



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

データ活用・DXに欠かせないのがデータ基盤です。ブレインパッドには、クラウドプラットフォームの知識・スキルを深化させるべく、Google Cloud 、AWS、Microsoft Azure、Snowflakeの4つのクラウドプラットフォームチームから成る「クロスファンクショナルチーム(CFT)」があります。今回は、より具体的に、データレイクの一つであるAmazonS3とSnowflake間の接続方法についてご紹介します!
顧客企業のデータ活用を、システム開発や基盤構築の面から支えている当社のデータエンジニアリング本部(DE本部)。そのDE本部には、 Google Cloud 、AWS、Azure、Snowflakeの4つのクラウドプラットフォームチームから成る「クロスファンクショナルチーム(CFT)」があります。今回はSnowflakeチームの活動紹介となります。(詳細は、https://blog.brainpad.co.jp/entry/2021/11/05/140000の記事を参照ください)
前回のブログで「データレイクとSnowflake間の接続方法(認証方法)」についてご紹介しました。今回はより具体的に、データレイクの一つであるAmazonS3とSnowflake間の接続方法についてご紹介します。(下図の赤線部分の話となります)
※前回の記事の詳細は、https://blog.brainpad.co.jp/entry/2022/03/03/110958を参照ください。

AmazonS3とSnowflake間の接続方法は、
①STORAGE INTEGRATION(ストレージ統合)を使用した接続方法
