活に身近なものとなりました。
【関連】
しかし、生成AI・LLMをいざビジネスに適用しようとした場合、どのように検討を進めればよいのでしょうか。
そこで本記事では、従来型AIモデルと生成AIモデルの違いについて整理し、生成AIが抱える諸リスクを踏まえた上で、読者のみなさまが生成AIをビジネスに適用される際の検討ポイントおよびユースケースをご紹介します。
本記事を読了されたみなさまが、生成AI・LLMのビジネス適用について、より具体的なイメージをお持ちいただければ幸いです。

株式会社ブレインパッド アナリティクス本部 アナリティクスサービス部の佐藤光です。現在は、データサイエンティストとして、主にデジタルマーケティング分野の分析支援や、データ利活用の業務設計に携わっています。
OpenAI社のChatGPTをはじめ、大規模言語モデル(LLM;Large Language Models)に代表される生成AI(GenAI;Generative AI)は、インターネットを通じて、様々なサービスを簡単に利用でき、さらに、APIも提供されているため、私たちの既存サービス・システムへの機能拡張等、その応用範囲は多岐にわたります。
本稿では、生成AIの大いなるポテンシャルをみなさんのビジネスに取り込んでいただくため、「生成AIはどのように活用できるのか?」「ビジネスに適用する場合には、どのように検討を進めたらよいのか?」に焦点を当て、生成AIのビジネス適用に関するポイントをご紹介します。
生成AIとは、入力として与えられた情報をもとに、出力として新たな情報(主にテキスト、画像、動画、音楽、プログラムソースコード等のマルチメディア)を生成する人工知能(AI)の総称です。大規模言語モデル(LLM;Large Language Models)も、生成AIの一つであり、テキスト情報を含む大規模データをもとに学習され、億単位を超えるパラメータ数を有するモデルです。
