



このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回は、LLMのビジネス利用に関して注意すべき点として、「著作権の侵害リスク」についてまとめました。
今回は、LLMのビジネス利用に関して注意すべき点として、「著作権の侵害リスク」についてまとめました。
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。アナリティクスサービス部の安藤です。LLMのビジネス利用に関して注意すべき点について解説させていただいている連載の3回目となります。
前回の記事では、LLMサービスをビジネス利用する際に、個人情報や営業秘密等の保護に関して注意すべき点について紹介しました。
LLMサービスを利用する際の他の主要なリスクとして、サービスに他者の著作物を入力したり、サービスの出力に他者の著作物が含まれていることで、他者の著作権を侵害するおそれがあります。本稿では、LLMサービスとの関係で問題となりうる主な著作権法上の権利について述べるとともに、LLMサービスを利用するに当たって著作権法との関係で気をつけるべき点について解説します。
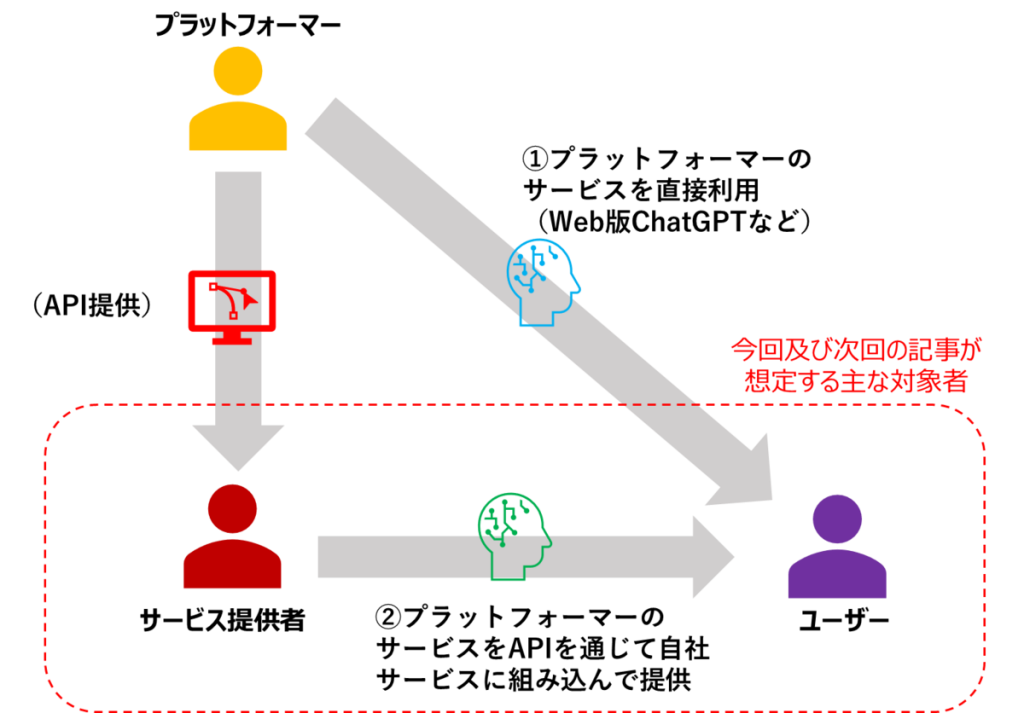
まず、本記事が想定する主な対象者の方について、これまでの連載でも使用した図を用いて説明します。
本連載では自らモデルを開発しサービスを提供する者を「プラットフォーマー」、プラットフォーマーの提供するサービスをAPI等を通じて利用し、自社のサービスを提供する者を「サービス提供者」、プラットフォーマーやサービス提供者が提供するサービスを利用する者を「ユーザー」と呼んでいます。
現状、日本国内においてLLMを用いたサービスを提供・利用する者は、自らモデルを開発するのではなく、海外のプラットフォーマー(OpenAI社やMicrosoft、Googleなど)が開発したサービスをAPI経由で利用している場合が大半と思われます。
したがって、本記事でも引き続き、主な対象として「サービス提供者」と「ユーザー」において注意すべき著作権上の問題について解説していきます。
また、以降ではプラットフォーマーが開発したモデルを用いるサービス(図の①又は②)を指して「LLMサービス」と呼びます。
著作権法において、著作物の著作者には様々な権利が付与されていますが、LLMサービスとの関係で問題となり得る主な権利は以下のようなものが考えられます。
複製権
複製権は、著作者に与えられた最も基本的な権利であり、全ての著作物が対象となります。手書き、印刷、写真撮影、複写、録音、録画、パソコンのハードディスクやサーバーへの蓄積など、その方法を問わず、著作物を「形のある物に再製する」 (コピーする)ことに関する権利で、このような行為を行えば、著作者の複製権が働きます。
第二十一条(複製権)
著作者は、その著作物を複製する権利を専有する。
例えば、LLMサービスに論文や記事などの著作物を入力することで、サービス提供者のサーバーに当該情報が保存される場合、著作権法第21条の「複製」に該当します。
公衆送信権
「公衆送信権」は、放送、有線放送、インターネット等、著作物を公衆向けに送信することに関する権利であり、このような行為を行えば、著作者の公衆送信権が働きます。
第二十三条(公衆送信権等)
著作者は、その著作物について、公衆送信(自動公衆送信の場合にあつては、送信可能化を含む。)を行う権利を専有する。
2 著作者は、公衆送信されるその著作物を受信装置を用いて公に伝達する権利を専有する。
また、インターネットのように、受信者がアクセスした情報だけ手元に送信されるような送信形態を「自動公衆送信」といいます。また、送信の準備段階として、送信される状態に置く行為(いわゆる「アップロード」等)を「送信可能化」と定義しており、アップロードも「自動公衆送信」に含まれます。したがって、受信者への送信が行われていなくても、無断でアップロードすると権利侵害となります。
翻訳権、翻案権
「翻訳権・翻案権等」は、著作物(原作)を、翻訳、編曲、変形、脚色、映画化などにより、創作的に「加工」することによって、「二次的著作物」を創作することに関する権利です。「翻案」には、著作物の要約も含まれます。
第二十七条(翻訳権、翻案権等)
著作者は、その著作物を翻訳し、編曲し、若しくは変形し、又は脚色し、映画化し、その他翻案する権利を専有する。
