

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。この記事では、GPT-4の登場から執筆日(2023年5月31日時点)までの2ヶ月間で登場した論文を振り返りながら、まとめて紹介していきます。
こんにちは。AIソリューションサービス部の濵田です。
GPT-4が2023年3月14日の登場から早くも2ヶ月以上が経ちましたが、そのわずか2ヶ月くらいの間に非常に多くのLLMに関する論文がでてきました。特にChatGPTの限界や特性に言及した研究やオープンソースLLM、ChatGPTのドメインへの応用といった分野の論文が、Twitterや当社内で注目を集めていました。
この記事ではGPT-4の登場から執筆日時点(2023年5月31日時点)までの2ヶ月間で登場した論文を振り返りながら、まとめて紹介します。
GPT-4 Technical Reportが2023年3月14日に公開され、人間と遜色ない精度で多くの実世界タスクをこなせることが明らかになりました。特に画像などマルチモーダルな入力が可能になったことやアメリカの司法試験で上位10%に入るなど、その性能には驚かされるばかりです。GPT-4を使った初期実験とその実行プロンプトをまとめた論文(Sébastien Bubeck et al., 2023)も公開され、GPT-4で非常に多くのタスクを代替できることがわかってきました。一方で、同時期にGPTが米国の労働市場に与える潜在的な影響も調査され、労働者の 80 %がLLM導入により影響を受けるという結果が報告され(Tyna Eloundou et al., 2023)、社内でも話題になりました。
ChatGPTやGPT-4が世間的にも注目を集め始めた時期に、LLMのこれまでの研究を包括的にまとめた「A Survey of Large Language Models」やChatGPTの基礎技術やアプリケーションへの応用、課題などをまとめた論文(Chaoning Zhang et al., 2023)などが公開され、初期調査の際には非常にお世話になりました(前者のサーベイ論文は社内の勉強会など色々なところで話題に上がってました)。一方で、アプリケーションへの応用も非常に関心が高く、入力の曖昧さからくるアプリの挙動の不安定さや、ChatGPTが事実でないことを本当のことの様に語りだしてしまうHallucination、ガードレールの設計や評価方法など、現実で活用するには様々な課題が見えてきました。LLMアプリケーションについてはChip Huyenさんの記事「Building LLM applications for production」が参考になるので、ぜひ読んでみてください。
ビジネス利用を視野に入れると、ChatGPTを利用するだけでなく、自分たちでチューニングしたセキュアーなLLMという需要も出てきます。特にMeta AIからLLaMAが公開されてからは、オープンソースLLMの動きが強くなり、様々なオープンソースのLLMが公開されました(後述)。Googleからリークしたとされる「We Have No Moat, And Neither Does OpenAI」の記事でも、オープンソースLLMの重要性が言及されており、今後も話題の中心に登り続けることが予想されます。一方で、Googleの「PaLM 2」や Anthropicの「Claude 100k」などのGPT-4に匹敵する性能のクローズドな大規模言語モデルも公開されてきているという状況です。
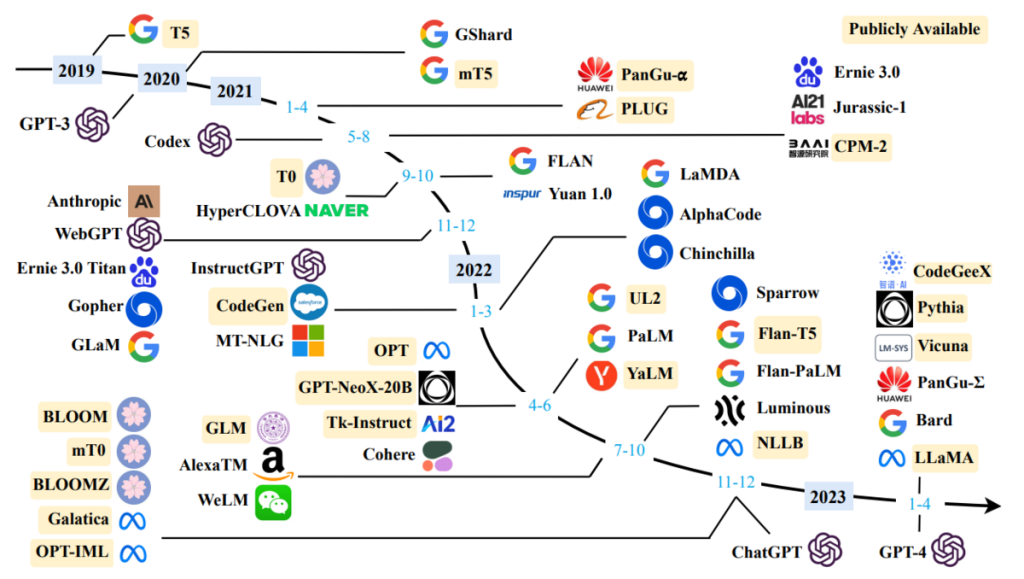