代表的なLLMサービスであるWeb版ChatGPTを例に挙げると、ユーザーは自然言語を用いて、入力フォームからリクエストすることで(これをプロンプトと呼びます。)、所望の情報処理タスクを実行することが可能となります。代表的な情報収集タスクとしては、質問・要約・翻訳・情報収集などが挙げられます。他にも、テキスト情報から画像生成、テキスト情報から音楽生成、テキスト情報からプログラムのソースコードを生成するサービス・モデルがあります。
このように、生成AIは「数値情報を予測・分類する」振る舞いだけではなく、「幅広い情報を生成する」振る舞いが実現でき、私たちのビジネス貢献への大きな可能性を秘めています。

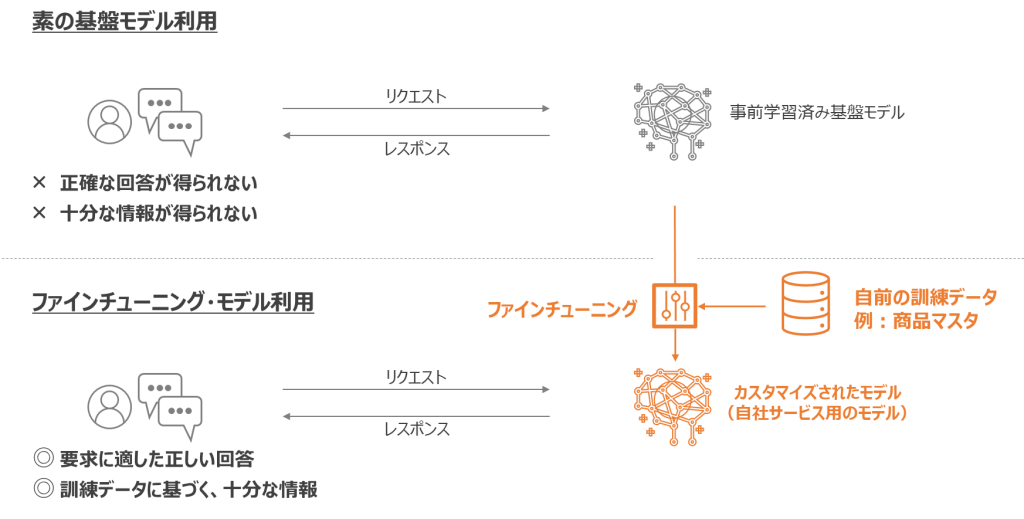
生成AIは、ソースコードのみ提供されているものもありますが、広く知られるサービス・モデルには、事前学習済み基盤モデル(PFM;Pretrained Foundation Models)(※注1)として提供されているケースがあります。事前学習済み基盤モデルとは、大規模データをもとに汎用性能の獲得を目的に事前学習したモデルです。スケーリング則(※注2)の発見をうけて、プラットフォーマーをはじめ世界中の組織・団体は、莫大な資金を投じて、LLM等の基盤モデルを構築しました。
このような背景から、LLMをはじめとした生成AIは、事前学習済み基盤モデルとして多く提供されており、私たち利用者は、その恩恵を大いに活用できます。事前学習済み基盤モデルは、提供されているデフォルトのモデルでも、汎用的で高い性能を示すことが知られています。さらに、精度向上を図るために、自組織のデータを学習させるファインチューニングと呼ばれる機能も提供されています。ファインチューニングにより、自組織の業務やサービスに特化したモデルへとカスタマイズすれば、ビジネス活用においても、より実践的なAIへと昇華させることができます。
【関連】社内文書に特化したChatGPT ファインチューニング実践編
※注1:事前学習済み基盤モデルは、単に「基盤モデル(FM; Foundation Models)」と呼ばれることもある
