



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

本記事は、ブレンパッドの自社サービスである「Rtoaster(アールトースター)」のユーザー分析機能チームで開発をしている、新卒入社2年目のエンジニア吉田がお送りします。
実は、これに近しい内容を「builderscon 2019」で CfP で投稿しました。残念ながら不採用でした…が、抜粋してブログに書き起こそうと思い至り、この場を借りて紹介させていただきます。
上記のタイトルを見て、来ていただいた方々には申し訳ありませんが、以下はお話ししません。
当社のデータ基盤にBigQueryを採用しました。
自社サービス(Rtoaster)のユーザー分析機能チームがAWS環境内で構築・運用していたデータ基盤を捨て、プロダクト間共通利用を想定しているデータ基盤(統合データ基盤)に移行するための対応を2019年4月末に行いました。
この対応には、当時入社してから数ヶ月目の私のほか、2名のエンジニア、計3名が中心となり進めていました。
この記事では、特に私が担当した部分を触れつつ、どんなことをしたのかを書いていきます。
以下の内容を踏まえつつ、紹介を進めていきます。
これらの紹介を通じて、当社に入社している新卒エンジニアが取り組んでいる実務を知ってもらうこと、感じてもらうことを目的として書いています。
簡単にユーザー分析機能の紹介をします。Rtoasterは DMP市場で高いシェアを誇る、最先端のレコメンドエンジンと、ユーザーの可視化・分析エンジンが搭載されたSaaS型プライベートDMPで、ユーザー分析機能はRtoasterに組み込まれている機能の一つです。
https://www.rtoaster.com/:embed:cite
このユーザーの可視化の部分を担っているサービスがユーザー分析機能です。
ユーザー分析機能は、Rtoasterが蓄積したデータを扱って、利用者が容易にアクセス解析を行い、Webサイトの理解を深めながら、次のアクション(施策)を手早く行うことができる機能です。
具体的には、ユーザー行動のログデータを元に、どのページがよく閲覧されているのか、どこのページの文言に興味を持ってアクセスしたのか、等を可視化・集計(ユニークユーザー数、ページビュー数、セッション数…の可視化・集計)をしています。

データ基盤をAWS EMRからBigQueryに変更しました。データ基盤が変わったことでどのような変化があったのか、説明します。
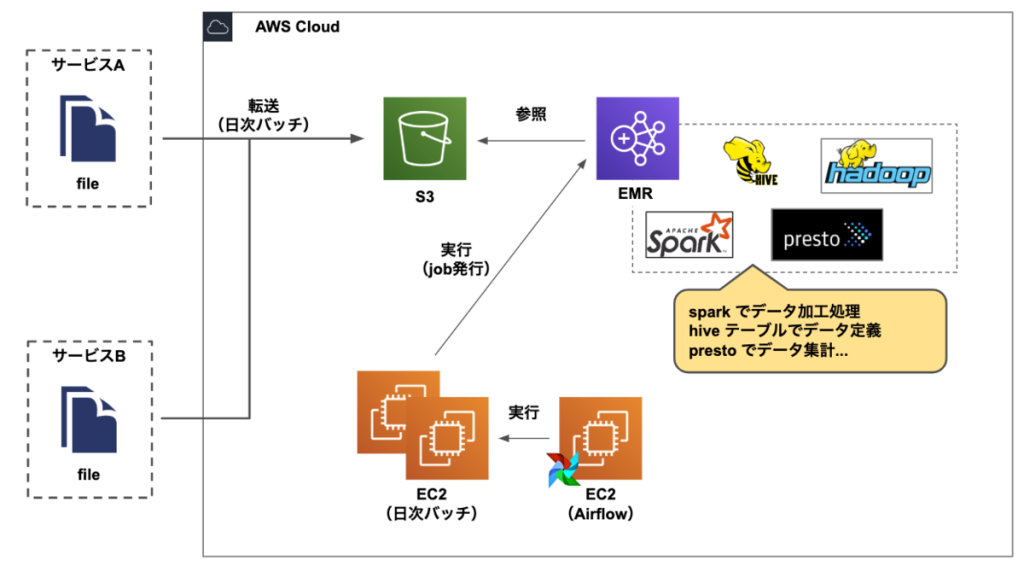
以下の画像は、AWS EMRで構築していたデータ基盤を活用していた時期のデータ加工までの流れを示しています。
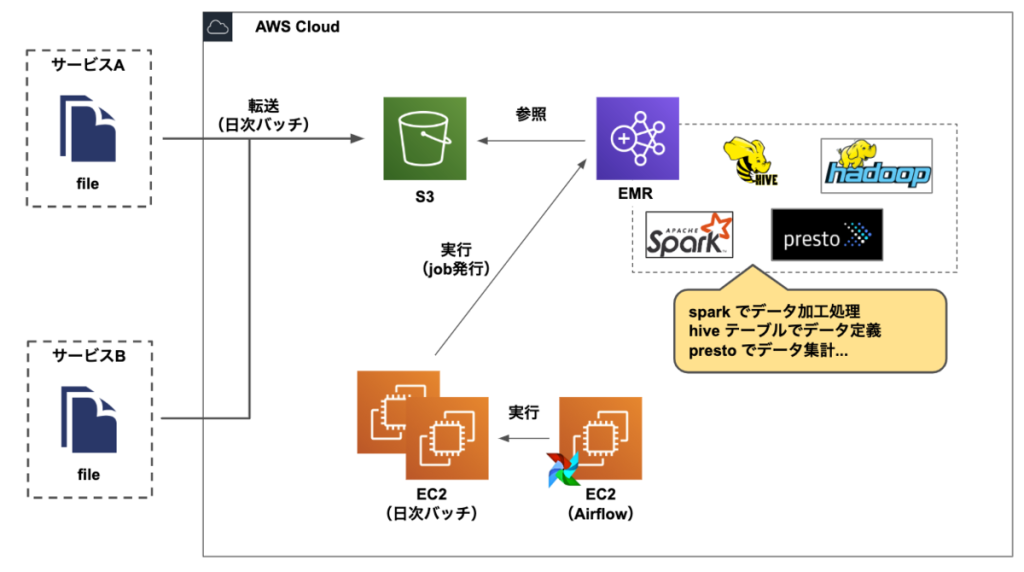
データ基盤移行前の環境
データ基盤移行前におけるデータ加工までのフローは、
といった順序です。このように データ分析機能チームではEMRを中心に、データの管理・運用をしていました。
次に、データ基盤移行後の環境です。
以下の画像は、BigQueryを中心とした環境におけるデータ加工までの流れを示しています。
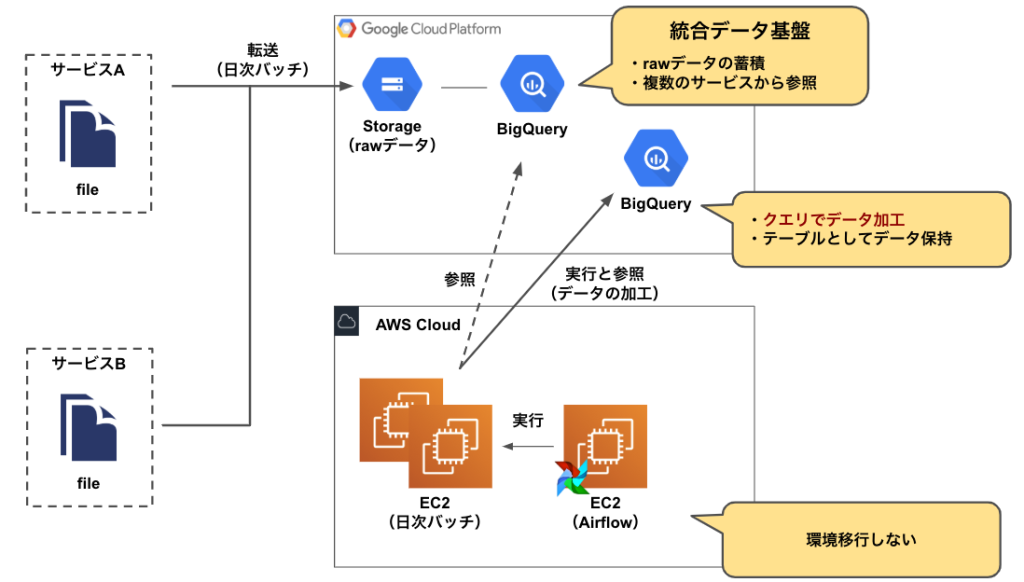
データ基盤移行後の環境
新たに統合データ基盤が構築されたことによって、
の点を、専任のエンジニアが受け持つようになりました。