2023年2月にMeta AIから公開されたLLaMAを皮切りに、多くのオープンソースLLMが開発されましたね。LAION AIからもOpenAssistantを立ち上げたり、世界的にLLMのオープンソース化の流れがおきました。3 月から 4 月にかけてはVicunaやBaizeなど研究目的でのオープンソースLLMが出始めましたが、その後はDolly 2.0など商用利用可能なオープンソースLLMが開発され始めました。4 月の後半から5 月にかけては、画像が入力できるようにチューニングされたLLaVAやMiniGPT-4などのモデルが開発され、最近では日本語特化のオープンソースLLMであるOpenCALMやJapanese-gpt-neox が公開されました。これらのモデルの性能は、LLM-Leaderboardで確認・比較できるので、ぜひ見てみてください。一部のLLMを以下表にまとめてあります。
| License | models |
|---|---|
| オープンソースLLM | GPT4ALL、Vicuna、Baize、Koala、WizardLM |
| 商用利用可能なオープンソースLLM | Dolly 2.0、FastChat、OpenAssistant、RedPajama、OpenLLaMA、Falcon-40B |
| 日本語対応オープンソースLLM | MPT-7B、OpenCALM、Japanese-gpt-neox |
| 画像入力可能なオープンソースLLM | LLaVA、MiniGPT-4 |
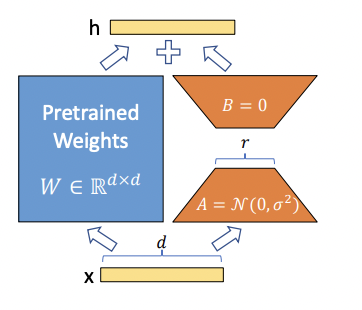
オープンソースLLMの流れが起こった要因の一つとして、個人の持っている環境でも実行できるような学習のしやすさがあげられます。少ない計算リソースで、できるだけ高精度のモデルを学習できるように、LoRA とinstruction tuningを最近の研究を踏まえて紹介します。
「LLMを効率的に再学習する手法(PEFT)を解説」でも紹介された通り、LoRAはAdapterと呼ばれるサブモジュールを、更に低ランクの行列に分解することで、学習するパラメータの量を大幅に削減する手法です。これによりオープンソースのLLMを家庭向けのGPUを使って数時間でファインチューニングすることができます。ここ2ヶ月の間により洗練された調整手法が研究されており、最近ではQLoRAを使えば、LLaMA-64Bのような比較的大きいモデルでも24時間で学習可能となってきています。以下の表で他の技術もご紹介します。
| 論文 | 説明 |
|---|---|
| AdaLoRA | 「LLMを効率的に再学習する手法(PEFT)を解説」参照 |
| LLaMA-Adapter、LLaMA-Adapter V2 | 1.2Mの少ないパラメータとより1時間程度の少ない学習時間で学習可能なAdapter。マルチモーダルにも対応している。 |
| QLoRA | NF4への量子化を始めとしたメモリ節約の仕組みにより、LLaMA-64Bのような大きなモデルでも単一GPUで24時間の学習を可能。FP16で学習したモデルと遜色ない精度を達成できる。 |
Instruction Tuning自体はFLANの論文で紹介された技術で、特定のタスクを解くようにモデルを学習させるのではなく、入力と出力の指示(インストラクション)に従うようにモデルを学習させることで未知のタスクに対して汎化させる技術です。このインストラクションはモデルに作成させることもできるため、ChatGPTやGPT-4にインストラクション作成させることで学習したモデルを高精度化する研究(Baolin Peng et al., 2023)も行われていました。一方で、ChatGPTやGPT-4の出力を競合するモデルの開発には使えないため、これらのモデルは商用利用はできませんでした。Dolly 2.0などは人手でオープンソースなインストラクションを新たに作成しているため、商用利用可能となっています。
