



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

不良品検知の手法に関するナレッジをさらに高めるため、工業製品に対する不良品検知に関して、様々な手法を性能検証する連載をスタートします! 今回はその第1回です。
こんにちは、アナリティクスサービス部の廣岡です。本ブログは、画像による不良品検知に関する連載ブログの第1回です。本記事では、まず画像の異常検知に対して深層学習を用いることのモチベーションからはじめ、そのあとに基本的なアプローチを紹介します。画像の異常検知は近年も新しい手法が提案されていますが、それらを理解する上でもベースとなる基本的な手法を押さえておくことは重要と言えます。
これらを通じて、画像の異常検知に対して深層学習がなぜ有効なのか、また基本的な手法の核となるアイデアについて理解の助けになれば幸いです。
工業製品などの生産工場では多くの場合、製品や材料に欠陥がないかどうかを確認するために、見た目をチェックする工程が含まれます。こうした欠陥による影響は様々ですが、最終的に製品を利用するお客様の安心や安全のために対処しなければならないという点は多くの企業で共通していると言えるでしょう。このように見た目をチェックする工程は外観検査と呼ばれます。
外観検査の問題設定は、生産される製品や材料のほとんどは商品に利用できる良品(正常品)であり、その中に混入したごく少数の不良品を検知する問題であると言えます。これは機械学習で扱う場合、異常検知として捉えることができます。またブレインパッドでは「不良品を検出する」と言うことを強調して不良品検知と呼ぶこともあります。前回の記事で紹介したMVTecADデータセットも多くの良品画像に対して少数の不良品画像を検知すると言う点で、不良品検知としてアプローチするのに適したデータセットであると言えます。
また今回は取り扱いませんが、画像以外の異常検知も社会には多く存在します。例えばクレジットカードの利用履歴に対する不正利用の検知や、インターネットトラフィックの急激な変化の検出などが挙げられます。
具体的な手法の紹介の前に、不良品検知に対して深層学習を用いる理由をおさらいします。ここでは以下の二つのポイントに注目します。
当たり前ですが、工業製品に対して不良品検知を行いたい場合、必ずしも深層学習に頼る必要はありません。実際、工業製品の検査は機械学習や深層学習が普及する前から取り組まれています。
もっとも単純な検査方法は人手による検査です。人手の検査の何よりも優れている点は言語のコミュニケーションを介して不良品の定義などを議論・共有できるところでしょう。一方で、どこまでを不良品としてどこまでを正常品とするのかについて、複数人で基準を統一するのは非常に難しいと言えます。また作業者が同じ場合でも、体調や疲労の度合いによっては、長時間同じ基準で目視検査を行うのは難しいと言えます。
こうした属人性を解決するには、プログラムによって処理を行うことが効果的です。大きさや形状などの点で、不良品となる基準をわかりやすく設定できる場合には、アルゴリズムによって検査処理を行うことで、半永久的に同じ基準で不良品検知を行うことが可能になります。例えばOpenCVはさまざまな画像処理アルゴリズムも実装されているツールです。これを利用することで高度な不良品検知を行うことも期待できます。
画像処理アルゴリズムはたくさんの種類がありますが、不良の基準となる特徴を適切にプログラムするのは難しい場合もあります。例えばMVTecADデータセットには以下のようなサンプルが含まれています。赤枠で示されている不良品は目視ではわかりやすいものもありますが、不良の基準となる色や形状をプログラム上で定義するのは難しいと言えます。