以前は、開発の前に、複数のサービス同士のデータ連携には、サービスの担当者同士がデータ定義や連携について、仕様のすり合わせをしていました。
それに比べ、専任のエンジニアが中心にデータ定義や連携の仕様を担当することで、ユーザー分析機能チームは本来多くの時間をかけるべき、設計・開発を集中して行えるようになったと感じています。
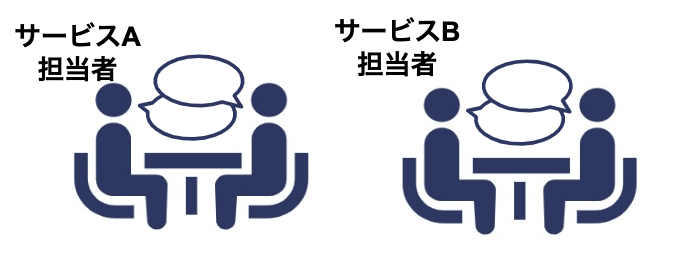
専任のエンジニアが主導で 、データの定義、保管する動きができた。
統合データ基盤を構築して以来は、
という風にデータ加工までの流れで開発をしています。
このデータ基盤移行時に、全ての環境をAWSからGCPには移行していません。
例えば、GCPには Google Composerがあり、Airflowの環境を変更することが可能です。
ただし、今回の環境移行に際し多大なメリットが得られる箇所がデータ基盤移行であったことから、集中してデータ基盤移行のための活動をしました。
データ基盤の移行に至った経緯には様々な理由が存在しています。特に課題感を持っていた2つを紹介します。
統合データ基盤の設計が進行していた背景もあり、独自実装して持っていたデータ基盤をAWS上で持つ必要がなくなったことが大きな要因でした。
移行前のデータ基盤はAWS EMRを中心に設計していました。ただ、上手にAWS EMRを活用するには 多くの知識、管理や運用が問われるものでした。
少人数で開発しているユーザー分析機能チームで、本来の多くの時間をかけるべきところ(設計・開発)に対し、運用負荷が高まっていたと感じています。
運用負荷の高まりと、ユーザー分析機能が持つデータ基盤を統合データ基盤に委譲を進めるとともに、全体のアーキテクチャの刷新を図っていくことになりました。
この統合データ基盤では、BigQueryを活用する方針で、連携等を考えてBigQueryを採用しています。
BigQueryを採用したことによる恩恵は非常に大きく、GCPのサービス間の親和性が高く、ETL処理も任せられるサービスが豊富((Cloud Composer、Cloud Dataflow、Cloud Pub/Sub etc…といったサービス))なことは、本来の多くの時間をかけるべきところに時間をかけれるようになったと感じています。
単純にAWSで独自実装していたデータ基盤自体、システム維持するためのコストで問題を抱えていました。
そこで、独自で実装していたデータ基盤(AWS EMR)からBigQueryに変更することでコストの最適化が図れることが調査してわかりました。
詳細なコスト面に関してはブログでの紹介は控えますが、私がチームに配属したあとにコストを見たときには驚きました。
ここで、なぜAWS環境で統合データ基盤を構築をしなかったのかについては、組織内でGCPに関するノウハウが蓄積されつつあったことが大きな動機になっています。
[http://blog.brainpad.co.jp/entry/2017/12/01/140000:title=Google App Engine( GAE )や Google BigQuery を活用したWebサービスの開発]という記事で紹介しているように、以前からBigQueryの活用、GCP環境で自社サービスの構築が進んでいたことで、
より前向きに「BigQueryで構築する」という流れがあったと認識しています。
http://blog.brainpad.co.jp/entry/2017/12/01/140000:embed:cite
よかったこと「プロダクト内部のコードをある程度統一できたこと」
