

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
BERTとChat GPTの精度比較に関する記事を全2回でお届けします。連載の第2回はChat GPT(GPT4)を用いて同様のタスクに取り組んだ結果と、BERTとChat GPTの精度比較についてご紹介します。
ブレインパッドでデータサイエンティストとして働いている鈴木といいます。
前回の連載①ではBERTを用いた日本語誤り文修正モデルについてご説明しました。今回の連載②では、Chat GPT(GPT4)を用いて同様のタスクに取り組んだ結果と、両者の精度比較についてご説明します。
すぐに精度比較結果を知りたい方は、「6-1-3. 精度比較」のセクションからごいただけます。
TransformerのEncoderをベースにしたBERTやそこから派生したモデルは、まず大規模データにより事前学習を行い、その後ファインチューニングにより各下流タスク*1に適応しています。
一方、LLMはより大きな規模のデータにより事前学習を行っており、ファインチューニング無しに各種タスクを精度良くこなすことができます。
LLMの代表であるChat GPTは、果たしてファインチューニング済のBERTによる下流タスクのパフォーマンスも凌駕するのでしょうか?それを今回は検証してみました。
具体的には、連載①でBERTにより構築した日本語誤り文修正モデルとChat GPT、それぞれに誤り文修正タスクに取り組んでもらいました。
連載①で使用したデータのうち、学習にも検証にも使用していないテストデータを使用しました。
誤り無しも含めた各カテゴリ8つ(誤字、脱字、句点抜け、読点抜け、衍字、転字、漢字誤変換、誤り無し)から100件ずつ、合計800件取り出して来ています。
以下のような流れで行いました。
1. BERT、Chat GPTそれぞれでテストデータ800件について誤り文修正タスクを行う
2. 各カテゴリで、正しく修正できた(誤り無しの場合は何も手を加えなかった)割合を算出
3. 結果を比較
ここからは、どのようにChat GPTのプロンプトを入力したか、また得られた出力についてご説明します。
以下、プロンプト作成にあたって工夫した点です。
連載①でご説明したBERTでは、各文をラベル付けした後に修正を行っていました。Chat GPTでは、そのように「誤りラベル付け→ラベル別に適切に処理」というプロンプトを入力すると複雑になり過ぎてしまい、うまく処理ができませんでした。そのため、以下のように具体例を交えてなるべくシンプルにタスクに取り組んでもらいました。

文字数の限界があるのでバッチで複数に分けてプロンプトを入力しました。
しかし、単純に「以下についても誤りがあれば修正してください。 」というプロンプトで続けていくと、ある時点からChat GPTの修正度合いが上がり、誤り修正に限らず文にアレンジを加えるようになりました。


そのため、毎回のプロンプト毎に改めて指示文を入れるようにした所、そのような挙動は無くなりました。
以前出力した修正文も併せて出力してしまう事がありました。

そのため「前回修正してもらった文は出力しなくて大丈夫です。」と加えました。ただ、多少減った気はするものの、これでも同様に前回の修正文を出力してしまう事がありました。文言がどの程度効果があったのかは検証できていません。
以上を踏まえて、最終的に使用したプロンプトは以下になります。*2

以下は、Chat GPTの出力のうち特徴的だったものです。

