

メルマガ登録
ベストなDXへの入り口が
見つかるメディア


-
テーマ
から探す -
技術
から探す -
業界・事例
から探す -
関連トレンド
から探す
ベストなDXへの入り口が
見つかるメディア
テーマ
から探す
技術
から探す
業界・事例
から探す
関連トレンド
から探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回、プログラミングなどのIT技術系のトピックについて、LLMに学習用のドキュメントを作成してもらえるアプリを、OpenAIのAPIとStreamlitを使って作成しました。
こんにちは、アナリティクスサービス部の齋藤です。
今回は、OpenAIのAPIとStreamlitを使って簡単なアプリを作成してみたので、その内容と作成過程で学んだことを紹介します。
ChatGPTのようなLLMは非常に賢く、既に何でもやってくれそうに見えますが、(少なくとも現時点では)私たち使う側に、生成された内容をレビューしたり判断したりする能力が引き続き求められているように思います。
そこで、主にプログラミングなどのIT技術系のトピックについて、LLMに人間の能力を高めてもらう学習用のドキュメントを作成してもらえたらいいなと考えました。
書籍や各種ホームページでも様々な有益な情報は見つかりますが、LLMなら「任意の」テーマについて、学習用のドキュメントをいくらでも作成できます。
今回作ったアプリの機能は、後述する通り非常に基礎的なものですが、LLMを使った簡単なアプリを作ってみたい方への参考になると思うのと、また、作成過程で直面した課題には普遍的なものも含まれると思うので、紹介していきたいと思います。
まず作ったアプリの内容を紹介します。
アプリは2ページからなります。
(※Streamlit自体の使い方はここでは割愛しますが、下記のような内容のアプリをhtmlなどの知識なしで、pythonコードだけで簡単に作成できるパッケージです。)
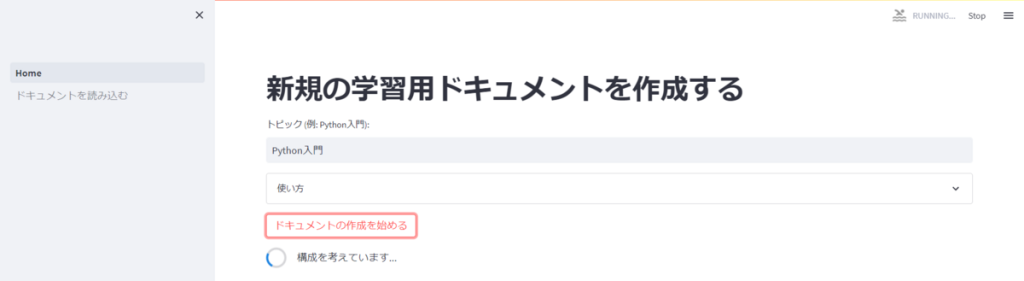
任意のトピックを入力し、学習用のドキュメントを生成させるページです。

トピックの欄に自然言語で任意のテーマを入力し、「ドキュメントの生成を始める」を押下すると、テーマを学ぶにあたって必要なサブトピック(要は目次)が生成されます。
↓

そのうえで、「次のチャプターを作成する」を押下すると、各チャプターの内容が、マークダウン形式で逐次出力されていきます。

全チャプターの出力が終わると、ドキュメントの評価とドキュメント自体を、クラウドストレージ(今回はAWS S3を使いました)にエクスポートができるようにしています。
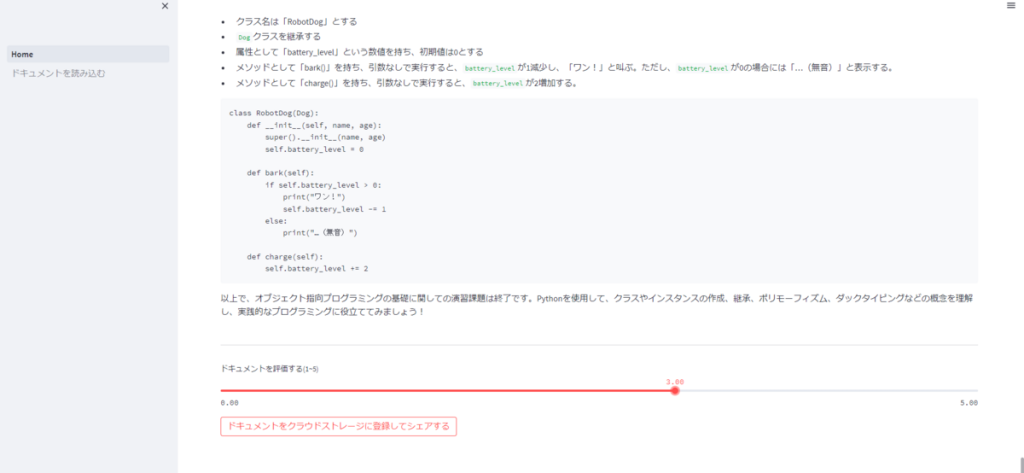
新規生成され、クラウドストレージに登録されたドキュメントを読み込んで表示できるページです。
これまでに、アプリのユーザがエクスポートした全てのドキュメント(とそれまでの評価★)を読むことができます。