ここからは、LLMサービスの利用においてどのような場合に著作権侵害が起きるリスクがあるかについて説明します。
まず、当然ですがLLMサービスへの入力・出力ともに他者の著作物ではない場合は著作権の侵害リスクはありません。例えば、「〇〇について書かれた論文(or記事)のリストと所在(URLなど)を教えてほしい」といった質問を入力し、論文や記事のタイトルと所在情報のリストを得るような場合です。このような場合は既に述べたような著作権者の有する権利を侵害するものではありません。
LLMサービスの利用において著作権侵害の問題が発生しうるのは、入力又は出力に他者の著作物の全部又は一部が含まれる場合です。以下、サービスへの入力と出力に分けてそれぞれの問題点について解説します。
まず、LLMサービスに他者の著作物を入力することの問題点について説明します。例えば、他者が著作権を有する論文やWeb記事などを入力して、その翻訳や要約を出力する場合などです。
既に述べたように、LLMサービスに著作物を入力する行為自体は著作権法第21条の著作物の「複製」に該当します。しかし、これにより直ちに著作権侵害が発生し得るかというと別問題です。著作権法には一定の「例外的」な場合に著作権等を制限して、著作権者等に許諾を得ることなく利用できる条件が置かれているためです(著作権法第30条〜第47条の8)。
LLMサービスへの著作物の入力が著作権侵害に当たるかについては、現状確立された見解はありません。ただし、出力が他者の著作物に当たらない場合(例えば翻案に当たらない程度の論文の抄録や要旨など)、著作権法第30条の4に規定する「情報解析」や「非享受利用」に該当するため、著作権侵害に当たる可能性は低いという見解があります(詳細は下記「著作権法第30条の4の例外について」を参照)。
他方で、出力が他者の著作物の全部又は一部に当たる場合は、後述するようにサービス提供者・ユーザーともに著作権侵害に当たるリスクがあります。
また、出力が他者の著作物ではない場合でも、Web版のChatGPT(オプトアウトしていない場合((連載第2回の個人情報の保護の問題についてでも解説しましたが、現在Web版のChatGPTでは、ユーザーが手元で簡単に会話記録をモデルの学習に利用されないようにすることが可能となっています。)))など、入力した情報がモデルの学習に利用される場合、入力した著作物と同一又は類似の内容が第三者に取得される可能性もあります。その場合、間接的に著作権の侵害を助長することになりかねないため、少なくとも入力した情報がモデルの学習に利用されるサービスには、みだりに他者の著作物を入力しない方がよいのではないかと思われます。
【著作権法第30条の4の例外について】
著作権法第30条の4は、「著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」には、その必要と認められる限度において、著作物を方法を問わず利用することができるとしています。
それに該当する場合として、「情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うこと)の用に供する場合」(著作権法第30条の4第2号)と「非享受利用(著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用に供する場合)」(同条第3号)が挙げられています。
現在のところ、出力が他者の著作物でなければ、単に他者の著作物を入力する行為については、後述するように著作物の情報解析のための利用や非享受利用が行われていると考えられることから著作権侵害には該当しないとする見解も主張されています。
【日本ディープラーニング協会の生成AIガイドラインについて】
2023年5月1日、一般社団法人日本ディープラーニング協会が「生成AIの利用ガイドライン」を公開しました。LLMを含む生成AIガイドラインをビジネス利用する際に法的な観点から気を付けるべき点について、網羅的にまとめられています。
著作権の問題についても言及されており、他者の著作物を入力する行為は『単に生成AIに他人の著作物を入力するだけの行為は、著作権法30条の4の「情報解析」非享受利用」に該当すると思われますので、著作権侵害のリスクはかなり低いと思われ』るとしています。
(参考)日本ディープラーニング協会「生成AIの利用ガイドライン【簡易解説付】」
続いて、LLMサービスの出力に他者の著作物が含まれる場合の問題について解説します。入力の場合と比較すると出力においてはより直接的に著作権侵害が発生するリスクがあると思われます。