それまでは「・」で箇条書きしていたのに、急に数字で箇条書きを始める事がありました。

修正後の文だけでなく、入力文も一緒に出力し始める事がありました。
急に修正文の間に行間を空け始めた事がありました。
特にこちらからは何もしませんでしたが、なぜか次の出力から元に戻りました。
| 入力文 | 正解文 | Chat GPT |
|---|---|---|
| wikipedia編集方針より、 | wikipedia編集方針より、 | Wikipedia編集方針より、 |
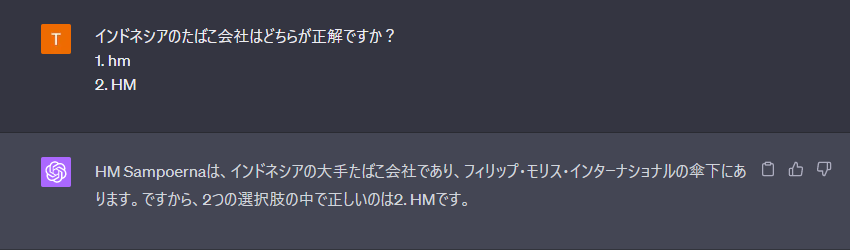
| インドネシアのタバコ会社であるpt・hm・サンプルナを | インドネシアのタバコ会社であるpt・hm・サンプルナを | インドネシアのタバコ会社であるpt・hm・サンプルナを |
表のwikipedia→Wikipediaのように、英語の小文字を大文字に変換する事があります。しかし、例えばインドネシアのたばこ会社のHMは、正式名称が大文字であるにも関わらず、Chat GPTはhmのまま出力しています。
‘Wikipedia’という固有名詞は学習されており、’HM’は学習されていないためかと思って聞いてみましたが、そうでもないようです。
| 入力文 | 正解文 | Chat GPT |
|---|---|---|
| バルザニの一族はクルディスタンで複数の企業を所有しており、何十億$もの資産を持っていた。 | バルザニの一族はクルディスタンで複数の企業を所有しており、何十億$もの資産を持っていた。 | バルザニの一族はクルディスタンで複数の企業を所有しており、何十億$もの資産を持っている。 |
こちらは誤り無しの文ですが、Chat GPTは時制を「持っている」と現在形に修正しています。確かに現在の話のようにも思えますが、元のWikipedia*3を参照すると、以下のような意味合いのようです。
(現在)バルザニの一族はクルディスタンで複数の企業を所有しており、(当時は)何十億$もの資産を持っていた。
そのため入力文の時制は合っているという事になりますが、Chat GPTの気持ちも良く分かります。
日本語の時制のあいまいさが分かる一例だと思いました。
| 入力文 | 正解文 | Chat GPT |
|---|---|---|
| 専門課程園芸学科と専門課程のフラワービジネス学科が設置されており、 | 専門課程の園芸学科と専門課程のフラワービジネス学科が設置されており、 | 専門課程の園芸学科とフラワービジネス学科が設置されており、 |
これは脱字の文(専門課程と園芸の間に「の」が抜けている)ですが、Chat GPTはそこを修正しただけでなく、「園芸学科」と「フラワービジネス学科」が同じ「専門課程」だという事から、2つをまとめています。
良く言われる、Chat GPTは意味を把握しているのでは?という議論はこういう所から来ているのでは無いかと思います。
ここからは、BERTとChat GPTを具体的に比較していきます。
精度比較結果をお見せする前に、評価方法について簡単にお伝えします。
今回、各出力が「正解」か「不正解」でラベル付けをし、正解率(accuracy)を出しています。
例えばスコアが0.5だったとすると、これは100個のうち50個で「正解」だった、という事です。
今回は、誤り文と誤り無し文で「正解」かどうかの基準を分けています。
誤り文については、「誤りの部分が想定通り修正されている」場合は「正解」、それ以外を「不正解」としました。
