



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
ChatGPTなど高性能な会話型AIの学習プロセスとして採用されているRLHFとは、一体何者なのかをご紹介します!
こんにちは。アナリティクスサービス部の橋本です。
今回は、ChatGPTなど高性能な会話型AIの学習プロセスとして採用されているRLHF(Reinforcement Learning from Human Feedback、人間からのフィードバックを用いた強化学習)とは一体何者なのかをご紹介させていただきます。
ChatGPTなどの会話型AIが、どんな学習プロセスで我々を驚愕されるレベルで望ましい応答ができるようになったのか、RLHFの学習プロセスをステップごとにまとめたので、参考になれば幸いです。
ここでは、RL(強化学習)とHF(ヒューマンフィードバック)に分けて、ざっくり理解して行きます。
まずは強化学習について簡単に説明します。強化学習とは機械学習の一種であり、試行錯誤的なプロセスで、与えられた課題を処理する学習方法です(本ブログの解説記事もあわせて参照ください)。
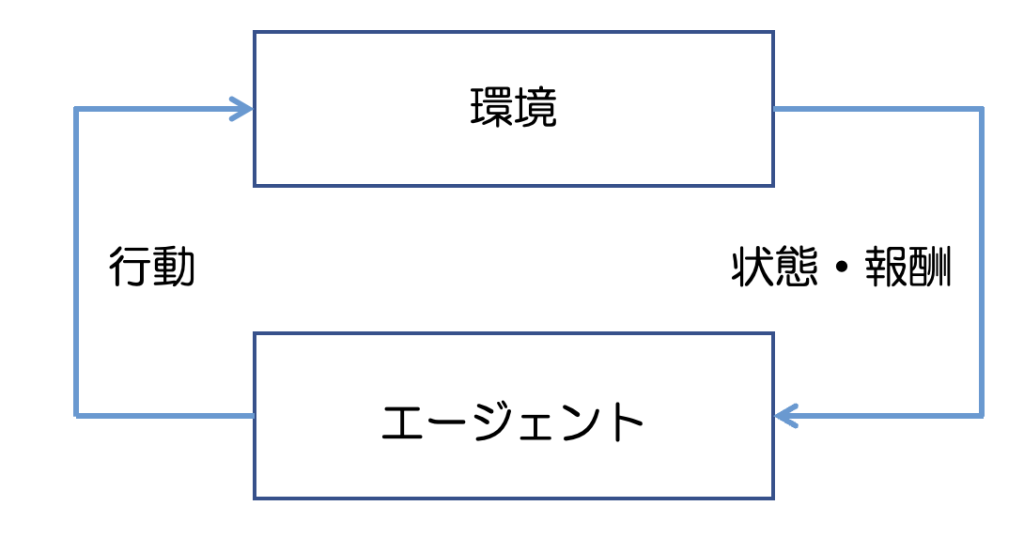
図1はとても簡略化した強化学習のプロセスです。
このプロセスをイメージで理解するために、迷路を最短経路で突破することを目標にしたゲームを想像してみてください。
この場合、「エージェント」は迷路をさまようプレイヤーで、「環境」は迷路そのものです。
スタート地点から出発して、その都度プレイヤーは何かしらの「行動」を決定(右に行くか左に行くかなど)し、迷路を進みます。この時に、環境の今ある状況(プレイヤーの位置情報など)を示す「状態」が更新されます。更新された「状態」に基づいてプレイヤーは次の「行動」を決定し、迷路を進みます。ある程度の試行ののち、プレイヤーは出口に辿り着き、ゴールまでに要した経路の長さが決まります。
このゲームでは、経路が短いほど高得点が得られるとします。この得点が「報酬」に相当します。
プレイヤーはこの「報酬」を参照しながら繰り返しゲームをプレイすることで、どうすれば短距離で迷路を抜けられるか(=高い報酬を得られるか)を少しづつ学習していきます。
このプロセスによって、最終的には最短経路を得る(=与えられた問題を解く)ことができます。
これが強化学習のプロセスです。