②AWSのIAMユーザーのAWS キー(AWSAccessKeyId)と秘密キー(AWSSecretKey)を使用した接続方法
の2種類ありますが、後述の1.1章で①の方法、1.2章で②の方法を説明します。基本的には①の方法を
使用して運用をしますが、まずは細かい設定をせずにS3のデータを取得して試してみたいという方は、
②の簡易な方法もご検討ください。
接続の設定は、AWSとSnowflakeの両方で行う必要があります。AWSでの設定とSnowflakeでの設定を、行ったり来たりしますが、下図に設定手順の番号を振りましたので、迷った時はこの図を参考にしてください。①~⑥までが接続の設定手順(①の設定は任意)、⑦⑧はデータの取得手順となります。
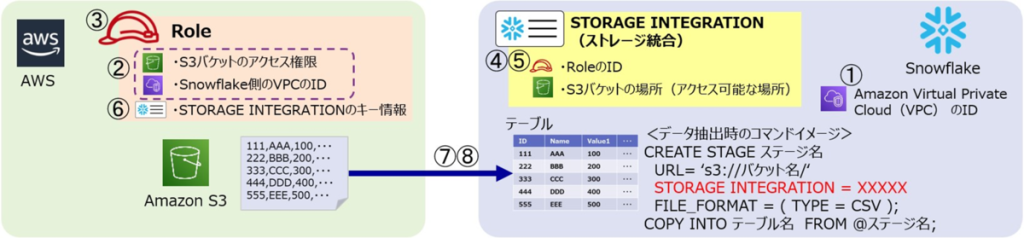
【設定手順】
① Snowflakeアカウントが存在する Amazon Virtual Private Cloud(VPC)のIDを取得します。
(※この①の手順は省略可能です。②のポリシーを作成する際に、Snowflakeが存在するVPCからのアクセスに限定するポリシーを作成する目的で使用します。VPCを指定することで、②のポリシーを使いまわして、他のSnowflakeアカウントからアクセスできないようにします。2022年3月時点で、この手順は公式ドキュメントからは省略されています。)
② AWSのコンソールから、ポリシーを作成します。
③ AWSのコンソールから、②のポリシーを紐づけたロールを作成します。
④ ③で作成したロールのIDを指定して、STORAGE INTEGRATION を作成します。
