



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社自社開発プロダクト「Rtoaster」のAI機能「conomi-optimize」にも考え方を利用したアルゴリズムが使われている、多腕バンディッド問題。今回のブログでは、多腕バンディッド問題の内容と基本的な解法についてご紹介します!
こんにちは、アナリティクスサービス部の小野川です。
今回は多腕バンディット問題と呼ばれる問題の内容とその基本的な解法についてご紹介したいと思います。
多腕バンディット問題とは強化学習に含まれるもので、複数の選択肢のなかからよりよい選択肢、つまりより報酬を得られやすい選択肢を選ぶという問題です。
ビジネス現場でもWeb広告最適化やレコメンドなどで活用しうるもので、活用範囲は幅広くあります。(実は弊社の製品であるRtoasterでもこの問題の考え方を利用したアルゴリズムが使われています。)
この問題を考える際、スロットマシンを使った例がよく挙げられます。
例えば無料で引くことができる100台のスロットマシンがあり、1回引くことによってある確率で金貨をもらえるとしましょう。
この100台のスロットマシンについて、それぞれに金貨をもらえる確率が設定されており、プレイヤー1人だけがそれらのスロットマシンを引けることを想定します。
この場合、スロットマシンを引くプレイヤーが一定回数の中でいかにして多くの金貨を得るか?という問題が多腕バンディット問題の内容です。
単純に考えれば100台の中で最も金貨を獲得できる確率が高いスロットマシンを引き続ければ良いのですが、スロットマシンの確率をプレイヤーが事前に知ることができないとなるとやや話が難しくなってきます。確率の高いスロットマシンを探るためにはスロットマシンを満遍なく引く必要があるため確率の低いスロットマシンも必然的に引かなければなりません。しかし、必要以上に確率の低いスロットマシンを引いてしまうと確率の高いスロットマシンを引く回数が減ってしまい、金貨の獲得期待値が下がることになります。
つまり、確率の高いスロットを「探索」すると同時に、探索結果を「利用」して確率が最も高そうなスロットマシンも適度に引くことが金貨の獲得期待値を上げるうえで重要となります。このような探索と利用のトレードオフの関係を上手に保つために様々なアルゴリズムが存在します。これらのアルゴリズムの中から基本的なものを確認しながら、それぞれのアルゴリズムの考え方、利点を見ていきましょう。
ちなみに多腕バンディット問題には主に、割引定式化・確率定式化・敵対的定式化の3つの定式化がありますが、今回はこのうち確率定式化について触れていきます。
ランダムアルゴリズムは、その通りK台のスロットマシンから引くスロットをランダムに選んでいく手法です。シンプルな方法ですが、当然効率的ではありません。
ランダムに引いていくことは探索活動としてはスロット確率の情報を得られるためよいのですが、問題はその情報を利用することなく延々と探索活動を行ってしまうことにあります。
そこで、うまい具合に利用行動を行うためのアルゴリズムが提案されます。
ε-greedyアルゴリズムは、先ほどの「探索」の行動と「利用」の行動をどの程度の割合で行うかを決めてしまうことで探索と利用の行動をバランスよく行うことを目指したものです。
探索行動を行う確率をεとすることからε-greedyアルゴリズムと呼ばれます。
例えば探索行動を50%、利用行動を50%の確率で行うとしましょう。(ε = 0.5)
この場合、スロットを引く前にどちらの行動を行うかを選択し、探索行動が選択された場合にはランダムに、利用行動が選択された場合にはそれまでに引いたスロットの中で観測上最も確率高く金貨を得られたスロットを選択することになります。
