



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

不良品検知の手法に関するナレッジをさらに高めるため、工業製品に対する不良品検知に関して、様々な手法を性能検証する連載です! 今回はその第3回です。
こんにちは。AIソリューションサービス部の栗原です。本記事は、画像に対する異常検知に関する連載ブログの第3回です。
今回はDifferNet*1という手法を紹介します。DifferNetの特徴の一つとして、少数の画像で高精度な異常検知モデルが構築できるという点があります。データ収集やラベリングは非常に工数がかかるタスクですので、実際のプロジェクトにおいてメリットが大きいのではと思い、今回取り上げました。
本記事では、プロジェクトにおける有用性と簡単な論文紹介をしていきます。
まずはじめに、不良品検知プロジェクトを進めるにあたって、この手法の嬉しいポイントを考察してみます。
主に3点あると考えます。ここでは概要のみ記載し、それぞれの詳細は手法紹介・検証結果の後に述べたいと思います。
1. 学習データを数千枚~数万枚と大量に用意しなくてすむ
冒頭でも述べた通り、データ収集、ラベリングは工数がかかります。
本手法は16枚という少ない学習枚数でも高精度を達成できると述べられていて、データセットを準備する負担を少しでも減らせる手法として提案できると考えています。
2. ロバスト性を意識したアーキテクチャである
これまでの連載でも触れましたが、不良品はサイズや種類などが多様である場合が多いです。
本手法は、そのような多様性に対応できるよう、ロバスト性を確保できるような工夫がされています。
3. 不良領域の視覚化が可能
ある画像に対して、「機械学習がなぜ不良と判定したのか」を知りたいというお客様は少なくありません。本手法は「良品か不良品かを判定するために重要なピクセル」を視覚化することが可能です。
手法の詳細に入る前に、既存手法との比較をしていきます。
論文中では、異常検知の手法を下記の通り二分しています。
※連載②のブログ*2で紹介した距離学習などは下記のどちらにも当てはまらないので、あくまでも論文中での分類になります。
それぞれ簡単に見ていきましょう。
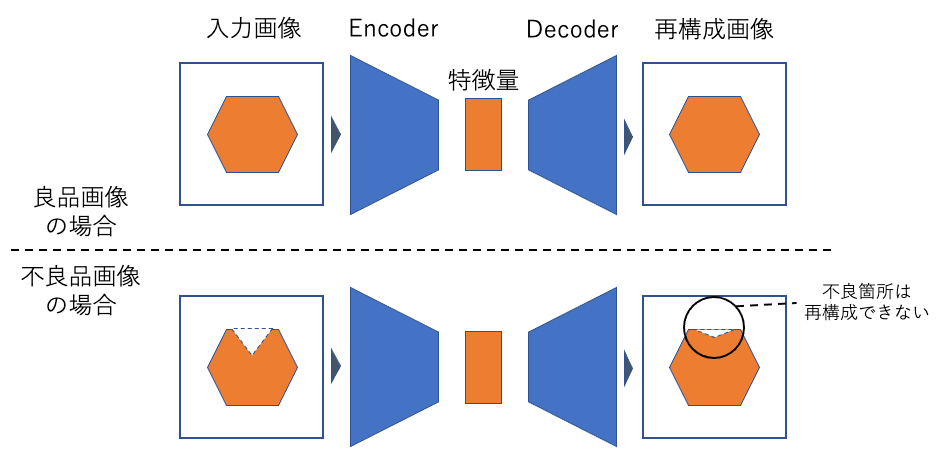
こちらのアプローチは、連載1回目のブログで紹介したAutoEncoderやGANが該当します。
まず、良品画像を生成するモデルを構築します。このモデルに対して不良品画像を入力すると、モデルは入力画像をうまく生成できない、という考えに基づいて異常検知を行います。
※連載①のブログ*3の図再掲
ある特定の問題を解いて得た知識を、別の問題を解くために活用するイメージです。
多くの手法は、事前学習済みネットワークを特徴抽出器として用いて、得られた特徴量を活用して異常検知を行います。
上記の既存手法に対して、それぞれ問題点が述べられています。
DifferNetが、その問題点に対してどのようにアプローチするか簡単に紹介します。
生成モデルに基づく手法の問題点
対象画像の特徴が複雑である場合、良品画像をうまく学習できず、再構成誤差が大きくなりがちです。その結果、不良があった場合の再構成誤差全体への影響が小さいため、良品/不良品の境界があいまいになり、良い精度で検知できません。
また、高次元かつ多様な良品画像の特徴を学習するためには、大量の学習データが必要となります。