不良品検知に対して機械学習、特に深層学習を用いるのは、このような定義しづらい特徴を考慮するためと言えます。本ブログでは詳細は省きますが、画像認識における深層学習の有用性は、2012年に開催されたILSVRCと言う画像認識コンペティションを契機として爆発的に認知されるようになっています。画像認識に置いて深層学習が広く利用される理由の一つは、予測に重要となる特徴量を人手で設計することなく、特徴抽出自体を学習できるという点です。よって不良品検知に対しても深層学習を検討するのは自然な流れと言えます。
さて、深層学習によって画像に対する高度な特徴抽出が期待できると記述しましたが、不良品検知を行う際には一つ考慮しなければならない問題があります。深層学習モデルは膨大なパラメータを学習する必要があるため、豊富な学習データを用意する必要があります。前回の目次ブログで紹介したように、不良品検知の問題設定では不良品画像の枚数は欠陥のない良品画像に比べて非常に少ないと想定されます。よって良品と不良品の分類を教師ありのアプローチによって直接学習するのは難しいと言えます。
こうした場合にはまず良品がどのようなものかを学習しておき、これと異なるものは全て異常(不良品)とするアプローチが取られます。良品データは不良品に比べて豊富に用意できることが多いため、これは不良品検知だけでなく異常検知という分野全体で基本的なアプローチです。良品だけで学習を行うという点で、以降これを「良品学習」と呼んでいきます。
これらを踏まえると、画像に対する不良品検知を深層学習モデルの良品学習によって取り組むことが検討できます。本ブログでは、これを実現する基本的なモデルとして以下の二つを紹介します。
CAEとBiGANはどちらも、入力画像の再構成というアプローチによって不良品検知を行います。一方で後述するように学習方法は異なっており、それぞれの手法の特徴を生み出しています。
補足として、正常データから外れたものを異常とするアプローチ自体は、深層学習に限らず1クラスSVMなど色々な手法が存在します。今回は画像の高次元な特徴抽出が期待できる手法として、深層学習ベースのアプローチを検討します。
AutoEncoder(自己符号化器)は、ラベルを用いずにデータの特徴を学習する手法としては非常にシンプルかつ基本的な手法と言えます。全体のモデルは入力データから特徴抽出を行うEncoder(符号化器)と、特徴量からデータを復元するDecoder(復号化器)からなります。入力データから特徴量を経由し、Decoderによってデータを復元するという過程から、”Auto”Encoder(自己符号化器)と呼ばれます。データを復元するように学習することで、Encoderは特徴量が復元に必要な情報を保持するように学習することとなります。
CAEはこのEncoderとDecoderを畳み込み(Convolution)によって構築します。畳み込みの利用を明示的にせずにそのままAutoEncoderとして呼ばれることもあります。CAEによって良品学習を行うことで、Encoderには「良品がどのようなものか」に関する特徴量の抽出が期待できます。
こうして学習したCAEは、良品画像を入力とした時は適切に画像の再構成を行えます。対して不良品画像を入力とした場合には、不良箇所に関してはうまく再構成できないと期待できるため、再構成誤差に基づいた不良品検知が可能になります。また、再構成誤差はピクセルごとに計算されるため、画像のどこが不良なのかを見た目で確認しやすいというメリットもあります。

以上を踏まえて、MVTecADデータセットに対してCAEを用いた不良品検知の実験を行いました。学習方法などは以下のように設計しました。
Precision(精度)とRecall(再現率)は異常検知において広く使われる評価指標です。不良品検知の場合は、Precisionが高いほど良品に対する誤検知が少なく、Recallが高いほど不良品の見逃しが少ないことを意味します。この二つはどちらも高いほど良いのですが、良品の誤検知を減らそうとすると不良品の見逃しが増え、見逃しを減らそうとすると誤検知が増えてしまうというトレードオフの性質があります。実務上はこのバランスを業務要件と照らし合わせて適切に調節する必要があります。
以下はヘーゼルナッツカテゴリの良品画像に対する検知結果の例です。再構成誤差は絶対値で計算しています。入力画像に近い画像を再構成できており、良品として判定できそうです。

不良品画像に対する検知結果は以下のようになりました。ヘーゼルナッツカテゴリには割れ目や印字などの不良品画像があります。右から二列目の画像において明るくなっているところが再構成誤差が大きい領域であり、これらは不良品としての判定が期待できます。