⑤ ④で作成したSTORAGE INTEGRATIONの詳細を確認し、STORAGE_AWS_IAM_USER_ARN、
STORAGE_AWS_EXTERNAL_IDの情報を取得します。
⑥ ③で作成したロールに対して⑤の内容を反映して更新します。
【データの取得手順】
⑦ STORAGE INTEGRATION を使用した外部ステージを作成します。
⑧ ⑦の外部ステージを使用してS3のデータを取得します。
(参考サイト)Snowflake公式ドキュメント
https://docs.snowflake.com/ja/user-guide/data-load-s3-config-storage-integration.html
前項の手順に沿って、実際に設定をします。
(手順①)
まず、Snowflakeのポータル画面から、Snowflakeアカウントが存在するAWSのVPCのIDを取得します。
「ACCOUNTADMIN」ロールにて、下記のSQLを実行して、vpc-から始まるVPCのIDを取得します。
※Snowflakeの「ACCOUNTADMIN」ロールの権限が必要になります。
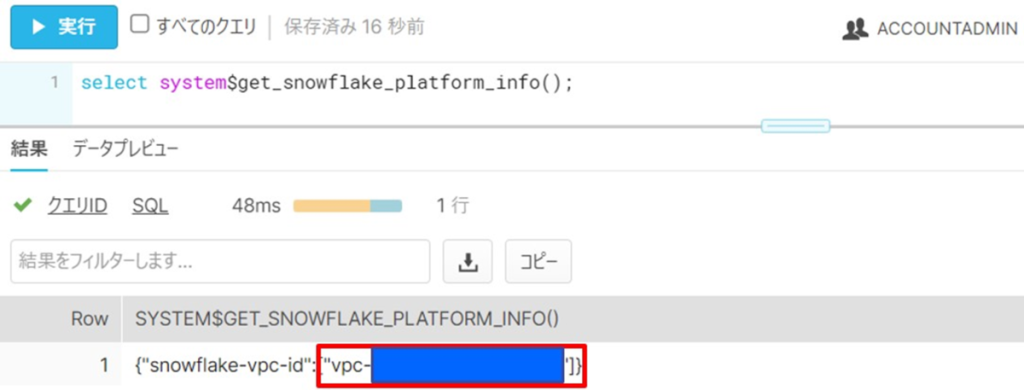
select system$get_snowflake_platform_info();(手順②)
AWSのコンソールから、ポリシーを作成します。(S3バケットへのアクセスと、手順①のVPCからのアクセスを許可するポリシーを作成)
ポリシーはJSON形式で記述します。下記の雛形を流用して、バケット名と手順①で取得したVPCのIDを置き換えたものを使用します。(VPCの指定は任意です)
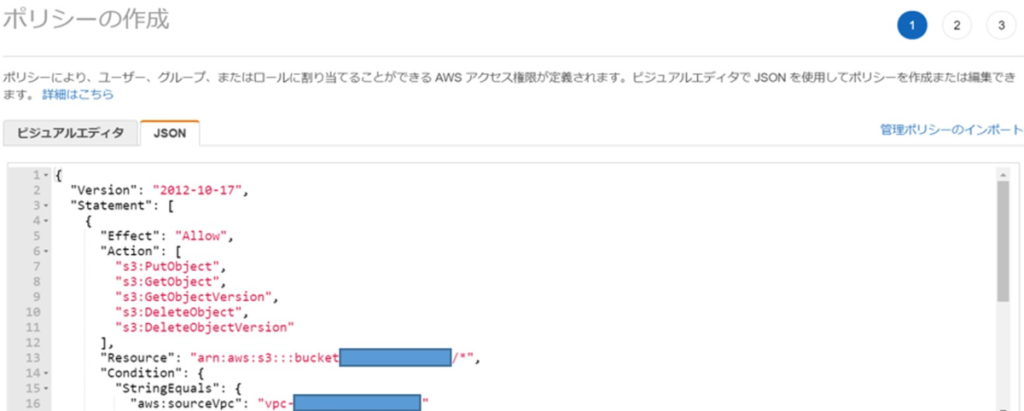