一方でInstruction自体の質も重要で、LIMAの論文では、たった1000例程度の人が選別したインストラクションでファインチューニングしたLLaMA-64Bが、人による評価でGPT-4に匹敵する性能を示したと報告されています。
モデルを人の嗜好や指示に従うように「アライメント」するには、人からのフィードバックを利用することが有効であることもわかってきました。「ざっくりわかるRLHF(人間からのフィードバックを用いた強化学習) – Platinum Data Blog by BrainPad」で紹介したような強化学習を用いた方法で調整を行います。また人からのフィードバックをLLMへの活用方法についてのサーベイ論文(Patrick Fernandes et al., 2023)もあるので、より詳しく知りたい方はそちらをお読みください。ここ2ヶ月の間では、LLMに生成させたフィードバックを入力プロンプトに加える精度を改善させる論文が非常に面白いと感じました。これなら高価な人のフィードバックの収集もモデルの再学習も必要なくなります。以下はその2つの研究になります。
| 論文 | 説明 |
|---|---|
| Teaching Large Language Models to Self-Debug | コード生成タスクで、生成コードのラバーダックデバッグをLLM自身にフィードバックを生成させる。生成させたフィードバックをプロンプトに加えることで精度を向上させる研究。 |
| RL4F | LLM出力を修正するための批判フィードバックを生成する軽量モデルを学習させるフレームワークで、批判フィードバックをプロンプトに入力することで出力を修正する。ChatGPTなどブラックボックスなLLMでも利用可能。 |
ChatGPTやGPT-4の登場により、再学習しなくても様々なタスクを汎用的に実行可能になりました。それに伴い、ChatGPTやGPT-4の汎化性能を十分に引き出せるように、タスクを実行するための指示を適切に設計するプロンプトエンジニアリングが重視されています。ChatGPTやGPT-4のユーザの増加に伴い、DAIR.AI からLLMを使うユーザや開発者向けに Prompt Engineering Guide が公開されています。現在は日本語版も公開されているので、これからプロンプトエンジニアリングを学ぶ方はぜひ見てください。ファインチューニングと違って重みの更新が必要ないため低コストなのですが、そのトレードオフとして以下のような課題があります。
ChatGPTでは4096トークンと入出力できるトークン長が決まっており、出力も含めたそれ以上長い入力プロンプトを使うことができません。大きなモデルを使えばある程度は解決できますが、その分応答速度は遅く、コストは高くなりますし、長さは制限されるため根本的な解決にはなりません。GPT-4が知らないようなドメイン知識を必要とするタスクではHullucinationを起こさないように、大量のドメイン情報をプロンプトに入れる必要がありますが、トークン長のため入れられるプロンプトには限界があります。この問題を解決するため、この2ヶ月の間では以下のような研究がされていたようです。
| 論文 | 説明 |
|---|---|
| Gist Tokens | プロンプトをより小さな「gist」トークンのセットに圧縮する機構を組み込んだLMを学習することで、プロンプトを最大26倍まで圧縮して様々なタスクにファインチューニング無しで対応できるようにしたモデル。 |
| Active Retrieval Augmented Generation(FLARE) | 外部リソースから検索して情報を得てHallucinationを防ぐ方法がよく使われるが、一度しか検索しないため複数の情報を使う複雑なタスクに対応できない問題がある。長文を生成中に適宜能動的に必要な情報を収集する仕組みを入れることで、長文タスクで優れた性能を発揮できることを示した研究。 |