BigQueryに移行したことで得たことは、データ加工に用いていたscalaコードが大幅に削減できたこと、データ加工にはクエリだけである程度対応可能であったことでした。
以前は、データ加工ではscalaを主に利用し、サービスではpython(backend) + vue(frontend)で構築されて、とコードが統一されていない問題がありました。
今回の移行では、UDF(ユーザ定義関数)を活用しつつ、クエリのみで実装していく方向で進めて、scalaコードを大幅に捨てることができたことは良かったと感じています。
ただし、k-means法のクラスタリングを利用している箇所においては、Google Cloud Dataproc を用いて、データ加工をしています。
当ブログでも、BigQuery MLで、k-means(beta)が対応したことを紹介していましたが、「k-meansを用いたデータ加工の実装をBigQuery MLに代替できるか」の調査は終了しており、Google Cloud Dataproc を止める計画を進行している段階です。
http://blog.brainpad.co.jp/entry/2019/05/30/110000:embed:cite
大変だったこと「クエリの書き換え」
prestoで利用していたクエリは全て破棄し、かつ集計・可視化するサービスということで同一の結果が得られるようにクエリを合わせていくことは、大変でした。
この prestoで利用していたクエリは、SQLAlchemyで生成されていたクエリで、BigQuery対応ではSQLAlchemyを止めた上で、クエリの再実装が求められ、さらにデータ加工のクエリも実装していました。
また、結果の保証も必要であったことから、大量のテストを用意して確認していました(ここには紆余曲折がありますが、割愛します…)。
今回は、ユーザー分析機能におけるデータ基盤の移行について紹介させていただきました。
ユーザー分析機能の環境移行は、AWSからGCPに移行するにあたって、
といった対応が残っている状況です。タスクや優先度に合わせ、対応を考えていきたいと思います。
ちなみに、上記において担当した箇所はなにかと言われると、全体の対応を行っていた認識で、環境検証・開発実装・インフラ構築をしていました。
新卒1年目のエンジニアでも、このような大規模な改修を経験させてもらい、色々と学びながらやらせていただきました。
ここでの紹介では、「データ基盤をAWSからBigQueryに変更した」だけの情報です。
私が次回に書く記事では、実際にサービスで利用している Tips を少し紹介させていただきたいと思います。それでは。
ブレインパッドでは、エンジニアを積極採用中ですので、ご興味がある方はぜひお問合せください。下記より直接エントリーも可能です!お待ちしています!
株式会社ブレインパッド 自社サービス開発エンジニアの求人一覧
[https://hrmos.co/pages/brainpad/jobs?category=1354660212331102208:embed:cite]
株式会社ブレインパッド システムエンジニアの求人一覧
[https://hrmos.co/pages/brainpad/jobs?category=1117376730156548096:embed:cite]
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