実際の強化学習ではプレイヤーは機械(AI)であり、与えられた問題の中で、報酬を最大化するような行動を学習していくことで、問題を解く(あるいは最適化する)ことができるわけです。
RLHFでは、与えられたプロンプトに対して学習結果を参照して応答文を生成(=行動の決定)し、その文章がどれほど望ましいかという観点で評価(=報酬)が決まり、それを基に応答文の生成モデルを更新していきます。
それでは、この過程の中でヒューマンフィードバックはどこに入っているのでしょうか。次項でそれを確認していきましょう。
ヒューマンフィードバックは一言でいうと、AIが生成した応答文に報酬を与える際に利用されています。
強化学習を実施する前に、報酬をどうやって与えるか(数値化するか)を決める必要があります。この時、「報酬の決め方」に対して「モデル作成者にとっての好ましさ」を反映させた設計にしておきます。
具体的には、あるプロンプトに対してAIが生成した応答文の良し悪しを人間がランク付けし、そのランク付されたデータセットを使って「より望ましい応答文とはどんな感じの文章なのか」を評価できる報酬モデルを作成するわけです。
なお、次節の具体的なプロセスで説明しますが、たとえばInstructGPTでは強化学習を実施する前に、事前学習として人間が用意したプロンプトとそれに対応する望ましい応答のセットを教師データとして、教師あり学習が行われています。
よって、この場合はここでも、モデル作成者の意図が生成モデルに反映されることになります。
1文でまとめると、ヒューマンフィードバックは、大規模言語モデルが望ましい応答文を生成できるようになるために必要な、ガイドラインの構築に利用されるのです。
ここでは、RLHFの具体的な学習プロセスが示されているInstructGPTの論文に着目して、そのプロセスをステップごとに理解していきたいと思います。
InstructGPTの学習についてはこちらの記事で詳しく書かれており、以下の文章でも参考にさせてもらっています。
(InstructGPTでは大規模言語モデルであるGPT-3をベースに、RLHFを適用して人間が期待している回答を出力するモデルを生成しています)
RLHFを行う場合、なるべく優秀な言語モデルを用意します。RLHF自体の役割は「モデル作成者にとって好ましい出力をするように言語モデルを微調整する」ことなので、元の言語モデルが一級品でないと、当然RLHFを適応しても「使える」結果はなかなか得られないでしょう。