※注2:スケーリング則は、Scaling Laws for Neural Language Modelsで発表された「モデルの性能が、計算量・データセットサイズ・パラメータ数に応じて、べき乗則で向上する」という法則。この発見は、AIモデルの大規模化が進む一因となった。
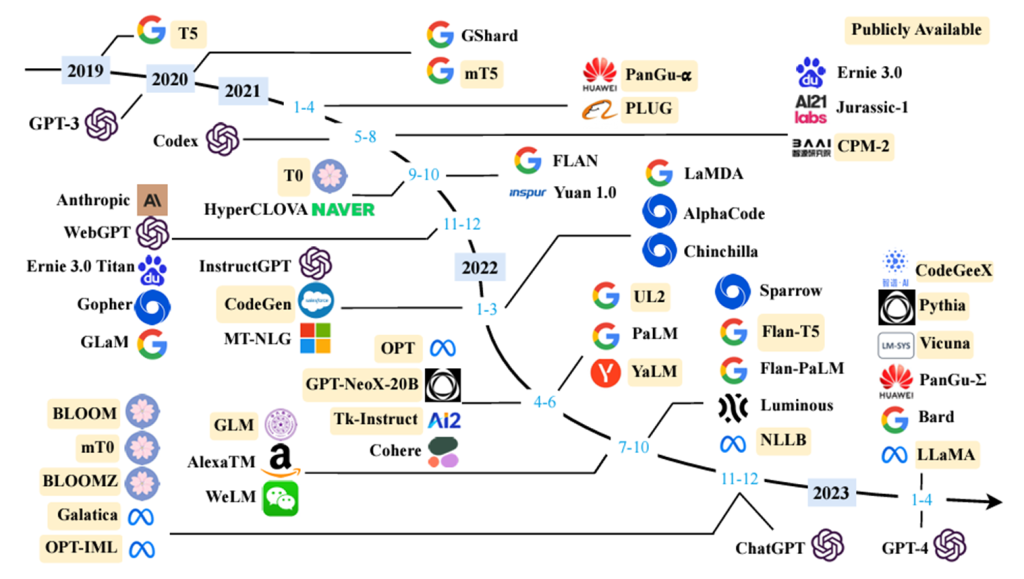
ここからは、従来までのAIモデルと生成AIモデルの違いを見ていきましょう。
従来、私たちがAIモデルを利用したいと考えた際には、次のような開発工程が必要でした。
この開発工程を経て、AIモデルの結果として獲得できる情報は、数値情報や識別結果のクラスラベルといった情報がメインでした。自前で構築・カスタマイズしたAIモデルは、私たちのビジネスにおいて大きなインパクトを生み出してくれています。一方で、以前までは、AIの価値を獲得するためには、「データ収集・蓄積」や「モデルの学習・調整」に多くの労力を払う必要がありました。
無論、今後も、解きたい課題によって、従来同様の開発工程が必要となるケースもあることでしょう。一方で、生成AIが得意とする領域・課題においては、既に用意された学習済み基盤モデルを利用・応用することで、「データ収集・蓄積」や「モデルの学習・調整」の工程を省力化しつつ、より高度な情報処理が期待できます。
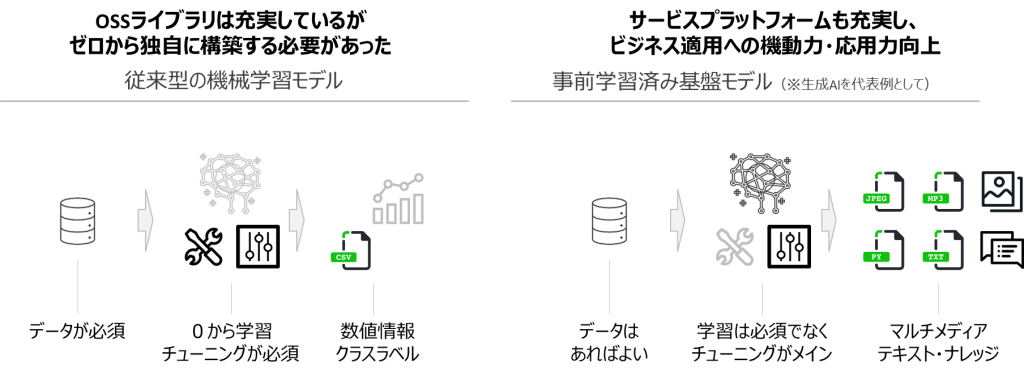
本章では、私たちのビジネスに生成AIを導入するために、「どのようにプロジェクトを推進したらよいか?」「どのように検討を進めたらよいのか?」について、ポイントを解説します。
生成AIは、基盤モデルおよびWebサービスとして容易に利用開始できます。その一方で、こちらの連載記事『【連載①】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-LLMの使用許諾条件- – Platinum Data Blog by BrainPad 』にて紹介した通り、いくつか注意を払う点があります。例えば、生成AIが抱える代表的なリスクとして、以下のような観点が挙げられます。
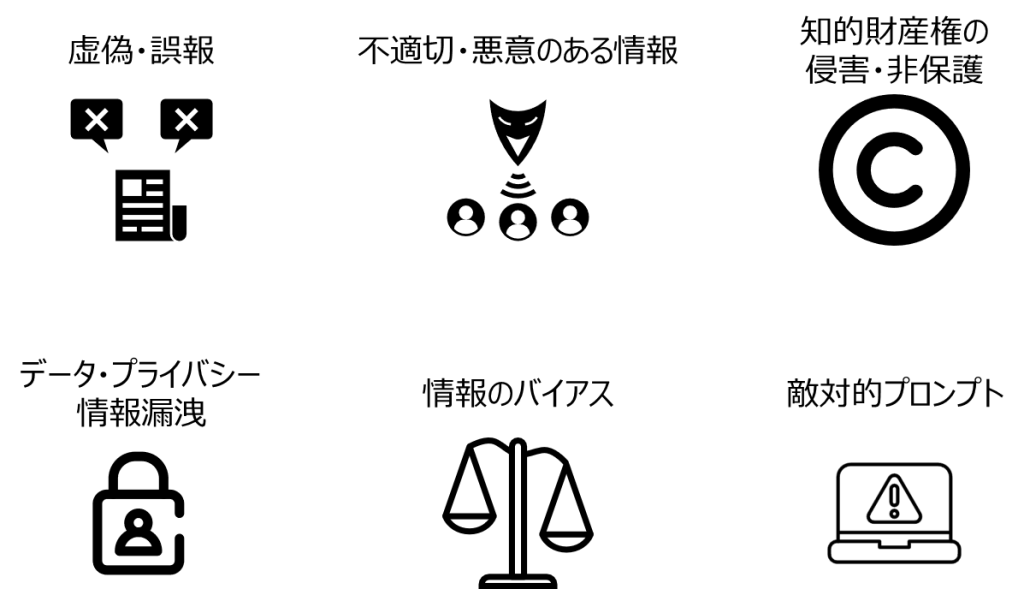