誤り以外の部分に手を加えていても、「誤りの部分が想定通り修正されている」のであれば「正解」としてあります。
というのも、Chat GPTは以下のように、誤り以外の部分にも手を加えてしまう事が多かったためです。
(太字が誤り箇所、赤字は手を加えている箇所です)
| 入力文 | 正解文 | Chat GPT | 解説 |
|---|---|---|---|
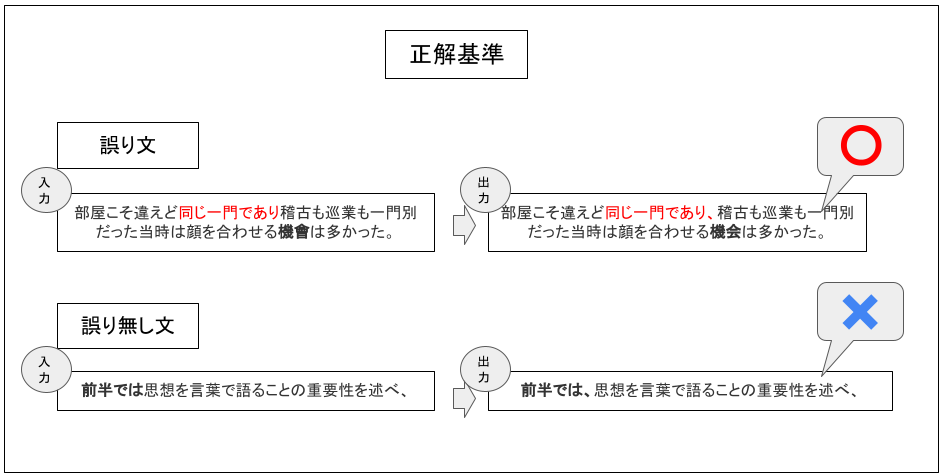
| 部屋こそ違えど同じ一門であり稽古も巡業も一門別だった当時は顔を合わせる機會は多かった。 | 部屋こそ違えど同じ一門であり稽古も巡業も一門別だった当時は顔を合わせる機会は多かった。 | 部屋こそ違えど同じ一門であり、稽古も巡業も一門別だった当時は顔を合わせる機会は多かった。 | 読点を加えている。 |
| 原作とアニメ両方とものび太がまた悪戯で使用した為、…ドラえもんは「少しは懲りた方がいんじゃない」と呆れた。 | 原作とアニメ両方とものび太がまた悪戯で使用した為、…ドラえもんは「少しは懲りた方がいいんじゃない」と呆れた。 | 原作とアニメ両方でのび太がまた悪戯で使用したため、…ドラえもんは「少しは懲りた方がいいんじゃない」と呆れた。 | 「為」を「ため」と修正している。 |
そのため、「正解」の条件が「誤り以外の部分も入力文と同じ」としてしまうと、Chat GPTの精度が非常に下がってしまいました。
今回の主旨は「誤りの修正」のため、誤りの部分が想定通り修正されていれば「正解」としました。
誤り無しについては、入力文に全く手を加えないというのが条件のため、入力文と全く同じ時は「正解」、少しでも修正されているようであれば「不正解」としました。BERTの場合も同じです。
それでは、BERTとChat GPTの精度比較をお見せしたいと思います。
| 全体 | 誤字 | 脱字 | 句点抜け | 読点抜け | 衍字 | 転字 | 漢字誤変換 | 誤り無し | |
|---|---|---|---|---|---|---|---|---|---|
| BERT | 0.63 | 0.51 | 0.66 | 0.90 | 0.57 | 0.86 | 0.35 | 0.48 | 0.71 |
| Chat GPT | 0.50 | 0.61 | 0.55 | 0.50 | 0.56 | 0.73 | 0.35 | 0.22 | 0.45 |
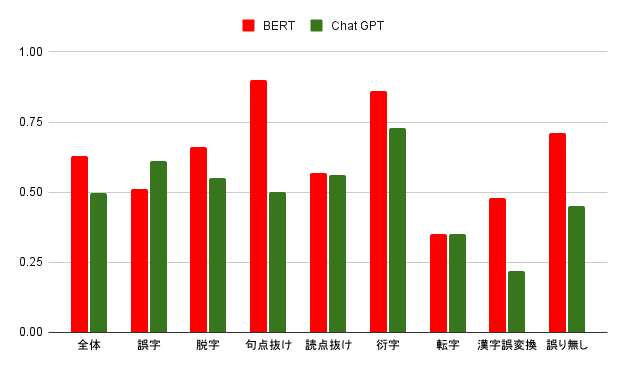
全体で見ると、BERTの方が10%ほど精度が高いです。
個別に見ると脱字・句点抜け・衍字・漢字誤変換・誤り無しにおいて差が開いていますが、句点抜け・漢字誤変換・誤り無しにおいては特に開きが顕著です。
一方、誤字はChat GPTの方が10%精度が高いです。
次は、これについて具体例を見ながら検証してみたいと思います。
まず、BERTの方が精度が良かったカテゴリにおいて、BERTが「正解」でChat GPTが「不正解」だったものを見てみたいと思います。
修正された箇所を太字にしてあります。
また、「解説」は、Chat GPTがどのような判断をしたかについてです。
| 入力文 | 正解文(=BERT) | Chat GPT | 解説 |
|---|---|---|---|
| このフォーマットは、各年に記事がある20世紀以降のものみです。 | このフォーマットは、各年に記事がある20世紀以降のもののみです。 | このフォーマットは、各年に記事がある20世紀以降のものです。 | 「ものみです。」を「ものです。」と修正。 |