事前学習済みネットワークに基づく手法の問題点
事前学習済みネットワークの従来研究では、ネットワークから抽出された特徴量をそのまま活用するような手法が多く、十分なロバスト性を持っていないと述べられています。
また、不良箇所を視覚化するためには、多数の重なり合うパッチに対して処理を実施する手法が提案されていますが、非常にコストがかかります。*4
少量のデータでロバスト性を確保した異常検知をするために、DifferNetが採用したアプローチは以下です。
① ロバスト性を確保するために、学習と評価時に画像に対して複数の変換をかけたり、特徴抽出した後に、ニューラルネットワークを用いて特徴空間の分布を変換したりするなどの工夫をしている
② 事前学習済みの特徴量抽出器から得た、比較的低次元な特徴量を用いて密度推定量を計算し、異常スコアとして活用する
さらに、不良箇所を効率よく視覚化するアプローチとして、異常スコアに対して各ピクセルがどの程度影響するかを示す値が提案されています。
DifferNet のコアアイデアを図示したものが図2です。
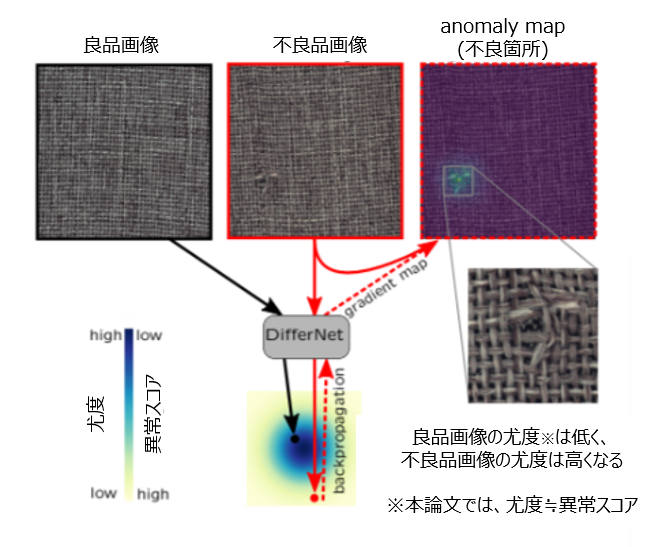
DifferNet は、良品画像の特徴量の密度推定に基づく手法で、学習時は良品画像のみを使用します。本手法の特徴的な部分として、異常スコアとして尤度(ゆうど)を活用している点があります。尤度とは、サンプリングされたデータが、仮定している確率分布から生成される尤もらしさを表す度合です。特徴量抽出器によって得られた良品画像の特徴空間を、正規分布を仮定した潜在空間に写像できるようにNF(Normalizing Flow; 正規化フロー)を学習させます。詳細は後ほど説明しますが、結果として、良品画像は潜在空間中の正規分布の中心付近に写像され、仮定した正規分布に対して尤度が高くなります。一方で、不良品画像が入力された場合は、正規分布の裾野に写像されるようになっており、尤度が低くなります。
図2の通り、今回の手法においては尤度≒異常スコアです。例えば図2中では、左上の良品画像とは対照的に、上部中央の不良品画像は高い異常スコアが割り当てらます。
さらに、DifferNetは勾配マップ(図2右上の画像)を得ることが可能です。入力まで尤度損失をバックプロパゲーションすることにより、不良領域を視覚化します。勾配マップが得られると、不良位置と形状の詳細な分析が可能になります。
学習のパイプラインを図示したものが図3です。
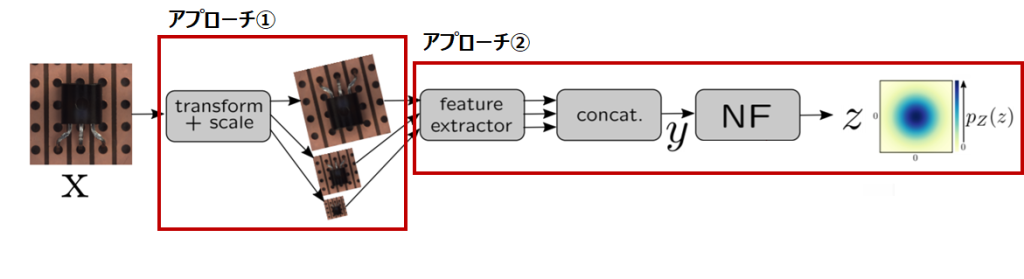
ここで、DifferNet が採用したアプローチを再掲します。
① ロバスト性を確保するために、学習と評価時に画像に対して複数の変換をかけたり、特徴抽出した後に、ニューラルネットワークを用いて特徴空間の分布を変換したりするなどの工夫をしている
② 事前学習済みの特徴量抽出器から得た、比較的低次元な特徴量を用いて密度推定量を計算し、異常スコアとして活用する
以降、各アプローチに関するコンポーネントを順に見ていきましょう。
図3の前半にある、入力画像に対して複数の変換を行っている部分がそれにあたります。異なる3つのスケールの画像を特徴量抽出器に入力し、得られた各特徴を連結したものを画像の特徴量として定義しています。これは、ロバストな異常スコアを確保するためのアプローチとして採用されています。
