



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
BERTとChat GPTの精度比較に関する記事を全2回でお届けします。連載の第1回はBERTを用いた日本語の誤り文修正モデルについてご紹介します。
ブレインパッドでデータサイエンティストとして働いている鈴木といいます。
連日、本ブログでは弊社LLM研究プロジェクトによる投稿が続いておりますが、私はBERTとChat GPTの精度を比較した内容を報告したいと思います。
本日の連載①ではBERTを用いた日本語の誤り文修正モデルについての説明を、明日の連載②ではそれとChat GPTとの精度比較についてご説明します。
ここで突然ですが、問題です。
以下の日本語文にはそれぞれ誤字または脱字が1つずつ含まれています。
皆さんはそれらを指摘、修正できますでしょうか?
1. 2017fifau−20ワールドカップは、2017年5月20日から6月11日かけて行われる予定の21回目のfifau−20ワールドカップである。
2. 草刈りにも強く、石外の間に根を下ろし、背の低い群落を形成し、初夏に一面に咲いていたという。
3. ウーゴ・アウカンタラは、ブラジル・クイバア出身のサッカー選手。
いかがだったでしょうか?
1.は分かりやすいかと思いますが、2.や3.は少し難しかったかも知れません(正直私は間違えてしまいました)。
今回は、今取り組んで頂いたような誤り文の修正をBERTやChat GPTで実行し、精度を比較してみた、というお話になります。
ちなみに学習後のBERTやChat GPTでは、先ほどの3問いずれも正解しています。特に3.についてはブラジルのクイアバについて知っている必要があり、単に文法修正に留まっていないのが驚きです。
それでは改めて、BERTによる誤り文修正モデルについてご説明します。これはPCやスマホ等で入力した文の誤りを検知し修正するタスクになり、Wikipediaでの修正履歴を元にした学習データを用いてファインチューニングをしています。
例えば前述の問題2.のように、「いしがき」→「石垣」とする所を、誤って「いしがい」→「石外」と入力・変換してしまった、といったものです。
英語ではGED(Grammar Error Detection)やGEC(Grammar Error Correction)と呼ばれておりますが、言語によって間違の種類は違うため、日本語独自のアプローチが必要になります。
具体的には、以下のようなビジネスシーンでの活用が期待できます。
今回、誤りを以下の7種類としています。
誤字
脱字
句点抜け
読点抜け
衍字(えんじ)
転字
漢字誤変換
それぞれどのような誤りなのか、以下から具体的にご覧いただけます*1。
ちなみに、太字になっているのが誤りの含まれる部分です。
1.誤字
ひらがな又はカタカナ1文字が誤っています。
例) 「バットマンの存在が犯罪を呼ぶ」点をフューチャーしたエピソードである。(正解は「フィーチャー」)
2.脱字
ひらがな又はカタカナ1文字が抜けています。