私たちがビジネスに応用する際には、革新的な機能が備わっているからといって、直ちに導入するのではなく、従来のAI導入プロセス同様に「検証工程」を置くことが重要になります。
プロジェクト推進の一例を図示します。生成AIのビジネス適用においては、特に、PoC(Proof of Concept)フェーズにて、生成AI特有の機能・性能・リスクを考慮した、業務・サービス・機能設計が肝要となります。
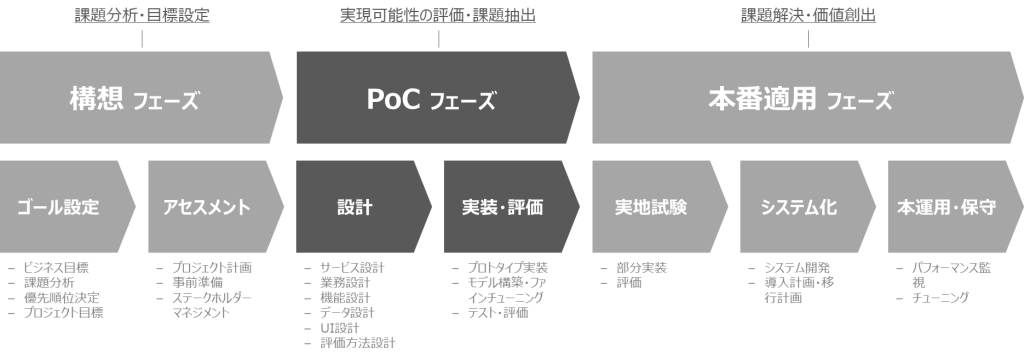
PoCフェーズでは、ビジネスユースにおける生成AIの実現可能性を検証することが重要となりますが、あくまでビジネス課題の解決が目的であることを忘れてはなりません。構想フェーズ及びPoCフェーズの結果を踏まえた上で、最終的に「生成AIモデルではない課題解決手段」を採用することも、重要な意思決定となります。
【関連】
私たちのビジネスに生成AIを導入する際、設計工程における検討事項は、活用先である業界・業種・ビジネス、あるいは、活用先組織の前提となるインフラ環境・セキュリティポリシーによって、多岐にわたります。しかしながら、生成AIサービスや機能、その性質を踏まえると、異なる業態においても、共通する検討事項は存在するものと考えられます。
そこで、本節では、生成AIをビジネス適用する上で必要となる検討項目を例示します。仮説のケーススタディとして、LLMの代表事例であるチャットボットへの生成AI技術適用を想定し、検討すべきポイントを考えてみましょう。
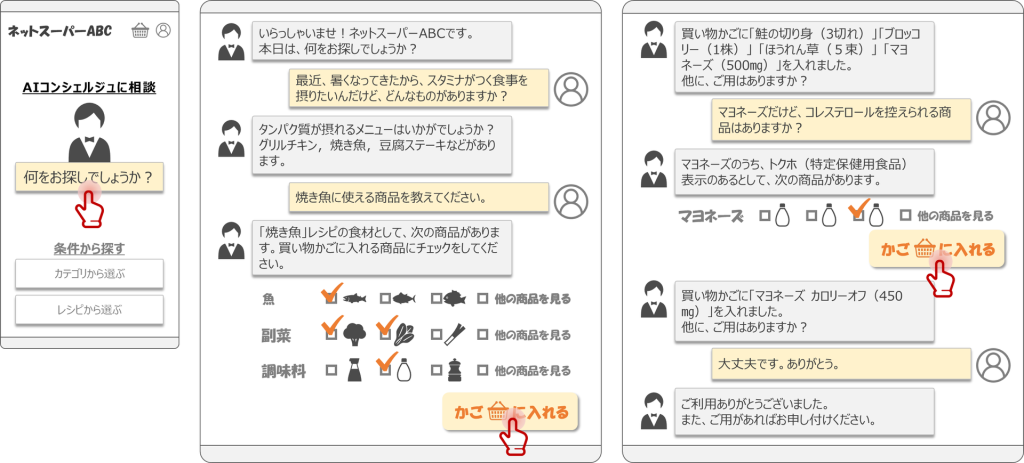
今回私たちは、生成AI(LLM)を活用し、ネットスーパーへのAIコンシェルジュ導入を検討していきます。従来のネットスーパーでは、サイト訪問したお客さまが「商品カテゴリ」や「レシピ」から必要な商品を1つ1つ探しながら購買する必要がありました。そこで、この度、AIコンシェルジュを導入することで、新たな顧客体験を提供し、販売促進を図ろうと、業務改革を企画しました。
