



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス本部の小田です。
寒くなるとクシャミをするたびにギックリ腰の予感がします。
このところ業務でレコメンデーションに触れることが多いので、本ブログではレコメンドについて、実際にRやPythonでコードを書きながら、ゆるゆると考察していきたいと思っています。
今後複数回にわたってレコメンド手法の概念や実装方法を中心に、基礎的な内容から最近流行りの技術まで幅広く触れる予定です。また手法以外にも、評価方法やコールドスタート問題に代表されるレコメンデーションの課題など、様々なトピックに触れたいと思っています。不定期に書いていく予定ですが、その辺はゆるふわということでご了承ください。
さて、今回はレコメンドアルゴリズムの基本とも言える「協調フィルタリング」について、機械学習手法のkNN回帰との比較を通して考察します。
レコメンド手法を簡単に分類すると、以下のような図となります。その中で、協調フィルタリングは、広義にはユーザの利用履歴(トランザクションデータ、ユーザ・アイテム行列)を利用するレコメンド手法全体を指します。そのため、広義の意味での「協調フィルタリング」に含まれるアルゴリズムや手法は非常に多くなります。商品やユーザの属性情報を使ってレコメンドをする「内容ベースフィルタリング」との対比としてこの言葉は使われます。
レコメンド手法の分類
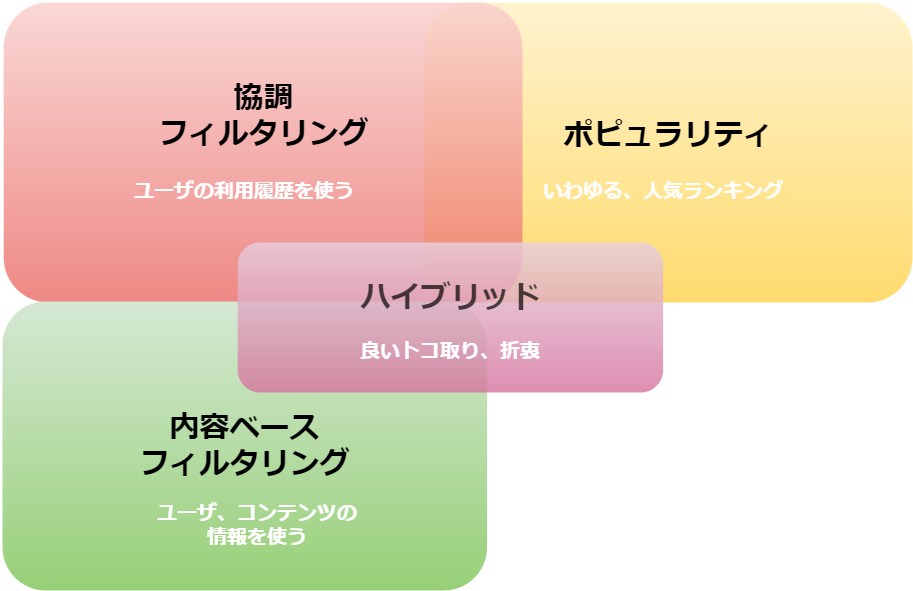
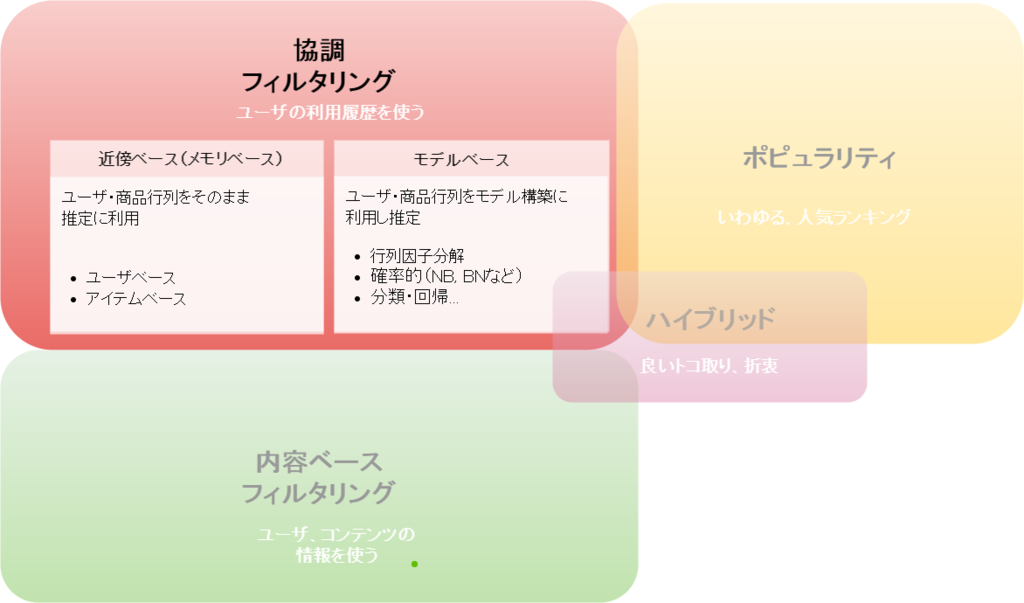
協調フィルタリングは更に、近傍ベース(メモリベース)とモデルベースに分類されます。2つの違いはレコメンド(推定)をする際にトランザクションデータをそのまま利用するのか、事前にモデル構築を行うのかにあります。狭義に協調フィルタリングといった場合、前者の近傍ベースアプローチを指すことが多いと思います。本ブログでフォーカスしているのも、この近傍ベース協調フィルタリングになります。
協調フィルタリングの分類
近傍ベース協調フィルタリングのコンセプトは、「類似度」がキーになっています。過去の利用履歴から似たもの同士を明らかにし、この類似度を使ってオススメ商品を推定していきます。類似度といった場合、ユーザ同士の類似度と商品同士の類似度の2つが考えられますが、前者を使う協調フィルタリングをユーザベース、後者をアイテムベースと言って区別したりします。
例えば、ユーザベースの協調フィルタリングで「類似度」というコンセプトを考えた場合「自分と好みや行動が似ているユーザさんは、私好みの商品を知っているはずだ。その人達にオススメを聞こう」というものです。これは日常我々も考えるような、ごく自然な発想です。
