



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス本部の三浦です。
当社は、昨年夏より人工知能(AI)を用いた画像処理や言語処理などの先進技術のビジネス活用を支援する「機械学習/ディープラーニング活用サービス」の提供を開始し、多くのお客様からのお問い合わせをいただいております。
そこで、今回はこの「機械学習/ディープラーニング活用サービス」の事例として、自律型無人航空機(ドローン)による空撮測量サービスを提供するエアロセンス株式会社(以下エアロセンス)で実施した、ドローンの空撮画像から車両をディープラーニング(深層学習)で検出する取り組みについてご紹介します。
エアロセンスは、ドローンを活用したサービスを提供されており、資材置き場や工事現場などさまざまな場所の空撮画像を有しています。
ブレインパッドは、ディープラーニングを用いた画像処理の支援として、空撮画像から自動車の領域を検出し台数をカウントする技術の実用化を支援しました。エアロセンスは、この領域検出技術をベースとして、資材置き場における資材の自動管理、施設の監視が可能となり、新たなサービスの展開などに積極的に活用していく予定です。
ディープラーニングを用いた領域検出の方法としては、R-CNNをはじめとして、Faster R-CNN、YOLOなど複数の手法がここ数年で考案されています。今回は、それらの手法のベースとなるR-CNNについて紹介します。
分析で用いるのは、オルソ画像というドローンによる上空からの空撮画像です。以下の画像は、オルソ画像の例です。画像の右上の領域に自動車が多数停車していることがわかります。
図. オルソ画像の例

オルソ画像の1枚の解像度は非常に高いため、R-CNNをそのまま適用するのは難しいと考えました。そのためオルソ画像を複数の入力画像に分割し、各画像に対してR-CNNの適用を行いました。
下図に分析の全体概要を示します。
図. 分析の全体概要図
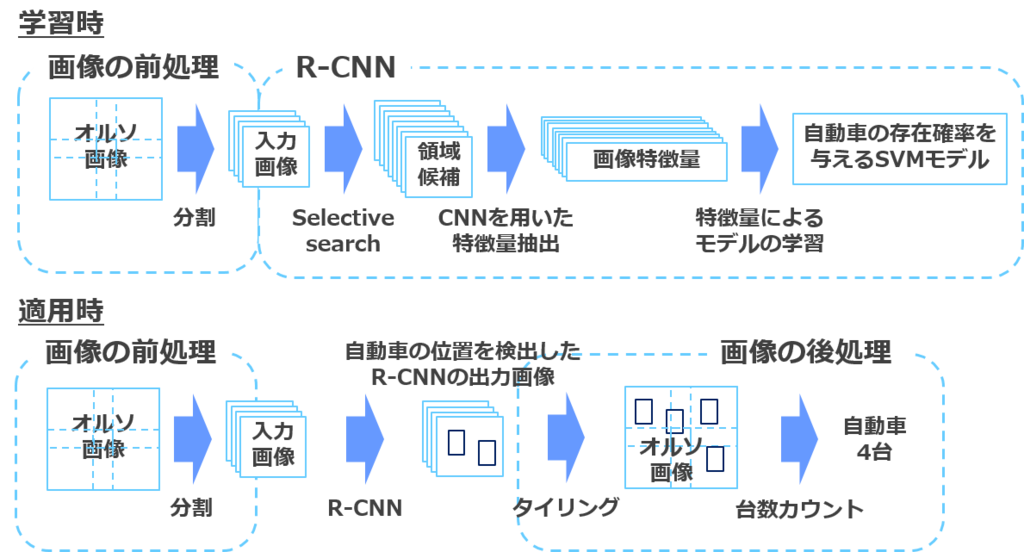
R-CNNのアルゴリズムは大別して、次の3つから構成されています。
1.領域候補の抽出
2.画像特徴量の計算
3.画像分類モデルの構築
上の分析の全体概要図では、selective searchが1に、CNNを用いた特徴量抽出が2に、特徴量によるモデルの学習が3に対応しています。次項以降でそれぞれについて説明したいと思います。
1.Selective searchによる領域候補の抽出
Selective searchとは、入力画像のピクセル同士の類似度を元に計算された、物体の位置候補を生成する手法です。色空間、特徴量、サイズ、含有関係の類似度を元にピクセル同士を結合し、最終的に1枚の画像になるまで、繰り返し領域候補を結合して生成します。
図. アルゴリズムのイメージ

図は論文(*1)より引用
1)ピクセル領域の結合
色空間、特徴量、サイズ、含有関係の類似度を元に、最終的に1枚の画像になるまで、繰り返しピクセル同士を結合していきます。
2)ボックスとして候補を抽出
ピクセルを囲む矩形を位置候補として検出します。
Selective searchを実行することにより、以下のような大量の領域候補が得られます。
図. Selective searchの実行結果

