

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
この記事では、生成AIの中でも、テキスト、画像、動画、3Dデータ、オーディオデータ、モーションなど多岐にわたるマルチモーダル系のタスクについて、全2回の連載でご紹介します。
こんにちは、アナリティクスサービス部の八登です。
昨今話題をさらっている生成AIですが、ChatGPTのようなテキストベースのタスクだけでなく、マルチモーダル系のタスクにも大きな関心が集まっています。
ここでマルチモーダルとは、AIが同時に複数の形式を扱うことができる、ということを指します。
モーダル(形式)の例としては、テキスト、画像、動画、3Dデータ、オーディオデータ、モーションなど多岐にわたります。しかし、この多岐にわたるという性質のために、マルチモーダル系タスクの全貌を把握することは容易ではありません。
本記事は、このような生成AI×マルチモーダルの領域の全体像を俯瞰することで、まずはこの領域に対するイメージを深めていただくということを目的としています。
本記事では、マルチモーダル系タスクの整理のために、AIのインプット/アウトプットに着目します。
つまり、インプットがどのモーダルであり、アウトプットがどのモーダルであるかによってタスクを分類します。
しかし、すべての組み合わせのタスクをここで紹介することは現実的ではありませんので、本記事では、昨今のLLMの隆盛も鑑みて、テキストとテキスト以外のモーダルを組み合わせたモデルを中心に紹介していきます。
なお、各タスクについては、基本的に以下のような項目について記載していきます。
一方、本記事では以下のような技術的詳細に関する内容は基本的には扱いません。
このような技術的な点を深掘りした検証については、後日改めて記事を公開する予定です。
以下でモデル例に記載の情報は調査内容に基づいていますが、内容には誤りを含む可能性があります。実際に利用する場合は、商用利用可否などをご自身でも確認いただくようお願いします。なお、モデルについては主に公式のAPIやGitHub、もしくはHuggingFaceに存在するモデルについて調査しています。非公式に実装されたコードや非公式の事前学習済みモデルについては基本的に対象外ですのでご注意ください。
[:contents]
テキストを入力し、そのテキストに応じた画像を生成するタスクです。
例えば、以下の例はStable Duffusion 2.1(Stable Diffusion Version 2)の事前学習済みモデルを用いて、
“A horse riding an astronaut.”というテキストから画像を生成した例になります。
このプロンプトは検証用にしばしば用いられるもので、似たような生成結果を見られた方もいるかもしれませんが、簡単な実装を行うことで、自分でも平易にこのような画像を生成することが可能です。

なお、画像生成タスクには、以下のように画像から画像を生成するタスクも多く存在します。
以下は、SAM(Segment Anything Model)((Segment Anything, https://segment-anything.com/))と呼ばれるモデルを使用して、上で生成した画像に対してゼロショットでセグメンテーションタスクを実施した例となります。
この例では自動でマスクを生成していますが、セグメンテーションしたいものをテキストで指示する、などの方法でセグメンテーションを実施することも可能です。

画像生成はマルチモーダルタスクの中でも特に盛んに研究されている領域であり、近年も多くのモデルが毎日のように提案されています。 なお、本記事のモデル例では、主に2022年、2023年に公開されたモデルのみを紹介します。