(ポリシーの記載例・雛形)
select system$get_snowflake_platform_info();
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::bucketXXXXX/XXXXX/*",
"Condition": {
"StringEquals": {
"aws:sourceVpc": "vpc-XXXXXXXXXXXXXXXXX"
}
}
},
{
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": "arn:aws:s3:::bucketXXXXX",
"Condition": {
"StringEquals": {
"aws:sourceVpc": "vpc-XXXXXXXXXXXXXXXXX"
}
}
}
]
}※PutObjectやDeleteObjectは、S3バケットを参照するだけであれば必要ないですが、今後、データをアンロード(SnowflakeからS3へ出力)するケースやPURGE コピーオプションを使用してデータファイルを削除するケースも想定して、付与しています。
(手順③)
AWSコンソールから、手順②で作成したポリシーを紐づけたロールを作成します。
下記のロールの作成画面にて、「AWSアカウント」を選択し、外部IDを仮の値で入力します。(手順⑥にて修正しますが、この時点では一先ず「このアカウント」を使用し、外部IDは「0000」を入力します)
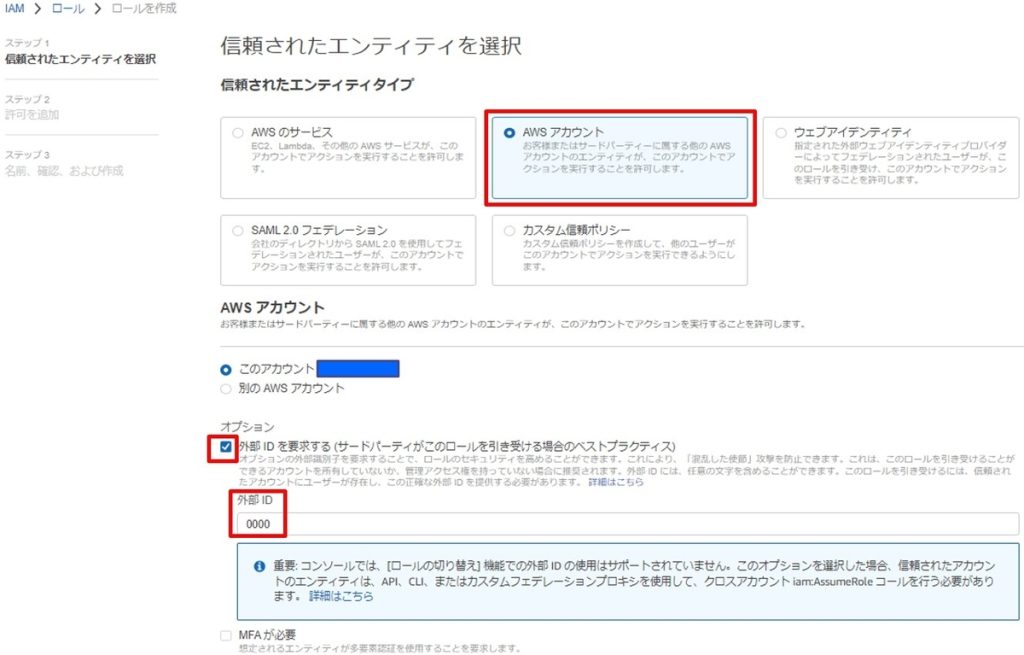
アクセス権限ポリシーの画面にて、手順②で作成したポリシーを選択して、チェックを入れます。