これで探索結果を利用するアルゴリズムとなったわけですが、もう少し改良できそうです。というのも探索状況が変化していくと探索と利用を行うべき割合が変化していくためです。
例えば、各スロットを1回も引いていない状況では利用すべき情報がないためにとりあえず探索行動を優先して確率の高そうなスロットを見つける必要があるでしょうし、各スロットを100回ずつ引いていたとすればある程度スロットの情報が得られているのでその情報を利用することに重きを置いた方が良いでしょう。
そこでスロットを引いていく度にεを減衰させていくことで、状況に応じた探索と利用のバランスの取り方を実現できます。このような手法を焼きなまし法といい、これをε-greedyアルゴリズムに適用するとより効率的に金貨を得ることができます。
ε-greedyアルゴリズムでは探索行動の際にランダムに探索を行っていました。もしこの探索行動でもなるべく確率の高いスロットを中心に探索を行えれば、探索行動中にも金貨を獲得する期待値がぐっと上がるでしょう。
そこで、探索行動中にも過去の探索で得た情報を利用して確率の高そうなスロットを中心に探索することがソフトマックスアルゴリズムの目指すところとなります。
ここから先はやや複雑になりますので、数式を交えて見ていきましょう。
\(K\)個のスロットがあり、それぞれのスロットに\(x_k(k=1,2,3…K)\)と名付けます。
さらに、この\(K\)個のスロットをある程度引いた時にあるスロット\(x_k\)の期待報酬(この場合は金貨を獲得した割合)を\(\hat{\mu_{k}}\)と置きましょう。ここで、ソフトマックスアルゴリズムは次に引くべきスロットの確率を返します。例えばあるスロットを引くべき確率が80%であれば、アルゴリズムは80%の確率でそのスロットを引くといったような具合です。
その確率は以下のように表されます。
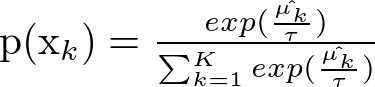
一度τ=1としてこの数式の意味合いを見ていきましょう。
この場合、数式は以下の通りになります。

各スロットの\(exp(\hat{\mu_k})\)に応じてスロットを引く確率を設定することで、\(\hat{\mu_k}\)が大きいスロットを優先的に引くような形となっています。ここで各スロットを引く確率の和が1、つまり\(\sum_{k=1}^{n} p(x_k) = 1\)を満たすようにソフトマックス関数が使われています。このように、うまくそれまでに引いた各スロットの情報を用いて確率を設定していることがわかります。
先ほど無視したτに戻ってみましょう。これは温度パラメータと呼ばれるもので、これによって”どの程度過去の確率を重視するか?”を設定することができます。
ここで、ある2台のスロットを例として考えましょう。
これまでこの2台のスロットをそれぞれ数百回引いて、\(\hat{\mu_1} = 0.2, \hat{\mu_2} = 0.7\)を得たとしましょう。
このとき、τ=1とすると
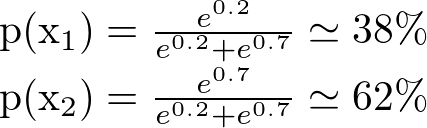
となります。これまでに金貨を得た確率が高いスロット2を優先的に引くようになっていることがわかります。
ここで、τ=0.1と小さくしてみたらどうなるでしょうか?
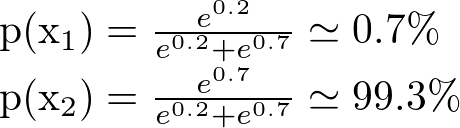
このように、スロット2を引く確率がほぼ100%となりました。このようにτを調整することによってそれまでにスロットから得られた確率の大小をどの程度評価するかを決めることが出来ます。