例) さて、上記の『すごくおいしうた』の件で…(正解は「おいしいうた」)
3.句点抜け
句点が1つ抜けています。
例)2011年1月、リメイクベストアルバム「moonlightsongs」をリリース東日本大震災を契機に活動を休止。(正解は「リリース。東日本」)
4.読点抜け
読点が1つ抜けています。
例)駅の発車標は御堂筋線谷町線、四つ橋線、長堀鶴見緑地線…(正解は「御堂筋線、谷町線、」)
5.衍字
2種類あります。
a)ひらがな又はカタカナが1文字余分に入っています。
例)氷のブロックを運ぶ目的としてく作られた。(正解は「目的として作られた。」)
b)ひらがな又はカタカナ又は漢字が余分に繰り返されています。繰り返しが1文字の場合は漢字、2文字以上の場合はひらがな又はカタカナ又は漢字です。
例)スロバキア代表デビューを果たしたした。(正解は「果たした。」)
6.転字
ひらがな又はカタカナ2文字が逆転しています。
例)また何かと美星につかっかってくる。(正解は「つっかかってくる。」)
7.漢字誤変換
漢字が誤っています。
例)首都圏方言に近い言葉を話す若者が急造しており…(正解は「急増」)
今回は、2つのモデルを用いて文書修正を行います。1つはラベリングに特化したモデル①、もう1つは[MASK]に入る単語を予測するモデル②です。
具体的には、以下のような流れになります。ちなみにこちらは漢字誤変換(ラベル = 7)の例です。
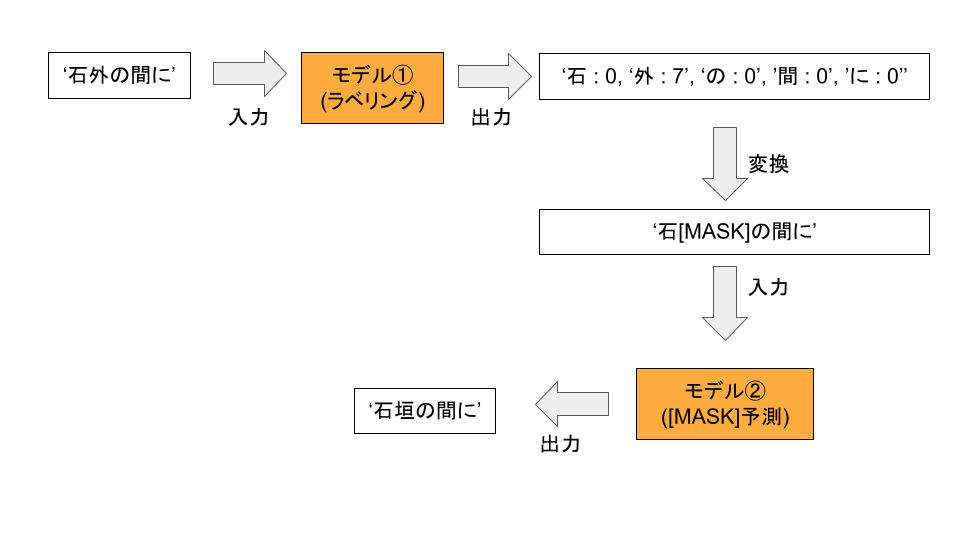
モデル②の部分では、事前学習として[MASK]を予測するタスクを既に事前学習したパラメータをそのまま使用します*2。
モデル①は、各トークン毎にラベルをつけるタスク(=ラベリング)のために学習させたモデルになります。以降は、このラベリングモデルの学習についてご説明します。
今回は、京都大学の言語メディア研究室が作成された日本語Wikipedia入力誤りデータセット (v2) を使用させて頂きました*3。nlp.ist.i.kyoto-u.ac.jp
Wikipediaの修正履歴から誤り文を作成しており、70万行近く含まれています。
上記京都大学のデータには句点抜け並びに読点抜け文章は含まれていません。また、文毎にそれぞれ別々の記事から待ってきているため、文を結合させて句点抜けデータを作成する事もできませんでした。
そこで、GoogleのWiki-40B: Multilingual Language Model Datasetからこれらのデータを作成しました*4。
research.google
このデータセットには745,392個のWikipedia記事が入っています。それぞれの記事が複数の文で構成されているため、大量の文章が手に入りました。
モデルをビジネス活用する際には、過半数の文に誤りが含まれない事が想定されます。そのような文は「誤り無し」とモデルに判別してもらいたい訳ですが、例えば学習用データ全文に必ず誤りが含まれるようだと、誤り無しの文を正しく判別できない事が予想されます。
そのため誤り無し文章も用意する必要があり、上記GoogleのWiki-40Bデータから同じく作成しました*5。