| ReccurentGPT | LSTMの長期短期記憶のメカニズムを、ChatGPTのプロンプト上に再現した手法。長期記憶や短期記憶に相当する要約文をハードウェアに保存し、適宜更新しながら長文タスクに対応できるとしている。また記憶は永続なので、パーソナライズされたアシスタンへの応用もできるとしている。 |
一方で、長いプロンプトを入力可能な新しいアーキテクチャの研究もされており、プロンプトエンジニアリングでの有用性から非常に注目を集めていた。
| 論文 | 説明 |
|---|---|
| Reccurent Memory Transformer | 長い文章を再帰的に処理させる際に、トークンの一部をメモリーとして渡す仕組みを入れたトランスフォーマー。なんと200万のトークン長に対応できる。 |
| Unlimiformer | 長さ無限の文章を処理できるように、エンコーダ・デコーダトランスフォーマーをkNNで検索可能な外部データストアで補強する手法。 |
複雑なタスク、特に多段思考が要求されるようなタスクでは、Chain of Thought(CoT)のようなステップバイステップ手法では、計算タスクでのエラーやステップ飛ばしなどの問題が発生してしまい、精度が出ないことが知られている。以下は CoTの弱点を補う新しいプロンプト手法の研究になります。
| 論文 | 説明 |
|---|---|
| Plan-and-Solve | CoTのようにステップバイステップで考えるのではなく、タスクを小さく分割する計画を立ててから、その計画に沿ってタスクを実行する「Plan-and-Solve」を提案。複数のタスクでCoTよりも常に高い性能を発揮することが確認されている。 |
| Tree-of-Thought | 計画や戦略の先読みが必要なタスクでは、CoTのような方法では対応できない。そのため、木構造の中間段階の思考ユニットを探索すること可能にしたToTを提案。4つの数字を足して24を作るゲームタスクなど多段階の思考が必要なタスクで圧倒的に高い性能を発揮。 |
ChatGPTやGPT-4で様々なタスクの実行が可能になったため、より複雑なタスクをLLMに解決させることができるようになりました。中でも大きなトレンドは、ChatGPTの持っていない能力を他のツールやAPI、モデルを道具として使うことで補う研究でしょう。BabyAGI、AutoGPT、JARVISのような、与えられた複雑なタスクを解く計画を立て、必要な道具を選定し、実行、必要なら実行結果をまとめたり、評価を行う汎用AIがこの2ヶ月で多く開発されました。4月のはじめには、BybyAGI やAutoGPT、JARVISの3つのAGIがGitHubトレンドの上位にいましたね。
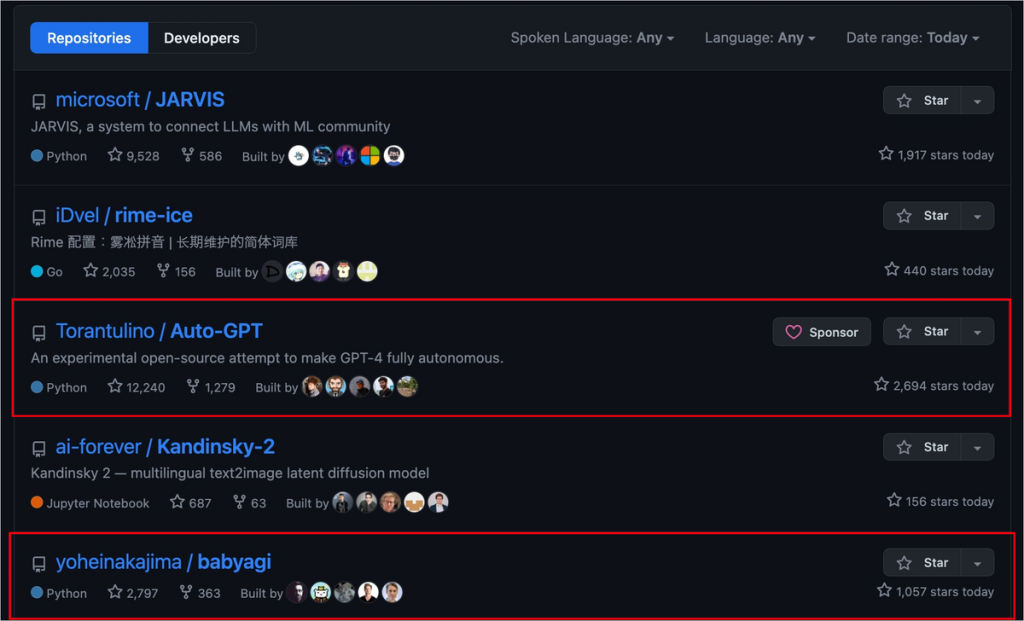
ドメイン専門タスクを解決するため、タスク固有のデータセット、評価指標と拡張可能なモデルを含むAGI研究用プラットフォームとして、OpenAGIが発表されました。また基盤モデルのツール学習について体系的な調査研究した論文(Yujia Qin et al., 2023)も報告されていました。4月の終わりには、モデルだけでなく、プログラミングや画像やウェブ検索、数値計算、テーブル処理などあらゆるツールを使えるようにし、タスクプランナーとツールシケーンスで構成されるプラグアンドプレイモジュール「Chameleon」が登場。知識集約型推論タスクで高い有効性を示しました。一方で、ツールの使用に関してはhallucinationやバージョン更新などによりAGIが安定して動作しないことが問題とされていました。そこで、ツール使用に特化してファインチューニングしたGorillaというモデルによりHaluccinationを大幅に低減することに成功。さらにドキュメントリトリーバーと組み合わせることで、柔軟なユーザアップデートやバージョン変更への対応も可能にしました。最近だとツールを利用するだけでなく、再利用可能なツール自体をLLMが作り出すフレームワーク「LATM」が提案されている。
