



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、AI開発部の伊藤です。
今回のブログは、「深層学習はいったい画像のどこを見て判断しているのか」という素朴な疑問に答えてくれる技術として、昨年提唱された「Grad-CAM」という技術を紹介します。
近年、画像分類技術の精度向上には目覚ましいものがあります。深層学習と呼ばれるニューラルネットワークを進化させた技術を画像分類に適用することにより、人間と同程度かそれ以上の高精度を実現できるようになりました。
そのような深層学習モデルの中でも、「畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)」は、視覚野の特徴抽出の仕組みをモデル化したもので、画像解析において高い性能を発揮してきました。CNNは、畳み込み演算(Convolution)による画像特徴量の抽出とプーリング(Pooling)と呼ばれるノイズ処理を行い、何層にもわたって積み上げられたネットワークから構成されます。人間の手を介さずネットワークの学習を通して画像特徴量を自動抽出できるようになったことで、既存手法を著しく上回る精度を実現できるようになりました。その一方で、そもそも機械学習、特に深層学習は判断結果の解釈が難しいという問題点も指摘されてきました。
では、深層学習、とりわけCNNは、画像から対象物を判別するとき、画像のどこに着目しているのでしょうか?
私たち人間は画像を見て対象物が何かを判別するとき、判別の手掛かりとして対象物の特徴的な部分に着目します。例えば、画像に何やら小動物らしきもの(猫)が写っている場合、その顔の部分を特定して目や耳の特徴を探したり(猫目で耳が立っている)、体の模様や毛並み、足の本数、尻尾の長さ(縞模様、4本足、長い尻尾)など体の特徴にも着目します。では、CNNはどこで判別しているのでしょう。
この疑問に答えてくれる技術はいくつかありますが、今回はそのような手法の一つとして最近注目を集めているGrad-CAMという技術を紹介します。さらに、Grad-CAMの実施例として、実際に「お好み焼き」と「ピザ」の画像分類に適用してみたので、その結果についても紹介します。
ここでは、Grad-CAMの仕組みについて説明しますが、詳細については、参考文献にあるGrad-CAMの提唱者による論文*1と実装例*2を参照してください。以下、論文中の図や画像を引用しつつ説明します。
まずは、Grad-CAMで何ができるかを紹介します。以下に犬と猫が一緒に写っている写真があります。その右横にGrad-CAMとその拡張であるGuided Grad-CAMによる出力が貼ってあります。Grad-CAMを実施する前提として、CNNによる画像分類器が必要です。写真のように”犬”と”猫”を判別する分類器にGrad-CAMを適用した場合、”犬”、”猫”のそれぞれについて特徴部位がヒートマップで強調されます。”犬”の特徴部位を可視化した場合には、犬の顔がヒートマップで強調され、”猫”の特徴部位を可視化した場合には、猫の胴体の部分がヒートマップで強調されています。