図3、4に示した画像は適切に良品・不良品の判定ができそうですが、一方で検知が難しい画像も存在しました。図5上段は良品画像に対する検知結果ですが、殻の模様が変わっている箇所の再構成誤差が大きくなっています。下段は傷がついた不良品画像ですが、再構成誤差はあまり大きくありません。これは不良箇所が小さく、また色も周囲とあまり変わらないからだと考えられます。
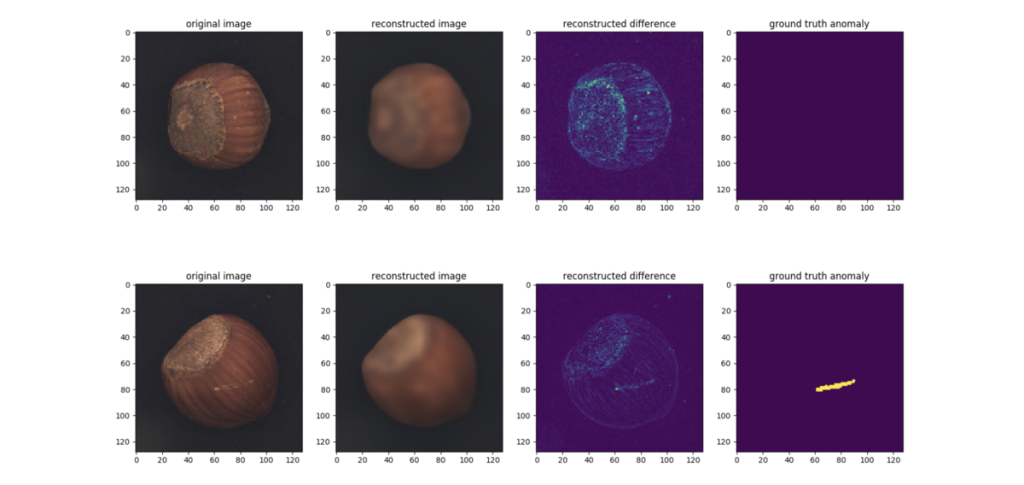
図5からわかる特徴として、CAEは入力画像よりもややぼやけたような再構成画像を出力します。これはピクセルごとの再構成誤差を最小化しているためです。今回の実験ではあまり問題になりませんでしたが、物体や不良の種類によっては誤検知・見逃しに繋がるため注意が必要です。
他にCAEの利用時に注意すべき点としては背景のノイズが挙げられます。再構成誤差に基づいて検知を行うという性質上、入力画像の背景にノイズが含まれていると、そのノイズを不良として誤検知してしまう可能性があります。
またピクセル単位ではなく画像単位で不良品かどうかを判定するには、CAEとは別に画像全体の再構成誤差を集約するための後処理が必要になります。例えば細かい再構成誤差を無視するためのノイズ除去や、不良箇所を捉えるための連結成分の計算などが考えられます。これらは実際に扱う画像をよく観察した上で検討することになります。
このようにCAEはメリットもデメリットもありますが、シンプルで適用しやすい手法なのでベースラインとしても十分検討できると言えるでしょう。
GAN(Generative Adversarial Network、敵対的生成ネットワーク)とは、Generator(生成器)とDiscriminator(識別器)という二つのニューラルネットワークによってデータの生成分布を学習するモデルであり、深層生成モデルという大きな枠組みのうちの一つのアプローチとして数えられます。本ブログでは深層生成モデルの詳細は割愛しますが、GANは特に画像分野においては精巧な画像を生成できるモデルとして注目されています。