画像生成のユースケースには、例えば以下のようなものが考えられます。
なお、本記事のユースケースは、すでにSaaSなどでサービス展開されているものを中心に、こういう領域も考えられるのではないかという主観も一部加えて作成しています。
また、自分で画像を生成するのではなく、第三者が生成した画像をダウンロードできるサービスなども存在します。
近年の画像生成モデルの生成画像の質は非常に高くなっていますが、そもそも、このような生成画像の質はどうやって評価すればよいのでしょうか。
評価に関しては、以下のような3つの基準が用いられることが多いです。
これらは定性的な評価と言えますが、これらの評価軸をより定量的に行う方法もいくつか存在します。
なお、定量的な評価には通常正解の画像とテキストのペアが必要なります。
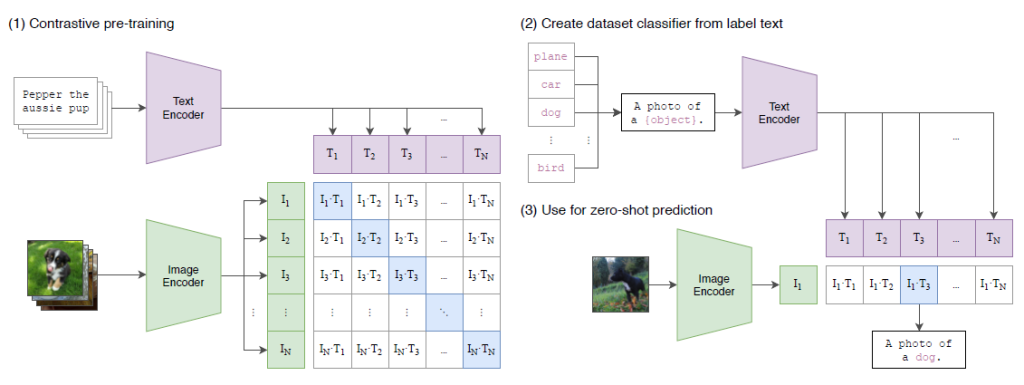
CLIP(Learning Transferable Visual Models From Natural Language Supervision)とは、下図のように、対照学習によりテキストと画像のペアを大量に学習させることで、類似するテキストと画像の埋め込み表現を対応付けることを可能とした基盤モデル(Foundation Model)です。
画像生成に限らず、多くの画像とテキストの両方を用いるモデルでこのCLIPが組み込まれています。
>
画像を認識した結果をもとにテキストを生成するタスクです。
画像認識は、以下のようなタスクに細分化して考えることができます。
試しにBLIP-2((BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, https://arxiv.org/abs/2301.12597))というモデルに、下の画像を入力して、画像を説明するキャプションを生成してみましょう。なお、この画像もStable Diffusionで生成した画像です。

ピクセルアート調で描かれており、写真風の画像より読み解きが難しそうに感じますが、どのように回答するでしょうか。
“a yellow car is parked in front of a building”
路上に車があるので、私は車が走っている画像と捉えましたが、モデルは駐車していると返しています。
ただ、トータルで見るとまずまずの回答を返しているようです。
なお、BLIP-2では質問のテキストを入力して、それに回答させることも可能です。
上のキャプションでは、画像のスタイル(ピクセルアート調であること)は無視されていました。
そこで、この点を突っ込んで聞いてみましょう。うまく回答できるでしょうか。
“Question: What style is this image drawn in? Answer:”というプロンプトを入力してみましょう。
以下のテキストが生成されます。
“pixel art”
モデルはスタイルも正しく理解していましたね!
画像認識については、例えば以下のようなモデルが提案されています。

画像認識のユースケースには例えば以下のようなものが考えられます。
主要なチャットサービスが今後画像認識に対応してくることも想定され、実用が徐々に広がっていくでしょう。
画像認識のタスクでは、モデルがどれだけ正しいテキストや回答を返しているかが評価対象となります。
定量的な指標としては、たとえば以下のような指標がしばしば用いられます。
テキストの内容に沿った動画を生成するタスクです。画像生成の動画版と考えればよいでしょう。
以下の例はText2Video-Zero(Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators)というモデルを用いて、先ほどと同じ“A horse riding an astronaut”というテキストから動画を生成した例になります。
画像生成と同様に、動画も一定のクオリティで生成できていることが分かります。

動画生成も近年盛んに研究されている分野であり、多くのモデルが提案されています。 ただ、現段階では公式にモデルが公開されていてかつ商用利用可能なモデルは多くないようです。