Grad-CAMでは、CNNが着目している特徴箇所を特定することはできますが、見ている内容の詳細まではわかりません。そこで拡張手法であるGuided Grad-CAMを適用して高解像度の画像を出力した結果が、ヒートマップ図の右隣の画像です。犬の画像では犬の顔の特徴として垂れた耳、目、頬などが可視化されているのが見て取れます。同様に猫の特徴部位として胴体の縞模様に着目していることがわかります。


(※以下の説明はやや複雑なため、Grad-CAMの仕組みに興味のない方は読み飛ばしてください。)
次にGrad-CAMの仕組みについて説明します。まずは、論文にある概念図(下図)を見てください。

畳み込みニューラルネットワークは、大きく2つの部分に分かれます。畳み込み層とプーリング層を何層にもわたって積み重ねた特徴抽出部分と、その特徴量出力を受け取ってクラスラベルと照合して教師あり学習を行う識別部分です。識別部分は通常、全結合の多層ニューラルネットワークで構成され、その最終層は特徴量を各クラスの確率スコアに変換するソフトマックス層になっています。
ここでいう確率スコアとは、入力画像に各クラスのタグが付与される確率のことです。例えば、犬と猫の2値分類の場合、入力画像に対して”犬”が付与される確率が70%、”猫”が付与される確率は30%と計算されます。判定結果は、確率スコアが最大となるクラスとなるので、上述の場合、入力画像には”犬”がタグ付けされます。
Grad-CAMの基本的なアイディアは、クラスごとの確率スコアへの影響が大きい画像箇所を微分係数の平均化によって特定するという考えです。ここでいう微分係数とは、特徴量マップ*3において、ある画像箇所に微小変化を加えたときに確率スコアに生じる変化の大きさを表す係数のことです。クラス判定に与える影響が大きい画像箇所は、確率スコアの微分係数も大きいという訳です。ちなみに、微分係数は変化率を表すという意味で勾配(gradient)とも呼ばれます。この手法がGrad-CAMと呼ばれる所以です。
概念図でいうと、Grad-CAMは出力部分から入力画像に向かう下側の矢印で表されるルートに対応しています。数式も示しておきます。
$${ \displaystyle
\quad\quad \alpha_k^c = \overset{\text{global average pooling}}{\overbrace{\frac{1}{Z} \sum_i \sum_j}} \frac{\partial y^c}{\partial A_{ij}^k} \quad\quad (1)
}$$
$${ \displaystyle
\quad\quad L^c_{\rm Grad-CAM} = ReLU \underset{\text{linear conbination}}
{\underbrace{\left(\sum_k \alpha_k^c A^k \right)}} \quad\quad (2)
}$$