協調フィルタリングのコンセプトイメージ

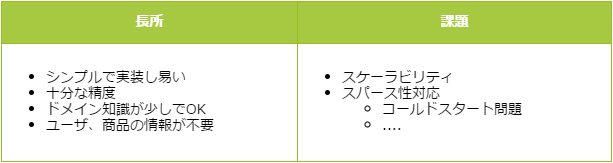
近傍ベース協調フィルタリングは古くからある手法ですが、コンセプトも実装もシンプルでそこそこ良い精度が出るため現在も広く利用され、様々な改良が行われています。また、このような特徴から、各種手法を検討する際のベースラインとしても、よく使われます。そして協調フィルタリングの特筆すべき魅力は、利用履歴さえあれば、「どんなユーザなのか」や「どんな商品なのか」を知らなくてもレコメンドが可能な点です。例えば、あなたが明日突然知識が全くない事業分野でECサイトのマーケ担当者となっても、ユーザIDと商品IDからなる利用履歴のデータさえあれば、それなりのレコメンドシステムを構築することが可能です。極端な例ですが、原理としては商品名すら知る必要はありません。
協調フィルタリングの特徴
協調フィルタリングの課題面については後段で述べるとして、レコメンデーションシステムの体系的な分類や詳しい説明については、他に素晴らしい調査やまとめがありますので、詳細が気になる方は以下のようなサイトを参考にしてみてください。
注:”recommender system”でググると色々出てきて良いかもしません
ここから、ユーザ同士の類似度にもとづいて、オススメを決定するユーザベース協調フィルタリングのロジックを、考察していきます。ユーザベース協調フィルタリングのロジックは、いわゆるkNN回帰という機械学習手法になります。kNN(k-Nearest-Neighbor、k近傍法)を簡単に説明すると、推定する対象に最も特徴が似ているk個の観測値を参考にし、値を推定しようというものです。kNNは一般に分類問題に適用されることが多いですが、オススメ度のような連続値を推定する場合、明示的にkNN回帰と呼んでいます。
具体的な手順を見るため、映画のレビューサイトを題材として考えます。ユーザが自分が見た映画作品を評価付けできるサイトです。ここで、あるユーザ(鈴木さん)がまだ評価していない作品に対して協調フィルタリングを使って評価値を推定し、推定された評価の高い上位10作品(Top-Nレコメンド)をレコメンドするとしましょう。単純化すると、手順は以下のようになります。
1. 鈴木さんと似たような評価をしている(類似度の高い)ユーザを探す
2. 類似度の高い上位k人の評価を参考に、鈴木さんが評価していない映画の評価値を推定する
3. 推定評価値の高い上位10の映画を抽出する
