

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回は、ビジネス展開を想定したAzure OpenAI Serviceのネットワークセキュリティの設定について紹介します。
アナリティクスサービス部の秋本です。
今回は、AzureOpenAIを利用するまでのガイドラインとして、Azure管理者・プロジェクト管理者向けにビジネス展開を想定したAzure OpenAI Serviceの設定について紹介していきます。
初回利用や利用者向けの記事は下記を読んでいただければと思います。
Azure OpenAI ServiceでChatGPTを使ってみた – Platinum Data Blog by BrainPad
大規模言語モデル(LLM)の技術が高まると同時に、ChatGPTを皮切りに様々な用途で使いたい・サービス展開したいという需要が急激に増加しました。
しかし、ビジネスで利用する場合、情報の取り扱いやリスクについていろいろ考える必要があります。これらについては、当ブログ上でも以前触れております。
【連載①】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-LLMの使用許諾条件- – Platinum Data Blog by BrainPad
【連載②】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-個人情報や営業秘密等の保護- – Platinum Data Blog by BrainPad
【連載③】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-著作権の侵害リスク- – Platinum Data Blog by BrainPad
【連載④】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-海外の法規制- – Platinum Data Blog by BrainPad
本記事では、Azure管理者・プロジェクト管理者向けにビジネス展開を想定したAzure OpenAI Serviceの設定について紹介していきます。
ChatGPTの場合、プロンプトが学習に使われるかどうかの話に注目が集まりがちですが、エンタープライズでの利用を考えた場合、情報漏えいや不正アクセスをはじめとしたセキュリティも非常に重要です。
Azure OpenAI ServiceはOpenAI APIと異なり、クラウドサービスとしてセキュリティに関する機能が十分に備わっているため、それらを紹介します。
以下の条件まではすでに済んでいるものとします。
Azureでリソースグループを作成していきます。
リソースグループとは、その名の通りAzureのリソースを管理しておく箱(コンテナー)です。「リソース」とは、仮想マシンや仮想ネットワークなどの各サービスです。Cognitive Serviceのアカウントもこれに該当します。アクセス制御や権限管理も基本的にリソースグループで行うことが多いため、事前に検討しておくことでスムーズかつ安全に利用を開始できます。
リソースグループは、リソースの一覧表示や一斉削除を行えます。そのため、用途にあったグループの管理方法が幾つかあります。
アプリケーションやソリューションに必要なリソースをまとめて管理するパターンがあります。この方法は、dockerやk8sのコンテナの考え方に近いかもしれません。ネットワーク構成やコンピューティングリソースの設定をまとめ上げ、その中でアプリケーションに関するリソースが完結するように作成する方法です。
開発用・本番用と似た構成を複数用いる場合にも有効な方法です。
補佐的に、一部の共有設定(社内ネットワークとのS2S設定など)だけを共有リソースグループとして作成しておく事も可能です。
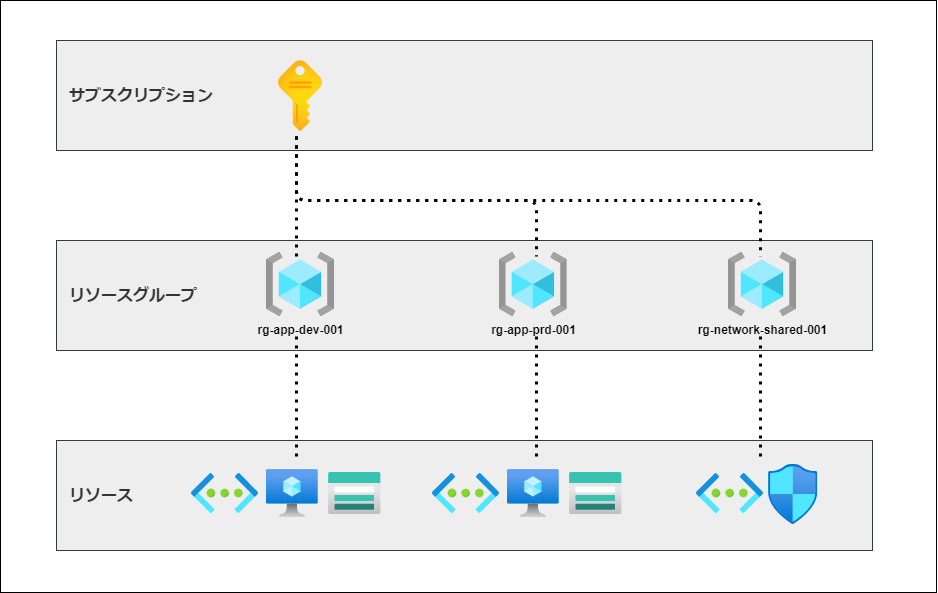
具体的なアプリケーションがない場合は、アクセス制御の観点でリソースグループを作成すると良いでしょう。リソースグループ毎に使用状況を確認できるため、部署・部門でリソースグループを分けると言った方法もあります。
また、請求単位でサブスクリプションを分けていない場合、リソースグループを請求単位として分けておくユースケースもあります。

