



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社が開発・提供する運用型広告最適化ツール「L2Mixer(エルツーミキサー)」の開発者が、 Google App Engine ( GAE )や Google BigQuery といった Google Cloud Platform のマネージド・サービスを活用したWebサービス開発について紹介します。
こんにちは。マーケティングプラットフォーム本部 開発部の井上です。
ブレインパッドは、デジタルマーケティングの分野に力を入れて取り組んでおり、私が所属する開発部では、Webマーケティングの施策やインターネット広告の運用を支援するWebサービスを開発しています。
当社は、Webサービスのシステム基盤を構築するためにクラウドサービスを積極的に活用しており、Amazon Web Services(AWS)をはじめとして、最近では Google Cloud Platform ( GCP )も利用しています。
そこで、今回は Google App Engine ( GAE )や Google BigQuery といった GCP のマネージド・サービスを活用し、Webサービスの開発について、紹介したいと思います。
私は、当社が提供・開発する運用型広告最適化ツール「L2Mixer」のシステム基盤をオンプレミス環境から GCP へ移行したことがきっかけで、 GCP を利用するようになりました。
L2Mixerの GCP への移行にあたっては、システム構成を極力変えない方針で移行したため、 GCP のIaaSである Google Compute Engine ( GCE )の利用が中心となっています。
GCE はライブマイグレーションにより、ホストメンテナンス時にはVMインスタンスを実行したまま別の物理ホストへの移動が行われるため、メンテナンスによるVMインスタンスの停止が発生しないことや仮想CPUやメモリをカスタマイズできるなど、非常に柔軟で高性能な仮想マシンです。一方、ミドルウェアのインストールやセキュリティアップデートなどは自分たちで行う必要があります。
そのため、現在、 GCP のマネージド・サービスを活用し、クラウドに即したアーキテクチャへの変更に取り組んでいます。
広告サービスの開発には、 Google やYahoo!、Facebookといった広告プラットフォームとのAPI連携、広告データ(テキスト、画像、動画)やレポートデータ(広告のインプレッションやクリック、コンバージョンなどの実績)といった大規模なデータを取り扱うことがあります。
当社では Google AdWords やYahoo!スポンサードサーチ、Yahoo!ディスプレイアドネットワーク(YDN)といったインターネット広告の運用を支援するサービスとして、L2Mixerを開発・運用してきた長年の実績があり、これまでに培ってきた開発や運用のノウハウを活かした、新たな広告サービス基盤の構築にも取り組んでいます。
当社の広告サービス基盤の構築には、 GCP のマネージド・サービスを活用しており、主に以下のサービスを利用しています。
これらをどのように利用しているかを解説していこうと思います。
当社の広告サービス基盤では、広告プラットフォームから取得した広告データやレポートデータを Cloud SQL や GCS に保存しています。これらのデータを外部のWebサービスから利用できるようにするために、REST APIをGAE/Pyで開発しています。
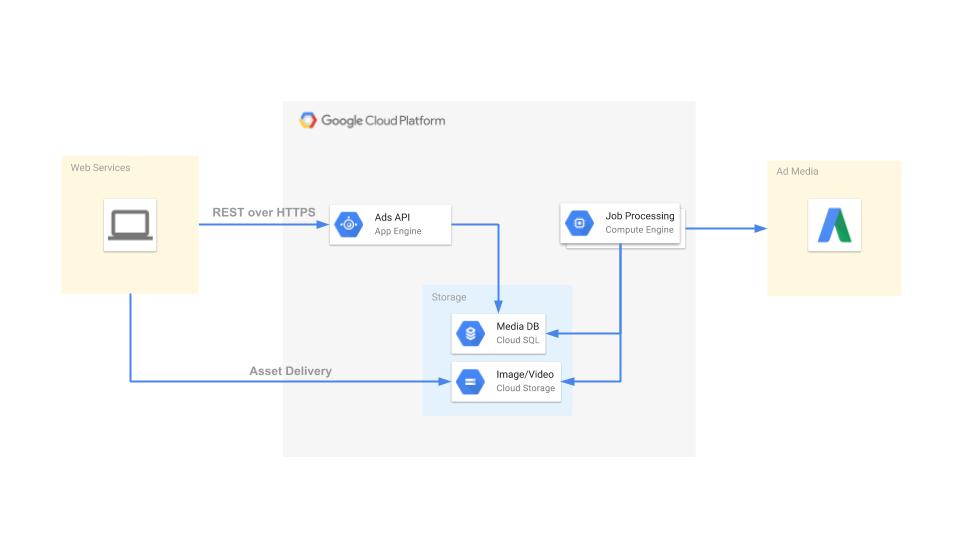
となります。
GAE を使う利点は、
セキュリティ対策のため、Webサービスの常時SSL化が当たり前となりつつある中で、最近、 GAE ではマネージドなSSLを無料で利用できるようになったことも利点です。
https://cloud.google.com/blog/products/compute/introducing-managed-ssl-for-google-app-engine?hl=en