| …衆院議員2010年7月、…「おれをだれだと思っているのか」と恫喝発言していたことも政権批判の遠因かとされる。 | …衆院議員が2010年7月、…「おれをだれだと思っているのか」と恫喝発言していたことも政権批判の遠因かとされる。 | …衆院議員は2010年7月、…「おれをだれだと思っているのか」と恫喝発言していたことも政権批判の遠因かとされる。 | 「が」で無く「は」を当てはめている。 |
| 入所・出所時は厳重に管理されいる所が殆どである。 | 入所・出所時は厳重に管理されている所が殆どである。 | 入所・出所時は厳重に管理される所が殆どである。 | 「管理されいる」を「管理される」と修正。 |
全体的に誤りの箇所は指摘できており、文法としても間違っていないものが多いですが、微妙なニュアンスが変わってしまっている印象です。
| 入力文 | 正解文(=BERT) | Chat GPT | 解説 |
|---|---|---|---|
| 2014年、宝塚音楽学校入学第102期生。 | 2014年、宝塚音楽学校入学。第102期生。 | 2014年、宝塚音楽学校入学、第102期生。 | 読点抜けと判断。 |
| 2005年にトップに昇格し正式にプロ契約を結んだ同期に、前田、佐藤…がいる。 | 2005年にトップに昇格し正式にプロ契約を結んだ。同期に、前田、佐藤…がいる。 | 2005年にトップに昇格し正式にプロ契約を結んだ同期に、前田、佐藤…がいる。 | 誤り無しと判断し変更せず。 |
| デンマーク・ユトランド半島東岸にある湾主に東西方向に伸びており、 | デンマーク・ユトランド半島東岸にある湾。主に東西方向に伸びており、 | デンマーク・ユトランド半島の東岸にある湾で、主に東西方向に伸びており、 | 「で、」が抜けていると判断し挿入。 |
| ヤロスラヴリに引っ越した1911年にギムナジウムを卒業し、 | ヤロスラヴリに引っ越した。1911年にギムナジウムを卒業し、 | ヤロスラヴリに引っ越し、1911年にギムナジウムを卒業し、 | 「引っ越した」を「引っ越し、」に変換。 |
こちらも全体的に誤りの箇所は指摘できていますが、句点の代わりに読点を入れる事が多い印象です。
| 入力文 | 正解文(=BERT) | Chat GPT | 解説 |
|---|---|---|---|
| ゴビ砂漠にて基地防衛防衛。 | ゴビ砂漠にて基地防衛。 | ゴビ砂漠にて基地防衛行動。 | 「防衛」を衍字とせず、漢字誤変換としている。 |
| 最終戦で中村との直接対決を制し、3位となりc級1組への昇級。 | 最終戦で中村との直接対決を制し、3位となりc級1組へ昇級。 | 最終戦で中村との直接対決を制し、3位となりc級1組への昇級。 | 誤り無しと判断し変更せず。 |
| 1979年の日本シリーズは、第30回プロ野球の日本選手権シリーズである。 | 1979年の日本シリーズは、第30回プロ野球日本選手権シリーズである。 | 1979年の日本シリーズは、第30回プロ野球の日本選手権シリーズである。 | 誤り無しと判断し変更せず。 |
| 本名はの伊藤輝男「いとうてるお」はテリー伊藤の本名と同音異字である。 | 本名の伊藤輝男「いとうてるお」はテリー伊藤の本名と同音異字である。 | 本名は伊藤輝男「いとうてるお」はテリー伊藤の本名と同音異字である。 | 「は」ではなく「の」を除いている。 |
意味が通るように修正しているものもあれば、一見間違っていないもののよく見ると意味が通らない文に修正しているようなケースも見受けられました。