これが典型的なユーザベース協調フィルタリングによるTop-N(ここではN=10)リスト作成手順です。また上記手順の1と2の部分が、kNN回帰による推定に該当します。具体的な評価値を用いて推定してみましょう。
下記のような評価履歴(ユーザ-アイテムの評価値行列)があったとします。鈴木さんのダークナイト(The Dark Knight ;Batman)に対する評価値はいくつと推定できるでしょうか。
映画レビューサイトでの評価値行列
| ユーザ | 作品1 | 作品2 | 作品3 | 作品4 | ダークナイト |
| 鈴木さん | 5 | 3 | 4 | 2 | ? |
| ユーザ1 | 3 | 1 | 2 | 3 | 3 |
| ユーザ2 | 4 | 3 | 4 | 2 | 5 |
| ユーザ3 | 3 | 3 | 1 | 5 | 4 |
| ユーザ4 | 1 | 5 | 5 | 2 | 1 |
とりあえずRでデータを入力し、評価値のヒートマップをプロットします。
library(ggplot2)
library(tidyverse)
# 評価値行列の作成
rating.mtx <-
matrix(
c(5, 3, 4, 2, NA,
3, 1, 2, 3, 3,
4, 3, 4, 2, 5,
3, 3, 1, 5, 4,
1, 5, 5, 2, 1
)
,nrow=5
,byrow=TRUE
)
# 行・列ラベル付与
row.lbl <- c("鈴木さん", "ユーザ1", "ユーザ2", "ユーザ3", "ユーザ4")
col.lbl <- c("作品1", "作品2", "作品3", "作品4", "ダークナイト")
dimnames(rating.mtx) <- list(row.lbl, col.lbl)
# プロットのための整形(wide -> long)
rating.mtx.p <-
rating.mtx %>%
as.data.frame() %>%
tibble::rownames_to_column("userId") %>%
tidyr::gather(key="movieId", value="rating", -userId) %>%
dplyr::mutate(userId=factor(userId, levels=row.lbl[5:1]), movieId=factor(movieId, levels=col.lbl))
# プロット(ヒートマップ)
(g <- ggplot(rating.mtx.p,
aes(movieId, userId)) +
geom_tile(aes(fill=rating)) +
geom_text(aes(label = rating), color="gray30") +