今回は、文字毎にトークナイズ(理由は後ほどご説明します)をし、以下の表に従ってラベルを付けていきました。
| 正解 | 誤字 | 脱字 | 句点抜け | 読点抜け | 衍字 | 転字 | 漢字誤変換 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
以下、各ラベル毎のラベル付け方法です。
正解・誤字・衍字・転字・漢字誤変換の場合
それぞれの該当箇所にラベリングします。
例えば「私はは走る。」という衍字(ラベル=5)誤り文があったとすると、以下のようにラベル付けします。
| トークン | 私 | は | は | 走 | る | 。 |
|---|---|---|---|---|---|---|
| ラベル | 0 | 0 | 5 | 0 | 0 | 0 |
脱字・句点抜け・読点抜けの場合
抜けている箇所の直後の文字にラベルを付けます。
例えば「今日か春休みだ。」(正解は「今日から春休みだ。」)という脱字(ラベル=2)誤り文があったとすると、以下のようにラベル付けします。
| トークン | 今 | 日 | か | 春 | 休 | み | だ | 。 |
|---|---|---|---|---|---|---|---|---|
| ラベル | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 |
句点抜け、読点抜け、衍字、転字については、ラベル付けされたトークンやその周辺を適宜処理します(ex. 句点抜けとラベル付けされたら、その直前に「。」を挿入する)。
それ以外の誤字、脱字、漢字誤変換については、ラベル付けされた箇所やその前(脱字の場合)のトークンを[MASK]に変換し、その[MASK]を予測します。
(単位 : 件)
| 誤り無し | 誤字 | 脱字 | 句点抜け | 読点抜け | 衍字 | 転字 | 漢字誤変換 |
|---|---|---|---|---|---|---|---|
| 472,770 | 60,300 | 90,450 | 10,050 | 35,175 | 85,425 | 5,025 | 165,825 |
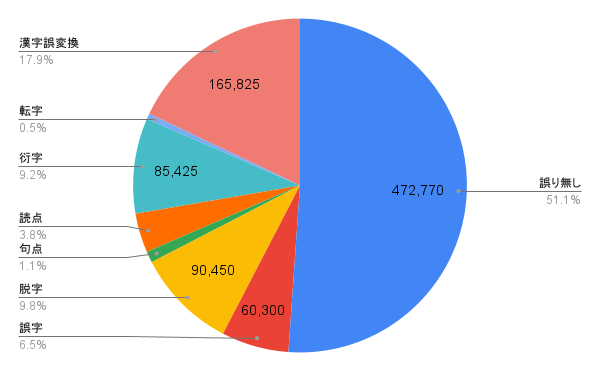
誤り無し文章の分類精度を上げるためには、かなり多くの文章数が必要でした。また、誤り無し、句点抜け、読点抜け以外については元々の京都大学のデータセットの比率に依存しており、転字が少なく、漢字誤変換が多いです。
今回は、文字毎にトークナイズ・学習をさせたモデルを使用しました。例えば「改めて」という文があった場合、[‘改’, ‘め’, ‘て’]のようにトークナイズされます。理由は、文字毎で無い場合、トークナイズのされ方によっては誤りのラベル付けが変わってしまう等で扱いづらいためです*6。
Huggingfaceで’japanese-char’と検索すると学習済みモデルが複数ヒットします。今回、具体的には
cl-tohoku/bert-base-japanese-charと
