メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。アナリティクスサービス本部の仲田です。
本日は、「強化学習」について、その基礎的なアルゴリズムと、簡単なデモをご紹介します。
「強化学習(Reinforcement Learning)」と呼ばれる学問分野をご存知でしょうか。
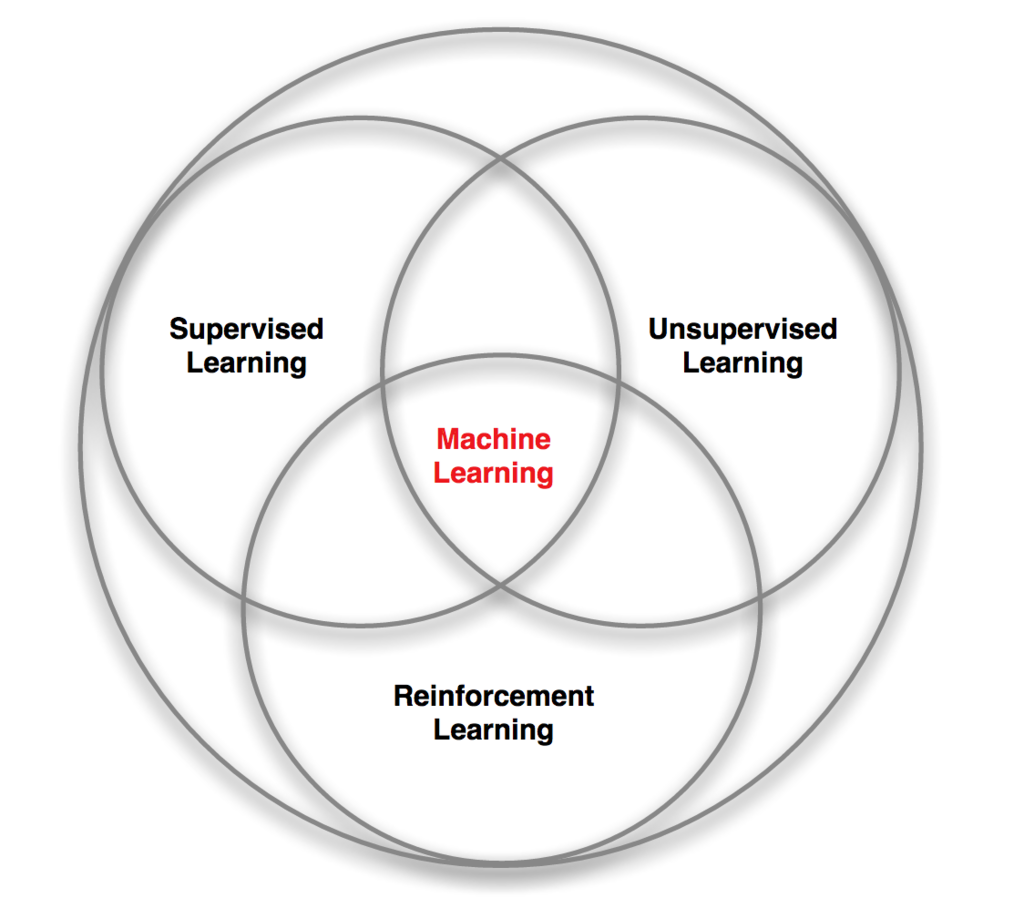
機械学習にはさまざまな分類方法がありますが、「教師付き学習(Supervised Learning)」「教師なし学習(Unsupervised Learning)」「強化学習」という3種類に分ける考え方があります。
この考え方では、強化学習は機械学習のひとつの大きな分野をなすということになります。
教師付き学習とは、「入力と出力の関係」を学習するものです。
「分類」や「予測」と呼ばれるような問題は、教師付き学習のクラスとなります。
例えば、今日の天気から明日の天気を予測するような問題が、教師付き学習にあたります。
この場合、入力が今日の天気、出力が明日の天気となります。
教師なし学習とは、「データの構造」を学習するものです。「教師なし」という名の通り、正解となる出力が学習の際に与えられないことが特徴的です。
「クラスタリング」や「次元削減」と呼ばれるような問題は教師なし学習のクラスとなります。
例えば、購買情報を元にユーザを数種類のグループに分けるような問題が教師なし学習にあたります。
この場合、入力は購買情報、出力はグループですが、その出力されたグループには正解がもともとあるわけではなく、単に「似ているユーザ」をグループ分けした結果です。
最後に、
強化学習とは、試行錯誤を通じて「価値を最大化するような行動」を学習するものです。
教師付き学習とよく似た問題設定ですが、与えられた正解の出力をそのまま学習すれば良いわけではなく、もっと広い意味での「価値」を最大化する行動を学習しなければなりません。