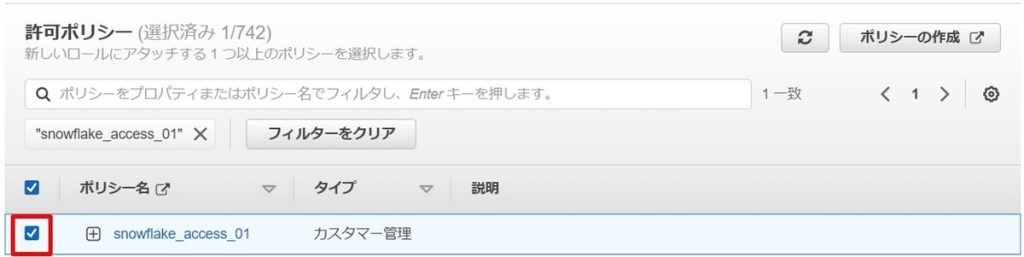
ロール名を入力して、「ロールの作成」ボタンを押して、ロールの作成が完了です。
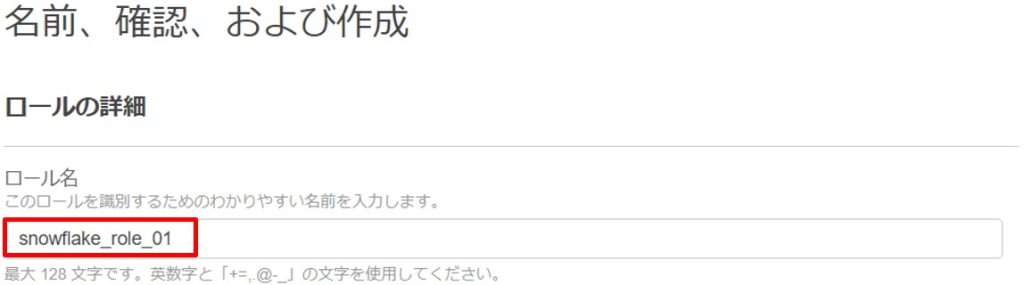
ロールを作成後、ロールのARNを確認しておきます。(手順④で使用します)

(手順④)
Snowflakeのポータル画面から、手順③で作成したロールのARNを指定して、STORAGE INTEGRATION を作成します。※Snowflakeの「ACCOUNTADMIN」ロールの権限が必要になります。
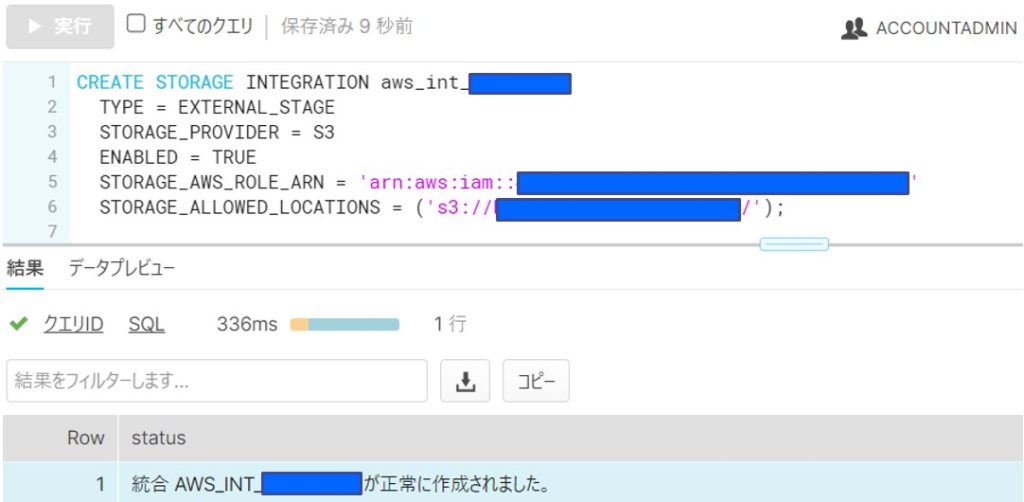
CREATE STORAGE INTEGRATION aws_int_XXXXX
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::XXXXXXXXXXXX:role/snowflake_role_XXXX'
STORAGE_ALLOWED_LOCATIONS = ('s3://bucketXXXXXXX/');(手順⑤)
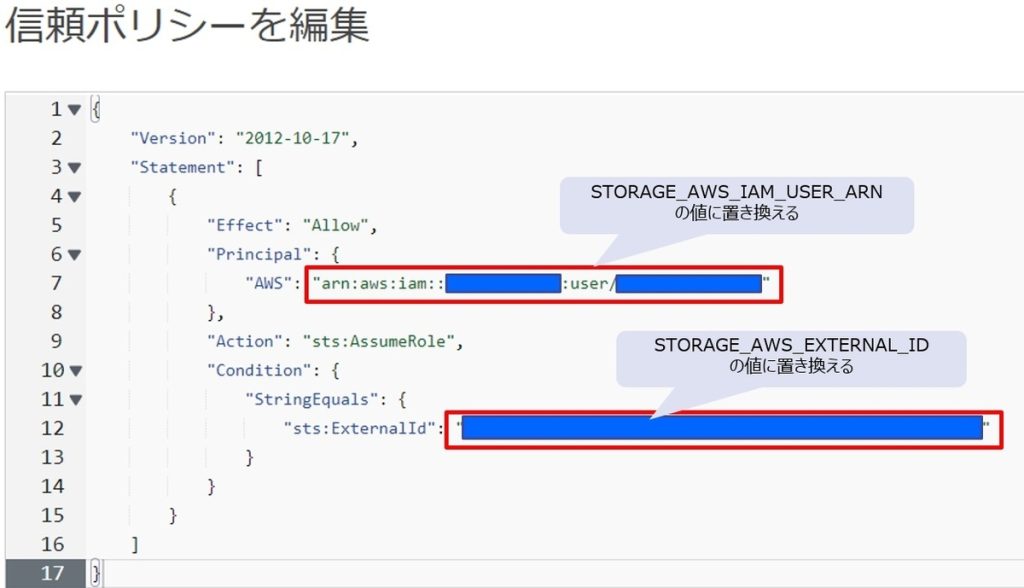
手順④で作成したSTORAGE INTEGRATIONの詳細を確認し、STORAGE_AWS_IAM_USER_ARN、STORAGE_AWS_EXTERNAL_IDの情報を取得します。
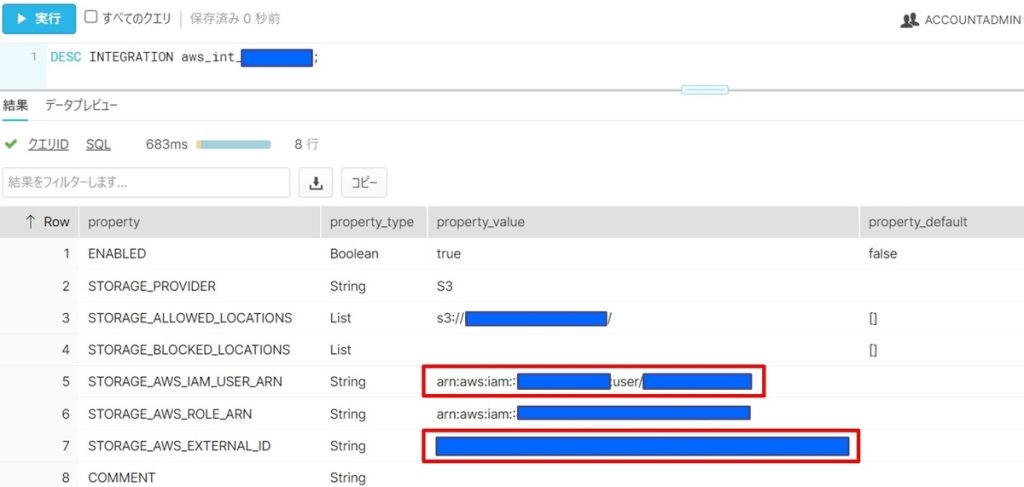
DESC INTEGRATION aws_int_XXXXX;(手順⑥)
AWSのコンソール画面から、手順③で作成したロールに対して、手順⑤で取得した情報で更新します。
