



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

深層学習の登場により、時系列データ、画像、動画といったサイズが大きいデータの異常検知が現実的に可能となりました。
ブレインパッドも異常検知技術を製造現場の不良品検知プロジェクトに応用してすでに多くの成果をあげており、これからもさらなる活用が見込まれています。
さらにナレッジを高めるため、このブログで工業製品に対する不良品検知に関して、様々な手法の性能検証する連載をスタートします!
こんにちは。アナリティクスサービス部の北島です。
ブレインパッドの不良品検知に関するナレッジを高めるため、自分を含め4人のメンバーが興味を持った手法について、性能検証をする連載を開始します。
本連載を通して、不良品検知の世界を僅かながらでも伝えられたらと思います。
異常検知とは、データの中から通常のパターンとは異なる異常な挙動を検出することを言います。
クレジットカードの不正使用検知やシステムの故障検知など様々な分野で異常検知技術が活用されています。
ブレインパッドで取り組み実績のある異常検知領域に、製造業における不良品検知があります。
製造現場において、不良品検知の精度を向上させることは製品の信頼性確保のために非常に重要です。不良品検知は従来、人の目に頼られていましたが、近年の画像認識技術の発展とともにAIを活用するケースが増加しています。AIを用いた不良品検知システムの導入により、検知速度の向上や人員コスト削減などのメリットが期待できます。
一言で異常検知と言っても、様々な問題が存在します。
以下、異常検知のサーベイ論文*1から異常検知問題の難しさについて簡単にご紹介いたします。
未知性:過去に存在したことがない異常は学習が困難
機械学習は、過去のデータからパターンを見つけ出し、そのパターンを活用することで物事の判断や識別をしています。そのため、過去に記録がない現象については学習することができません。
例えば、テロリストやハッカーの攻撃など、過去に攻撃を受けたことがなければそれらを検知することは困難です。
特異性:異常の種類が複数あり、各種類で特徴が全く異なる場合
異常の種類が複数ある場合、まずは正常と異常の二値判別でよいのか、異常種類の判別まで必要なのかを検討する必要があります。特に、実際のビジネスに当てはめる際、異常の種類によって検知後の対応が異なることも想定されます。 そのため、異常であるという事実を見つけるだけでは課題解決に不十分な可能性があります。
異常の種類まで判別する場合は問題が複雑になり、正常/異常の二値判別の場合でも異常種類別に大きく特徴が異なれば、異常の特徴を学習することは困難です。
不均衡性:正常ラベルに対して異常ラベルが極端に少ない場合、異常の特徴の学習が困難
一般的に、製造現場などにおいて不良品(≒異常)が発生する確率は低いです。
その結果、データセット中の正常サンプル数と異常サンプル数の差が大きくなり、図1のようにサンプル数が不均衡になることがあります。
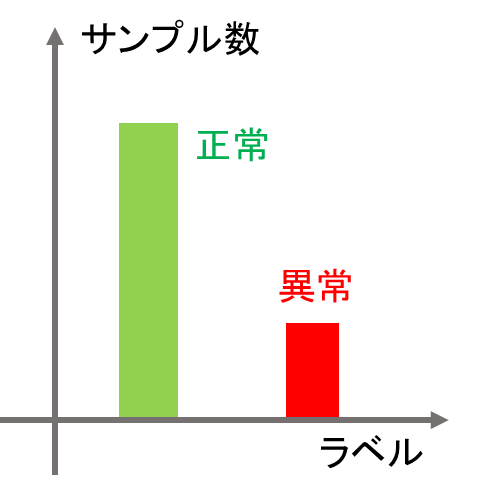
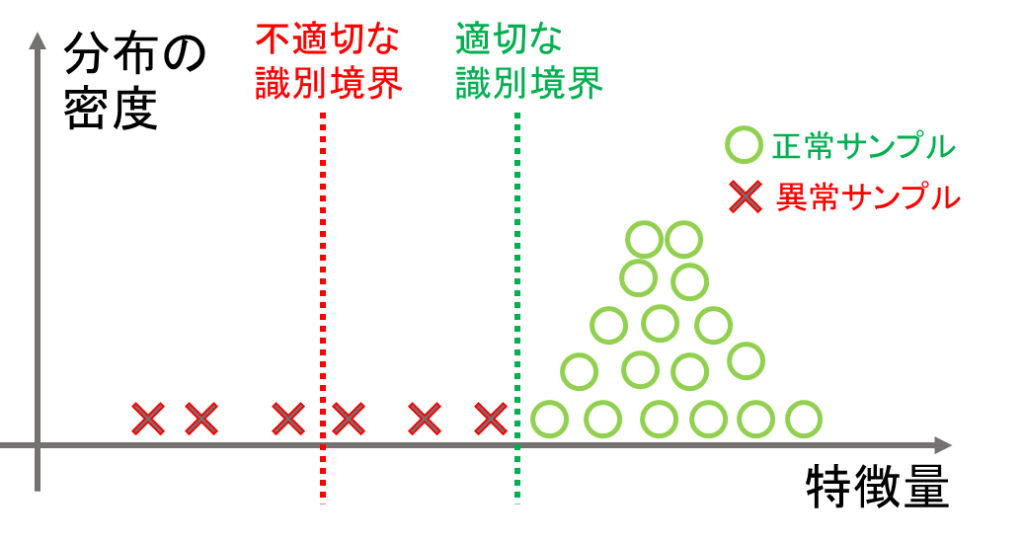
こういった不均衡なデータセットで教師ありモデルを構築すると、異常データに対するリコール(異常と予測したサンプル数 / 全体の異常サンプル数)が小さくなることが多いです。
なぜならば、異常サンプルの特徴を十分に学習することが出来ず、図2のように不適切な識別境界を引いてしまうからです。
多様性:背後にある条件によって正常か異常かが異なる
例えば、季節性のある製品を対象とした異常検知では、異常の定義が季節によって変化する場合があります。
他にも、ソーシャルネットワーク上の異常検知では、大量の偽アカウントのみとつながりのある集団は異常であるが、個々の偽アカウントは異常ではない、などの集団異常といったケースもあります。
上で説明したような様々な問題を解決する手段の一つとして、良品学習があります。
良品学習とは、良品(≒正常)データのみを学習させる教師なし学習のことをさします。正常と異常の両方を学習させる教師あり学習モデルと異なり、上記の “未知性“、”不均衡性” の問題を回避しやすいというメリットがあります。
下記に異常検知における教師あり学習と教師なし学習の特徴をまとめます。
| 教師あり学習 | 教師なし学習 | |
|---|---|---|
| 検知方法 | 正常と異常の両方を学習し、異常を検知 | 正常のパターンのみを学習し、 正常から逸脱するものを異常として検知 |
| メリット | 教師なし学習と比較すると精度が高い傾向 | 未知の異常にも対応可能 |
| デメリット | ・不均衡データの場合、異常の特徴を捉えられない可能性がある ・学習データに含まれない異常は検知が難しい | 教師あり学習と比較すると精度が低い傾向 |
今後の連載で行う性能検証では、MVTec Software GmbH社が公開している不良品検知用のデータセット「MVTecAD」を用います。*2