画像生成と同様に、動画生成も多くのユースケースが想定できます。
動画生成はクリエイティブ用途がまずは思い浮かぶと思いますが、バーチャルプレゼンのようなビジネス用途も考えられ、すでにサービス化されているものもあるようです。ただし、動画生成単体というよりは、後述するテキストからの音声生成などの技術と組み合わせて用いることが一般的でしょう。
*** 検証方法
動画生成の定量な評価については、以下のような方法が提案されています。
画像認識と同様に、動画を認識した結果のテキストを生成するタスクです。例えば、VideoChat(VideoChat: Chat-Centric Video Understanding)というモデルを使うことで、読み込んだ動画に関してチャットで質問を投げることができるようになります。
なお、このVideoChatはInternVideo(InternVideo: General Video Foundation Models via Generative and Discriminative Learning)という動画の基盤モデルとLLMを組み合わせた構成となっており、このケースではLLMにChatGPT(gpt-3.5-turbo)を使用しています。
VideoChatに先ほど生成した動画を読み込ませて、実際にチャットしてみた例が以下になります。
基本的には問題なく動画を解釈して回答していることがわかります。
特に2行目は、ちゃんと動画の時系列も考慮したうえでの回答になっているように見えます。

例えば以下のようなモデルがあります。

下のようなユースケースが考えられます。
– 動画内容要約
– 動画を含んだチャットボット 特に動画は人が要約するのにより時間を要することが想定されるので、有効な使用方法となるでしょう。
テキストを入力して3Dデータを生成するタスクです。以下はthreestudio(threestudio)のコード上でDreamFusion(DreamFusion: Text-to-3D using 2D Diffusion,)モデルを用いて、“a bolt with a nut”というテキストに対する3Dモデルを生成した例です。
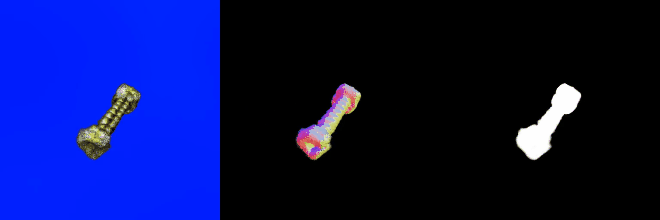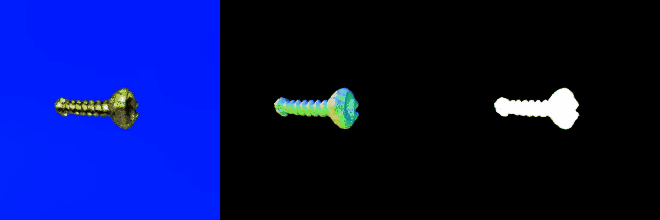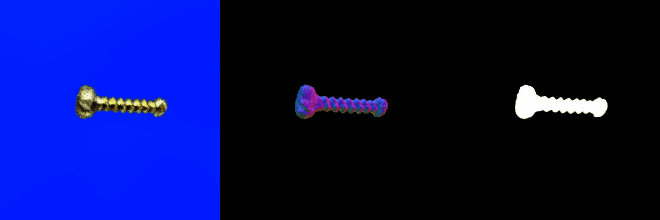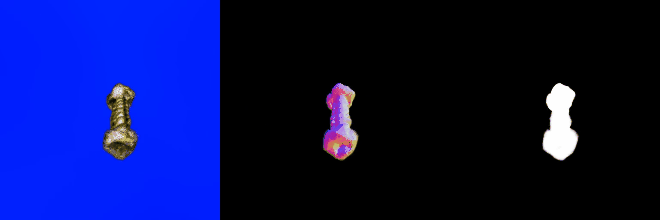
若干粗いところもありますが、プロンプトは正しく解釈されていますし、まずまずのモデルが出力されていると言えるでしょう。