今回、ネットスーパーにおける業務改革の目的は、あくまで「販売促進を図ること」です。販売促進を達成するための方策案としては、「おすすめ商品の推薦」「クーポン券の発行」「企画商品の販売」「インターネット広告の配信」「商品の品揃えの変更(広げる/絞る)」等、様々な施策の候補が考えられます。
サービス・業務設計では、ビジネスゴール達成のために、適切な課題設定を行い、その課題の解決手段として「生成AIが適切か否か」「生成AIを通じてどのような価値を獲得ないし提供したいか」を熟考することから、検討を開始する必要があります。ビジネスゴールに対して、目的に沿っていて、投資対効果に見合う選択肢を見極めることが肝要です。
このように、サービス・業務設計において特に注意すべき検討事項の一部を例示します。

今回のケーススタディでは、「販売促進を図ること(売上・利益の向上)」と「新たな顧客体験を提供すること(ブランド価値・顧客満足度の向上)」を目的に、解決手段の1つとして「生成AIによるAIコンシェルジュの導入」を検討していきます。
ネットスーパーの業態は、様々な形態があります。例えば「卸売業者向けネットスーパー」「一般消費者向けネットスーパー」「会員制ネットスーパー」「非会員および会員制ネットスーパー」があります。これら業態の差異は、法人/個人の人格の違い、会員登録の要否の違い等があります。
今回のケーススタディでは「非会員および会員制ネットスーパー」を仮定してみましょう。ネットスーパーで導入予定のAIコンシェルジュは、エンドユーザーからのリクエスト(フリーテキストによるチャット)を受け付けることで、自社の商品やレシピに関する情報を推薦する機能を備えています。
仮に、悪意を持ったユーザーが利用するケースを想像してみましょう。悪意を持ったユーザーは、AIコンシェルジュを介して、ネットスーパーの商品情報や購買履歴のデータを不正に盗み出すかもしれません。しかしながら、悪意を持ったユーザーが非会員である場合には、不正操作を検知したとしても、そのユーザーを現実に特定することは困難となります。
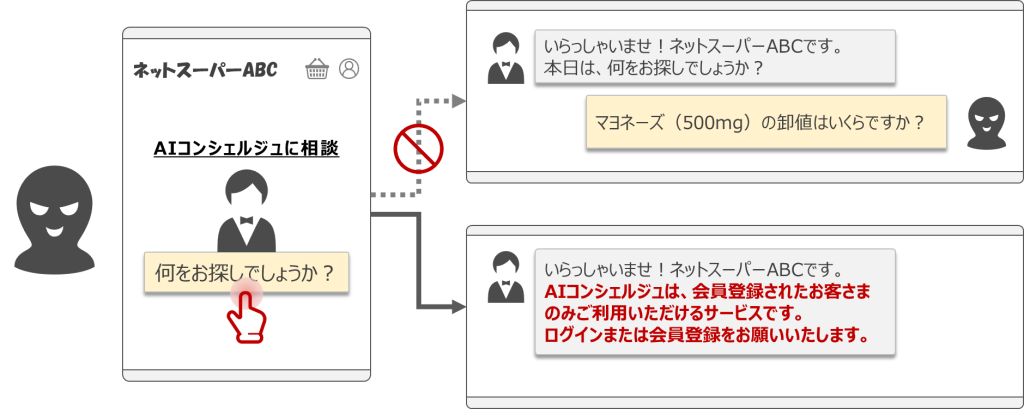