ku-nlp/deberta-v2-large-japanese-char-wwm *7の2種類を使用させてもらいました。
基本的なコードの流れは下記のtoken-classificationを参考にしました。
github.com
今回はmacro-F1を使用しました。以下、具体例でご説明します。
例えば「私はは走る。」という誤り文(衍字)があったとすると、以下の手順で評価をします(簡単のため、ラベル5についてのF1値計算で説明します)。
1.誤り毎に以下のようにラベルをセッティングしておく
| 正解 | 誤字 | 脱字 | 句点抜け | 読点抜け | 衍字 | 転字 | 漢字誤変換 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
2. 文の単語のラベルを定義する
{‘私’ : 0, ‘は’ : 0, ‘は’ : 5, ‘走’ : 0, ‘る’ : 0, ‘。’ : 0}
3. 予測値を出し、 F1値を出す
| 予測 | 正解 | F1値 |
|---|---|---|
| [5,0,0,5,0,0] | 0,0,0,5,0,0] | 0.67 |
今回は0ラベルを除いた7つのラベルのmacro-F1をモデルの評価に使用しました。0ラベルが非常に多く、それ含めてしまうと0のF1値が極端に高くなり、全体のmacro平均値に外れ値としての影響が出てしまうためです。
今回はFocal Lossを使用しました。
Focal Lossは不均衡データや、ラベルを予測するのが難しい時に効果を発揮します。今回はそのどちらにもあてはまるだろうと考えました。
参考までに、以下はFocal Lossの式になります。αはカテゴリ毎に損失を変えたい時、γは少なくて予測が難しい例に対しての損失を相対的に大きくしたい時の調整パラメータです。
$$FL(p_t) = -α_t(1 – p_t)^γlog(p_t)$$
結果から言いますと、γはあまり効果がありませんでしたが、αはかなり大きな効果がありました(macro-F1 0.596→0.64)。
以下、学習*8後の各モデルの精度比較です。
| all | 誤字 | 脱字 | 句点抜け | 読点抜け | 衍字 | 転字 | 漢字誤変換 | TN_rate | |
|---|---|---|---|---|---|---|---|---|---|
| BERT | 0.73 | 0.69 | 0.77 | 0.86 | 0.61 | 0.85 | 0.55 | 0.75 | 0.65 |
| DeBERTa | 0.70 | 0.66 | 0.76 | 0.88 | 0.60 | 0.84 | 0.46 | 0.72 | 0.78 |
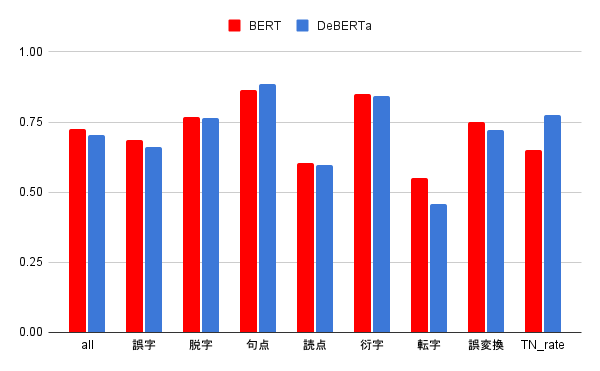
「all」はmacro-F1、各誤りの数値はそれぞれのF1値を表します。「TN_rate*9」は、誤りの無い文に対して全てのトークンを「0」と予測できた割合(=正解率)です。
