



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

自社開発サービスである「Rtoaster(アールトースター)」は、2019年にユーザー分析機能の「自動クラスタリング機能」をSpark(DataProc)からBigQueryMLに移行しました。
ブレインパッドの新卒2年目の自社サービス開発エンジニアが、新卒1年目で取り組んだ、この大きなプロジェクトでの経験についてご紹介します!
本記事は、ブレインパッドの自社サービスである「Rtoaster(アールトースター)」のユーザー分析機能のチームで開発をしている、新卒入社2年目のエンジニア柴内がお送りします。
私は新卒1年目だった昨年秋ごろ、ユーザー分析機能の「自動クラスタリング機能」をSpark(DataProc)からBigQueryMLに移行する仕事を担当しました。その時にやったこと・得られた知見について共有できればと思い、この記事を執筆しました。
ユーザー分析機能をGCPベースに移行した話も併せてご覧いただければと思います。
Rtoaster(アールトースター)は、レコメンドエンジンをはじめとしたマーケティング活用のための機能が多数搭載されているSaaS型プライベートDMPであり、ブレインパッドの主力製品の一つになっていhttps://www.rtoaster.com/
ユーザー分析機能は、Rtoasterの機能のひとつで、訪問者を条件で分類した「セグメント」の作成や可視化を行えます。可視化においては、サイトにアクセスした訪問者の傾向や時系列に従った傾向の変化などを知ることで、新たな施策へのインサイトを得られます。また作成したセグメントを、ポップアップ通知やメールなどのアクションにシームレスに連携できます。
そのセグメント分類機能の1つに「自動クラスタリング」というものがあります。これは、訪問者がアクセスしているページの傾向を訪問者ごとに集計を行い、それを特徴量として複数のクラスタに分類する機能です。対象の特徴量はトラッキングから自動で生成されるため、Rtoasterのオペレータ(導入されたサイトの運営者)が特別な設定をする必要はありません。

Rtoasterの自動クラスタリング機能は数年前に研究・実装が行なわれ、大規模データ処理エンジンであるApache Spark上にてScalaで実装されていました。以前のブログ記事にもあるように、最初はAWS EMRでバッチを動かしていましたが、GCP移行に伴い類似サービスであるDataProcで運用するようになりました。DataProcとは、SparkやHadoopなどのOSSのデータ処理エンジンをGCEの複数のインスタンス(クラスタ)を制御して実行するマネージドなサービスです。
無事にDataProcへの移行は完了しましたが、以下のような問題点がありました。
そこで、BigQuery MLへの移行が計画として立ち、まずは検証から行うことになりました。
BigQuery MLは、BigQuery上で標準SQLを用いて機械学習モデルのトレーニングや予測をする機能です。MLを用いるための特別な設定やワーカのプロビジョニングがいらず、既存のBigQuery APIやGCPコンソールの中で利用できます。また、BigQuery内部のエンジンで自動的に分散処理が行なわれるため、コストパフォーマンスにも優れています。機械学習のメソッドとしては以下のようなものが提供されています。
それぞれの予測アルゴリズムについては深くは触れませんが、当社の新卒研修資料「分析の基礎」で触れられているものもあるので興味があればご覧いただければと思います。
現在、BigQueryMLの料金は、予測の場合非MLクエリと同価格の1TBあたり$6(東京リージョン)と非常に低価格に抑えられているため(モデル学習の場合は$300です)、Spark on DataProcと比較して非常に低コストで運用できるという点が魅力でした。
既存のSpark基盤では、複数の自動クラスタリングのアルゴリズムによるバッチ処理が実装されていました。ソースコードからアルゴリズムを読解した結果、いずれもBigQueryの数学・統計関数とMLで実現できることがわかりました。今回はその中でもBigQuery MLを用いた「カテゴリクラスタリング」処理の移植についてフォーカスします。
「カテゴリクラスタリング」ではざっくりと以下のような処理を行なっています。
1. 全トラッキングデータを解析し、訪問先ページを数十のセクションに分割した「カテゴリ」を作る
2. 訪問者ごとにカテゴリの閲覧傾向の比率を計算し、訪問者ごとの特徴ベクトルとする。
3. k-meansで学習し、訪問者がどのクラスタに属するかを分類する。
1, 2はいわゆる「前処理」であり、既存のSpark基盤のコードを等価な SQL 表現にするというそこそこハードな作業でした。この作業においては、新卒研修期間中に受けたSQL研修の資料(その資料自体はRedShiftに関するものでしたが)の知見がかなり役に立ちました。(特に集約やウィンドウ関数)
https://speakerdeck.com/brainpadpr/sql-for-data-handling:embed:cite
その中でも具体的な話を(かなり簡略化していますが)1つしたいと思います。2の処理において閲覧データを処理することによって以下のようなデータが得られます。