また、ドキュメントを生成したユーザでなくても、各ドキュメントに評価をつけられるようにしています(各ドキュメントに付与されている評価★は、これまでの評価者がつけた評価の平均値)。

上記のアプリ概要を見るだけでお分かりかと思いますが、ドキュメントの生成を1回のAPIレスポンスで得るのではなく、分割して得ています。
具体的な手順は以下のようにしています。
アプリにおける「ドキュメントの作成を始める」の押下で行います。
使用している関数は以下です。
今回はLangChainなどのパッケージは使わず、OpenAIのAPIを直接使用しています。
def create_table_of_contents(topic: str, model_name: str="gpt-3.5-turbo", max_tokens: int=2048) -> str:
"""目次を生成する"""
user_message = f"""
「{topic}」というタイトルで教材を作りたい。
ユーザが段階的に技能を身に着けられるよう、テーマを分解し、適切なサブトピック、つまり、教材の目次、を作成せよ。
「{topic}」を学ぶにあたって、最低限度必要だと考えられるサブトピックのみを作成せよ。
出力の形式は以下のjson形式とする。
{{
{{1}}:{{サブトピック名}},
{{2}}:{{サブトピック名}},
...
}}
"""
res = openai.ChatCompletion.create(
model=model_name,
messages=[{"role": "user", "content": user_message}],
max_tokens=max_tokens,
)
table_of_contents = res["choices"][0]["message"]["content"]
return table_of_contentsなお、アプリコード内で取り回しやすいように、出力形式を指定しています。
このように実際にアプリでLLMを使う際は、出力の形式などを調整する工夫が必要になるケースに直面することも多いのではないかと思います。
今回はレスポンスがpythonの辞書で扱えない形式で返ってくる場合もあるので、アプリ側では辞書への変換が成功するまで何度かトライするような実装をしましたが、出力形式を整える用途で別途LLMを使うのも手だと思います。
このように、いきなり全体のドキュメントを得ようとするのではなく、「ドキュメント全体の構成を定めるタスク」を実行させています。
アプリにおける「次のチャプターを作成する」の押下で行います。
使用している関数は以下です。
def stream_chapter(
topic: str,
dict_table_of_contents: dict[int, str],
chapter: int,
max_tokens: int,
model_name: str="gpt-3.5-turbo",
) -> str:
"""生成した目次のkeyを与え、そのkeyのドキュメントを生成する"""
user_message = f"""
「{topic}」というタイトルで教材を作成している。
教材の目次は、以下である。
{dict_table_of_contents}
このうち、あなたは、「{dict_table_of_contents[chapter]}」の部分を作成する担当となった。
担当部分に関して、読者がスキルや知識を習得できる素晴らしいドキュメントを作成せよ。
以下の要件を満たしたドキュメントを生成せよ。
- マークダウン形式であること
- コードサンプルのような、ユーザが実際に試すことのできる実践的な内容が含まれていること
- 担当部分以外の項目に関わる説明をあなたの担当部分の中に含めないこと
- # {chapter}. {dict_table_of_contents[chapter]} という見出しで始まること
"""
res_stream = openai.ChatCompletion.create(
model=model_name,
