



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社データサイエンティストが、自然言語処理分野でよく用いられる「敵対的学習手法」から、「FGM(Fast Gradient Method)」「AWP(Adversarial Weight Perturbation)」手法をピックアップしてご紹介します。
こんにちは。アナリティクスサービス部の佐々木です。
今回は、自然言語処理の分野においてよく用いられる「敵対的学習手法」についてご紹介します。
深層学習モデルの発展により、自然言語処理分野を含め様々な分野で高い精度のモデルを作成できるようになってきた一方、入力に小さな摂動(perturbation)を加えただけで誤ったクラスに分類してしまう、敵対的サンプルと呼ばれるサンプルが存在することが指摘されています。

敵対的学習は、オリジナルのサンプルに加え、上記のような敵対的サンプルについても正しく分類できるような学習手法となっています。
敵対的学習を行うことで、単にモデルの頑健性が高まるだけでなく、オリジナルのサンプルに対してのパフォーマンスも向上することが知られており、特に近年の自然言語処理のコンペでは様々な敵対的学習手法が用いられ、それらが実際にモデルの精度向上に寄与することが報告されています。
敵対的学習、と一口にいってもそのアプローチは様々であり、それらの方法を知っておくことは実務家にとっても重要と考えられます。今回は自然言語処理でよく使われる手法をピックアップしてご紹介し、実際のコンペデータでの性能を試してみたいと思います。
FGMでは、学習のプロセスにおいてコスト関数に以下の項を追加します。
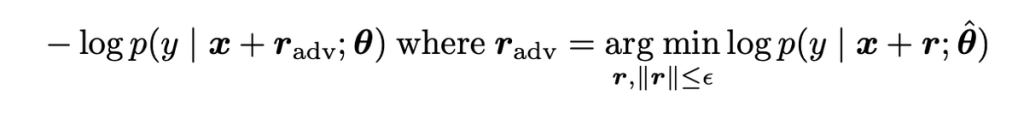
ここで、\(x\)はモデルへの入力(自然言語処理の場合、入力は文章そのものではなく埋め込み表現を想定します)、\(θ\)はモデルのパラメータ、\(r\)は摂動、\(\hat{θ}\)は現在のモデルのパラメータとなっています。
学習の各stepおいて、現在のモデルの精度を、ノルムが\(ϵ\)の範囲で最も悪化させる敵対的な摂動[tex:{r}_{adv}]を求め、その摂動を加えた際の入力に対してもコスト関数が最小化されるよう学習することで、敵対的サンプルについても正しく分類できるような学習を行うことが可能となります。
上記の学習のためには敵対的な摂動を求める必要がありますが、深層学習モデルなど多くのモデルではこの値を正確に求めることが難しくなっています。
そこで、Explaining and Harnessing Adversarial Examples において、\({r}_{adv}\)の求め方として以下のような方法が提案されました。
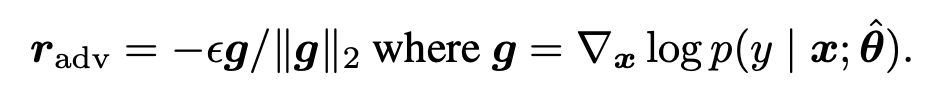
モデルの精度を悪化させる方向を微分によって求める方法となっており、これは深層学習においては誤差逆伝播を利用することで簡単に計算することができます。
FGMのpytorchでの実装、使い方は以下のようになります。
実装
# reference: https://www.kaggle.com/c/tweet-sentiment-extraction/discussion/143764
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='word_embeddings'):
"""
敵対的な摂動を求め、現在のembedding layerに摂動を加える
"""
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='word_embeddings'):
"""
敵対的な摂動を求める際に変更してしまったembedding layerのパラメータについて
元のパラメータを代入する
"""
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}使い方
fgm = FGM(model)
for batch_input, batch_label in data:
# オリジナルのサンプルについての損失を計算
loss = model(batch_input, batch_label)
loss.backward()
# adversarial training
# embedding layerに敵対的な摂動を加える
fgm.attack()
# 敵対的な摂動を加えられた状態での損失を計算
loss_adv = model(batch_input, batch_label)
loss_adv.backward()
fgm.restore()
optimizer.step()
model.zero_grad()FGMにおいては、敵対的な摂動はモデルの入力(入力の埋め込み表現)に対して加えられることになりますが、摂動をモデルの「入力」ではなくモデルの「重み」に加える、という方法も考えられます。この方法として代表的なのがAWP(Adversarial Weight Perturbation)です。
コンペにおいては以下の実装がよく用いられています。原論文においてはモデルの重みに対しての摂動だけではなく、同時に入力に対しての摂動も加えるなど、コンペで用いられている実装とは差異がありますので、原論文の実装が気になる方は論文を参照していただければと思います。
実装
# reference: https://www.kaggle.com/code/wht1996/feedback-nn-train/notebook
class AWP:
def __init__(
self,
model,
optimizer,
adv_param="weight",
adv_lr=1,
adv_eps=0.2,
start_epoch=0,
adv_step=1,
scaler=None
):
self.model = model
self.optimizer = optimizer
self.adv_param = adv_param
self.adv_lr = adv_lr
self.adv_eps = adv_eps
self.start_epoch = start_epoch
self.adv_step = adv_step
self.backup = {}
self.backup_eps = {}
self.scaler = scaler
def attack_backward(self, x, y, attention_mask,epoch):
"""
敵対的な摂動を加えた損失を計算し、パラメータを更新する
"""
if (self.adv_lr == 0) or (epoch < self.start_epoch):
return None
self._save()
for i in range(self.adv_step):
self._attack_step()
with torch.cuda.amp.autocast():
adv_loss, tr_logits = self.model(input_ids=x, attention_mask=attention_mask, labels=y)
adv_loss = adv_loss.mean()
self.optimizer.zero_grad()
self.scaler.scale(adv_loss).backward()
self._restore()
def _attack_step(self):
"""
敵対的な摂動を求め、重みに加える
重みの範囲をbackup_epsで制限している
"""
e = 1e-6
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None and self.adv_param in name:
norm1 = torch.norm(param.grad)
norm2 = torch.norm(param.data.detach())
if norm1 != 0 and not torch.isnan(norm1):
r_at = self.adv_lr * param.grad / (norm1 + e) * (norm2 + e)
param.data.add_(r_at)
param.data = torch.min(
torch.max(param.data, self.backup_eps[name][0]), self.backup_eps[name][1]
)
def _save(self):
"""
重みのバックアップと、重みの範囲を取得する
重みの範囲はパラメータの絶対値とadv_epsによって決定する
"""
for name, param in self.model.named_parameters():
if param.requires_grad and param.grad is not None and self.adv_param in name:
if name not in self.backup:
self.backup[name] = param.data.clone()
grad_eps = self.adv_eps * param.abs().detach()
self.backup_eps[name] = (
self.backup[name] - grad_eps,
self.backup[name] + grad_eps,
)
def _restore(self):
"""
バックアップを取っていたパラメータを代入するとともに初期化する
"""
for name, param in self.model.named_parameters():
if name in self.backup:
param.data = self.backup[name]
self.backup = {}
self.backup_eps = {}今回は自然言語処理分野で用いられる敵対的学習手法についていくつか紹介しました。今後も様々な敵対的学習手法が出てくると思いますので、引き続きキャッチアップしていきたいと考えています。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