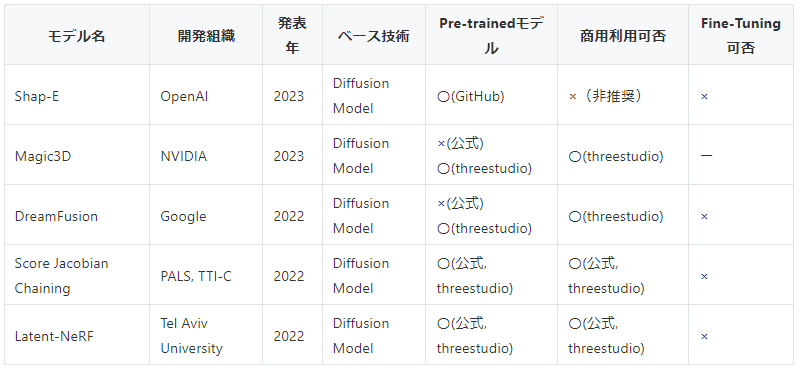
3Dデータ生成も、近年かなり精力的に研究されている分野です。 上で用いたthreestudioのように、複数のモデルを試せるような便利なプロジェクトも登場しています。
3Dデータ生成はメタバースに必須の技術であり、近年特に注目されています。産業用途での使用も多く想定できます。
3Dモデルの良し悪しをどう評価するかは難しい課題ですが、定性的には、画像生成と同じように3Dデータのリアルさ、テキストの忠実度などで評価したり、モデルの滑らかさなども実使用を考えると評価対象となるでしょう。
定量的な評価手法としては例えば以下のようなものがあります。
3Dデータを認識してテキストを生成したり分類を行うタスクも存在します。
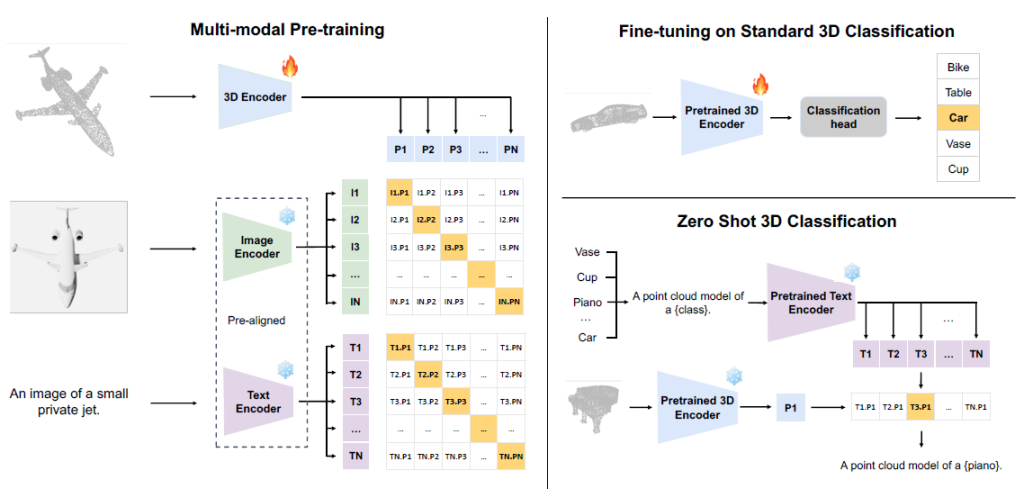
例えばULIP((ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding, https://arxiv.org/abs/2212.05171))というモデルでは、以下の画像にあるように、画像-テキストの対応付けをあらかじめ学習した事前学習済みモデル(パラメータは固定)を用いて、3Dデータ(点群)、画像、テキストの3つの組に対して、3Dデータの埋め込みベクトルと、画像、テキストの埋め込みベクトルを対応させるように学習を行います。
CLIPを3Dデータに拡張したような手法と言えます。
これにより、3Dデータをゼロショットで解釈して、適切な分類を返すことができます。
たとえば以下のようなユースケースが考えられます。 – 3Dモデル分類 – 3Dモデル説明自動生成 例えば自動運転やロボット制御などの領域で、センサーで取得したデータに対して認識処理を行うような用途は考えられるかもしれません。
テキストを入力して何らかのオーディオデータを生成するタスクです。テキストどおりの音声を出力する読み上げタスク(TTS: Text-To-Speech)は、実用レベルでも広く使われていますので、なじみ深いタスクと言えるでしょう。
それ以外にも、テキストの指示に沿った音楽や効果音を生成するようなモデルも公開されています。
本タスクでは生成例は割愛しますが、各モデルの公式ページなどに、モデルから生成されたサンプルのオーディオデータが多く公開されています。
単に読み上げるだけでなく、歌声を生成したり、笑い声といった発話以外の音声も再現できるなど、多様な表現が可能となってきていることがわかります。
このタスクについても、非常に速いペースで新しいモデルが提案されています。