広告サービス基盤の開発では、CircleCIを使ってテストやビルド、デプロイのプロセスを自動化していますが、 GAE へのデプロイは gcloud コマンド一発で済むため、デプロイの設定もシンプルに書けます。
また、 GAE はPythonやGoなどさまざまな開発言語をサポートしていますが、個人的には、最近 Standard EnvironmentでJava8が正式サポートされたことがトピックです。
広告サービス基盤には、広告データやレポートデータの取得といったバッチ処理をJava8で実装しており、バッチ処理は GCE 上で実行しているため、バッチ処理の実行環境として GAE の利用も考えています。
当社の広告サービス基盤では、広告データやレポートデータの取得といった時間がかかる処理は、バッチ処理で実行しています。
バッチ処理は、確実なスケジューリングと、ジョブの件数が増加してもスケールすることが重要ですが、これらを満たす環境を自分たちですべて構築するのは、大変な作業です。
広告サービス基盤では、 GCP が提供するマネージド・サービスを利用して、バッチ処理のスケジューリングと分散実行の環境を構築しています。
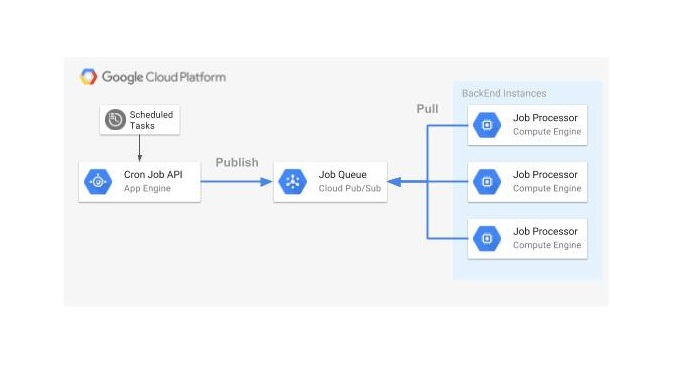
GAE には、ジョブ実行の要求メッセージを Pub/Sub へパブリッシュするためのアプリケーションをデプロイし、 App Engine Cron Service を利用して定期的に実行します。
一方でバックエンドには、ジョブ実行の要求メッセージを Pub/Sub からサブスクライブし、ジョブを実行するアプリケーションをデプロイします。
App Engine Cron Service により実行されるアプリケーションと、ジョブを実行するアプリケーションは Pub/Sub によって分離されているため、例えば、メンテナンスなどでバックエンドのアプリケーションが停止している最中に、要求メッセージがパブリッシュされたとしても、要求メッセージは Pub/Sub にキューイングされます。バックエンドのアプリケーションを再開すればジョブは実行される仕組みとなっています。
また、バックエンドのインスタンスを増やすことにより、より多くのジョブを実行させることも可能です。
GCP にはVMインスタンスをグループ化してオートスケーリングさせる機能も備わっているため、オートスケーリング機能を利用して、ジョブの件数に応じてインスタンスを増減させる仕組みも考えています。
インターネット広告を運用しているユーザー(広告主や広告代理店)にとって、広告プラットフォームから提供されるレポートデータを解析することは、重要な業務の一つです。
広告プラットフォームから提供されるレポートの種類は多岐にわたり、大規模な広告主や大手広告代理店が扱うレポートデータは、数十億行、数TBオーダーのデータとなることもあります。
GCP には、これらの大量データを解析するための基盤として Google BigQuery が提供されており、当社の広告サービス基盤でも BigQuery を活用しています。
インターネット広告のレポートデータは日別や時間別といった軸で取得することができるため、 BigQuery の日付分割テーブルを利用して、レポートデータを保存しています。
広告のレポートは一定期間で集計することが多いため、日付分割テーブルにレポートデータを保存しておくことにより、クエリの対象範囲を特定のパーティションに限定することができます。
日付分割テーブルを作成すると、_PARTITIONTIME という疑似列が暗黙的に作成されるため、_PARTITIONTIME 疑似列を使用して、クエリの実行中にスキャンされるパーティションの数を制限することができます。
クエリサンプル
SELECT
report_date,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks,
SUM(conversions) AS conversions,
SUM(cost)
FROM
mydataset.reports
WHERE