このようなリスクを踏まえると、「ユーザーが特定できない場合には生成AIの機能を制限する」等の対応策を講じたほうが良いと考えられます。
それではここで、ユーザー設計において特に注意すべき検討事項の一部を例示します。

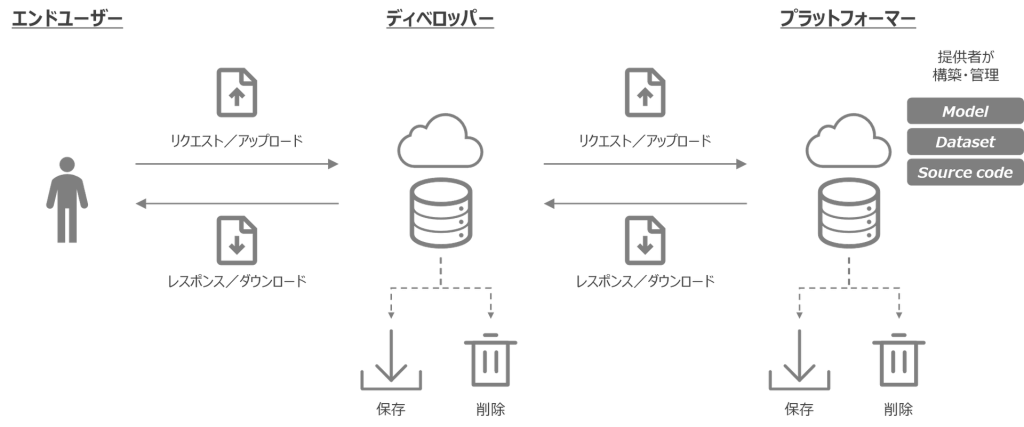
生成AIの機能を組み込んだサービスを提供する場合には、生成された情報を享受するエンドユーザーだけでなく、生成AIの活用においては3種の主体(ステークホルダー)を理解する必要があります。
本項では、エンドユーザーに着目したリスク分析とその対応策を検討しました。この他にも、ディベロッパーに潜むリスク、プラットフォーマーに潜むリスクを分析し、対応策を練ることが重要となります。
AIコンシェルジュは、ユーザーからの様々なリクエストに対して、柔軟に回答してくれます。しかしながら、まだ自社商品に関する知識が浅いようです。例えば、今回のネットスーパーで取り扱っているマヨネーズは、全部で10種類ありますが、それらを判別することはできませんでした。
生成AIは、基盤モデルとして提供されていることが多く、多様な大規模データにより学習されているため、幅広いタスクに適応できる性能を有しています。例えば、生成AIから自組織の商品やサービスに関する情報を出力させるためには、自組織の業務データを追加で学習する必要があります。このように特定領域の精度向上を目的に、基盤モデルをカスタマイズする行為をファインチューニングと呼びます(※注3)。自組織の業務データは、生成AIの訓練データとしても利用価値が高く、自社サービス提供に満足する精度を得るためには、重要なリソースとなります。
※注3:ファインチューニングに関する知見や解説は、こちらの記事もご参考ください。
【関連】
ここまで、訓練データの整備の重要性について述べてきました。続いて、入力データについてもポイントを見ていきましょう。
