



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

自社開発プロダクト「Rtoaster」をはじめとする製品群を扱うプロダクトビジネス本部(PB本部)の社員によるエンジニアブログです。今回は、CDP「Rtoaster insight+」の開発チームで構築したワークフロー機能について紹介します!
PB本部開発部の新谷です。この記事では、自社製品「Rtoaster」のCDPチームで開発したワークフロー機能について紹介します。
弊チームでは、顧客の保有するデータを統合し、分析した結果を施策につなげるためのプラットフォームを開発しています。具体的には以下のような機能を提供しています。
特に1つ目のETL機能については、取り込み・加工・出力の1つ1つの処理を「ジョブ」という単位で実現しています。プロダクトの初期段階ではジョブ間の順序関係を明示的に指定する方法がなく、顧客が各ジョブのスケジュール実行のタイミングを調整して、ジョブの実行順序を保証する運用となっていました。これには以下のような問題があります。
これらの課題を解決するために、顧客の指定した順序関係に従って一連のジョブを実行する、ワークフロー機能を実装しました。
UI上でワークフローを組み立てる部分に関しては、以下のような要件がありました。
◦ジョブの追加、削除
◦ジョブ間の順序関係の追加、削除
◦ワークフローの見た目の変更(ジョブの表示位置の変更、表示の倍率変更)
以上を満たすライブラリとして、Drawflow (drawflow – npm) を採用しました。こちらは他に似たようなライブラリが少なく、選定工程でほぼ迷いがありませんでした。
またワークフロー実行に関しては以下のような要件がありました。
これらを満たすワークフローエンジンとして、Digdag(Home Default )とCloud Composer(Cloud Composer | Google Cloud ) が候補に挙げられました。今回はコストを抑えたかったことと、既存のジョブ実行の仕組みとの親和性から、Digdagを採用しました。
こちらがワークフローのUIイメージです。ジョブの端点をドラッグ&ドロップで繋ぎ合わせることで、直感的に順序関係を設定できます。
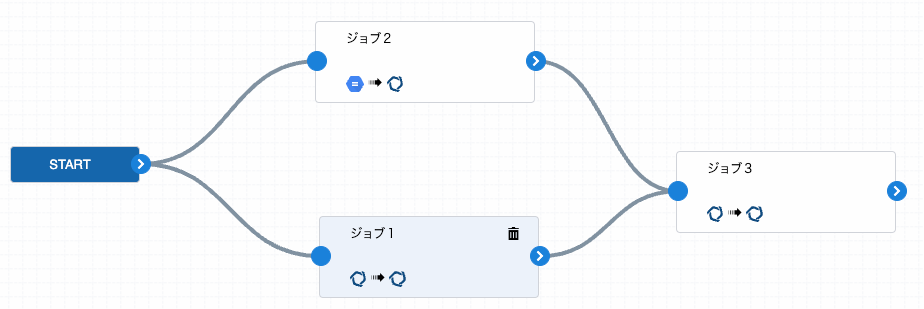
ユーザーがワークフローを作成すると、ワークフロー内のジョブの結びつきが隣接リストとしてバックエンドに送られます。上のワークフローの場合は、以下のような隣接リストが生成されます。
[[“START”, ジョブ1”], [“START”, “ジョブ2”], [“ジョブ1”, “ジョブ3”], [“ジョブ2”, “ジョブ3”]]
バックエンドではこの渡された隣接リストをもとに、Digdagによるワークフロー実行に必要なdigファイルを組み立てる処理を行います。例えば先ほどの隣接リストからは、次のようなdigファイルが生成されます。
timezone: Asia/Tokyo
+group_0:
_parallel:
limit: 5
+job_1:
sh>: {ジョブ1を実行するスクリプト}
+job_2:
sh>: {ジョブ2を実行するスクリプト}
+job_3:
sh>: {ジョブ3を実行するスクリプト}
+success:
sh>: {成功時の処理}基本的に書かれた順番に処理が実行されますが、parallelの指定されたブロック内の処理は並列実行されます。以下ではこのdigファイルの組み立て方について説明します。
まずは隣接リストで表現されている前後関係を破らないように、ジョブを一列に並べる必要があります。そのため隣接リストをもとにトポロジカルソートします。
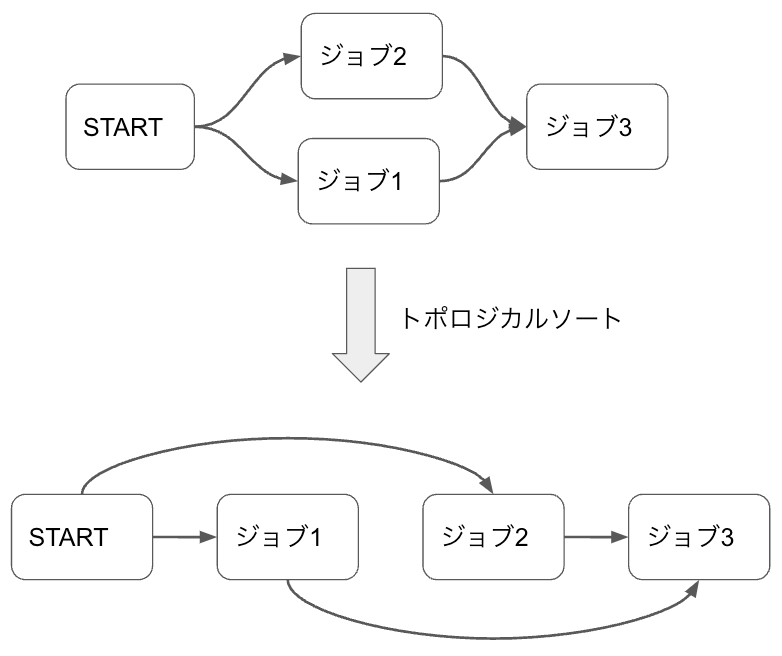
その後、基本的にはソート結果の順番にdigファイルに書けば良いのですが、一般にはソート結果が一意にはならない場合があります。例に挙げたDAGの場合、ジョブ1とジョブ2は入れ替えた結果もトポロジカルソートとなっています。つまりジョブ1とジョブ2はどの順番で実行しても順序関係を崩さないので、並列実行することができます。結果として先ほど記載した通りのdigファイルが生成されます。
timezone: Asia/Tokyo
+group_0:
_parallel:
limit: 5
+job_1:
sh>: {ジョブ1を実行するスクリプト}
+job_2:
sh>: {ジョブ2を実行するスクリプト}
+job_3:
sh>: {ジョブ3を実行するスクリプト}
+success:
sh>: {成功時の処理}一般に、入れ替えてもトポロジカルソートのままであるようなジョブの集合がある場合、そのジョブ集合は並列実行が可能です。
DAGをもとにしたdigファイルの組み立てが終わったので、これをDigdagに渡せばワークフローを実行することができます。またUI上でのワークフローの定義は顧客が自由に行えるので、一般には閉路がありえるのですが、それもトポロジカルソートを行うことで弾くことができます。
現状ではワークフロー内の各ジョブの実行ステータスは、ワークフローが全て終わってから一度にUI上に反映されるようになっています。ワークフロー実行中に順次ジョブのステータスを反映する方が、ユーザーに親切になると思います。
またワークフロー内の並列実行されるジョブが全て成功しないと、後続のジョブに進まない仕様となっております。つまりジョブの結びつきを依存関係ではなく単なる順序関係として解釈しているのですが、この部分を改善することでワークフロー失敗時に実行されないジョブを減らすことができます。
その他にも、以下のような要望もあります。
これらの改善案も今後検討していきたいと思っております。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