scale_fill_gradient(low="white",high="orange", na.value = "gray90"))評価値行列のヒートマッププロット
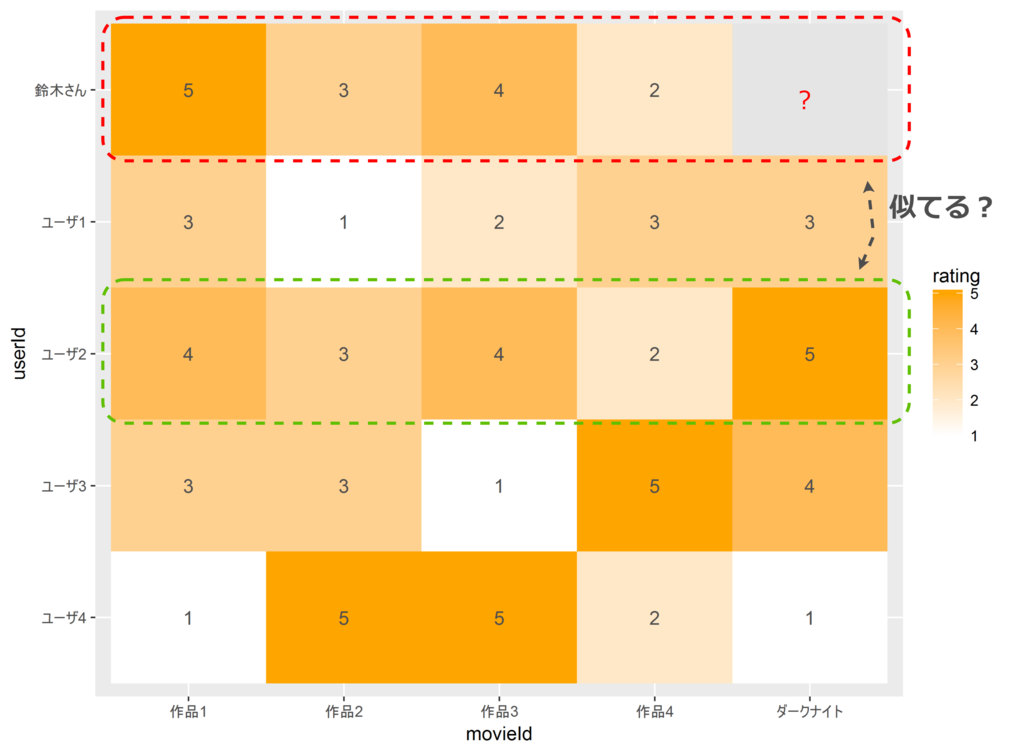
注:評価は1-5の5段階とします(大きいほど高評価)
ぱっと見た感じ、鈴木さんの評価はユーザ2と似ている感じがしますが、どうでしょう。類似性を定量化するために、なんらかの類似度を算出する必要があります。ここではユークリッド類似度(距離)を用いて類似度を計算してみます。(一旦、ここでは類似度を単純に距離の逆数として、以下のように書きました。普通は分母に1を足すと思います。)
# 類似度行列の計算
sim.mtx <- as(1/(dist(x=rating.mtx[,1:4], method = "euclidean", upper=TRUE, diag=TRUE)), 'matrix')
# 鈴木さんと他のユーザの類似度のみ表示
print(sim.mtx[,"鈴木さん",drop=FALSE])鈴木さんと他のユーザの類似度
| – | 鈴木さん |
| 鈴木さん | 0.0000000 |
| ユーザ1 | 0.2773501 |
| ユーザ2 | 1.0000000 |
| ユーザ3 | 0.2132007 |
| ユーザ4 | 0.2182179 |
確かにユーザ2が近いですね。鈴木さん自身との類似度はなぜか0です。Infじゃないのね…
目安までにユークリッド距離に基づいた、鈴木さんと他のユーザ間の距離関係を図示しておきましょう。
※各ユーザの円周上の位置(角度)はランダムなので意味はありません。
鈴木さんと他のユーザ間の距離
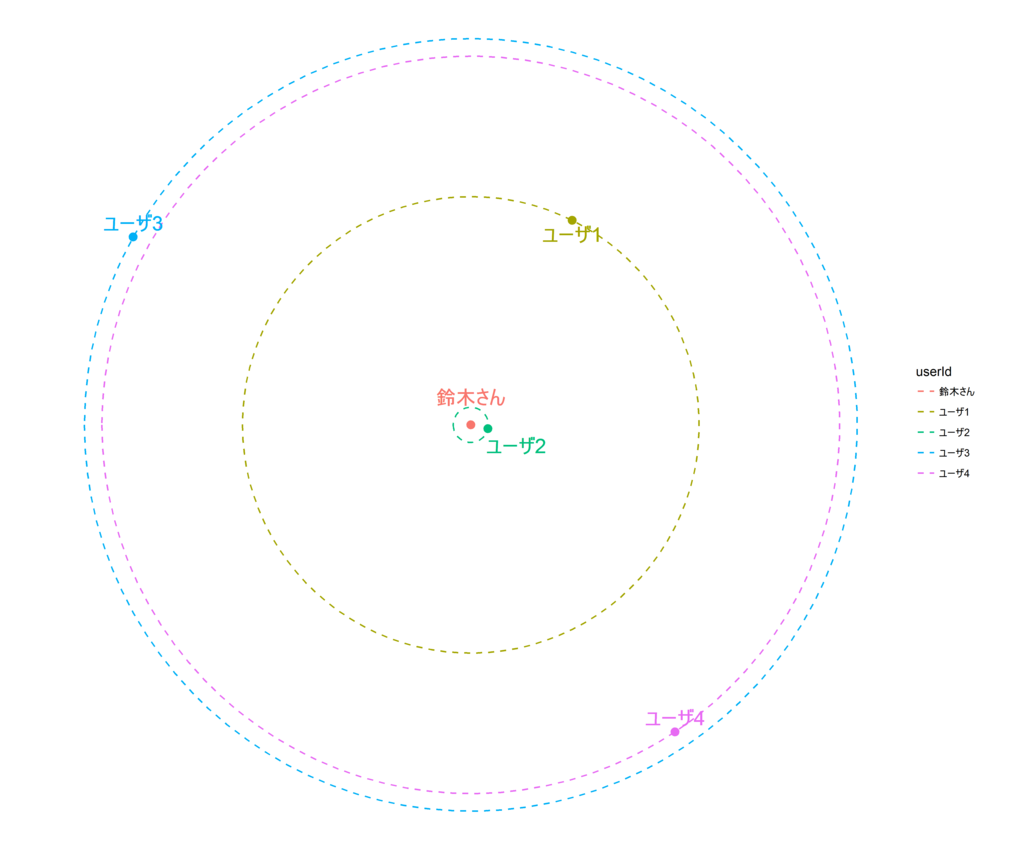
類似度が出ましたので、この中から鈴木さんと類似度の高いユーザを3人(k=3)選んで、ダークナイトに対する評価を推定します。類似度の高い人の評価をより重視するために、類似度を重みとして3人の平均評価値(加重平均)をとります。
# 鈴木さんに対する類似度を抽出(鈴木さん自身との類似度は除外)
sim.suzuki <- sim.mtx[rownames(sim.mtx) != "鈴木さん","鈴木さん"]
# 類似度の最も高い3人を選出(k=3)
NN.row.num <- head(order(sim.suzuki, decreasing=TRUE), n=3)
(NN <- names(sim.suzuki)[NN.row.num])