messages=[{"role": "user", "content": user_message}],
max_tokens=max_tokens,
stream=True,
)
return res_stream「ユーザの入力したトピック」「1で作成した目次(をdictに変換したもの)」「このAPIレスポンスで担当させるチャプターがどこか」をプロンプトに与えて、stream形式(逐次出力)で出力を取り出しています。
各チャプターを一挙に作成させるのではなく、「1で定めた全体の構成の中の一部を生成させるサブタスク」を実行させています。
これを全チャプターが生成されるまで反復します。
プロンプトのテクニックとして有名かと思いますが、LLMは一気にタスクを解かせるより、タスクを分解して、それぞれのサブタスクを解いていき、最終的に目的に近づいていくアプローチが有用だと言われています。
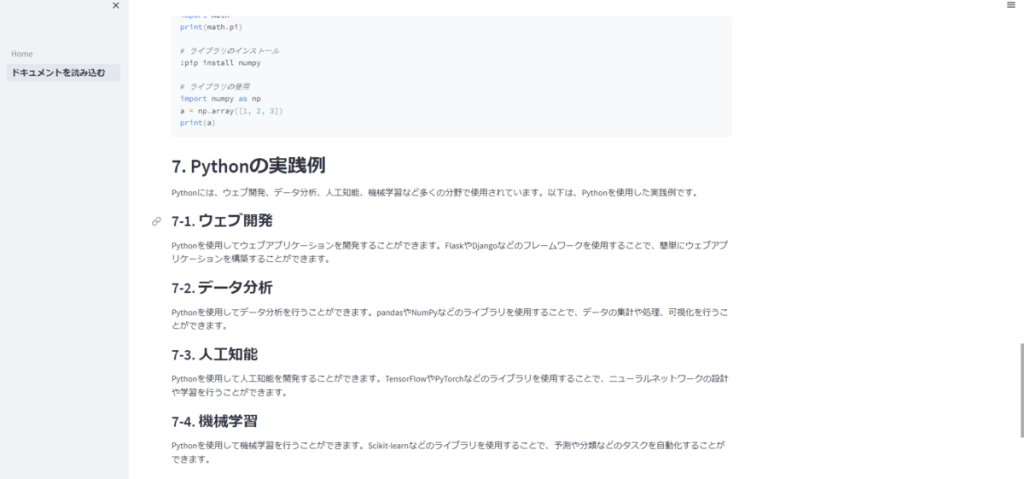
自分も最初、全てお任せで一気にドキュメント全体を生成させようと試みましたが、ドキュメントの情報の粒度にムラが出て、コントロールできませんでした。
例えば、下記のようなほぼ役に立たないざっくり説明が出たりします。これは、モデルをGPT-4のようなより性能が良いものにしても同様でした。
一方、タスクを分割させると、それっぽい内容が得られやすいです。
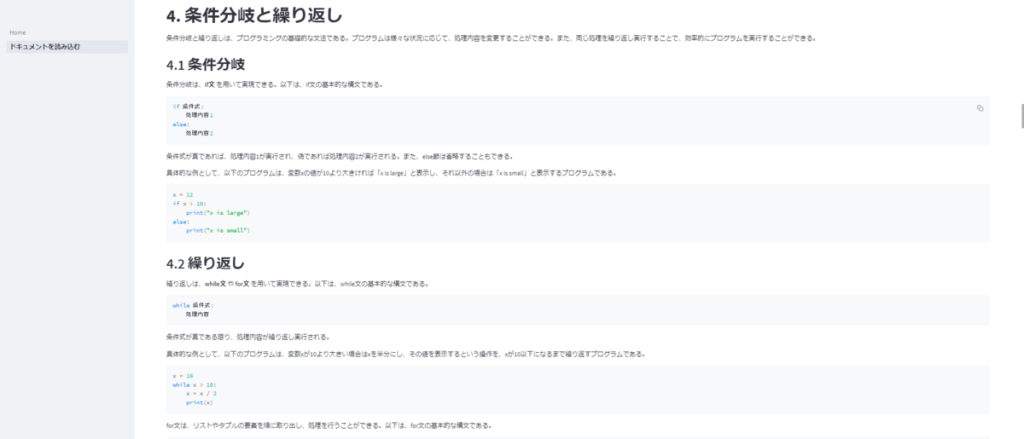
もちろん、プロンプトを工夫すればまともなドキュメントに近づけられる部分もあると思いますが、チャプターに分解させて生成させた方が、最終的なドキュメントの品質をコントロールしやすいと思います。
また、タスクを分割させることで、長文を生成させる今回のようなドキュメント生成タスクであっても、文字数制限の問題をある程度回避できます。
このように、そのアプリで実現したい内容に合わせてサブタスクを作成させ、段階的に目的にアプローチしていく方法は有用であると考えられます。
この問いは、何か作ってみようと決めてから、自分の中で色々と自問自答したものです。
ChatGPTのAPIで何か作ってみようと考えて、同様の問いに直面している方々も少なくないのではないでしょうか。
ChatGPTのようなLLMの性能がいくらすごくても、ファインチューニング等をきちんと実践(社内文書に特化したChatGPT|ファインチューニング実践編 | DOORS DX)しないのであれば、「OpenAIのチャットUIが持っていない追加の価値」は自動的には生まれません。
何かしら知恵を絞る必要があります。
今回はささやかなポイントだけですが、下記の2点の実装は追加の価値になりうると考えて実装を行いました(GPT4と対話しながら考えました)。
これは言わずもがなだと思いますが、目的に合わせたプロンプトを用意しておくことで、その目的に特化したアプリとして便利さを提供できます。
今回は、目次の生成と各チャプターの逐次生成という型をあらかじめ用意しておき、質をある程度担保したドキュメントが作成されるようにしています。
インターネットでの情報(まさにこのブログサイトやQiitaなど様々な技術系ブログで共有されている情報)は、生み出されると全世界にシェアされます。
そして、検索エンジンのランキングやサイト自体の機能によって、ある種の集合知のような形で、わかりやすさや正確性などの情報の質もシェアされます。
一方で、LLMによって生成された情報はユーザによって消費されますが基本的にシェアされません。
LLMの出力にも質の良し悪しがあり、他人にお勧めできるドキュメントがあれば、それをシェアできるようにすることには意味があると考えました。
また、他のユーザも各ドキュメントに対して評価できるようにすることで、有用な学習用のドキュメントが判別できれば集合知の恩恵にもあずかれます。
上記は、今回作った非常に基礎的なアプリにおける一例にすぎませんが、追加の価値を生み出すためにアイデアを考えるという点は、LLMを使おうが使わなかろうが、これまでのアプリ開発と同様だと思いました。