GANを不良品検知に用いることのモチベーションは、基本的にはCAEと同じと言えます。つまり良品画像のみを用いて良品画像がどのようなものかを学習し、それと異なる画像を不良とするというアイデアです。直感的にも精巧な良品画像を生成できれば、効果的な不良品検知が期待できます*1。
ここではGANを画像の異常検知に適用した手法としてBiGANを紹介しますが、その前に関連する先行手法であるAnoGAN(Anomaly GAN)について簡単に触れます。AnoGANは通常のGANをそのまま異常検知に適用した手法であり、モデルはGeneratorとDiscriminatorからなります。不良品検知の際には、対象画像に対して対応する潜在表現ベクトルを計算し、これをGeneratorの入力とすることで画像の再構成を行います。
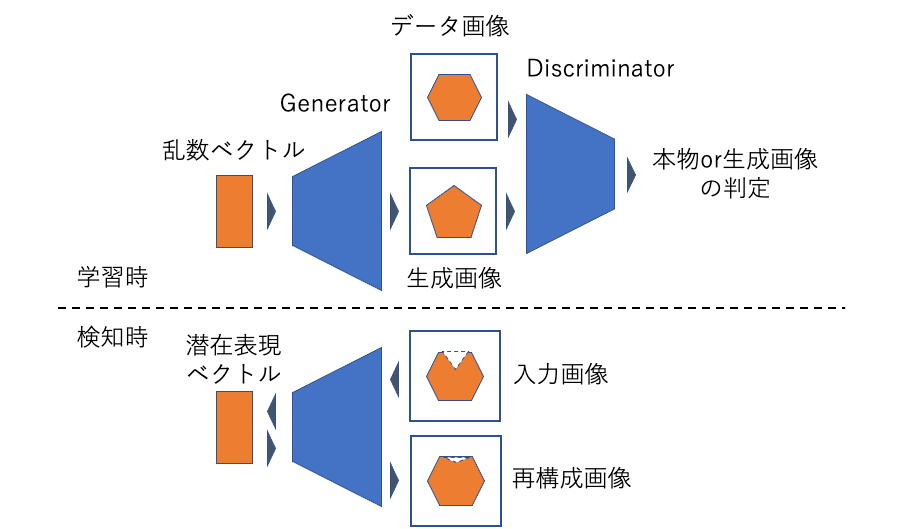
ここで問題となるのは、潜在表現ベクトルの計算部分です。AnoGANにおいてはまず潜在表現ベクトルを適当に初期化し、そこから生成される画像と対象画像が近くなるように、誤差逆伝搬法によって潜在表現ベクトルを更新していきます。しかし勾配法による更新は多くの計算時間を要するため、たくさんの画像に対して検知を行うのが難しくなってしまいます。
AnoGANにおいて潜在表現ベクトルの計算に時間がかかってしまうという問題に対して、BiGANは(GeneratorとDiscriminatorに加えて)Encoderを用意することを提案しました*2。Encoderは画像を入力として、対応する潜在表現ベクトルを直接計算します。検知の際には、対象画像をEncoderに入力して対応するベクトルを計算し、これをGeneratorの入力とすることで画像の再構成を行います。誤差逆伝播を用いないためAnoGANよりも高速な処理が可能になります。
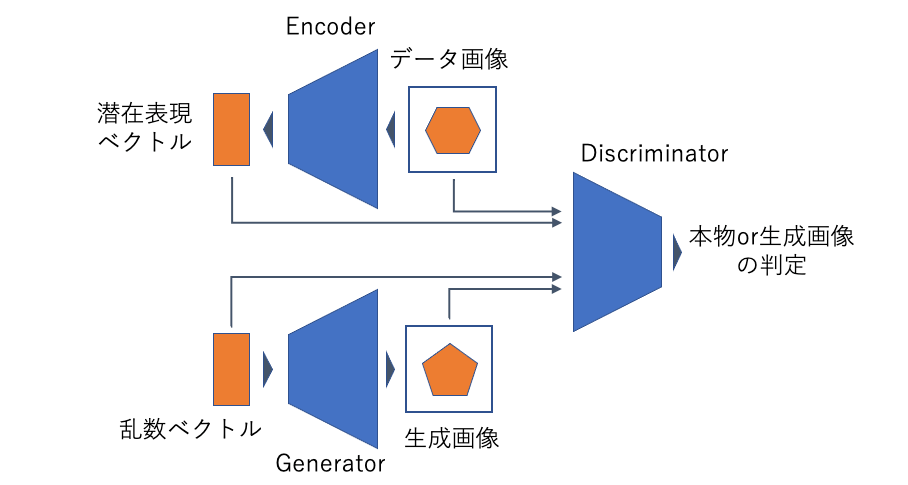
GeneratorとEncoderによって画像と潜在表現ベクトルの変換が行われます。これがBidirectional(双方向)という名前の由来です。またBiGANとCAEの構造を比べると、CAEにおけるDecoderがBiGANにおけるGeneratorに対応していることがわかります。このことからも、CAEとBiGANは近いモチベーションの手法であることがわかります。加えてGANに起因する精巧な画像生成を学習することができれば、CAEよりも効果的な不良品検知が期待できます。
画像生成における通常のGANは、データとして用意した画像とGeneratorが生成した画像をDiscriminatorに入力し、画像が本物か生成したものかを識別する形で学習します。対してBiGANでは、画像だけでなく潜在表現ベクトルも合わせてDiscriminatorの入力とします。GeneratorとEncoderは、Discriminatorが識別を間違えるように学習し、結果として画像生成と潜在表現ベクトルの計算の両方が可能になります。
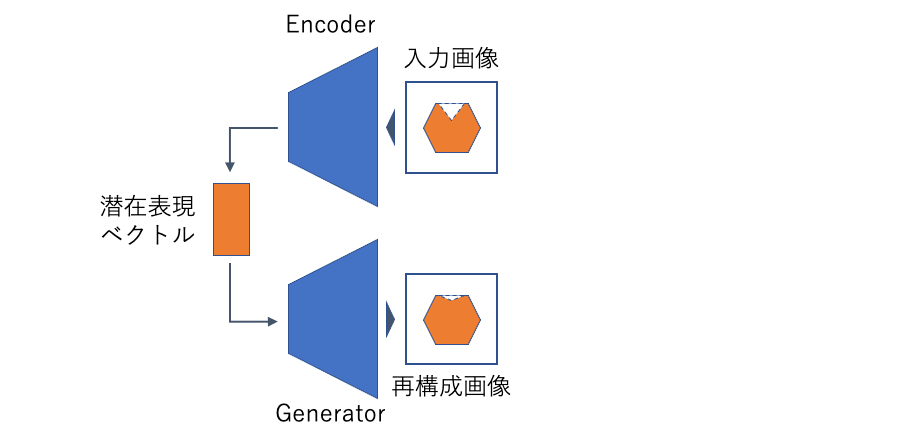
BiGANによる不良品検知は、CAEと同様に再構成誤差に基づいて行うことができます。加えて、論文では再構成誤差とDiscriminatorを組み合わせた異常(不良品)スコアの計算方法も提案しています。
以下の設定でBiGANの実験を行いました。
BiGANは通常のGANと同様に、乱数ベクトルをGeneratorの入力とした画像生成が可能です。CAEと同様にMVTecAD内のヘーゼルナッツカテゴリの画像で学習した結果、以下のような生成ができました。大まかにはヘーゼルナッツの色や形状を捉えられていそうです。