ロールを選択して、信頼ポリシーを編集します。
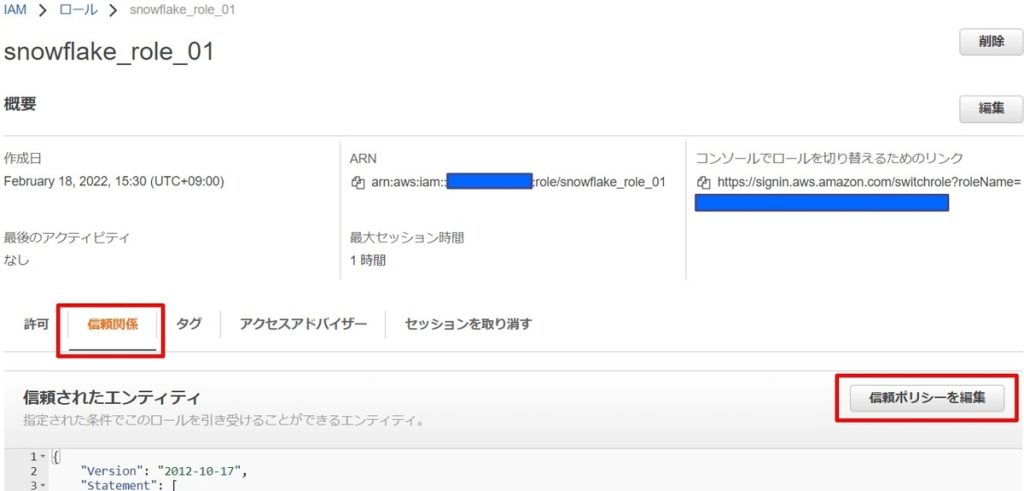
手順⑤で確認した「STORAGE_AWS_IAM_USER_ARN」「STORAGE_AWS_EXTERNAL_ID」の値で書き換え、信頼関係の情報を更新します。
これで、AmazonS3とSnowflakeの接続の設定は完了です。
接続の設定が完了したので、実際にS3からデータを取得してみます。以下のシナリオで確認をします。
(検証シナリオ)
「test_member_01」テーブルに2件のデータが登録されており、S3にあるファイルを取り込んで、テーブルのデータが4件に増えることを確認します。
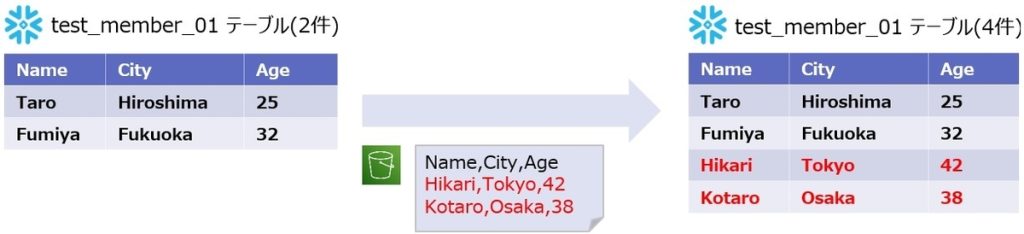
※他のDWH製品と同様にSnowflakeにおいても、外部テーブルを作成しデータをSnowflake側に持たず、ストレージのデータを参照する方法も可能ですが、今回のシナリオではSnowflake側にもデータを持ってくる方法で検証をしました。
【データの取得手順】
(手順⑦)
Snowflakeのポータル画面から、STORAGE INTEGRATION を使用した外部ステージを作成します。
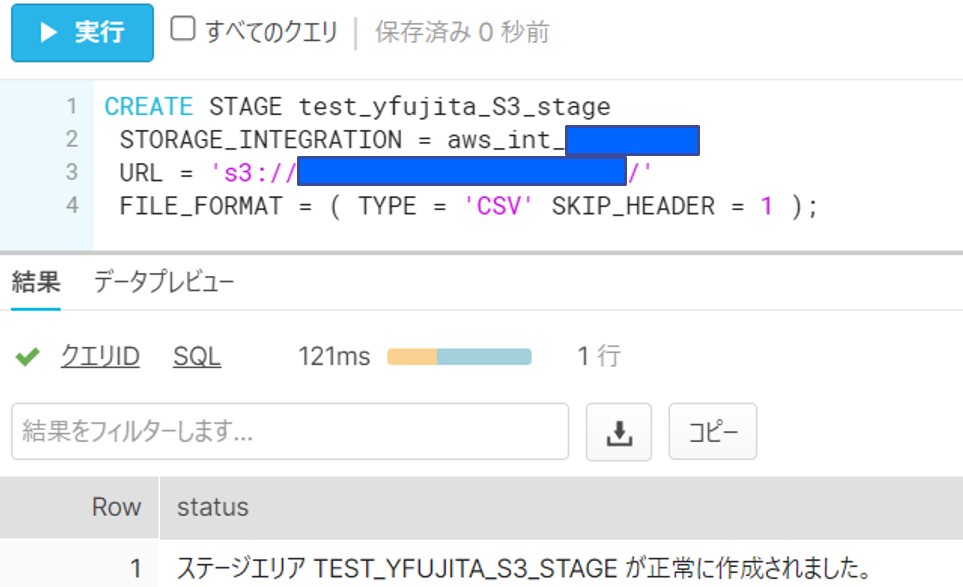
ステージの中身を確認します。※認証がうまくできていないと、このタイミングでエラーとなります。
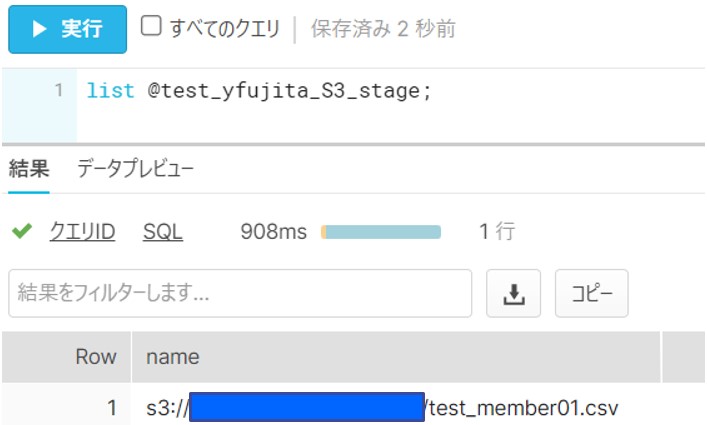
(⑧のデータ取り込み前の件数確認)
S3のデータを取り込む前に、テーブル内の件数を確認します。(データ件数:2件)