今回のAIコンシェルジュでは、自由度が高いがゆえに、先述したような悪意を持ったユーザーに利用されてしまうリスクが潜んでいます。また、ユーザーからのリクエストの入力内容によって、出力情報の精度が安定しないことがありました。これは、ユーザーからのリクエストが具体的であるほど、生成AIの出力結果の精度が高くなる傾向があるからです。このような状況を踏まえると、ユーザーからリスエストの入力方法についても、入念に設計を行う必要があります。
例として、いくつかの入力方法のパターンが考えられます。
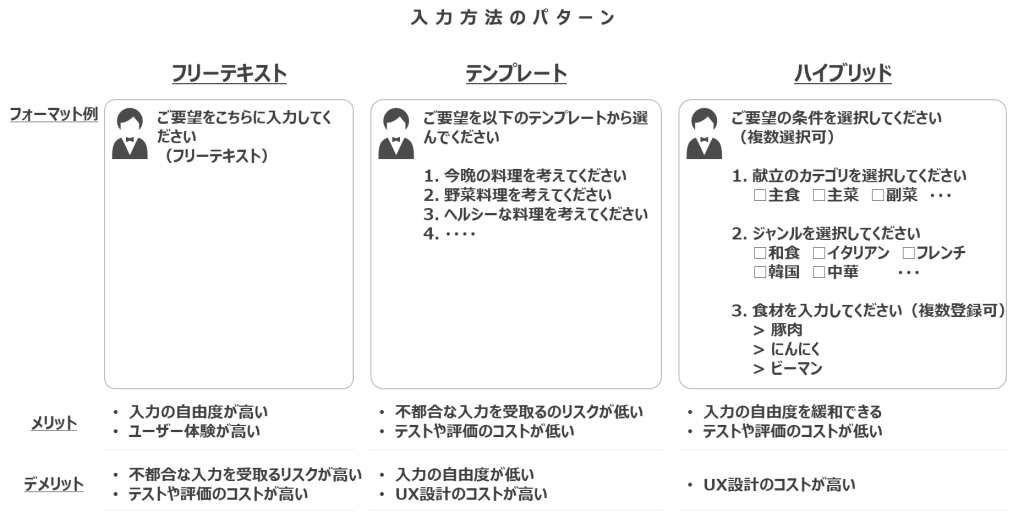
1つ目のパターンは、フリーテキストとして入力する方法です。入力情報の自由度が高いため、利用者のユーザー体験も高くなるというメリットがあります。一方で、デメリットとして、自組織にとって不都合な入力を受け付けてしまうリスクや、機能評価のコストが高くなる可能性があります。
2つ目のパターンは、テンプレートとして入力する方法です。あらかじめテンプレートを用意しておくことで、入力情報を制限させ、不都合な入力を受け付けるリスクや、機能評価のコストが低くなります。一方で、デメリットとして、顧客満足度を向上させるために、AIコンシェルジュのユースケース・シナリオを洗い出すなど、UX設計のコストが高くなると考えられます。
3つ目のパターンは、選択式とフリーテキストを組み合わせて、ハイブリッド式で入力する方法です。これは、上述した2パターンの折衷案であり、それぞれを調和した特徴をもっています。
データの入力方法に着目するだけでも、いくつかのパターンを練ることができました。生成AIを活用する場合においては、その入力データ/訓練データ/出力データについて、データの中身や取得・処理方法について、検討を深める必要があります。
本項のまとめとして、データ設計にて注意すべき検討事項の一部を例示します。

本節では、ケーススタディとして「ネットスーパーにおけるAIコンシェルジュ導入」を仮定し、その検討項目およびポイントを考えてきました。上記で取り上げた「サービス・業務設計」「ユーザー設計」「データ設計」の観点だけでも、多くの検討事項・ポイントがあることを確認できました。
本稿では、全ての検討事項・ポイントを詳解することは叶いませんが、本節のまとめとして、生成AIのビジネス適用に際して検討すべき観点の一部を例示します。