| 入力文 | 正解文(=BERT) | Chat GPT | 解説 |
|---|---|---|---|
| かつては大きな木造駅舎があったが平成元年に現在の簡易なものに立て替えられた。 | かつては大きな木造駅舎があったが平成元年に現在の簡易なものに建て替えられた。 | かつては大きな木造駅舎があったが、平成元年に現在の簡易なものに立て替えられた。 | 誤り無しと判断。 |
| 述べ400人以上が犠牲となった。 | 延べ400人以上が犠牲となった。 | 述べ400人以上が犠牲となった。 | 誤り無しと判断。 |
| かつて活動拠点としていたアニメ製作会社。 | かつて活動拠点としていたアニメ制作会社。 | かつて活動拠点としていたアニメ製作会社。 | 誤り無しと判断。 |
| なお、その会のクイズの内容は「キノコ全般」であった。 | なお、その回のクイズの内容は「キノコ全般」であった。 | なお、その会のクイズの内容は「キノコ全般」であった。 | 誤り無しと判断。 |
全体的に誤りに気付かず、そのままにする傾向にあります。
ちなみに、これらのうちいくつかで、入力文(誤り文)・正解文のどちらが正しいかを直接聞いてみた所、以下のような返答でした。

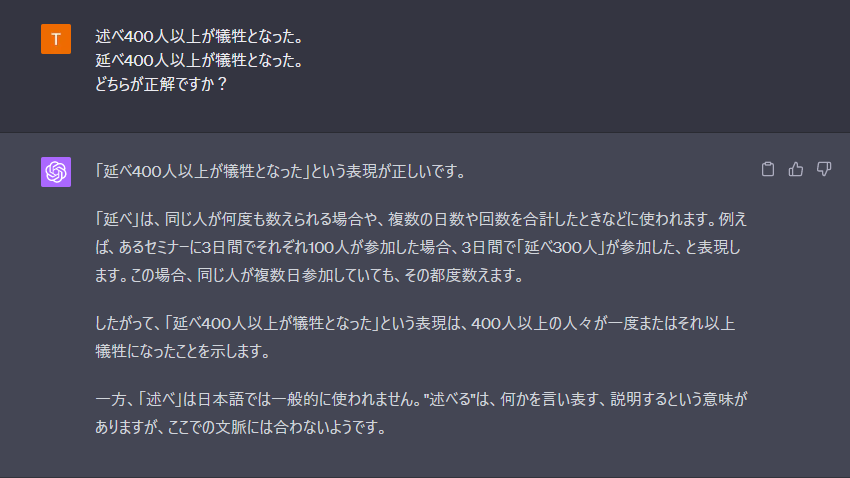
「延べ」については正しい回答ですが、「建て替え」についてはやはり「立て替え」でも大きな違いは無い、という誤った回答(いわゆるハルシネーション)を返しています。
| 入力文( = 正解文 =BERT) | Chat GPT | 解説 |
|---|---|---|
| 前半では思想を言葉で語ることの重要性を述べ、 | 前半では、思想を言葉で語ることの重要性を述べ、 | 読点を挿入している。 |
| 報道機関として厳しい処分を行い、そして「政府その他外部からの干渉は一切ない」と述べた。 | 報道機関として厳しい処分を行い、「政府その他外部からの干渉は一切ない」と述べた。 | 「そして」を除いている。 |
| だが催眠術がかけられているとも知らず、…再びナダイアの手に落ちてしまう。 | だが、催眠術がかけられていることを知らず、…再びナダイアの手に落ちてしまう。 | 「だが」の後に読点を挿入。また「とも知らず」を「ことを知らず」に修正。 |
「誤りが含まれる場合は修正」して欲しいとプロンプトで明言していますが、明らかに誤りとは言えない所でも、修正を加えてしまっている事が多いようです。
ここまでBERTの方が精度の良かったカテゴリの具体例でしたが、次は逆にChat GPTの方が精度の良かった、誤字の具体例を見てみましょう。
ここでは、BERTが「不正解」でChat GPTが「正解」だったものを載せています。
ここでの「解説」は、BERTがどのような判断をしたかについてです。
| 入力文 | 正解文(= Chat GPT) | BERT | 解説 |
|---|---|---|---|
| 国際プロレス時代の縁から…ジァイアント・マシーンのマネージャーに起用された。 | 国際プロレス時代の縁から…ジャイアント・マシーンのマネージャーに起用された。 | 国際プロレス時代の縁から…ジァイアント・マシーンのマネージャーに起用された。 | 誤り無しと判断し変更せず。 |
| デレビ受像機を含めた家電製品が | テレビ受像機を含めた家電製品が | デレビ受像機を含めた家電製品が | 誤り無しと判断し変更せず。 |