見ると、BERTに比べてDeBERTaはall(macro-F1)が下がっています。個別に見ると、特に転字が大きく下がっています。その一方TN_rateは大きく上がっています。
今回は誤りをしっかり予測できるかどうかに重きを置き、BERTの方のモデルを採用する事にしました。
今回は用意した文章を学習用・検証用・テスト用(Chat GPTとの精度比較で使用)に分けていますが、参考までに、検証用データのラベルや予測値から成る各混同行列(heatmap)を載せておきます。*10
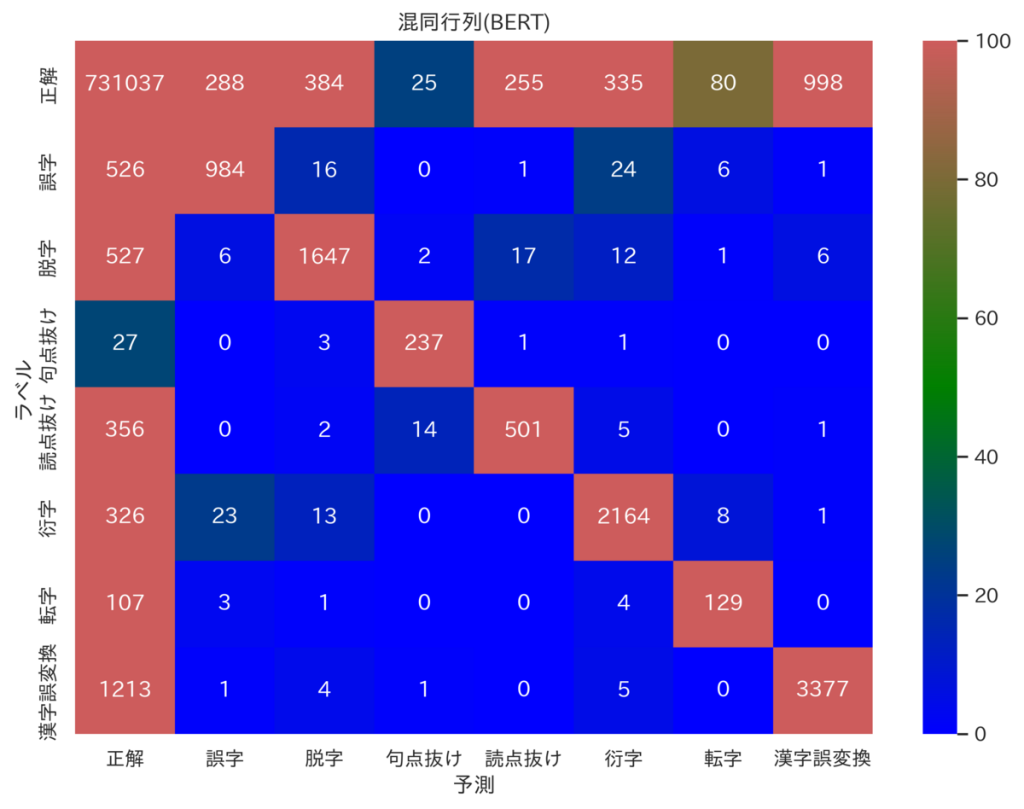
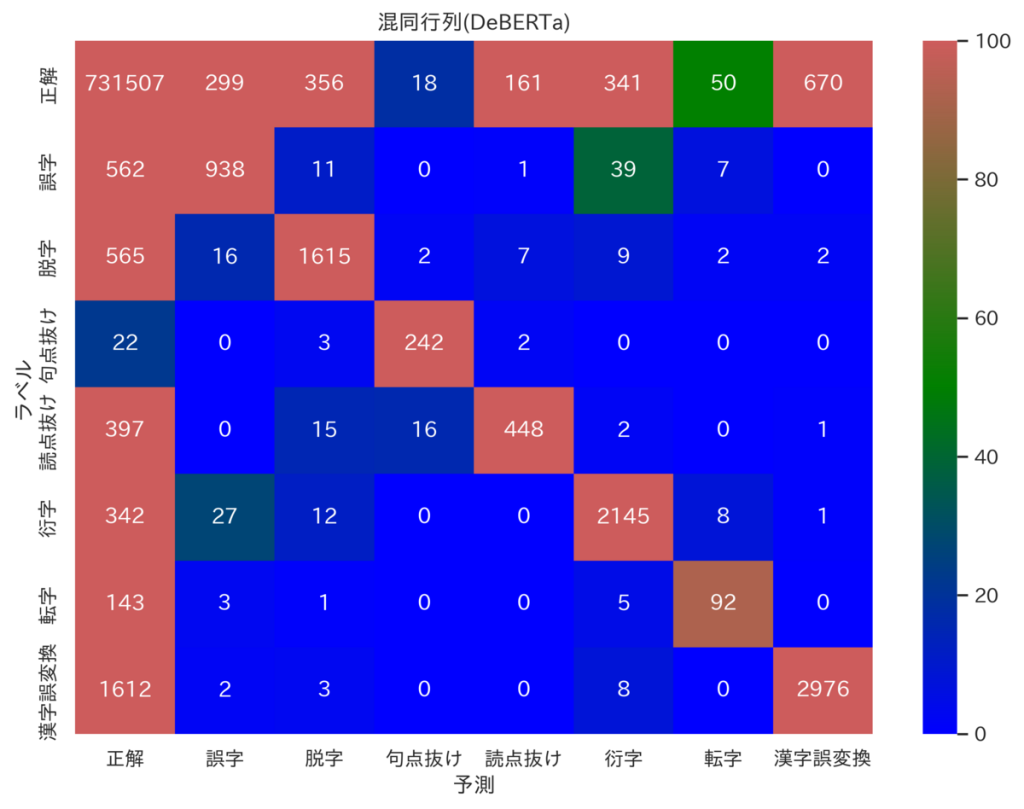
見ると、誤りを正確に予測できている一方、間違って「正解」と予測してしまっているケース(一列目二行目以降)が多い事が分かります。
ここでは、BERTがラベル付けを間違った例を具体的にご紹介します。
まずは、最も多かった、間違って0(正解)と予測してしまった例です。つまり、「誤りではない」とモデルが間違って判断してしまったものです。
皆さんも、ぜひ入力文のどこが誤っているのか考えてみて下さい。
| 入力文 | ラベル付け(正解) | ラベル(正解) | 正解文 |
|---|---|---|---|
| サミュエル・ド・シャンプレン | サ : 0, ミ : 0, ュ : 0, エ : 0, ル : 0, ・ : 0, ド : 0, ・ : 0, シ : 0, ャ : 0, ン : 0, プ : 0, レ : 1, ン : 0 | 1(誤字) | サミュエル・ド・シャンプラン |
| 長年の全国実業諸団体運動が実り | 長 : 0, 年 : 0, の : 0, 全 : 0, 国 : 0, 実 : 0, 業 : 0, 諸 : 0, 団 : 0, 体 : 0, 運 : 2, 動 : 0, が : 0, 実 : 0, り : 0 | 2(脱字) | 長年の全国実業諸団体の運動が実り |
| イーダ・ラウバーと一緒に暮らしていた高校・大学と地元ウィルミントンで学んだ。 | 一 : 0, 緒 : 0, に : 0, 暮 : 0, ら : 0, し : 0, て : 0, い : 0, た : 0, 高 : 3, 校 : 0, ・ : 0, 大 : 0, 学 : 0, と : 0 | 3(句点抜け) | イーダ・ラウバーと一緒に暮らしていた。高校・大学と地元ウィルミントンで学んだ。 |
| 本殿鳥居からなる地域の神社。 | 本 : 0, 殿 : 0, 鳥 : 4, 居 : 0, か : 0, ら : 0, な : 0, る : 0, 地 : 0, 域 : 0, の : 0, 神 : 0, 社 : 0, 。 : 0 | 4(読点抜け) | 本殿、鳥居からなる地域の神社。 |
| 騒がわしい雑音を出して | 騒 : 0, が : 0, わ : 5, し : 0, い : 0, 雑 : 0, 音 : 0, を : 0, 出 : 0, し : 0, て : 0 | 5(衍字) | 騒がしい雑音を出して |