LLMサービスから他者の著作物を出力する例としては、「〇〇というタイトルの論文やWeb記事(他者が著作権を有するもの)の全部or一部を出力してほしい」というような場合があります。また、出力が著作物の全体や一部そのものではなく、著作物の翻訳や要約などの二次的著作物である場合も、著作物を翻訳したり要約する権利は「翻案権」に含まれます。
この場合、サービス提供者は、他者の著作物を送信可能化することにより、
また、ユーザー側も、出力された著作物を他者の著作物であると知りながら自社の出版物で公表するなどして利用した場合、同様に著作権侵害が発生します。
ユーザー側もサービス提供者側も、出力に他者の著作物が含まれる場合は著作者の許諾を得るなど、慎重な対応が必要です。
【著作物の「依拠性」について】
LLMサービスの出力に他者の著作物が含まれる場合に著作権侵害の可能性があることについて説明しましたが、微妙な問題として、偶然他者の著作物やその類似物が出力されてしまう場合があります。
著作権侵害が肯定されるためには、出力物が元の著作物に対して「依拠性」がある(作品が既存の著作物を利用して作出されたものであること)と認められることが必要です。例えば、ある論文の内容をLLMサービスにそのまま入力して要約させる場合は、明確に出力された要約の元の論文への依拠性が認められると考えられます。
他方で、例えば特定の論文の存在を知らずに「〇〇の概念について教えてほしい」というプロンプトを入力して、たまたまある論文の内容が出力されたような場合に、依拠性があるといえるかははっきりした基準はありません。
なお、論文や記事のタイトルや著者名を入力するなど、ユーザーが明らかに特定の著作物の出力を意図していると認められる場合は、この「依拠性」があると判断される可能性が高いという見解があります*1。
【LLMサービスにおける著作権侵害の防止のための対策】
現在国内で展開されている文章要約系のサービスには、利用規約において、入力物に関する著作権について、入力物が他者の著作物である場合には著作権者から許諾を得るなど、ユーザーの責任において著作権侵害が無いことを担保することを求めているものが多いのではないかと思われます*2。
LLMサービスの利用による著作権侵害の発生を未然に防ぐた【「翻案」の範囲について】たり、責任の所在を明確にしておくことが考えられます。また、ユーザーにおいても事前に利用規約等で著作権に関する事項をしっかり確認することが重要です。
「著作者の権利」や「著作隣接権」が侵害された場合には、以下のような刑事・民事上の責任が生じます。
刑事
個人と法人の場合で異なります。個人の場合、原則として「10 年以下の懲役」又は「1000 万円以下の罰金」(懲役と罰金 の併科も可)という罰則規定が設けられています。企業等の法人による場合は、「3億円以下の罰金」が科せられます。
民事
著作権の侵害を受けた者は、著作権法に基づき、侵害をした者に対して侵害行為の停止を求めることができるほか、侵害のおそれがある場合に予防措置を求めることができます(著作権法第112条、第116条)
また、民法の規定に基づき、侵害をした者に対して以損害賠償の請求や、不当に得た利益の返還請求ができます(民法第703条、第704条、第709条)
今回はLLMサービスのビジネス利用に当たっての主要な法的リスクのうち、著作権の問題について扱いました。著作権についても前回の個人情報や営業秘密等に関する問題と同様、法的な見解が定まっていない部分が多いですが、LLMサービスの利用に当たってどのような場面で著作権の問題が生じうるかを認識しておき、著作権侵害が起きないよう、適切な対応を行うことが必要です。
本記事がLLMサービスの利用に当たっての著作権に関する問題について理解を深めるきっかけとなれば幸いです。
最後までお読みいただき有難うございました。
*1:先に紹介した日本ディープラーニング協会の「生成AIの利用ガイドライン」においては、保守的なスタンスをとり、「プロンプトに既存著作物、作家名、作品の名称を入力しないようにしてください」と記載しています
*2:例えば、東京大学松尾研究室が開発・提供している長文要約AIサービス「ELYZA DIGEST」の利用規約ではそのような規定を置いています。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