このレベルの単純な機能を開発する中でも、様々な課題を身を持って感じることができました。
以下に、いくつかあげます。
すくなくとも2023年5月時点では、LLMのAPIを用いてアプリを開発しようとするなら、レスポンス速度は大きな課題になりえるものだと思います(今回のような長文を生成させるようなタスクでは特に)。
当初は、トピックをAPIに投げてドキュメントを一括生成させる方法を試していましたが、ChatGPTのAPIであるgpt-3.5-turboでも3~4分はかかり、ドキュメントの質を良くすることを狙って使ってみたgpt-4では10分以上かかることもありました。
これは、ユーザ(というか開発者である自分自身)をうんざりさせるには十分すぎる時間でした。
レスポンス速度が遅いと、出力の質以前の問題で、誰もそのアプリを使いませんので、必ず解決しなければならない問題でした。
結果行き着いたのは、出力を逐次受け取って出力できるstreamモードでした。
res_stream = openai.ChatCompletion.create(
model=model_name,
messages=[{"role": "user", "content": user_message}],
max_tokens=max_tokens,
stream=True,
)streamモードでは、出力が完了してから結果を受け取るのではなく、生成途中から生成内容を確認できるため、個人的には大分ストレスを緩和できました。
特に長文を生成させる場合はお勧めです。
他には、AWS lambdaで非同期に生成処理をさせておいて、生成が終わったらS3に結果を格納させ、後から読み込める機能も試してみました。
結局、生成途中から内容をすぐに見たい(と自分は思った)のでボツにしましたが、トピックだけ投げて、作成完了を登録させておいたメールに通知する機能を実装するなど、少し凝ればそうした方法もユーザ体験をましにするためにありかもしれないと思いました。
これは自分がさぼっているだけですが、今回は長文をコントロールするための数多のテクニックは使いませんでした。
チャプターごとに生成させているので、そうそう文字数制限に引っかかることはないのですが、それでもmax_tokens以内でそのチャプターの生成が終わるとは限らず、たまにエラーになってしまいました。
tokenを意識した実装は必須になると思われますので、LangChainを賢く使うなどして、改善が必要だと感じました。
各チャプターごとに出力する方式はこれまでに紹介したようなメリットもありますが、同時にデメリットもあります。
特に、各チャプター間の整合性が保たれない課題が顕在化しました。
具体的には、チャプター間で内容が重複してしまったり、説明の口調がチャプターごとにばらばらになったりしました。
プロンプトによって、他のチャプターの内容と重複するものは生成するなと指示していますが、それでも他のチャプターが実際に何を出力したのかまでは考慮させていないので、どうしても重複が出てしまいます。
これは究極的にはmax_tokensを超える分量のテキストをどう扱うかという問題(それまでに生成されている全チャプターの内容をそのまま与えて内容を調整できれば楽ですがそれは無理)なので、長文取り扱いの方法を工夫することで、生成させたドキュメント内容を調整・修正する機能を追加する必要があると感じました。
今回は、OpenAIのAPIを使った簡単なドキュメント生成アプリの作成体験を紹介しました。
非常に簡単なアプリであっても、実際に動くものを作ってみようとすると、様々なハマりポイントやクリティカルな技術的問題を実感を持って学ぶことができます。
現在では、StreamlitやDashなどのツールと組み合わせることで、アプリを試しに作ってみることが容易にできるようになっています。
この記事が、LLMの理解を深めたい方や、何かしら作りたいものがある方の実践のきっかけになれば幸甚です。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