[tex:(1)] 式では、クラス \({c}\) の確率スコア \(y^c\) を \(k\) 番目の特徴マップの \((i,j)\) ピクセルにおける強度 \(A_{ij}^k\)について微分して勾配 \(\partial y^c/\partial A_{ij}^k\)を計算し、それらを全ピクセルについて平均することにより (global average pooling)、クラス \(c\)の\(k\)番目のフィルタに関する重み係数 \(\alpha_k^c\)を計算しています。この重み係数 \(\alpha_k^c\)が大きいほど、その特徴マップ \(A_k\)がそのクラス\(c\)にとって重要であるということです。
\((2)\)式では、\((1)\)式で計算された重み係数 \(\alpha_k^c\)により\(k\) 個のフィルタの加重平均を計算し、その活性化関数\(ReLU(x)\equiv \max\{x,0\}\)による出力をヒートマップ出力として定義しています。
Grad-CAMにおいて重要なのは、\((1)\)式において勾配の平均を取ることによってクラスによる違いを明瞭にするという点です。実際、勾配の平均を取らずに正値に限ってCNNを逆伝搬させて可視化することもできます。この手法は、Guided Backpropagation と呼ばれる手法で、概念図でいうと出力部分から入力画像に向かう上側の矢印で表されるルートです。
Guided Backpropagationは、Grad-CAMに先立って提唱された手法ですが、CNNを逆伝搬して得られる画像は、解像度は入力画像と同様の水準にある反面、クラスによる違いが明瞭ではありません。そこで、Guided Backpropagationの結果にGrad-CAMの出力を重ねることで、クラスごとの特徴箇所を明瞭に区別すると同時に、高い解像度で特徴箇所を可視化できるようになりました。これが、論文の提唱するもう一つの手法である Guided Grad-CAMです。
ここでは、Grad-CAMおよびGuided Grad-CAMの提案論文中での適用例について説明します。Grad-CAMは、そのシンプルな仕組みのおかげで、画像分類以外の学習モデルにも適用可能です。代表的なタスク・話題として以下の3つのテーマについて説明します。
※本章で紹介するGrad-CAMによる実施例は、全て提案論文の内容を掲載しています。
画像キャプション生成とは、入力画像に対して自動で説明文(キャプション)を生成するタスクのことです。CNNによる画像分類モデルとLSTMによる言語モデル(文章を生成するモデル)を組み合わせて学習することで実現されます。以下の画像は、Nueraltalk2 というモデルによるキャプション生成例です*4。
ホットドッグを食べている男性の画像に対して、”A man is holding a hot dog in his hand” というキャプションが生成されています。このモデルにGrad-CAMを適用した場合、キャプション生成の根拠となった特徴箇所としてホットドッグを持つ親指の部分がヒートマップで強調されます。さらに、Guided Grad-CAMでは、ホットドックと親指の輪郭線がくっきりと表示されているのが分かります。Guided Backpropagationによる可視化では、人物の顔も含めて強調されているのと対照的です。