単純にmember(訪問者)ごとのカテゴリの比率を計算するためには、以下のようなSQLで計算すればよいです。
sql
SELECT member, category, COUNT(category) / COUNT(*) AS ratio
FROM user_tracking_with_category
GROUP BY member
しかしBigQuery MLの学習・予測データとして利用するには、特徴ベクトルが1列ずつ並んだデータとして利用しなければなりません。いわゆる縦持ち・横持ちの変換をする必要があります。ここでは、カラム数がカテゴリの総数に応じて変化することになります。
# モデル生成のための疑似コード
WITH
feature_vec AS (SELECT
COUNTIF(category = 'category1') / COUNT(*) AS c_0,
COUNTIF(category = 'category2') / COUNT(*) AS c_1,
...
COUNTIF(category = 'categoryN') / COUNT(*) as c_N
FROM user_tracking_with_category
GROUP BY member)
CREATE OR REPLACE MODEL
`auto_clustering_model`
OPTIONS
( model_type='kmeans',
num_clusters=[クラスタ数N] ) AS
SELECT * FROM feature_vecただ、カテゴリの要素数は事前計算によって得ることになっていたので、Nの数はサイトごとに固定です。そのため、実装では事前計算で得られたカテゴリ数を元に、PythonコードでSQLを動的生成することにしました。
sql = "WITH feature_vec AS (SELECT"
sql += ",".join(f"COUNTIF(category = '{c}') / COUNT(*) AS c_{i}" for i, c in enumerate(categories))
sql += " FROM user_tracking_with_category)"
# 以下省略ただ、現在では、BigQueryにはEXECUTE IMMIDIATEという文字列からダイナミックにSQLを生成・実行する仕組みがあるため、それを利用することで同じことが実現できるかと思います。
移行に際し、移行前後で結果の差分が生じないようにする必要がありました。ですが、トラッキングデータは日々変化するので、再学習をすると結果が変わってしまうため、既存のモデルを移行する必要がありました。k-meansにおいては、「既存のモデル」とは各クラスタの中心点の座標(n次元ベクトルがクラスタ数個分)にあたります。
Sparkの保存した中心点の座標はparquet形式で保存されていたのでPythonでも容易に取り出せたのですが、BigQuery MLのk-meansクラスタリングの場合、簡単にモデルを取り込める機能はありません。(Tensorflowモデルを取り込む機能はありましたが、パフォーマンスが不明確なのと、当時はプレリリース〜ベータ版であり本番への投入は見送りとなりました)
そこでk-meansのアルゴリズムに注目し、「クラスタ数Nで中心点のデータN個のみを学習すれば、既存のモデルと等価なモデルができる」ということに気づきました。これの利点としては、BigQuery MLの学習が即座に終了するので、時間もコスト(作成は予測よりも料金が高いです)もかからずにモデルを作れるというものがあります。
モデル移行の実際の処理は以下のようなものになっています。
-各モデルに対して以下を実行する
1. Sparkのparquetファイル(既存モデル)からクラスタ中心点を取得する
2. クラスタ中心点を用いて学習し、クラスタリングモデルを作成
3. クラスタリングモデルの整合性チェック
a. 作成されたモデルのクラスタ中心点がずれなく保存されているかのチェック
b. 各訪問者のクラスタが相違なく分類できているかの検証
c. 各訪問者のカテゴリの比率の等価性の検証
4. クラスタリングモデルの保存(ドライランオプションがある場合、保存しない)
クラスタリングモデルの整合性チェックでは、検証自体をBigQueryのSQLで記述しました。新旧実装の比較が訪問者IDをキーとしたJOIN処理で簡単にできたので、リレーショナルなクエリの恩恵を感じました。
実際の移行作業においては、アルゴリズムや処理の抜け漏れがないかを調査するため、全体のサイトで一致するか検証(ドライラン)してからモデルを作るという作業になりました。これによりステージング環境のデータでは予想できないパターンが本番環境のデータであったとしても、移行を止めて再検証することができるようになりました。
BigQuery移行の結果、以前の問題点だった「インスタンスの料金が高め」「1回のバッチに数時間かかる」「運用の対応が面倒」といったものを解消できました。
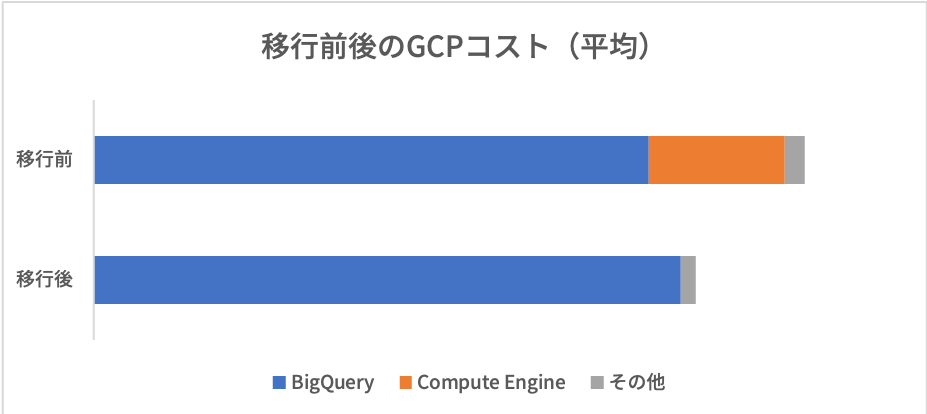
DataProcのクラスタを作らなくてもよくなったということで、月に数万円かかっていたコストをそのまま削減できました。
一方で、増加したBigQuery MLの処理料金については、移行時期にちょうどBigQueryの料金値下げがあったため、実質その差分に吸収されたため詳しくは把握できていません。しかし、それを鑑みても少なくない料金の削減を達成できました。他にも、GCSとの転送コストが下がるなどの成果もありました。
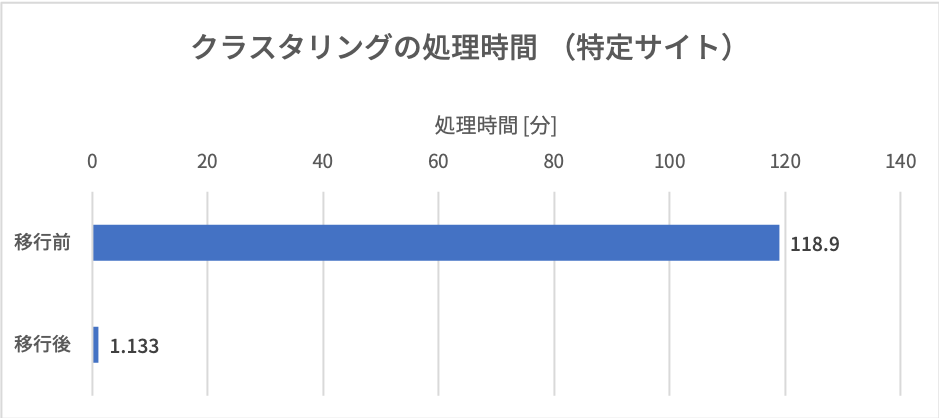
移行により一番効果が出たのは実行時間でした。今まで5〜6時間かかっていた自動クラスタリングのタスクが1時間以内に終了するようになりました。処理する対象サイトの中には、総計数十億レコードを処理するケースもありました。このようなトラッキング数の多いサイトに対する処理は、移行前の時点で2時間程度がかかっていました。しかし、修正後は数分で完了するようになり、処理時間の大幅な短縮を実現出来ました。また、BigQuery上で直接結果の読み書きができるようになったので、以前行っていたGCS間のインポート・エクスポートも不要になりました。