このτは先ほどε-greedyアルゴリズムで少し出てきた焼きなまし法に使えます。つまり、最初はτの値を大きくしておき、それぞれのスロットから得られた確率をあまり重視せずに探索に重きを置いて行動を促し、ある程度スロットを引いたらτの値を小さくしていき、確率が高いスロットを中心に引いていくということができます。
UCBアルゴリズムは、信頼区間というものに着目した手法となります。
この信頼区間は、それまでに各スロットを引いた結果得られた確率から”真の確率はおおよそこの範囲に収まりそう”という範囲を表します。
例えば、あるスロットを5回引いて3回金貨を得られた場合と、5000回引いて3000回金貨を得られた場合を考えてみましょう。どちらも同じ60%の割合で金貨を得られたことになりますが、その意味合いは少し異なります。後者のスロットは、金貨が得られる真の確率(スロットに設定されている確率)がなんとなく60%に近そうな気がします。しかし、前者はたまたま現段階で60%という割合に落ち着いているだけで、真の確率はもっと違う値になっていてもおかしくありません。
このようにスロットを引く回数が少ないほど、スロットを引いて得られた割合と真の確率の差異が大きい可能性があります。そこで、各スロットについてこの信頼区間を算出し、その信頼区間の上側の値が一番高いスロットを引くことで一番ポテンシャルが高い可能性があるスロットを引くことができます。
ここで各スロットを合計して\(t\)回引いた時点(以下、時点\(t\)において、スロット \(x_k(k=1,2,3…K)\)を引いた回数を\(N_k(t)\)と置き、その時点でスロット\(x_k\)が金貨を獲得した割合を\(\hat{\mu}_k(t)\)と置くと、この信頼区間の上側の値(UCBスコア)は以下のようにして求められます。
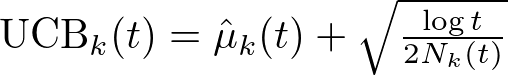
\(\hat{\mu}_k(t)\)に加えられた項によって、\(N_k(t)\)が小さいスロット、つまりそれまで探索がされていないスロットのUCBスコアが上がります。これにより、スロットによる金貨獲得期待値が高いもしくはまだポテンシャルを秘めていそうなスロットを重点的に利用/探索することができます。
\(N_k(t)\)の値が0、つまり一度も引かれていないスロットのUCBスコアは計算不能となってしまいますが、一度も引かれていないスロットがあれば、他のスロットのUCBスコアに関わらずそれを優先して引きます。
最後に、トンプソン抽出というアルゴリズムを見ていきましょう。
これはそれまでに各スロットで観測された情報と、事前にスロットにあてはめる事前分布から、金貨を得る期待値の事後分布を予測し、その分布によって生成される乱数が最も高いスロットを時点ごとに選択するといったものになります。
今回のスロットは、スロットを引くたびに金貨を得るか得られないかの2択であるため、ベルヌーイ分布の確率分布によって表すことができます。
このような場合、事前分布をベータ分布として、各スロットが引かれるたびにその結果から事後分布を更新していくことで各スロットの時点\(t\)での事後分布を得ることができます。
ベータ分布は以下のように表されます。

UCBアルゴリズムの時同様、時点\(t\)におけるスロット\(x_k(k=1,2,3…K)\)を引いた回数を\(N_k(t)\)とし、金貨を得られた回数を\(M_k(t)\)、金貨を得られなかった回数を\(N_k(t)-M_k(t)\)としましょう。
この時、スロット\(:x_k\)の事後分布は以下のようになります。
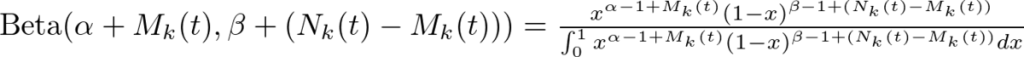
UCBアルゴリズムの時同様、時点\(t\)におけるスロット\(x_k(k=1,2,3…K)\)を引いた回数を\(N_k(t)\)とし、金貨を得られた回数を\(M_k(t)\)、金貨を得られなかった回数を\(N_k(t)-M_k(t)\) としましょう。