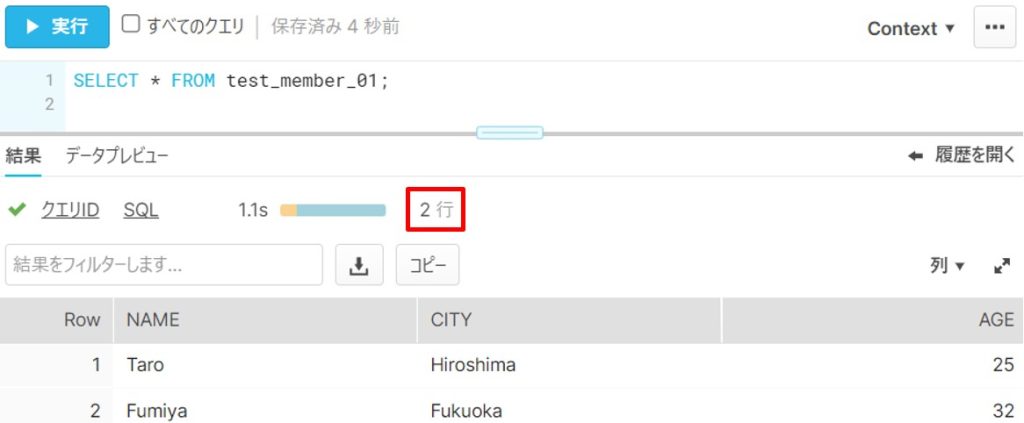
(手順⑧)
Snowflakeのポータル画面から、⑦の外部ステージを使用してS3のデータを取得します。
このタイミングで、Snowflakeのテーブルにデータが追加されます。
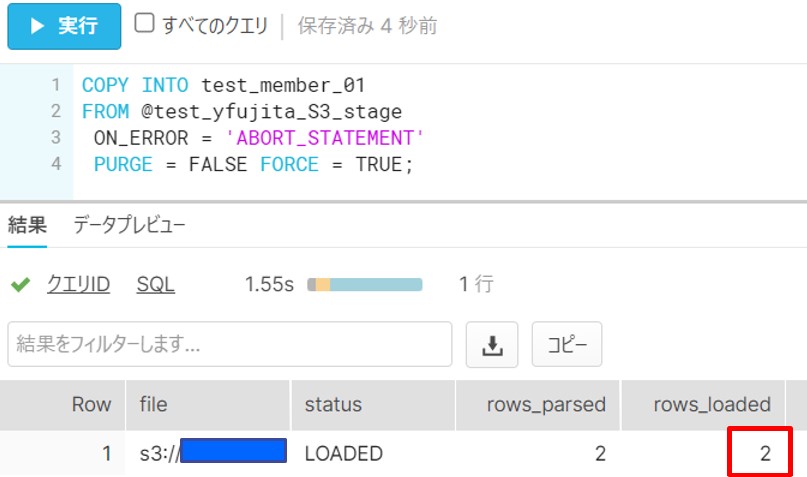
S3のデータ2件がSnowflakeのtest_member_01テーブルに登録されていることが確認できました。
AWSのAWSキー(AWSAccessKeyId)と秘密キー(AWSSecretKey)が分かっている状態であれば、事前の設定は必要なく、このキーを元に、S3からデータを取得することが可能です。

前章のSTORAGE INTEGRATIONを利用した接続方法の事前設定①~⑥が不要となり、AWSキーを利用して、Snowflakeのコンソールからデータ取得のSQLを実行します。(前章の手順⑦⑧と同様)
・前章の手順⑦と同様に、STAGEを作成します。
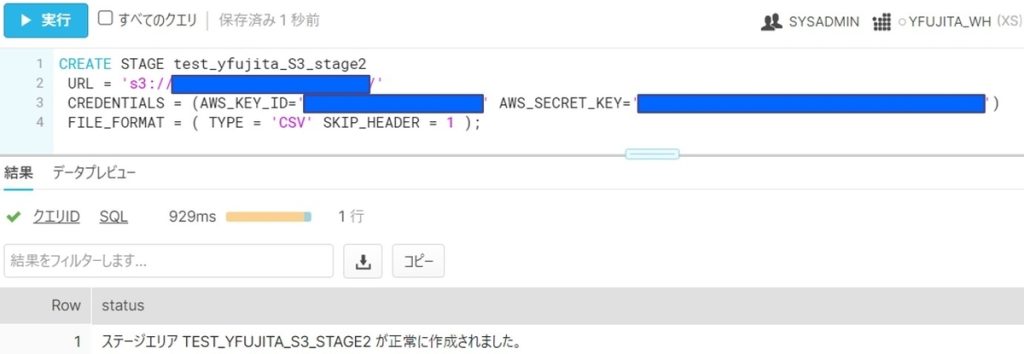
CREATE STAGE test_yfujita_S3_stage2
URL = 's3://XXXXX/'
CREDENTIALS = (AWS_KEY_ID='XXXXX' AWS_SECRET_KEY='XXXXX')
FILE_FORMAT = ( TYPE = 'CSV' SKIP_HEADER = 1 );・前章の手順⑧と同様に、S3からデータを取得します。
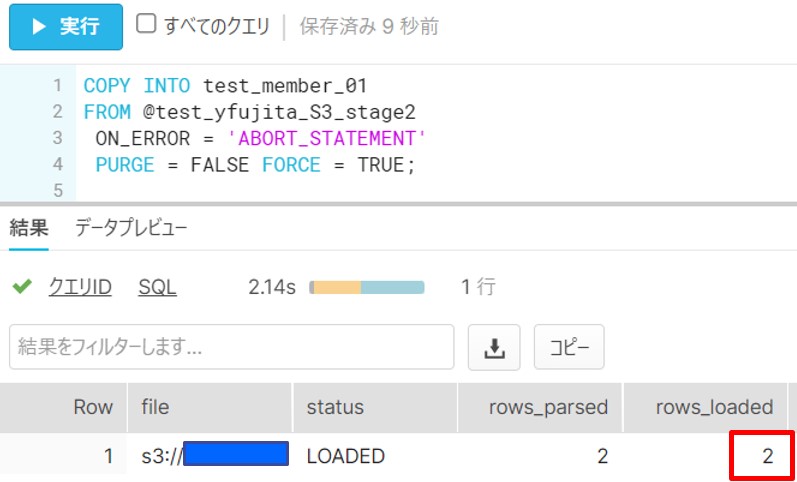
CREATE STAGE test_yfujita_S3_stage2
URL = 's3://XXXXX/'