例えば、株の売買により利益を得る問題が強化学習にあたります。
この場合、持っている株をすべて売り出せば確かにその時点では最もキャッシュを得ることができますが、より長期的な意味での価値を最大化するには、株をもう少し手元に置いておいたほうが良いかもしれません。
他にも、テトリスでできるだけ高スコアを得るような問題も強化学習の枠組みで考えることができます。
その時点で一番スコアが高くなるのは、一列でもすぐに消すようなプレイ方法ですが、より長期的には、できるだけ溜めてから一度にたくさんの列を消したほうがスコアが高くなります。
冒頭に載せたAlphaGoも、その一部に強化学習が組み込まれています。
囲碁や将棋といったゲームは、本質的に将来の価値(つまり今その手を打つことにより、最終的に勝つのか負けるのか)を最大化することが目的なので、強化学習とは相性が良い問題です。
さて、強化学習についてもう少し詳しく説明します。
強化学習では、与えられた「環境」における価値(あるいは「利益」と呼びます)を最大化するように「エージェント」を学習させます。
例えば、「テトリス」が環境で、そのプレイヤーがエージェントです。
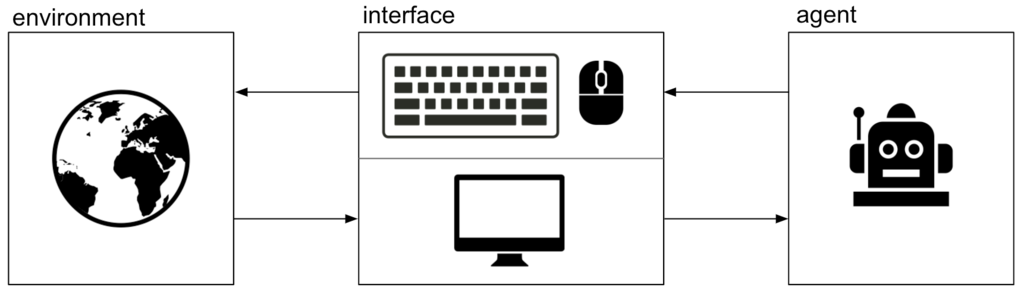
今回は、アルゴリズムのために必要な強化学習の用語について、状態 \( s\)・行動 \( a\)・報酬 \( r\) の3要素をご紹介します。
ここで、報酬に関しては一点注意が必要です。
先ほど言った通り、強化学習ではその時点で貰える報酬(即時報酬などと呼びます)ではなく、(将来に渡る)価値を最大化します。
よって、単に即時報酬が多くもらえる近視眼的な行動ではなく、より未来を考えた価値を最大化する行動を取らなければなりません。
では、どうやって価値を最大化させるようにエージェントを学習させるのでしょうか?