| ナイレンの脳転写手術中に | ナ : 0, イ : 6, レ : 6, ン : 0, の : 0, 脳 : 0, 転 : 0, 写 : 0, 手 : 0, 術 : 0, 中 : 0, に : 0 | 6(転字) | ナレインの脳転写手術中に |
| 『秦始皇帝本紀』に登場する徐市は | 『 : 0, 秦 : 0, 始 : 0, 皇 : 0, 帝 : 0, 本 : 0, 紀 : 0, 』 : 0, に : 0, 登 : 0, 場 : 0, す : 0, る : 0, 徐 : 0, 市 : 7, は : 0 | 7(漢字誤変換) | 『秦始皇帝本紀』に登場する徐氏は |
「騒がわしい」が衍字だと判断できなかったといった明らかなミスもありますが、概ね、間違えてもあまり不思議では無く、我々人間が取り組んでも間違えてしまうような例が多い印象でした。
また参考までに、少数ではありますが、間違って1-7のいずれかと予測してしまった例も挙げてみたいと思います。
ちなみに「解説」は、BERTがどのような判断をしたかについてです。
| 入力文 | ラベル付け(正解) | ラベル(正解) | ラベル付け(予測) | ラベル(予測) | 解説 |
|---|---|---|---|---|---|
| イギリスウェールズ人エドワード・ガントレットと | イ : 0, ギ : 0, リ : 0, ス : 0, ウ : 0, ェ : 0, ー : 0, ル : 0, ズ : 0, 人 : 0 | 0(正解) | イ : 0, ギ : 0, リ : 0, ス : 0, ウ : 2, ェ : 0, ー : 0, ル : 0, ズ : 0, 人 : 0 | 2(脱字) | 誤りは含まれないが、「イギリス」と「ウェールズ」の間が抜けているとモデルは判断。 |
| 1944年5月2日バラオ諸島の | 1 : 0, 9 : 0, 4 : 0, 4 : 0, 年 : 0, 5 : 0, 月 : 0, 2 : 0, 日 : 0, バ : 1, ラ : 0, オ : 0, 諸 : 0, 島 : 0, の : 0 | 1(誤字) | 1 : 0, 9 : 0, 4 : 0, 4 : 0, 年 : 0, 5 : 0, 月 : 0, 2 : 0, 日 : 0, バ : 4, ラ : 0, オ : 0, 諸 : 0, 島 : 0, の | 4(読点抜け) | 「パラオ」が正解だが、「1944年5月2日」と「バラオ諸島」の間に読点が抜けていると判断。 |
| 使徒継承のある正教会教会ではあるが、 | 正 : 0, 教 : 0, 会 : 0, 教 : 2, 会 : 0, で : 0, は : 0, あ : 0, る : 0, が : 0, 、 : 0 | 2(脱字) | 正 : 0, 教 : 0, 会 : 0, 教 : 5, 会 : 5, で : 0, は : 0, あ : 0, る : 0, が : 0, 、 : 0 | 5(衍字) | 「正教会は協会ではあるが」が正解だが、2つ目の「協会」が余分と判断。 |