CREDENTIALS = (AWS_KEY_ID='XXXXX' AWS_SECRET_KEY='XXXXX')
FILE_FORMAT = ( TYPE = 'CSV' SKIP_HEADER = 1 );※上記のように、簡易な手順でロードが可能ですが、AWSキーを直接記述する方法になるため、まずは試し てみたい、という場合などにご使用ください。
【補足】
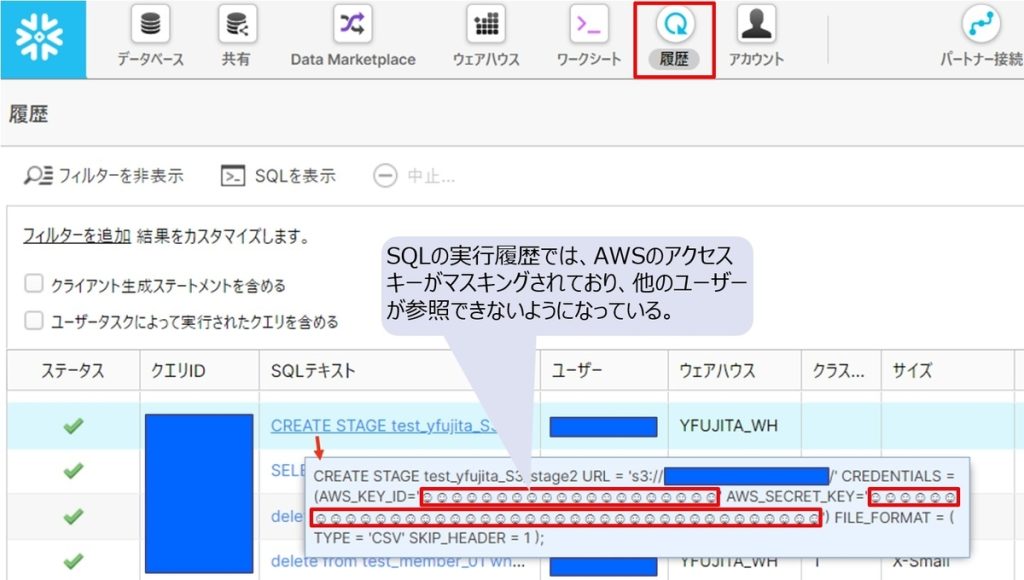
Snowflakeでは、SQLの実行履歴を保存しており、権限があれば他のユーザーの実行履歴も参照が可能ですが、このAWSのアクセスキーについては、特別な設定をしなくてもマスキングがされて参照できないようになっていました。
今回は、AmazonS3とSnowflakeの接続方法について確認をしました。STORAGE INTEGRATION(ストレージ統合)を利用した接続は、AWSとSnowflakeの双方で設定が必要になりますが、一度設定をすれば、様々なSQLをSnowflakeから実行できるので、ユーザーとしては1つのシームレスなサービスを利用している感覚になるかと思います。
今後は、AzureやGCP環境との接続方法についても整理をしていきたいと思っています。
データエンジニアリング本部では、中途採用を積極的に行っています。
ご興味がある方はお気軽にご連絡ください!
■データエンジニアリング部の紹介資料
https://speakerdeck.com/brainpadpr/brainpad-de-202107ver
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