典型的には、「ある状態 \( s\) においてある行動 \( a\) を取った時の価値」がわかれば、その価値の一番高い行動を選択すればよいはずです。
この価値のことを Q値 あるいは状態行動価値と呼び、 \( Q(s, a)\) と書きます *1。
Q値は「報酬」ではなく「価値」であることに注意してください。つまり、Q値とは短期的な報酬ではなく、長期的な意味での価値を値として持っている関数です。
さて、「その行動によって、価値の高い状態に遷移できるような行動」は、遷移先と同じくらいの価値を持っているとみなすのが自然です。
「価値の低い状態に遷移するような行動の価値は低い」ことも言えそうです。
つまり、現時点 \( t\) におけるQ値は一つ先の時点 \( t+1\) のQ値によって書くことができます *2:
$$
Q(s_t, a_t) = E_{s_{t+1}}(r_{t+1} + \gamma E_{a_{t+1}}(Q(s_{t+1}, a_{t+1}))) \tag{1}
$$
下付きの \( t\) は時点 \( t\) における状態や行動であることを表しています。
\( r_{t+1}\) は得られた即時報酬で、外側の期待値が \( s_{t+1}\) に関するもの、内側の期待値が \( a_{t+1}\) に関するものです。
\( \gamma\) は割引率と呼ばれ、将来の価値をどれだけ割り引いて考えるかのパラメータです。
ここまで準備ができれば、あとはどうやってこの Q値を学習するかを考えることができます。
強化学習のアルゴリズムのうち、シンプルな「Q学習」「Sarsa」「モンテカルロ法」について紹介します *3。
価値を最大化する行動を学習するためにはQ値がわかればよいこと、そしてQ値は (1) 式で計算できることがわかりました。しかし、(1)に含まれる期待値を計算するためには、次の時点の状態を正確に計算できる必要があります。
期待値とは、株の売買の例では「明日の株がどうなっているか」を、テトリスの例では「次にどのテトリミノ *4 が供給されるか」を計算しなければなりませんが、これは一般的に非常に難しいか、もしくは原理的に不可能です *5。
そこで、期待値をとるのではなく、実際に行動を実施して次の時点の状態を確認しながら、少しずつQ値を更新していきます。実際に行動した結果のサンプルで期待値の代用としよう、というわけです。
本記事で紹介する Q学習、Sarsa、モンテカルロ法のいずれも、この考え方に従ったアルゴリズムです。
名前が紛らわしいですが、「Q値を学習するためのアルゴリズムのひとつがQ学習」です。