次に、アプローチ②に関連するコンポーネントです。図3の中央にfeature extractor(特徴量抽出器)があり、ここで特徴量の抽出を行い次元が圧縮されています。圧縮された特徴量をNF(Normalizing Flow; 正規化フロー)へ入力し、正規分布を仮定した潜在空間へデータを写像しています。最終的には、正規分布に埋め込めるようなNFを学習します。特徴抽出器のパラメータは更新しません。論文中では、「学習中の目標は、潜在空間で抽出された特徴量の尤度を最大化する正規化フローのパラメータを見つけること」と記載されています。
NFは、非線形変換を繰り返し実施することによって、ある分布から求めたい分布に写像する機能をもつニューラルネットワークのことです。NF以外にも、特徴空間から潜在空間に写像する手法として、ニューラルネットワークと変分法を活用するアプローチ(例:VAEのEncoderなど)があります。しかし、変分法の活用には、変換前後の分布間の距離が正確に測れない、変換後の分布を十分な表現力を持って近似できないなどの課題が指摘されていました。それらを解決するためにNFが提案されており*5、今回の論文でも、より厳密な潜在空間への写像を狙ってNFが採用されているようです。
ここまでが学習のパイプラインです。
続いて、上記で学習したモデルを活用する方法を見ていきます。
まずは、異常スコアの算出です。
画像が入力されると、尤度が計算されます。この尤度を良品 or 不良品に分類するための基準とします。 ロバストな異常スコアを得るために、入力画像に対して複数の変換をかけ、負の対数尤度を平均化したものを異常スコアとします。複数の変換とは、回転や明るさ、コントラストの操作が含まれます。異常スコアが計算されたあとは、異常スコアが閾値以上であれば不良品、閾値以下なら良品と判断します。
次に、視覚化(論文中ではローカリゼーション)についてです。
DifferNetは、異常領域を特定することが可能です。各入力チャンネル(論文ではカラー画像のためRGBの3チャンネル)ごとに、負の対数尤度をバックプロパゲーションすることにより勾配マップを得ています。勾配マップの考え方は、「特徴量を変化させることで出力に大きな影響が出るものがある場合、それは重要な特徴量と考えることができる」というものです。ネットワークがどの入力に対して敏感なのか、という変化量を調べることで勾配マップ≒不良領域を得ているのです。
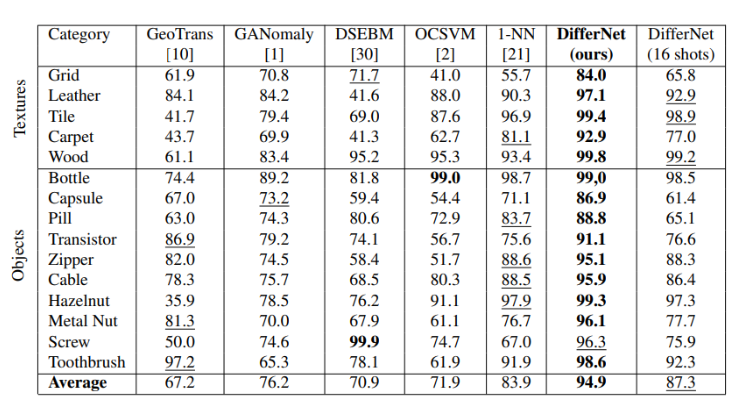
MVTec ADデータセットを用いた検証結果が表1です。AUROCで評価しています。最良の結果は太字で、2番目に精度が高い結果は下線を引いています。他のアプローチと比べて、DifferNetの精度が高いことがわかります。また、表1の一番右の列は学習に用いた画像の枚数を16枚にした場合の精度です。カテゴリにもよりますが、学習枚数を減らしても高い精度を達成しているものもあることがわかります。
公式の実装*6をもとに検証しました。
勾配マップを見てみると、大まかに不良領域を特定できていることがわかります。

冒頭で概要のみ述べましたが、不良品検知プロジェクトを進める際のこの手法の嬉しいポイント3点をまとめます。
1. 学習データを数千枚~数万枚と大量に用意しなくて済む
具体的に何枚のデータが必要かは解く問題によるので一概には言えませんが、少なくとも今回のMVTec ADデータセットでは16枚でAUROCが90%を超えるカテゴリもありました。また、今回の手法では、良品画像さえあれば学習が可能なのも嬉しいポイントです。(ただし、評価用に不良品画像も必要)