※ 見やすさのため、枠の表示面積を一定サイズ内に限定しています。
Selective searchの領域候補にそもそも車が入っていないと、その車が検出されることはありません。しかし、領域候補数が多すぎると、CNNによる特徴量抽出の回数が増えるため計算時間が増加します。したがって、適切な領域候補数になるようselective searchを実行することが重要と言えます。
2.CNNを用いた画像特徴量の計算
R-CNNではSVMで画像を判別するモデルを構築するため、SVMの入力となる画像の特徴量をCNNで抽出する必要があります。CNNのネットワーク構造は、AlexNet、VGG、 GoogLeNetといろいろと存在しますが、TensorFlowには学習済みのInception-v3が付属しているため、簡単に特徴量を抽出することができます。これにより各画像が、高次元のベクトルとして保存されます。学習済みのモデルを用いることで、教師データとなる車両の台数が、100台程度と少なくて済むというメリットもあります。
3.画像特徴量によるSVMモデルの構築
Selective searchによる領域候補と画像特徴量から、画像を分類するSVMモデルを構築します。車の分類モデルを学習したい場合、車が写っている画像に「正解」、写っていない画像に「不正解」のラベルを付与したデータが必要になります。正解と不正解の画像は、次の基準で作成します。
ここでのオーバーラップ率は、領域同士の(共通集合の面積 / 和集合の面積)で計算される、IoU(Intersection over Union)を用います。フロントガラスのみなどの領域を除去する目的で、正解画像とのオーバーラップが多少生じる領域に対しても、「不正解」のラベルを与えます。
図. 作成された正解/不正解画像の例

正解画像は車両の台数分しか作成されません。不正解画像は全て抽出すると多すぎるので適当にサンプリングを行います。しかし、単純にランダムサンプリングすると、車両と関係ない草むらや道路など地面の不正解画像が多くなります。
識別では、車両と誤検出しやすい物体が不正解画像としてサンプリングされていることが好ましく、正解画像に対する不正解画像の割合が大きい方が良い結果となります。
これらの正解/不正解画像をInception-v3に与えて得られる画像特徴量を、SVMの入力データとします。また正解のラベルを1、不正解のラベルを0として、SVMの学習を行います。
R-CNNの適用時には、selective searchで得られた領域候補に対してCNNで画像特徴量の抽出を行い、SVMによるスコアリングを行います。その際、同一の車両に対して、複数の領域候補に高いスコアが付くことがあります。
似た位置の領域同士に対しては、スコアの低い領域は削除しできるだけ重複を減らす必要がありますが、そのための除去方法がnon-maximum suppression(以下NMS)です。
NMSでは重なる領域同士を比較し、以下の条件に当てはまるスコアが低い方の領域を除去します。NMSを行うことで、結果が図のように変化します。
図. Non-maximum suppressionによる領域の復元例

図では、検出結果のうちスコアが低い領域を青で、スコアが高い領域を赤で示しています。NMSを行うことでスコアの低い領域が除去され、信頼性の高い領域だけが残ることがわかります。
エアロセンスへは、上記の内容や精度評価の方法などを、GCP(Google Cloud Platform、*2)上でJupyter notebookを用いて支援させていただきました。
図. Jupyterノートブックの例
ワークショップでは、実際にエアロセンスに車両を矩形で囲んだ正解画像を作成していただき、これらの画像も学習データに加えることで精度が良くなることや、本記事では紹介しませんが、この他にもモデルのチューニングを各種行うことにより、当初のモデルから精度(PR曲線下の面積, AP)を大幅に上昇できることが確認されました。
テスト画像における、最終的な検出結果は図のようになります。
図. テスト画像における車両の検出結果

※ 左下の部分でオルソ画像は切れています
図ではスコアの低い領域を青、高い領域を赤で示しています。何台か検出できていない車両は存在するものの、概ね正しい検出となっていることがわかります。
検出できない理由としては、
などが挙げられます。
今回、R-CNNという基本的な領域検出のモデルを構築し、またそれをチューニングすることで、空撮画像からの車両検出が良い精度で可能になることを示しました。
一方でR-CNNの課題としては、selective searchの領域候補に対して画像の特徴量抽出を行うため、計算に時間がかかる点が挙げられます。また、駐車場に車両が密集するというタスクの性質上、NMSにより隣接車両の検出結果が除去されてしまうという難しさも存在します。
これらの課題点のいくつかは、Faster R-CNNなど後発のアルゴリズムを採用することで解決できます。今後ともこうした領域検出の案件に取り組み、技術を磨いていきたいと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