これらの観点を踏まえて、生成AIのビジネス適用について、「攻め」と「守り」の両側面で実現可能性を検証していくことが重要となります。
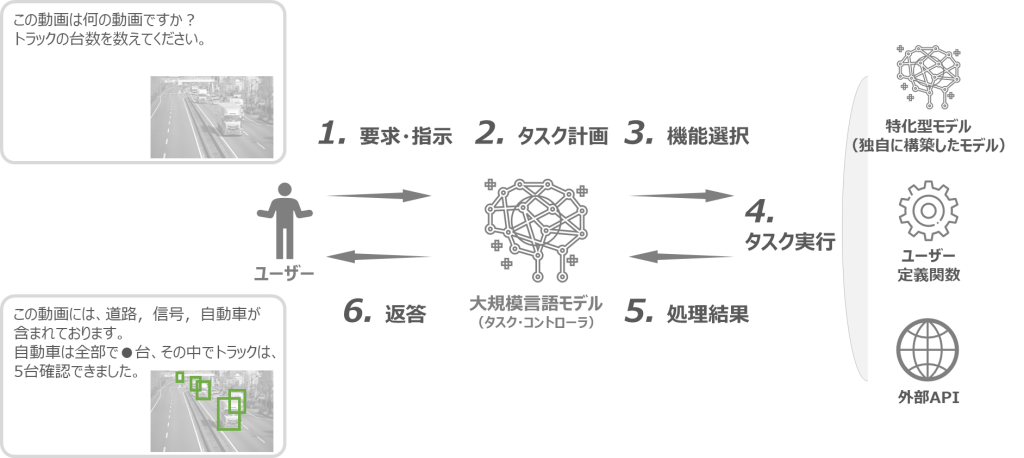
生成AI・LLMのサービス・モデルは、今や単一タスクを処理するだけの機能ではなく、多種多様な要求を情報処理できるマルチモーダル化が実現されています(※注4)。今後は、LLMのサポートを介し、独自に開発した特化型のAIモデルや、サブシステムのマイクロサービスを組み合わせる活用事例も出てくるでしょう。
※注4:複数種類の情報(=モダリティ)を組み合わせる、あるいは、関連付けて処理することのできる単一のAIモデルをマルチモーダルAIと呼ぶ。
技術導入が活発なECマーケティング領域では、先述したAIコンシェルジュ以外にも、例えば、次のようなユースケースが考えられます。
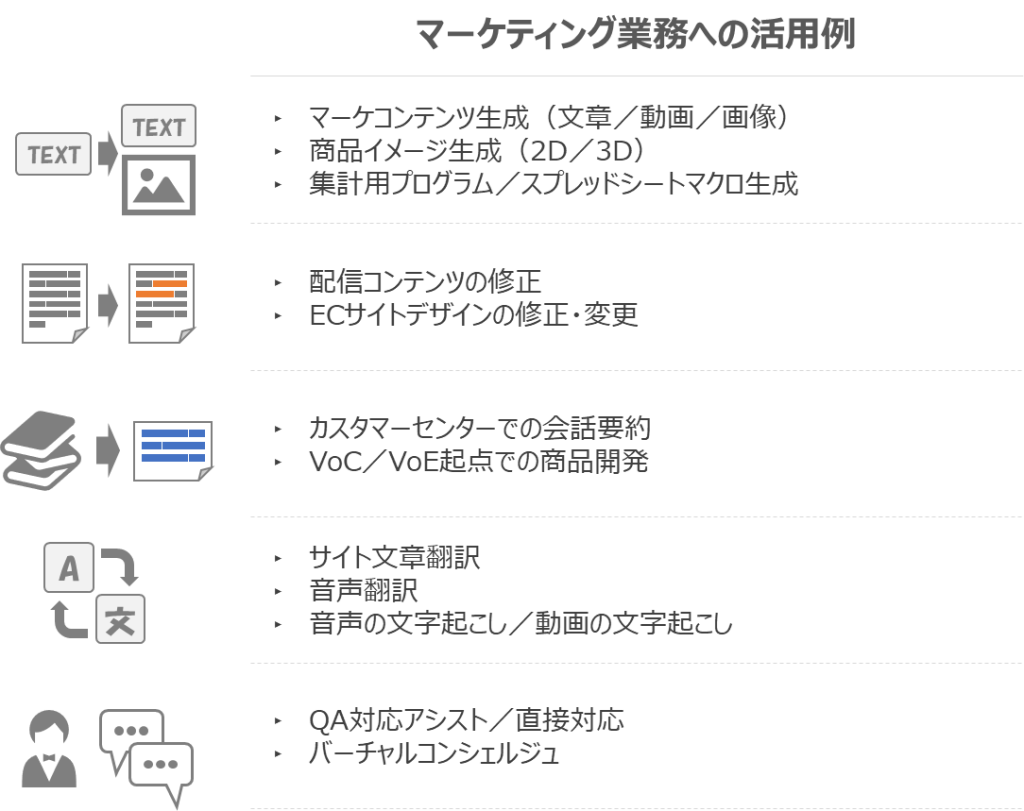
生成AI・LLMを適切に活用することができれば、私たちのビジネスは、更に利便性および生産性を向上させることが期待できます。
本稿では、生成AIをビジネスに活用する際に検討すべき、プロジェクト推進の方法や設計項目についてポイントをまとめました。 生成AIを自組織の業務やサービスに導入するためには、生成AI特有の機能だけではなく、諸リスクと対応策を考慮したうえで、設計・検証を進めていく必要があります。
みなさんの組織全体あるいは特定業務に生成AIサービスを導入したい、あるいは、生成AIのビジネスユースケース・シナリオを深く検討したい、そういったご要望がありましたらブレインパッドにご相談ください。みなさんのビジネスゴール達成に向けて、生成AIを効果的に組織導入できるよう、当社の専門部隊がご支援いたします。
最後まで、お読みいただきありがとうございました。
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