Q 学習では、(1) 式の期待値の中身 \( r_{t+1} + \gamma E_{a_{t+1}}(Q(s_{t+1}, a_{t+1}))\) を \( r_{t+1} + \gamma \max_{a_{t+1}}Q(s_{t+1}, a_{t+1})\) と置き換えることで、次のように Q値を更新していきます。
$$
Q(s_t, a_t) \leftarrow (1-\alpha)Q(s_t, a_t) + \alpha(r_{t+1} + \gamma \max_{a_{t+1}}Q(s_{t+1}, a_{t+1})) \tag{2}
$$
\( \alpha\) は学習率と呼ばれるパラメータ(0以上1以下)で、Q値の更新をどれだけ急激におこなうかを制御します。
第一項が現在のQ値、第二項が新しいQ値にあたり、その二項が \( 1-\alpha\) と \( \alpha\) で足し合わされていますから、現在のQ値を第二項にむかって \( \alpha\) ぶんだけ近づける更新をしています。
(1)式の内側の期待値は、(2)式では max により置き換えられています。
(1)式の内側の期待値は、次の状態がどれくらいの価値を持つかを見積もっているわけですが、その価値の見積もりを(現在推定されている値の)最大値にしてしまおう、というわけです。
エージェントは自由に行動を選ぶことができるので、現在推定されている価値の最大値をもって価値の見積もりとすることはそんなに悪い方法ではないように思われます。実際、Q学習はうまくいくことが多いことが昔から知られています。
なお、(2)式は実装や見た目の都合上、少し展開して次の形式でよく登場します:
$$
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha(r_{t+1} + \gamma \max_{a_{t+1}}Q(s_{t+1}, a_{t+1}) – Q(s_t, a_t)) \tag{3}
$$
Sarsa もQ学習のように、(1) 式の期待値の中身 \( r_{t+1} + \gamma E_{a_{t+1}}(Q(s_{t+1}, a_{t+1}))\) を \( r_{t+1} + \gamma Q(s_{t+1}, a_{t+1})\) で置き換えます。
Q学習では、期待値の見積もりを現在推定されている値の最大値で置き換えましたが、Sarsa の場合、実際に行動してみたらどうなったかを使って期待値の見積もりを置き換えます。
Q学習では、期待値の見積もりを現在推定されている値の最大値で置き換えましたが、Sarsa の場合、実際に行動してみたらどうなったかを使って期待値の見積もりを置き換えます。
ですので、Sarsa では現在の価値を更新するためには、エージェントが実際にもう一度行動をおこなう必要があります。
式で書くと次のとおりです:
$$
Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha(r_{t+1} + \gamma Q(s_{t+1}, a_{t+1}) – Q(s_t, a_t)) \tag{4}
$$
モンテカルロ法 *6 はQ学習やSarsaとは違い、Q値の更新のときに「次の時点のQ値」を用いません。
代わりに、とにかく何らかの報酬が得られるまで行動をしてみて、その報酬値を知ってから、辿ってきた状態と行動に対してその報酬を分配していきます。
得られた報酬を \( r\) と書くことにすれば、モンテカルロ法でのQ値の更新式は次のとおりです:
$$
Returns(s, a) \leftarrow append(Returns(s, a), r) \tag{5}
$$
$$
Q(s, a) \leftarrow average(Returns(s, a)) \tag{6}
$$
ただし、\( Returns(s, a)\) は状態 \( s\), 行動 \( a\) を経ることでこれまでに得られた報酬を格納している配列、\( append\) は配列に要素を付け足す操作、\(average\) は配列の平均をとる操作とします。辿ってきた行動と状態のペアに対してこの更新式に従いQ値を更新していきます。
モンテカルロ法では報酬が得られて初めてQ値を更新することができます。
逆に言えば、報酬が得られるまでQ値を更新することができません。
このことは、Q値が「ある時点でとった行動による即時報酬だけでなく、未来に渡る価値も含む」ことを考えれば当然です。
一方Q学習やSarsaは、「現在推定中のQ値でも、未来に渡る価値を含むはずだ」という前提で、次の時点でのQ値を使って常に更新をおこなっています。Q学習やSarsaでは、 (1)式の特性をうまく活かしているという見方もできますが、その方法だと、遠い未来で得られる報酬の学習は遅くなります。
モンテカルロ法は一度未来を見てから一気にQ値の更新をかけるため、遠い未来の報酬も比較的早く学習できるという特徴があります。
では、これらのアルゴリズムを使って、実際に仮想的な環境を学習するエージェントを作ってみます。

CartPole問題とは、強化学習で古くから研究されている単純な環境です。
左右に動くカートの上にポールを立て、倒れないように制御する問題です。
状態 \( s\) はカートの位置と速度およびポールの角度と角速度、行動aはカートを左右どちらに動かすか、報酬rはどれだけ長い間ポールを立てることができたか、となります。
なお、実験にあたっては、Python のライブラリ https://gym.openai.com/ を用いています。
Q学習によって CartPole 問題をエージェントに学習させてみます。