VQAとは、入力画像とそれに対する質問文を与えられたときに、質問文の答えに該当する画像部分を特定するというタスクです*5。CNNによる画像分類モデルとRNNによる言語解析モデル(文章を理解するモデル)を組み合わせて学習することで実現されます。VQAでは、質問文と回答のペアに対応する画像の領域を抽出し、またその抽出した領域の信頼度をスコアとして計算します。このスコアに対してGrad-CAMを適用することができます。
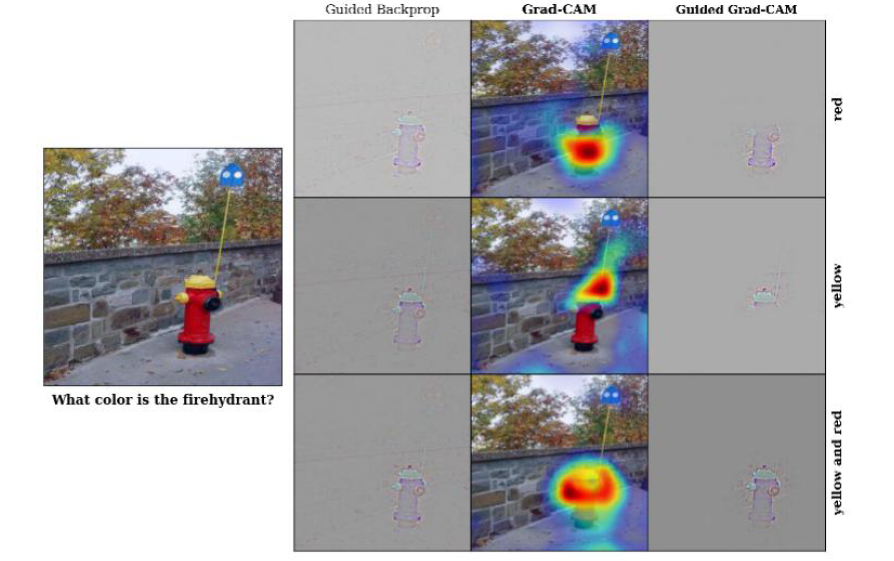
以下の画像は、VQAの実施例*6にGrad-CAMを適用した例です。質問文では、消火栓の色を質問しています。それに対して、赤色、黄色、赤色と黄色、の3通りの回答が与えられたとき、Grad−CAMが回答に対応する領域の部分をヒートマップで強調しているのが分かります。
学習用データのバイアスとは、あるカテゴリの画像がカテゴリとは無関係な特徴を持った画像を多く含んでいる状況を意味します。CNNがそのような画像データを学習すると、間違った特徴を学習したモデルができてしまうので問題です。Grad-CAMを適用すれば、CNNが画像のどの特徴箇所を見て判断しているかが分かるので、学習済みモデルが学習用データのバイアスの影響を受けているかどうかを判定できます。
以下の画像は、医者と看護師を画像から判別する事例です。この画像自体ちょっと判断が難しいのですが、正しいカテゴリは”医者”です。真ん中の画像は、バイアスのある画像データ(”医者”の画像の8割が男性、”看護師”の画像の9割が女性)の学習結果をGrad-CAMで可視化したものです。この場合、CNNは画像の人物の顔や髪形に着目して人物が女性であるから看護師でもあると判断してしまいました。一方、右端の画像は「看護師を判定するために「女性である」というバイアスがかかっている」という結果を受けて、学習データからそのようなバイアスを除いた画像データで学習した結果によるものです。CNNは人物の持っている聴診器や着ている白衣に着目して、人物が医者であると判断しています。

説明が長くなりました。ここから実施例の紹介に入ります。今回、画像分類の対象として身近な食べ物を取り上げることにしました。”お好み焼き”と”ピザ”の分類です。
お好み焼きとピザの画像は、flickr*7から集めてきました。日本語の検索クエリも受け付けてくれます。学習用データ、検証用データ、評価用データの画像枚数と内訳は以下の表のとおりです。
| 用途 | お好み焼き | ピザ |
|---|---|---|
| 学習用 | 250 | 250 |
| 検証用 | 100 | 100 |
| 評価用 | 100 | 100 |
画像分類モデルは、CNNで構築しました。TensorFlowとKerasを使って実装しています。CNNのネットワーク構造は、サイズ 3×3 のフィルタによる畳み込み層を4層積んでいます。活性化関数にはReLUを用いました。最初の2層はプーリングを介さずに積んでいます。3層目と4層目については、それぞれのReLU出力の直後にサイズ 2×2 のプーリング層を積んでいます。Keras記法では以下のように記述されます。