タスクに対処するために、複数のLLMのAgentに役割を与えてコミュニケーションさせることで、複数のAIに自律的に協力させてタスクを解かせる研究も盛り上がってました。
| 論文 | 説明 |
|---|---|
| CAMEL | ロールプレイングと名付けられた新しいコミュニケーション・エージェントのフレームワークを提案 |
| Generative Agent | 経験を記録し、時間とともに記憶をより高いレベルで合成、動的にそれらを取り出して行動するエージェントを作成。街中で25人のエージェントの自律して生活する様子が見られ、人間の行動の信憑性あるシミュレーションを可能とするアーキテクチャだと紹介。 |
| Improving Language Model Negotiation with Self-Play and In-Context Learning from AI Feedback | 複数のLLMエージェントに交渉ゲームを売り手・買い手・批判家に分けて、自律的にお互いを向上させるかどうかを見る研究。強いエージェント(大きいモデル)ほど、過去の経験やフィードバックを有意義に利用し、安定してパフォーマンスを上げることができる。 |
最後に各タスクやドメインへの応用論文を紹介します。
Text Classification via Large Language Models
Causal Reasoning and Large Language Models: Opening a New Frontier for Causality
Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations
Emergent autonomous scientific research capabilities of large language models
Is ChatGPT a Good Recommender? A Preliminary Study
Leveraging Large Language Models in Conversational Recommender Systems
現時点では初期検証が多く、断定的なことが言える研究は多くないですが、多くのタスクとドメインでChatGPTとGPT-4が高いパフォーマンスを発揮する兆候が見えています。また現状では因果推論や医学系、説明を求められる推薦やコード生成タスクなど、汎用的な知識からくる理由付けを求められるタスクでは非常に高い性能を発揮しやすいですね。ただその他のタスクでも同程度か少し劣る程度の性能を示しているので、調整次第ではChatGPTは様々な場所で活躍できるポテンシャルを秘めてます。たった2ヶ月でこれだけ進むなら、本当にほとんどの人の労働が奪われるようになるかもしれないですね(現時点ではなんとも言えないので話半分に聞いておいてください)。
この2ヶ月の間に発表されたChatGPTやLLM関連の論文や技術を振り返ってみました。ChatGPT/GPT-4やオープンソースLLMの課題になっていた部分に対して、集中的に取り組んでおり、すごい勢いで解決していっていると感じています。特にAGIについては先進的な研究が多く、今後どの様に発展していくか楽しみです。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