| 掃除機のような形をしたロケット掃除したい場所に解き放つと、 | 形 : 0, を : 0, し : 0, た : 0, ロ : 0, ケ : 0, ッ : 0, ト : 0, 掃 : 3, 除 : 0, し : 0, た : 0, い : 0 | 3(句点抜け) | 形 : 0, を : 0, し : 0, た : 0, ロ : 0, ケ : 0, ッ : 0, ト : 0, 掃 : 2, 除 : 0, し : 0, た : 0, い : 0 | 2(脱字) | 「形をしたロケット。掃除したい」が正解だが、「ロケット」と「掃除したい」の間に何かが抜けていると判断。 |
| 距離は間隙や環の中央までの値である。 | 距 : 0, 離 : 0, は : 0, 間 : 4, 隙 : 0, や : 0, 環 : 0, の : 0, 中 : 0, 央 : 0, ま : 0, で : 0, の : 0, 値 : 0, で : 0, あ : 0, る : 0, 。 : 0 | 4(読点抜け) | 距 : 0, 離 : 0, は : 0, 間 : 7, 隙 : 0, や : 0, 環 : 0, の : 0, 中 : 0, 央 : 0, ま : 0, で : 0, の : 0, 値 : 0, で : 0, あ : 0, る : 0, 。 : 0 | 7(漢字誤変換) | 「距離は、間隙や」が正解だが、「間」が何かの漢字と間違っていると判断。 |
| 絵画の中に閉じ込められいたが、 | 絵 : 0, 画 : 0, の : 0, 中 : 0, に : 0, 閉 : 0, じ : 0, 込 : 0, め : 0, ら : 0, れ : 0, い : 5, た : 0, が : 0 | 5(衍字) | 絵 : 0, 画 : 0, の : 0, 中 : 0, に : 0, 閉 : 0, じ : 0, 込 : 0, め : 0, ら : 0, れ : 0, い : 2, た : 0, が : 0 | 2(脱字) | 「閉じ込められたが」が正解だが、「閉じ込められ」と「いたが」の間が抜けていると判断。 |
| フリル人の宗教や | フ : 0, リ : 6, ル : 6, 人 : 0, の : 0, 宗 : 0, 教 : 0, や : | 6(転字) | フ : 0, リ : 0, ル : 1, 人 : 0, の : 0, 宗 : 0, 教 : 0, や : 0 | 1(誤字) | 「フルリ人」が正解だが、「フリル」の「ル」が何かと間違っていると判断。 |
| 「点検表か報告書」には | 「 : 0, 点 : 0, 検 : 0, 表 : 7, か : 7, 報 : 0, 告 : 0, 書 : 0, 」 : 0, に : 0, は : 0, | 7(漢字誤変換) | 「 : 0, 点 : 0, 検 : 0, 表 : 0, か : 5, 報 : 0, 告 : 0, 書 : 0, 」 : 0, に : 0, は : 0 | 5(衍字) | 「評価報告書」が正解だが、「表か報告書」の「か」が余分と判断。 |
これらも全体的に人間でも判断に迷うようなものが多く、間違えても仕方のないような所を間違えているのが分かります。
今回は学習にあたって工夫をしたのはFocal Lossのγ・αやモデルの変更だけでしたが、バッチサイズや学習率の調整等細かいハイパーパラメータの調整で精度がさらに伸びる可能性は十分にあります。