ここで、学習データ量と精度の関連について補足をします。学習データを増やし続けても、いずれ精度は頭打ちしますが、一定量まではデータ数が多いほど精度は向上していく傾向があります。しかし、実際のプロジェクトでは、クイックに検証を実施したい、大量にデータを準備するほどの工数が確保できない、などの理由により、なるべく少ないデータ量で高い精度が出るに越したことはありません。
DifferNetは、データセットを準備する負担を少しでも減らせる手法として提案できると考えています。
2. ロバスト性を意識したアーキテクチャである
これまでの連載でも触れましたが、不良品はサイズや種類などが多様である場合が多いです。また、同じ種類の不良でも画像の特徴は大きく異なるようなケースもあります。
今回の手法では、学習や異常スコア算出に画像を複数変換させる処理を入れることにより、ロバスト性を確保しています。
実課題における不良品の多様性にどれだけ耐えられるか、期待が高まるポイントだと感じました。
3. 不良領域の視覚化が可能
ある画像に対して、「機械学習がなぜ不良と判定したのか」を知りたいというお客様は少なくありません。今回の手法は「良品か不良品かを判定するために重要なピクセル」を視覚化することが可能です。
プロジェクトを進めていく上で、お客様の納得感は重要であると考えます。どれだけ精度が高くても、理由を説明することが難しいと意思決定しづらい場面もあるかと思います。そういった観点でも、この手法は実際のプロジェクトにおいて検討する価値があると考えます。
DifferNetは、上記で述べた通り、プロジェクトにおける有用性は高いと考えられます。
過去の不良品検知プロジェクトでも、既存手法として紹介した生成モデルに基づく手法を検討した例があります。生成モデルを採用したプロジェクトでは、画像の特徴が複雑でうまく学習ができなかったり、十分な良品画像枚数が準備できず精度がでなかったりしたこともありました。本手法は、このように過去にあった問題をクリアできるのではないかと期待しています。
とは言いつつ、どの手法にも言えることですが、機械学習はデータセットに大きく依存するため一概にこの手法がベストとは限りません。
今後も様々な手法を調査し、お客様に対して最良の価値提供ができるよう、研鑽に励んでいきたいと思います。
ブレインパッドでは、新卒採用・中途採用ともに新しい仲間を積極的に採用しています! AIによる不良品検知をはじめ、データサイエンスを仕事にしてみたい皆さま、ブレインパッドにご興味のある皆さま、ぜひご応募をお待ちしています!
https://www.brainpad.co.jp/recruit/
*1:https://arxiv.org/pdf/2008.12577.pdf
*2:https://blog.brainpad.co.jp/entry/2020/12/24/123000
*3:https://blog.brainpad.co.jp/entry/2020/12/11/110000
*4:https://arxiv.org/abs/1811.08495
*5:https://arxiv.org/pdf/1505.05770.pdf
*6:https://github.com/marco-rudolph/differnet
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