BiGANによる検知結果は以下のようになりました。結果として、今回の実験では不良品検知において期待される品質の入力画像の再構成はできませんでした。またCAEと同様に入力画像の解像度を128×128とした場合にも、不良品検知に利用できるほどの再構成はできませんでした。

CAEとGANの異なる点として、CAEは学習時に再構成誤差を直接最小化しますが、GANはDiscriminatorの出力に基づいて各ネットワークを学習します。この学習方法は一般的に不安定であるとされており、結果的に今回の実験設定では十分な品質の画像再構成ができなかったのではないかと考えています。
一方で学習の安定化や生成画像の品質・解像度向上を目標とした研究も多く提案されています。今回はBiGANとして比較的シンプルなネットワークと学習方法で検証しましたが、実際にはこれらの手法を組み合わせて検討すべきでしょう。
また、BiGANはCAEと同様に画像の再構成によって不良品検知を行うため、背景のノイズや再構成誤差の集約方法についても注意する必要があります。
今回は良品画像のみで学習を行う深層学習モデルの中でも基本的な手法として、CAEとBiGANを紹介しました。これらの手法は不良品画像を使わずに学習できるというメリットと、深層学習ベースの高度な特徴抽出が期待できるというメリットがあります。CAEとBiGANの違いをまとめると以下のようになります。
| 手法 | メリット | デメリット |
|---|---|---|
| CAE | 安定して学習でき、ベースラインとして扱いやすい | ぼやけたような再構成画像になる |
| BiGAN | 精巧な画像生成が期待できる | 学習が不安定であり、うまく入力画像の再構成ができない場合がある |
デメリットに関しては様々な改善手法が提案されており、今年のインターンでもテーマの一部として調査してもらいました。よければそちらもご確認ください。
注意しなければならない点として、最終的に入力画像が不良か否かを決定する際には閾値を設ける必要があり、閾値設定のためにはいくつかの不良品画像を用意する必要があります。つまり、CAEやBiGANの学習自体には不良品画像は不要ですが、全体として不良品か否かを決定する工程を構築する上では不良品画像が必要になる、ということになります。とは言え深層学習モデルの構築・学習よりも閾値設定の方がシンプルで扱いやすい問題であることを踏まえれば、今回紹介した手法は十分検討に値すると言えます。次回以降はさらに発展した不良品検知の手法を紹介します。
ブレインパッドでは、新卒採用・中途採用ともに新しい仲間を積極的に採用しています!
AIによる不良品検知をはじめ、データサイエンスを仕事にしてみたい皆さま、ブレインパッドにご興味のある皆さま、ぜひご応募をお待ちしています!
https://www.brainpad.co.jp/recruit/
*1:2020年現在ではGAN以外にも優れた画像生成を可能とする手法が提案されています。これらの手法を取り入れることで不良品検知の性能向上も期待できるかもしれません。
*2:BiGAN自体は異常検知に限らず潜在表現ベクトルを計算するために提案された手法であり、その後異常検知への適用も提案されました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