したがって、ここで用いられる言語モデルは基本的に数十から数百億パラメータを持つ、GPT-3やGPT-4、LLAMAモデルなどトップクラスの大規模言語モデルとなっています。
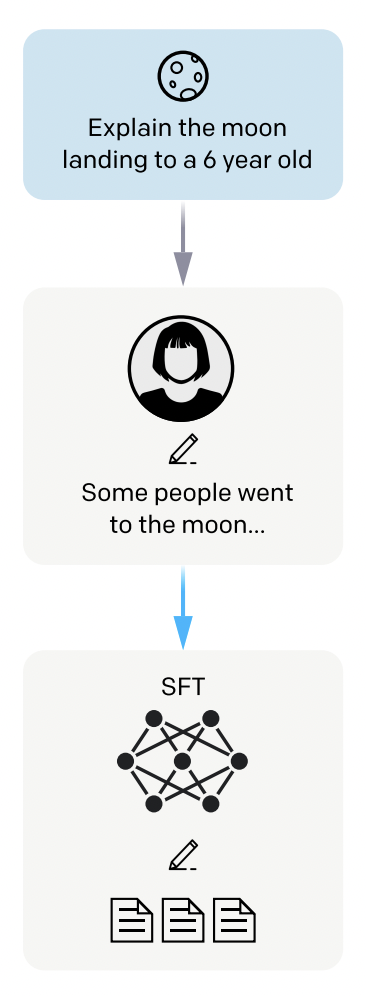
まず、学習に用いるプロンプトを用意します。
次に、それに対応した「望ましい出力」を人力で用意します。
こうして作られたデータセットを基に、教師あり学習を実施して、ひとまず人間の望む出力へ言語モデルをfine-tuningします。
どんな「望ましい出力」を用意するかは、完全にモデル作成者の判断であり、したがってこのデータセットがRLHF適用後のモデルの「性格」を決める一因になります。
というわけで、まとめるとステップ1ではステップ2以降の事前準備として、まず教師あり学習を利用した大規模言語モデルのチューニングを実施しています。
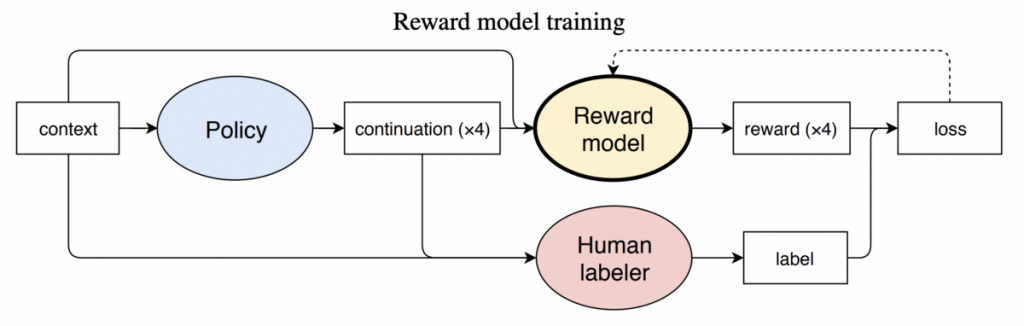
まず、ステップ1でfine-tuningしたモデルを利用して、1つのプロンプトに対する複数の応答を用意します。
モデル作成者は、その応答文をより好ましいものから順に順位付けします。
そして、これらを使って報酬モデルを学習させます。報酬モデルをこのように学習させることで、似たようなプロンプトが与えられた時に、より望ましいと評価された応答(=よりランクが高かった応答)に近い応答文が、より報酬が高くなります。結果として、より好ましいと評価された応答文に近い応答文が生成される確率が高まります。
なお、報酬モデルの望ましさの評価観点は以下の通りです。
ステップ2では、プロンプトに対する応答文がどれほど「望ましい」応答文であるかを、人間の価値判断に基づいた報酬モデルを作成することで数値化することを可能にしています。
報酬モデルを用意したことで、ステップ3で実施する強化学習を実施する準備が整いました。
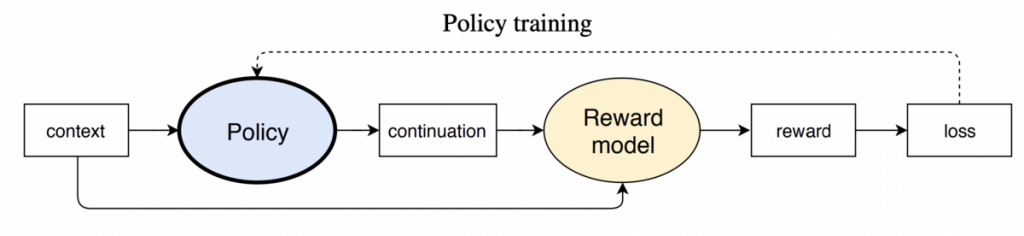
このステップでは、ステップ2で学習した報酬モデルに対してポリシーを最適化することで、報酬モデルに最適な(最も望ましい応答文を返す)応答文の生成モデルを作ることができます。
強化学習におけるポリシーとは、現在の状態で次にエージェントがどういう行動を取るべきかを決定するための戦略を意味します。
つまり、RLHFではあるプロンプトが入力されたときに、どういう応答を返せばよいかを決定する戦略になります。
具体的な流れとしては、まずデータセットから学習に使用していないプロンプトを抽出してきます。