_PARTITIONTIME BETWEEN TIMESTAMP(‘2017-10-01’)
AND TIMESTAMP(‘2017-10-31’)
GROUP BY
report_date
ORDER GY
report_date
BigQuery の日付分割テーブルにデータをロードする方法には、
といった方法がありますが、当社の広告サービス基盤ではジョブでレポートデータをロードしています。
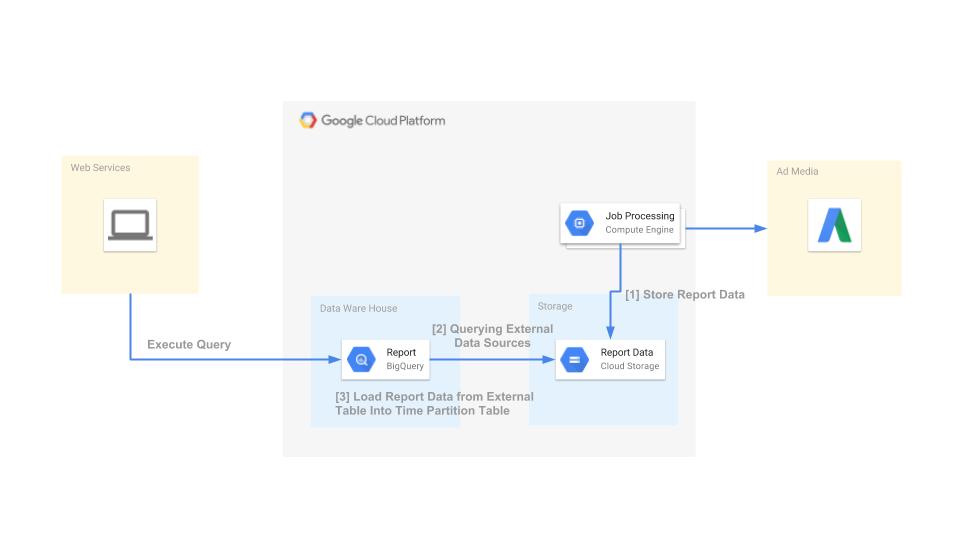
大まかな仕組みは
となります。
外部テーブルの作成例
bq mk –external_table_definition=reportsSchema.json@CSV=gs://mybucket/reports/20171001.csv.gz mydataset.external_reports_20171001
外部テーブルから日付分割テーブルにデータをロードするクエリ
bq query –allow_large_results –replace –noflatten_results –destination_table=’mydataset.reports$20171001′ “SELECT * FROM mydataset.external_reports_20171001”
BigQuery にデータをロードする方法は、クエリ以外には読み込みジョブやコピージョブを利用する方法もあります。
読み込みジョブやコピージョブは、データロードにかかる料金が無料で、クエリを利用するよりも簡単にデータをロードできますが、1日の実行回数に制限があります。(読み込みジョブは50,000回/日、コピージョブは10,000回/日)
当社の広告サービス基盤では、複数の広告主や広告代理店のアカウントを扱うため、アカウントの単位でデータセットとテーブルを分けています。そのため、アカウント数が数千の単位になると、読み込みジョブやコピージョブを利用した方法では、1日の実行回数に引っかかってしまうという懸念がありました。
クエリを利用した方法の場合には、1日の実行回数に制限がないため、広告サービス基盤では、外部テーブルとクエリを利用した方法で、データをロードしています。
今回は GCP のマネージド・サービスを活用したWebサービスの開発について説明させていただきました。
L2Mixerをオンプレミス環境から GCP に移行したことにより、さまざまなメリットがありましたが、私は、エンジニアがいろいろなアイデアをすぐに試せるようになったことが一番のメリットだと感じています。
何かを試したいときにさくっと環境を構築し、そこでアイデア(プロトタイプで実装したアプリケーションなど)を試してみて、不要になったらすぐに環境をなくすことができます。 GAE をはじめとしてマネージド・サービスには無料利用枠もあるので、ちょっとしたことを試す分にはお金のことも殆ど気にすることはありません。 GCP が提供するマネージド・サービスには、DataProc(SparkとHadoopのマネージド・サービス)やDataFlow(ETL、バッチ処理、継続的な計算処理などデータ処理のサービス)といった広告サービス基盤を構築する上で有用なサービスがまだまだあるため、今後はこれらのマネージド・サービスの活用にも、積極的に取り組んでいきたいと考えています。
「L2Mixer]」の GCP 移行については、TechTargetジャパンでも紹介されています。あわせてご覧ください。
「Google Cloud Platform」へ移行した企業に、使って分かった魅力を聞いた:ブレインパッドに聞くGCP活用のコツ(1/2 ページ) – TechTargetジャパン クラウド
ブレインパッドでは、今回ご紹介したような最新の技術を使って、自社のWebサービスを一緒に開発していただけるエンジニアを募集しています。ご応募をお待ちしています!
http://www.brainpad.co.jp/recruit/
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