# >[1] "ユーザ2" "ユーザ1" "ユーザ4"
# ダークナイトの評価値を推定(加重平均)
(sum(rating.mtx[NN,"ダークナイト"] * sim.suzuki[NN]) / sum(sim.suzuki[NN]))
# >[1] 4.045465めでたく評価値が推定できました。推定されたダークナイトの評価値は4.0と高めなので、結構オススメのようです。
一応、今後の比較のため、類似度と推定方法を数式で書いておきます。とてもシンプルなものです。
ユークリッド類似度(kNNと比較のため距離の逆数で定義)
$$
\displaystyle
sim_{euclid}(a, b) = \frac{1}{\sqrt{\sum_{y\in items}(r_{ay} – r_{by} )^2}}
$$
類似度を用いた加重平均による評価値の推定
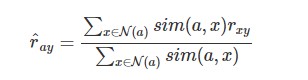
※\( r_{xy}\)をユーザ\( x\)のアイテム\( y\)への評価値とし、\( \mathcal{N(a)}\)はユーザ\( a\)の最近傍ユーザ(k-nearest neighbor)の集合とします。
念のため、既存のkNN回帰のライブラリを使って、推定値が同じになるのか確かめてみます。RにkNN回帰を手軽にできそうなパッケージが見当たらなかったので、Pythonのscikit-learnを利用します。統一感がないですが、、、まあ、ゆるふわなのでご了承ください。
import numpy as np
from sklearn import neighbors
# 評価値行列
rating_mtx = np.array([[5, 3, 4, 2, np.NaN],
[3, 1, 2, 3, 3],
[4, 3, 4, 2, 5],
[3, 3, 1, 5, 4],
[1, 5, 5, 2, 1]])
# 学習用データ(鈴木さん以外)
X = rating_mtx[1:5, 0:4] # 説明変数
y = rating_mtx[1:5, 4] # 目的変数
# 検証データ(鈴木さん)
x_suzuki = rating_mtx[0, 0:4]
# モデル構築
knn = neighbors.KNeighborsRegressor(3, weights='distance', metric='euclidean')
model = knn.fit(X, y)
# 評価値の推定
model.predict([x_suzuki])
# > array([ 4.04546516])同じになりました。めでたし、めでたし。
このように、協調フィルタリングとkNN回帰の基本的な考え方自体は同じです。それ故に、協調フィルタリングとkNNの特徴(長所、課題)も似通ったものとなります 。