次に、その時点でのポリシーに従って、抽出したプロンプトから応答文を生成し、生成された応答文を報酬モデルに与えて報酬を計算します。
得られた報酬を使って、現在採用しているポリシーを、より高い報酬が得られると期待できるポリシーへ更新します。
最初のステップに戻り、更新したポリシーを利用してプロンプトから応答文を生成し、報酬モデルに与えて報酬を計算し、より高い報酬が得られると期待できるポリシーへ更新します。以下この流れをループします。
後述しますが、この一連のステップはProximal Policy Optimization (PPO)アルゴリズムと呼ばれる、ポリシーベースの手法でよく利用される強化学習アルゴリズムにより実行されます。
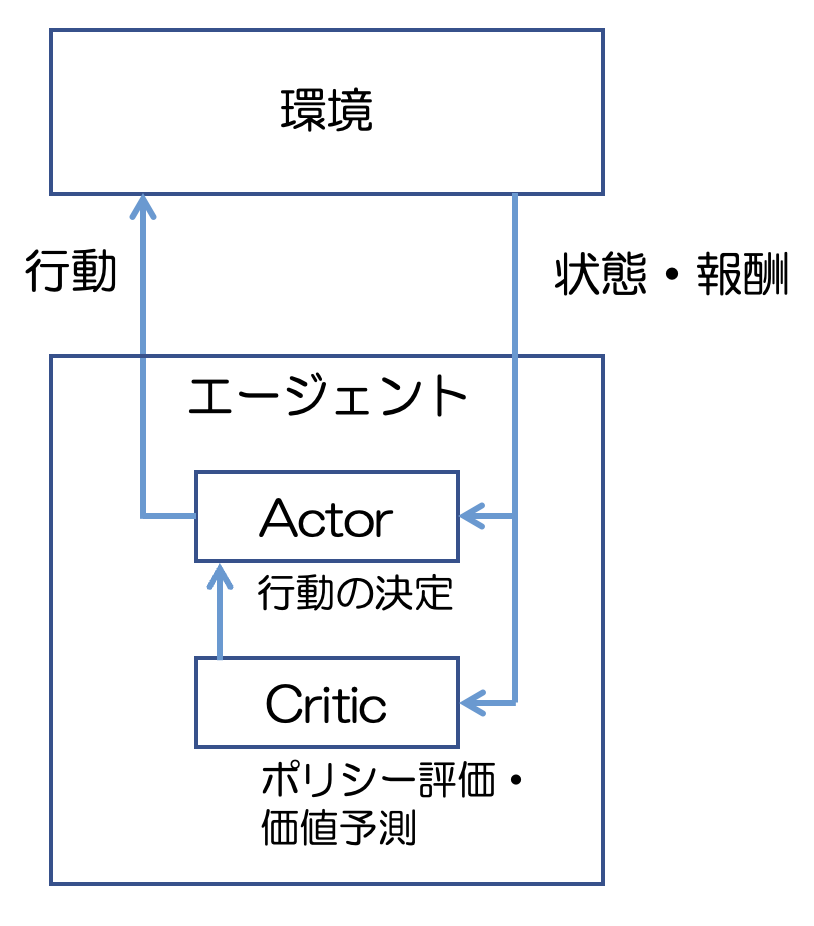
PPOアルゴリズムは、Actor-Criticと呼ばれるアルゴリズムの発展系なので、ここではActor-Criticについて概要を記述しておきます。
Actor-Criticは、連続値制御問題(出力が「右」「左」のような離散的な出力でないパターンの問題)で好まれるポリシーベースの手法の1つです。
Actor-Criticではその名前の通り、エージェント内にActorとCriticという役割が存在し、それらが協調することでポリシーを更新し、報酬を最大化していくプロセスです。
Actorはその時点のポリシーに基づいて行動を決定し、環境に作用します。一方で、CriticはActorの行動を評価し、ポリシーの更新に関して有用な助言をする立場です。
PPOアルゴリズムは、OpenAIが開発したアルゴリズムで、基本的な構造は全てActor-Criticから受け継いでいます。
特徴としては、ポリシーの大きすぎる更新による学習の不安定化を避けるために、更新幅を小さくクリッピングする操作を取り入れていることです。
この非常にシンプルかつ実装が簡単な操作で、高い学習性能を実現しています。
今回は、ChatGPTなどの会話型AIのモデル生成に利用されているRLHFについて、学習プロセスを追ってみました。今回のお話をまとめると以下のようになります。
今後は、当社研究プロジェクトを通してRLHFの学習を実際に行っていき、その結果も報告させていただく予定ですので、お待ちいただければ幸いです。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