model = Sequential()
model.add(Conv2D(64, (3, 3), input_shape=(160, 160, 3)))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(n_class, kernel_initializer='uniform'))
model.add(Activation('softmax'))バッチサイズ15、エポック数300で学習を行った結果、評価用データで正解率88%の分類モデルが得られました。分類結果を混同行列で表すと下表のようになります。
| 正解\推定 | お好み焼き | ピザ |
|---|---|---|
| お好み焼き | 90 | 10 |
| ピザ | 14 | 86 |
クラスごとに横に足した数字が正解画像の枚数です。”お好み焼き”なのに”ピザ”と判定された画像が10枚、”ピザ”なのに”お好み焼き”と判定された画像が14枚ありました。
今回は、提唱者による実装を参考にして、TensorFlowとKerasを使って実装しました。ちなみに、提唱者の実装はTorchとLua言語によるものです。
以下に、CNNの判定が当たっているケースと外れているケースについて、元画像とGrad-CAMの結果を比較しながら紹介していきます。ケースごとの図は、左から元画像、確率スコアの棒グラフ、Grad-CAMの出力、Guided Grad-CAMの出力、の順に並んでいます。
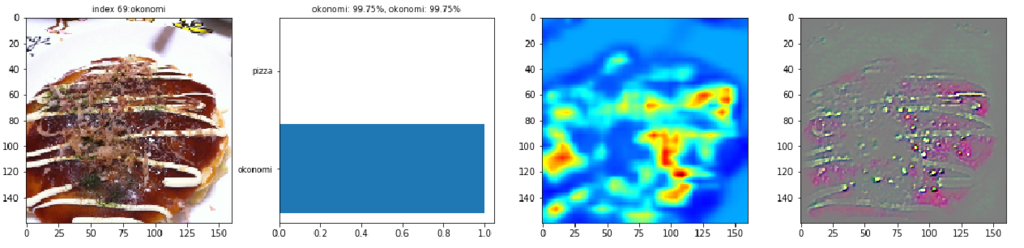
最初の画像には、鉄板の上のお好み焼きが写っています。棒グラフからCNNがほとんど100%の確信をもってお好み焼きと判定しています。Grad-CAMの出力を見るとお好み焼き部分の青色に対して、お好み焼きの周囲の鉄板が緑色なのが分かります。CNNはお好み焼き部分よりも周りの鉄板や鉄板との境目に着目しているようです。お好み焼きの表面を見るとマヨネーズの線が黄色でハイライトされています。Guided Grad-CAMで見ると確かにマヨネーズの線が浮かび上がっています。この画像の場合、鉄板の上にあってマヨネーズが掛かっているのでお好み焼きと判断したようです。
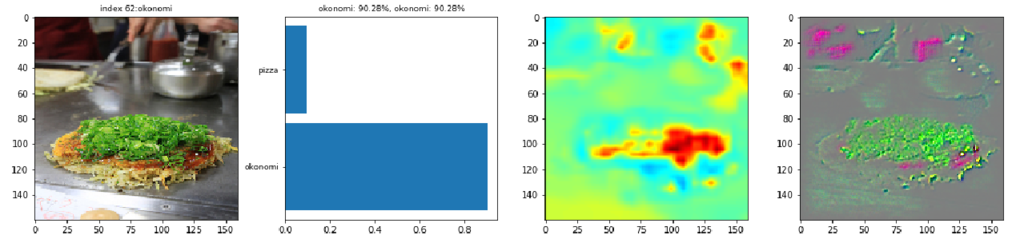
2番目の画像は、お好み焼きが白いお皿に乗っています。Grad-CAMで見ると、CNNが周辺よりもお好み焼き表面に着目しているのが分かります。お好み焼き表面の特徴として、マヨネーズや茶色のソースに反応しているのも分かります。
3番目の画像は、お好み焼きの表面にネギが山盛りになっています。これにはGrad-CAMも反応しているようでネギの箇所が赤くハイライトされています。Guided Grad-CAMで見てもネギの詳細が確認できます(緑色の部分)。ソースの茶色(ピンク色の部分)にも反応しているようです。