また、GoogleのWiki-40Bから句点や読点、誤り無し文章をさらに持ってくることも可能ですしかし、誤り文章(何かしら誤りが含まれる)を増やすと、macro-F1が上がる一方TN_rateが下がります。またその逆も見受けられます。なので、どちらの精度を上げたいかに応じて文章数を調整する必要があるようです。
今回はBERTを用いた誤り文修正について、特にラベリングのモデル構築にフォーカスしてお伝えしました。
ある程度時間をかけて構築されたモデルですが、それでは果たしてChat GPTの精度を超える事ができるのでしょうか?
次回、いよいよ比較していきたいと思います。
実は本記事の中に、意図的に3カ所入力誤りを含めておきました。
もし気づかれなかった方は、ぜひ探してみて下さいね。
| 誤り文 | 正解文 | 誤りの種類 | 場所 |
|---|---|---|---|
| 間違の種類は | 間違いの種類は | 脱字 | 2-2. 概要 |
| 待ってきている | 持ってきている | 漢字誤変換 | 4-2. 句点抜け・読点抜けデータ |
| 可能ですしかし | 可能です。しかし | 句点抜け | 8. 改善案 |
*1:以下の論文に、より詳しく記載されています。
Wikipediaの修正履歴を用いた 日本語入力誤りデータセットの構築
日本語 Wikipedia の編集履歴に基づく 入力誤りデータセットと訂正システムの改良
*2:ラベリングモデルは挟まず、このモデル②のみで一気に文を修正する手法もあります。しかし、これはあくまで「穴埋め」のために学習されており、脱字や転字といった誤りを検知する事はできないと考えられます。汎用的な誤り文修正モデルのために、今回はラベリングモデルと組み合わせました。
*3:ライセンスはサイト記載の通りCC BY-SAで、商用利用等が可能です。
*4:ライセンスは上記京都大学のデータと同じくCC BY-SAです。こちらの論文からご確認いただけます。
*5:京都大学・GoogleともにWikipediaから持ってきているためリークの可能性がありますが、学習の前にチェックをしてあります。
*6:例えば「見られた」を「見らた」と誤っているとします(脱字)。もしトークナイズ後「見」と「らた」に分かれた場合、「らた」に脱字ラベルを付けたい所ですが、そうなると「見」と「らた」の間に何かが抜けている、という事になり修正できません。この場合は、「らた」を脱字でなく誤字とみなす事で対応可能ですが、そうなるとラベルが変わってしまいます。
*7:こちらのライセンスも両方CC BY-SAです。
*8:GPUはGTX 1080 Tiを使用。BERTは1,485分(約1日)、DeBERTaは2,858分(約2日)かかりました。
*9:TNはTrue Negativeの略
*10:各F1値はこの混同行列からも算出できますが、TN_rateは別途算出しました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