| パイロット・テン・インターナショナルという大会が開かれる。 | パイロット・ペン・インターナショナルという大会が開かれる。 | パイロット・テン・インターナショナルという大会が開かれる。 | 誤り無しと判断し変更せず。 |
| セインはもともとサバーバン・レジェンヅのベーシストだった。 | セインはもともとサバーバン・レジェンズのベーシストだった。 | セインはもともとサバーバン・レジェンドのベーシストだった。 | 「ヅ」を「ド」と修正。 |
| セカンドシングル「エケスペクト」を発売。 | セカンドシングル「エクスペクト」を発売。 | セカンドシングル「エケスペクト」を発売。 | 誤り無しと判断し変更せず。 |
シンプルに誤字を検出できていないケースが多いですが、中でも特にカタカナの精度が低いようです。
実際、カタカナ誤字に絞った精度を見ると、以下のようになりました。*4
| 誤字 | カタカナ誤字 | |
|---|---|---|
| BERT | 0.51 | |
| Chat GPT | 0.61 |
データ件数が少ないのではっきりした事は言えませんが、誤字全体の精度と比較すると、今回学習したBERTがカタカナの誤字修正に弱い、と言えるように思えます。
どうやら、誤り文修正というタスクにおいては、従来の手法であるBERTに軍配が上がるようです。
具体的には、Chat GPTの出力には以下のような例が多かった印象です。
・誤りが無いのに手を加えてしまう。
・句点を入れるべきところに読点を入れる。
・漢字誤変換を検出・変換できない。
また、Chat GPTは意味が通らないような文は絶対に出力しないのかと思いきや、意外とそういった文を出力する事もあるようです。
しかし、今回構築したBERTは誤字、特にカタカナ誤字に弱いようで、その点ではChat GPTが上回っていました。
今回の検証の結果、Chat GPTは文章を自由に生成する事に長けている反面、入力文を忠実に再現しつつそこから微調整を加える、といったタスクは苦手だという事が分かりました。
これは、例えば日頃個人レベルで、「以下の文章に文法ミスがあったら修正して」といったタスクを投げる際にも注意が必要な点だと思います。
一方、BERTの構築は一連の調査、準備、そして実験を伴います。それに比べると、多少精度は下がってもChat GPTでタスクに取り組むというのも一つだと思います。
ただ、Chat GPTはBERTよりもはるかに推論に時間がかかるため、大量の文章に対しては適切ではないと思われます。また、誤り無し文書の検出精度を上げたい、といった微調整をする事もできません。
もちろん将来的にモデルの精度が向上して学習済BERTの精度を追い抜く、という可能性は十分あります。しかし現状では、同様の誤り文修正タスクに取り組む際には、Chat GPTよりはBERTを構築して取り組むのが理想といえるようです。
ブレインパッドでは、このタスクに限らず、様々なビジネス課題に対してのソリューションを提供しています。データ分析やAIの活用に関するご支援が必要でしたら、どうぞ遠慮なくお声がけ下さい。
*1:下流タスクには、今回の誤り文修正の他にも文書分類や感情分析等があります。
*2:今回使用したプロンプトはあくまで一例に過ぎず、さらに良いプロンプトのアイディアがあれば、ぜひご教授いただけると幸いです。
*4:具体的には、カタカナ誤字件数が27件あり、その内BERTの正解数は8件、Chat GPTが15件でした。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