移行前まではあるサイトについてエラーが発生すると、それ以降のバッチ処理も終了するので復旧のために手動で状態のクリア→処理の再実行が必要でした。ここで発生するエラーは、GCP(BigQuery、DataProc)の一時的なエラーやSparkのメモリエラーなどがほとんどで、少ないながらもそれなりの頻度で発生していました。
移行後は、Sparkに起因するエラーは発生しないようになり、またBigQueryのエラーについてもAirflowが自動でリトライを行うため特に対応する必要がなくなりました。Airflowの利用については、Builderscon2018の当社発表もよろしければご覧ください。
https://www.slideshare.net/BrainPad/2018-builderscon-airflow:embed:cite
リリースについても、クラスタリングの処理自体がBigQuery SQLに集約されたため、毎回のリリース作業の負担(テスト、ビルド、デプロイ)が軽減されました。
以上がBigQuery MLへの移行のお話でした。新卒の研修が終了し、チームに配属された後ではじめてやった大きな仕事がこの仕事で、アルゴリズムの検証などやScalaからSQLへの移行などとても楽しく取り組むことができ、また顕著な結果が出たことの達成感もありました。なかなか個人ではこのような規模のデータ処理を行うことができないため、この機会はクラウドベースの大規模データ処理についての知見を得る貴重なものとなりました。
ブレインパッドでは、エンジニアを募集しています。大規模なデータを扱うために、インフラからアルゴリズムまで様々なことを検討・実装しながらプロダクトを成長させています。もちろん、それをどのようにユーザーに価値として提供するかに関わっているフロントエンドも重要です。一緒にデータドリブンなプロダクトの未来を作っていただける方はぜひエントリーをお願いします。
https://hrmos.co/pages/brainpad/jobs?category=1354660212331102208:embed:cite
https://hrmos.co/pages/brainpad/jobs?category=1117376730156548096:embed:cite
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