CC by whitefield_d
CC by kosabe
CC by Norio.NAKAYAMA
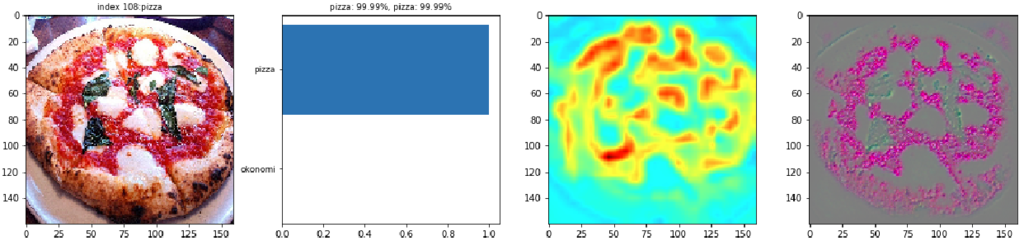
ピザ画像に関しては、CNNの判定が当たっている画像の全般的な特徴として、トマトソースや生地の質感、ピザの丸い形に反応しているように見受けられます。最初の画像の場合、Grad-CAMではトマトソースが赤くハイライトされています。Guided Grad-CAMでみてもトマトソースとバジルの詳細が強調されています。チーズは色合いが生地と区別がつかないので、チーズよりはトマトソースに着目しているようです。
2番目の画像は、ピザ以外に人物も写っていますが、Grad-CAMの画像では、ピザのトマトソースの円形パターンが赤く強調されており、CNNがピザの箇所を特定できていることが分かります。
3番目の画像は、変わった形のピザが写っています。バケットパンをスライスしてトマトソースとチーズでトッピングしただけのシンプルなピザです。Grad-CAM画像から、表面のトマトソースとバケットパン側面のパン生地の質感に着目しているのが分かります。棒グラフから判定が多少難しかったことが分かります。
CC by *tomoth
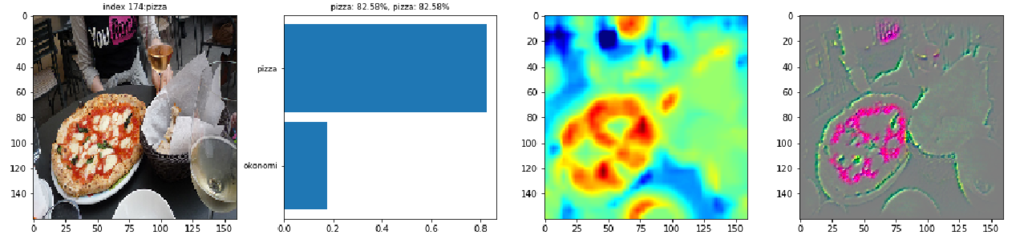
CC by yto

CC by Spiegel
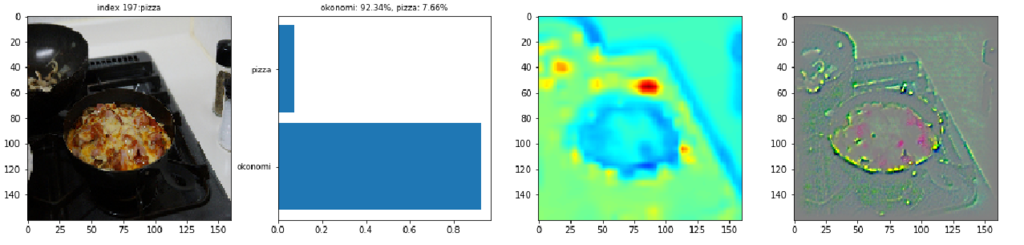
次にCNNが判定を誤ったケースを見ていきます。最初の画像は、丸いお好み焼きの写真です。鉄板の色が黒くないのと生地が薄くて丸いためかピザと誤認しているようです。表面の焦げた質感もピザと判断されているようです。確率スコアを見ると自信をもってピザと間違えています。
2番目の画像は、そもそもお好み焼きとして失敗しているようにも見えます。お皿の丸い形と表面のお好みソースやトッピングをピザと勘違いしているようです。
3番目の画像は、お好み焼きの接写画像です。Grad-CAMでは、背景画像がないので表面の様子から判断しようとしています。紅ショウガの部分がヒートマップで赤くなっていますが、トマトソースと誤認している可能性があります、Guided Grad-CAMで見ると、紅ショウガ部分に加えて青のりの部分も強調されています。青のりをバジルソースと勘違いしているようです。
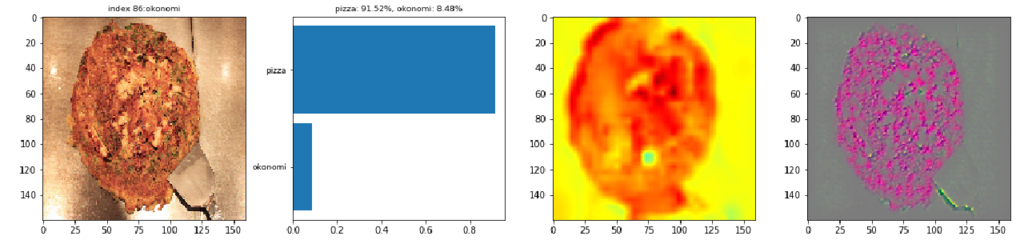
CC by 柏翰 / ポーハン / POHAN
CC by yukop
CC by naotakem
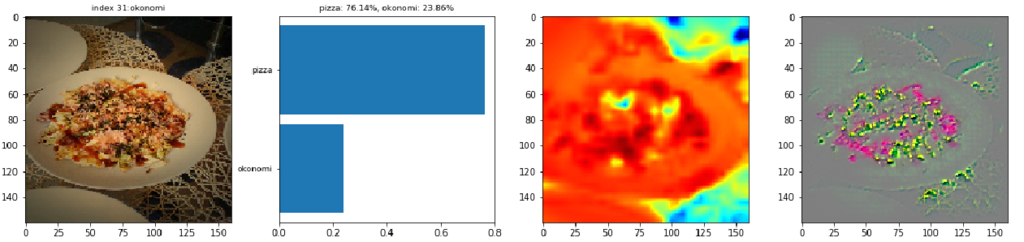
最後にピザをお好み焼きと間違えている例を見てみましょう。最初の画像では、表面に乗っているバジルに着目しています。Guided Grad-CAMの画像ではバジルの部分がネギや青のりのようにも見えます。
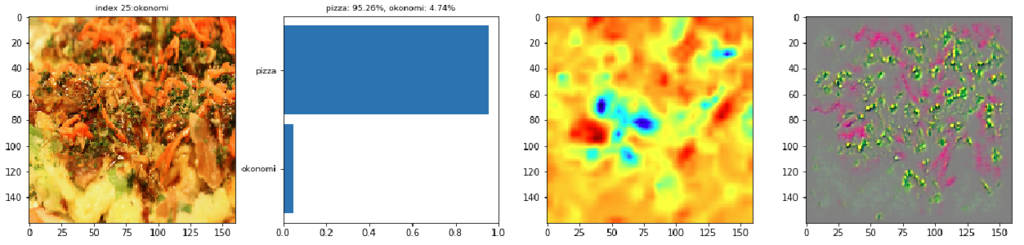