MVTecADは、15種類の工業製品カテゴリーについて、良品データと不良品データが用意されています。さらに、不良個所のセグメンテーションも用意されており、画像内の不良個所の位置を特定するタスクに取り組む場合にも役立つ不良品検知の性能検証に特化したデータセットです。
15種類のカテゴリーのうちの一つ”leather”のデータセットの構成を下図に示しました。訓練データセットは良品のみ、テストデータセットには良品と複数種類の不良品が含まれています。良品のサンプル数が277枚、不良品のサンプル数が92枚と不均衡なデータセットになっているため、実際の製造現場における不良検知を想定して性能検証をすることができます。

異常検知における様々な問題点とそれらを解決する手段をほんの一部ご紹介しました。
実際、ブレインパッドの過去の異常検知プロジェクトにおいても様々な問題に対応してきました。しかし、一つの手法だけに精通していても、問題に対して適切な手法を選択することはできません。そのためブレインパッドでは、個人での研鑽はもちろんですが、チームとしても日々輪読会や論文読み会などを開催し、様々な問題に対応できるよう努めています。
次回以降、検証で得たノウハウを共有していこうと思います。
記事が更新されるたびに、以下の目次も更新していきますので、どうぞお楽しみに!
<連載記事>
– 第1回:【連載①】画像に対する教師なし深層異常検知の基本手法【不良品検知ブログ】
– 第2回:(仮)パラメータ自動調整する深層距離学習手法で異常検知 ~Adacos~
– 第3回:(仮)少量の学習データで機能する異常検知手法 ~DifferNet~
– 第4回:(仮)中間表現の分布を用いた異常検知手法
AIによる不良品検知をはじめ、データサイエンスを仕事にしてみたい皆さま!
ブレインパッドでは、新卒採用・中途採用ともに新しい仲間を積極的に採用しています。 弊社にご興味のある方は、是非採用サイトをご確認ください!皆さまのご応募お待ちしています。
https://www.brainpad.co.jp/recruit/
*1:Pang, Guansong, et al. “Deep Learning for Anomaly Detection: A Review.” ArXiv Preprint ArXiv:2007.02500, 2020.
*2:Bergmann, Paul, et al. “MVTec AD — A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection.” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 9592–9600.
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