リソースグループを作成する場合、リージョンを選択する必要があります。
リソースグループには、リソースに関するメタデータが格納され、リソースを利用する際に必要に応じてメタデータを読み込む場合があります。リージョンはそのメタデータを格納する場所を指定する事になります。リソースグループ内のリソースを同じリージョンに限定する必要はないですが、基本的に同じリージョンに設定する方がパフォーマンス的に良いでしょう。
今回利用するAzure OpenAI Serviceは日本リージョンがないため、利用したいモデルが提供されているリージョン(East US, South Central US, West Europeいずれか)の利用は避けて通れません。
各リージョンごとにAzure OpenAI Service用のリソースグループを作成する方が無難でしょう。

Azure OpenAI Serviceのアカウントを作成します。
アカウントの分け方ですが、調査・研究段階であればリージョンごとに1つずつ作成すれば良いでしょう。その後、ユースケースが固まったり、アプリケーションが具体化してきた時はそれごとに分けるのが良いかと思います。利用量(メトリック)をアカウントごとに集計できるため、アプリケーションを監視する目的としても適しています。
また、クォータの審査において、アカウントごとに利用状況や制限緩和の正当性の説明が必要になります。その観点でも、アプリケーションごとにアカウント作成することを検討したほうが良いでしょう。
クォータの既定値については適宜変更されます。下記より確認できます。
Azure OpenAI Service のクォータと制限 – Azure Cognitive Services | Microsoft Learn
Azureでは、仮想ネットワークを始めとしたネットワークサービスを多数展開しています。
これらはAzure OpenAI Serviceをアプリケーションに組み込む場合にも適応でき、社内のコンプライアンスや秘匿情報の保護に役立ちます。OpenAI APIではなくAzure OpenAI Serviceを利用するメリットの最も大きいところと言っても良いでしょう。
OpenAIアカウントごとネットワーク設定ができます。
社内利用を考えた場合、閉塞網で利用できることがシンプルかつ一般的な構成でしょう。
設定内容としては以下の2種類があります:

2.の場合、社内VPNのパブリックIPなどを指定することで社外からの利用を拒否することができます。秘匿情報を含まないような調査段階であればこれで十分でしょう。
アプリケーションに組み込む場合、最終的には1.を選択するべきです。
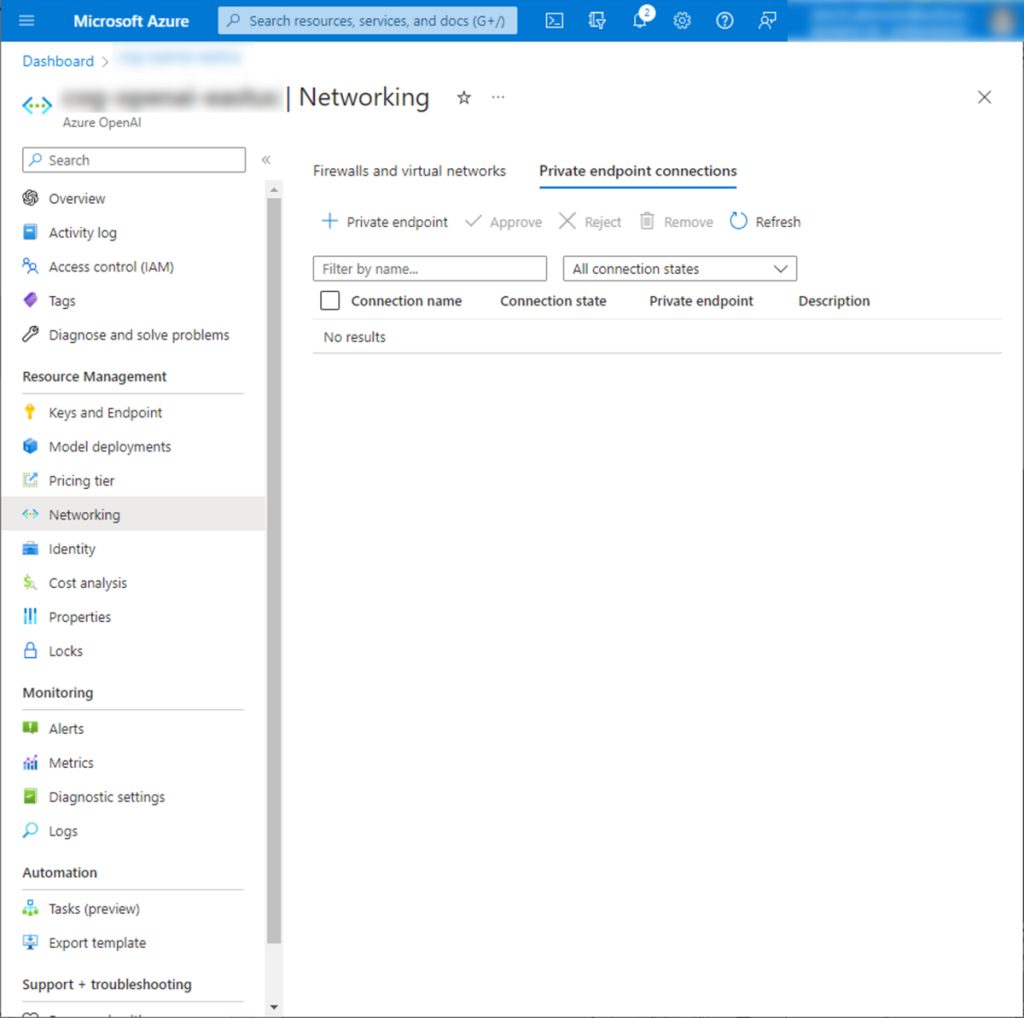
その場合、プライベートエンドポイントを立てる必要があります。
下記は、WebUIなどのアプリケーション上からAzure OpenAI Serviceを利用するシンプルな構成案です。WebUIではなく、(Slackなどと連携するなどを目的とした)APIを構築する場合は、Web AppをFunction Appに置き換えることで同様のことができます。

Azure OpenAI Serviceはプライベートエンドポイントをサポートしています。
APIへの通信をインターネット経由ではなく閉塞網経由にすることができます。
また、Firewallも設定できるため、インターネットからの通信を拒否したり、社内VPNからのアクセスのみを許可したりと、セキュアな通信環境を構築できます。
OpenAIに関して、プロンプトに送られる情報や学習に使われるか否かという話にフォーカスが当たりがちですが、エンタープライズ利用、セキュアな通信環境を構築することは必須要件かと思いますので、検討することをオススメします。
今回、Azure OpenAI Serviceの利用について、ネットワークセキュリティの観点から設定すべき項目について触れました。
エンタープライズ利用かつ、社内データ・社内ナレッジと言った秘匿性の高い応報を扱う場合、閉塞網での利用が基本となるかと思います。
Azure OpenAI Serviceの場合、それらは既に準備されているため、比較的容易に環境設定することが可能です。ChatGPTを始めとするLLMの活用と並行して如何に安全に利用するか、本記事が参考になればと思います。
LLM(大規模言語モデル)やFM(基盤モデル)に自社データを入力する場合、そのデータの在処は必ずしもAzure上ではないと思います。既存の分析業務はオンプレミスであったり他のクラウドサービスである場合もあるかと思います。
また、データの所在としてConfluenceやWikiなども考えられるでしょう。
社内ナレッジ検索としてAzure Open AIを使う場合、以下の様な構成で組むことになるかと思います。
Azure内のセキュア環境だけでなく、Azureとオンプレミスとの間のセキュリティについても考える必要があります。

より重要で意味のあるデータを使おうと思えば思うほどセキュリティ(とポリシー)の問題がついて回るため、今後はデータ活用と併せて知見を深めていく必要がありそうです。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