以下の gif アニメーションは、上から順に初期状態・200回の学習後・400回・600回・800回・1000回、となっています。
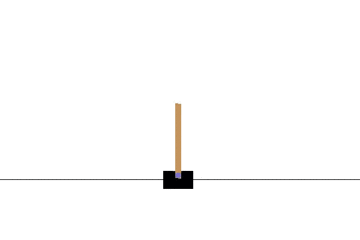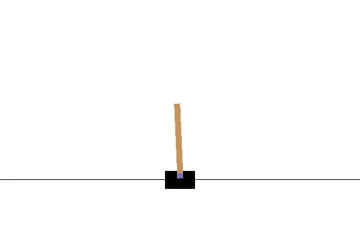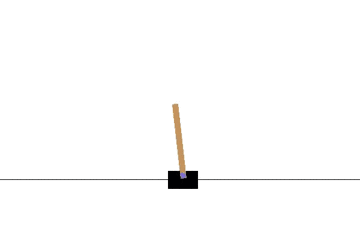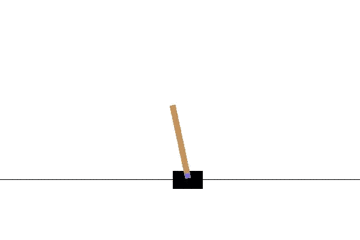

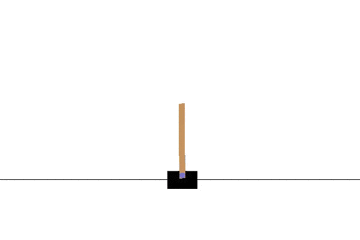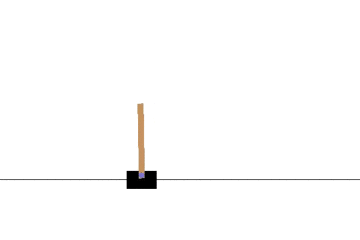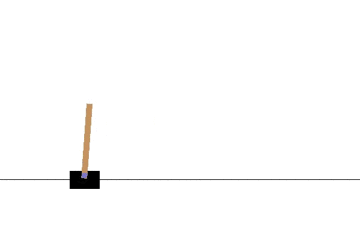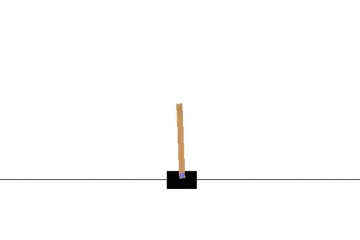


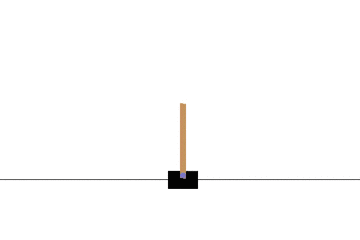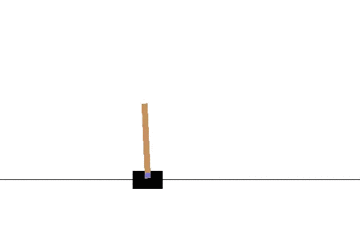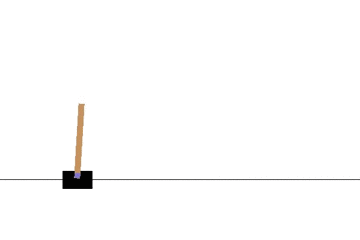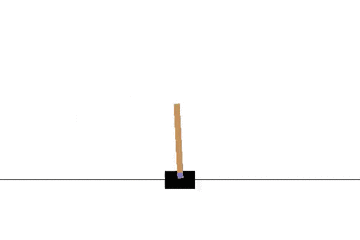
少しずつ学習が進み、最終的にはポールをうまく立て続けることができるようになっています。
以下は縦軸に得られた価値 (つまりどれだけ長くポールを立てることができたか)、横軸に学習回数をとったときの学習曲線です:

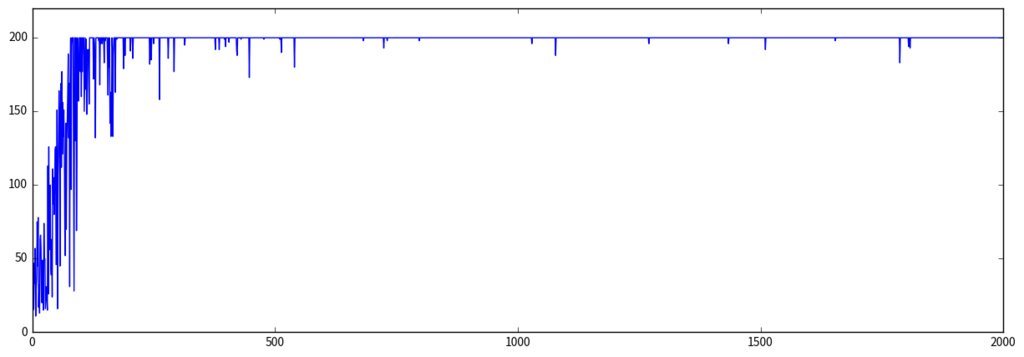
段々と学習が進んでいる様子が見られます。
Sarsa でも同様に CartPole 問題を学習させてみます。
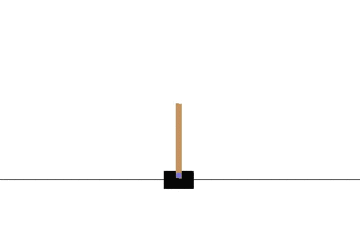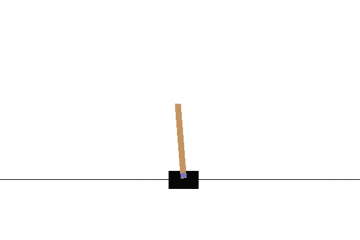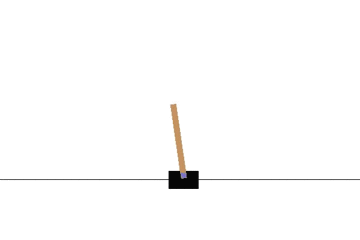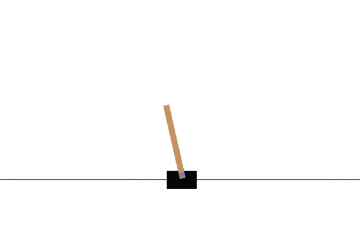
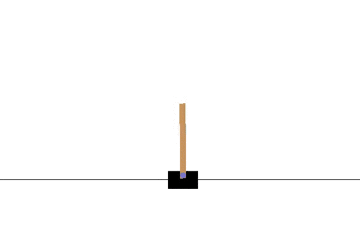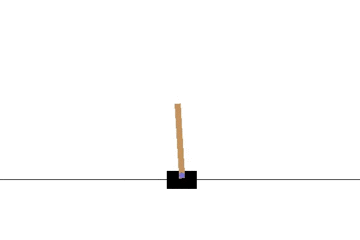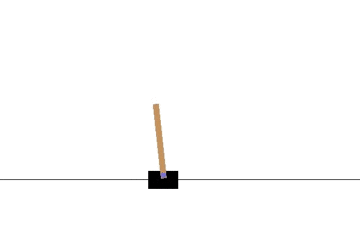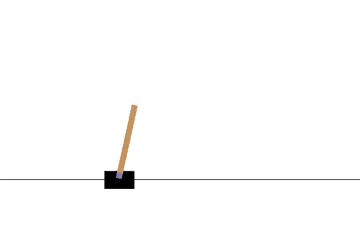


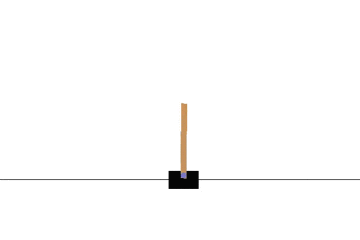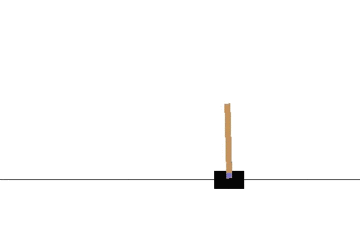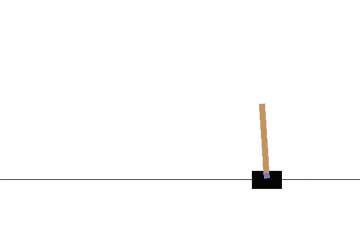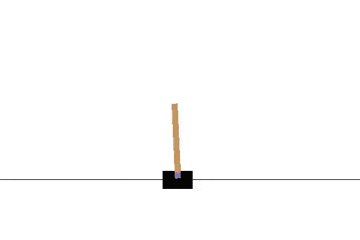