2番目の画像は、丸い典型的なピザの画像ですが、トマトソースが主張していないピザですね。そのためか、Grad-CAMで見る限りCNNもどこを見るか迷っているようです。結局、左側の表面の質感を見てお好み焼きと誤認してしまったようです。
3番目の画像は、黒いレンジの上に同じく黒いフライパン状の容器に入ったピザの写真です。Grad-CAMの画像から、CNNがピザの周辺に着目しているのが分かります。背景が黒いのを鉄板だと勘違いしてお好み焼きであると誤解しているようです。
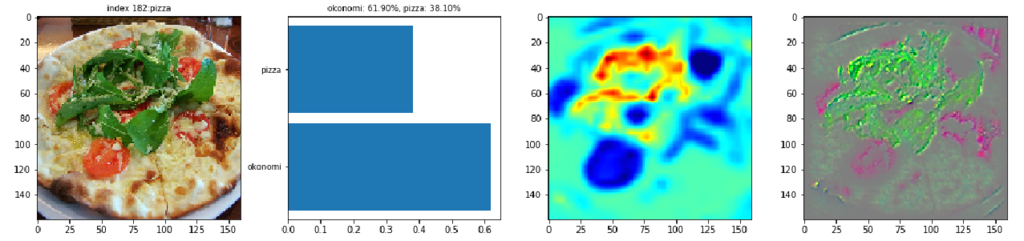
CC by Haseo
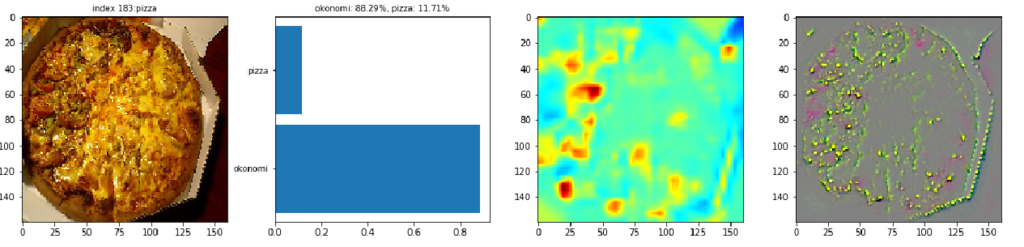
CC by matsudon,giraffe
CC by ume-y
今回のブログは、CNN可視化手法の一つとしてGrad-CAMを紹介しました。実際に、お好み焼きとピザの画像分類を実施してみて、CNNが画像のどこに着目して両者を区別しているかも検証してみました。お好み焼きの判断材料として背景の鉄板に着目していたり、トマトソースがかかっていればとりあえず「ピザ」と判定する、といった判断は私たち人間の判断と似ている所もあるようです。トッピングの食材の違いや、生地の質感の違いまで見て判断するためには、学習用データの多様性を増す工夫が必要そうです。また、背景が鉄板であることを見てお好み焼きと判断するのはバイアスには違いないので、背景処理した画像での学習も必要そうです。
今回は、お好み焼きとピザという身近な例で試してみましたが、画像解析に関わるさまざまな分野での応用が期待できる技術だと思います。特に画像判別が難しい事例において、学習したモデルの問題点を明らかにするのに有用かと思います。今回の検証結果を、案件でも積極的に活用していきたいと考えています。
当社は、深層学習などの技術をビジネスに活用するべく、最先端の取り組みを積極的に実施しています。実際のビジネスで、最先端の技術を活用してみたいという方は、ぜひエントリーください!
https://www.brainpad.co.jp/recruit/
※(2017年10月4日)「1.はじめに」の章、2段落目の「視細胞」を「視覚野」に修正いたしました。
*1:[1610.02391] Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
*2:GitHub – ramprs/grad-cam: [ICCV 2017] Torch code for Grad-CAM
*3:入力画像をCNNの特徴抽出器に通して得られる特徴量を画像として出力した2次元マップのこと
*4:https://cs.stanford.edu/people/karpathy/cvpr2015.pdf
*5:[1505.00468] VQA: Visual Question Answering
*6:https://github.com/VT-vision-lab/VQA_LSTM_CNN
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