繰り返しになりますが、協調フィルタリングおよびkNNの特徴をまとめると
1. シンプルで実装が簡単
2. 精度がそこそこ良い
3. 計算コスト、スケーラビリティが課題
ということになります。ここまで見たように、ロジックがシンプルで実装が比較的容易ですが、その割に精度もそこそこ良いです。一方で事前にモデルを構築せず(lazy learning、instanced-based model)、推定の都度、全データに対して計算を行うアプローチをとるため、データが大きくなった場合に計算コストが高くなります。もちろん計算量を効率よく減らすためのアルゴリズムの工夫などにより、この課題は改善されているようですが、他の手法に比べると依然課題として挙げられます。
また各種手法と精度比較する際のベースラインのような立ち位置にあることも、機械学習におけるkNNの立ち位置同様です。
さて協調フィルタリングとkNNのロジックの類似性を見てきましたが、一般的なkNNのライブラリを使って協調フィルタリングによるレコメンドシステムを実装できるかというと、これは多分結構面倒だと思います。レコメンデーションと一般的な教師あり機械学習モデルでは、想定されている問題設定が異なるため、色々とカスタマイズが必要になります。協調フィルタリングとkNN回帰の具体的な差異として、主に「類似度」「目的変数」の2点を挙げてみます。
協調フィルタリングとkNNの主な差異

kNNでの距離・類似度はユークリッド距離、マハラノビス距離を利用する事が多いと思いますが、協調フィルタリングではコサイン類似度、ピアソン相関、Jaccard係数が多いです。またレコメンデーションの問題設定はもともと「大量の欠損値を含む」事を前提としてるので一般的な機械学習の前提と趣が異なっていて、この辺がスパース性やコールドスタート問題といったレコメンドシステムで特徴的な課題に直結しています。
※kNNによる欠損値対処というアプローチもあるので、興味のある方はトライしてみるのも良いかもしれません。(”kNN impute”とかでググると情報が多いです。)
基礎原理は以上ですが、実際のレコメンドでは、さらに以下のようなポイントを工夫していくことになるでしょう。
次回以降のブログでは、今回紹介したユーザベース協調フィルタリングについて、実際に欠損の多い評価値行列に使って実装したり、協調フィルタリングを利用できるライブラリの使い方や、評価方法のまとめなどを確認できたらと思います。
長くなってきましたのでこの辺で。ごきげんよう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