学習曲線は次のとおりです:

モンテカルロ法でも同様に CartPole 問題を学習させてみます。


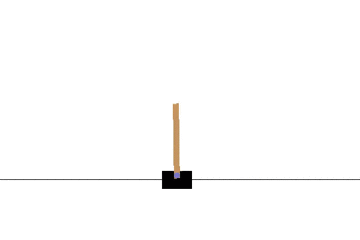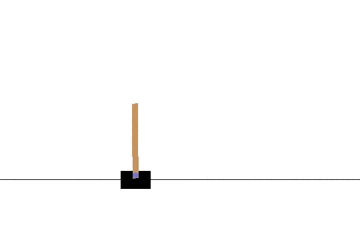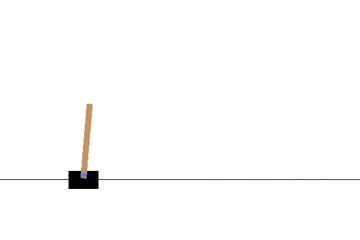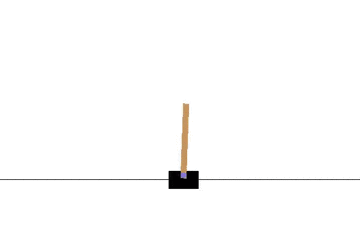



学習曲線は次のとおりです:
ここまで、強化学習の基礎的なアルゴリズムと簡単なデモを紹介しました。
しかし、今回紹介したQ値に基づくアルゴリズムには大きな課題が存在します。状態行動空間の爆発、と呼ばれるものです。
規模の小さな環境では問題になりませんが、状態や行動が連続値で定義され、その次元も非常に大きいような環境だと、状態と行動の組に対して定義されるQ値を保存するための領域が無限に必要となってしまい、なんらかの工夫をしなければなりません。
AlphaGoで使われているDeep Q-Network(DQN)では、この状態行動空間の爆発に対して、「Q値を直接表現するのではなく、ニューラルネットワークにより近似」することで対処しています *7。
Q値をニューラルネットワークで近似する、というアイデア自体はかなり前からあるものなのですが、これまで実問題ではあまりうまくいっていませんでした。AlphaGoは、囲碁という巨大な環境であっても深層学習技術を応用して学習に成功させたことで、深層学習と強化学習の融合の可能性を大きく世に示しました。
強化学習は、教師付き学習や教師なし学習と比べるとビジネス応用例がまだまだ少ないですが、今まさに大きく発展を遂げている分野です。
少しずつ試行錯誤することで価値を最大化する行動を学習する強化学習は、いわゆる「AI」と呼ばれるモノに最も近いイメージかと思います。
おそらく、今後もっと様々なビジネスへの応用が生まれてくると思います。
*1:状態と行動のペアではなく、状態だけの価値を考える場合、\( V(s)\) と書きます
*2:Bellman 方程式と呼ばれるものです
*3:歴史的には状態価値 \( V(s)\) を用いたTD学習と呼ばれるアルゴリズムが先に提案されましたが、本記事では割愛します
*4:上から降ってくるテトリスの駒のことです
*5:もちろん計算可能な問題もあります
*6:機械学習で「モンテカルロ法」というと広すぎる概念な気がしますが、強化学習ではこの名前が使われています
*7:DQNの構成要素はこれだけではなく、他にもさまざまな工夫を取り入れています
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説