この時、スロット\(x_k\)の事後分布は以下のようになります。
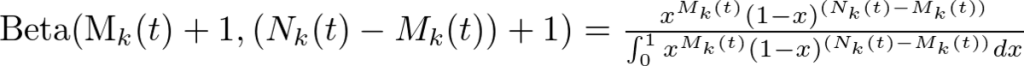
この分布から乱数\(x\)を生成し、その時点で乱数の値が高いスロットを引くということを繰り返していくことになります。
ここまで様々なアルゴリズムを見てきましたので、今度はそれを実行してみて各アルゴリズムがどのように金貨を効率良く得ていくかを見てみましょう。
スロットマシン100台がある環境を想定し、この環境に5つのアルゴリズムを適用させて実験を行ってみましょう。
実験の概要と利用するアルゴリズムは以下の通りです。
| アルゴリズム | 備考 |
|---|---|
| 期待値最大アルゴリズム | 毎時点で金貨獲得期待値が75%に設定されたスロットのみを引き続ける。 |
| 焼きなましε-greedyアルゴリズム | εの初期値を1として、時点が進むごとに0.99倍する。 |
| 焼きなましソフトマックスアルゴリズム | τの初期値を10000として、時点が進むごとに0.9倍する。 |
| UCBアルゴリズム | 特になし |
| トンプソン抽出 | 事前分布はBeta(1,1)����(1,1) |
横軸を時点、縦軸を累積報酬の平均値の比率として結果をグラフ化してみます。
期待値が最大のアルゴリズムに対して他のアルゴリズムがどれくらいの報酬を獲得しているかを比較しているため、値が1に近いほど理想的なアルゴリズムに近く性能が良いことを示します。
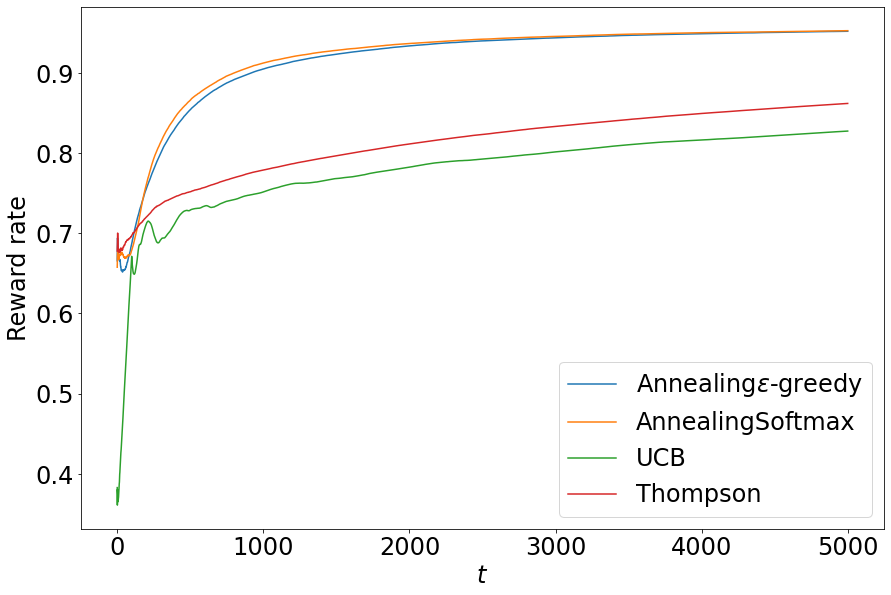
どうやら焼きなましε-greedyと焼きなましソフトマックスの2つが、今回の実験設定では多腕バンディットアルゴリズムの中で優れており、次いでトンプソン抽出、UCBという成績順となりました。
最終的な累積報酬の平均値は以下のとおりとなっています。
| アルゴリズム | 累積報酬の平均値 | 累積報酬の平均値の比率 |
|---|---|---|
| 期待値最大アルゴリズム | 3749.12 | 1 |
| 焼きなましε-greedyアルゴリズム | 3569.48 | 0.952 |
| 焼きなましソフトマックスアルゴリズム | 3572.23 | 0.953 |
| UCBアルゴリズム | 3102.64 | 0.828 |
| トンプソン抽出 | 3231.92 | 0.862 |
今回の実験設定では、焼きなましを採用した2つのアルゴリズムが上位アルゴリズムとなりました。多腕バンディット問題ではUCBアルゴリズムやトンプソン抽出が優秀なアルゴリズムとしてよく利用されるようですが、今回のように100個の選択肢があるような問題だと他の手法と比べて弱いところがあるのかもしれません。
特にUCBアルゴリズムは確率が低いスロットも引いていかなかればならないからか、時点t�が小さい値だと他の手法と比べて報酬の割合がかなり小さく、このあたりも手法選択の一つの要素となりそうです。
また、焼きなまし法を利用した2つの手法については最初のεやτの値をどのように置くかで結果が異なってしまうため、この設定をどのようにしてうまく行うかもよい結果を生み出すための鍵となります。
今回は多腕バンディット問題についてご紹介させていただきました。実際のビジネス現場でも活用しうるものであり、また実験もしやすい問題設定かと思いますので、様々な環境を設定して実験を行ってみるのも面白いのではないでしょうか。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