以下のようなユースケースが考えられます。
特にキャラクター音声生成は、他の生成AIの技術と合わせることで、ゲームなどでNPCと自然な対話を実現するための技術(NVIDIA Avatar Cloud Engine (ACE)for Games)として注目されます。
定性的には、音声読み上げの場合は、イントネーションやアクセントなどが自然かが評価対象となるでしょう。
定量的な評価のためには、オーディオデータに対しても埋め込み表現を用いた評価方法が用いられることがあるようです。
音声データから発話している内容どおりのテキストを生成するタスクです。いわゆる文字起こしのタスクです。
生成例として、Whisperというモデルを用いて、日本語音声をテキストに変換してみます。
日本語音声としては、ここでは公開しませんが、自分で録音した音声を使用します。
この音声の正解テキストは「正解の音声と生成された音声の埋め込み表現の距離の近さを評価する」です。
もっともパラメータ数の少ないtinyモデルを用いて生成された結果は以下のようになります。
「正解の音声と生成された音声の埋め込み表現の距離の近さを評価する」
元の音声を聞いていないので判断が難しいと思いますが、それほどクオリティが高いとは言えない音声についても、軽量なモデルでも結果を完璧に再現することができています。

文字起こしはすでに様々なシーンで実用化されていますが、例えば以下のようなユースケースが挙げられるでしょう。
音声文字起こしでは、以下のWERと呼ばれる指標が定量評価によく用いられます。
上記で取り上げたもの以外にも、以下のような様々なモーダルが存在します。
これらを含めて、実際のタスクでは、複数のモーダルを同時に入力したり、複数の出力モーダルをタスクに応じて使い分けるといったことが発生します。
あらゆるモーダルを同時に考慮することで、それぞれ単独で用いるよりインプットの解釈がより強化されることが期待できます。
複数のモーダルを同時に入出力できるようなモデルには以下のようなものがあります。

よりイメージを深めるために、この中のPaLM-E(PaLM-E: An Embodied Multimodal Language Model)と呼ばれるモデルについて概要を説明します。

PaLM-Eは、大規模言語モデルであるPaLMをマルチモーダルに拡張したモデルです。 言語の埋め込み表現に加えて、画像や他のセンサー情報などの埋め込み表現を同時にインプットすることで、外界認識に基づく複雑なタスクに対応可能なモデルとなっています。 タスクとしては、ロボット制御、ビジョン解釈、ビジョンに対する質問応答、などが想定されています。 我々が外界を認識するとき、ビジョンや言語、その他の情報を区別して処理しているというよりは、すべてを統合して処理した上で何らかの行動を決定していることが多いでしょう。 マルチモーダルモデルも、そのようなことを目指して進化している途上とも言えます。
ここで取り上げるサービスはあくまで一例であり、これらのサービスの優位性を確認していたり、使用を推奨するものではありません。
ここまで生成AIのマルチモーダル系の様々なタスクを紹介してきましたが、上記の例では、公式のコードなどを利用して、すべて自分で実装を行って結果を生成してきました。
しかし、ビジネス用途を考えたとき、コーディングなしでより洗練された質の高い結果を得たい、ということのほうが実際上は多いと思います。
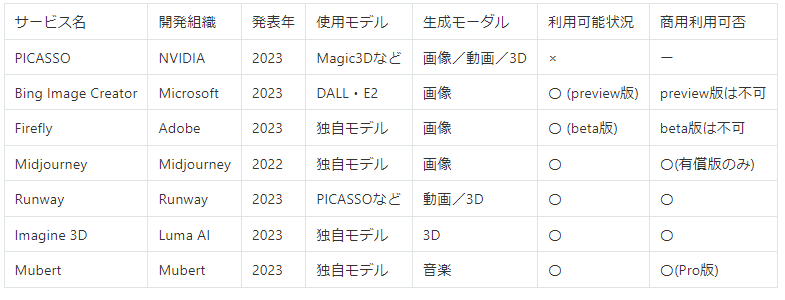
以下はそのような目的で使用可能と考えられるサービスの一例になります。
各サービスの実際の生成クオリティ、実用性については本記事の範囲を超えますが、様々なタスクですでに多くのサービスが提供されていることが分かります。
今後もGAFAMのようなビッグプレイヤーや多くのスタートアップから、新しいサービスが続々と登場していくことでしょう。
本記事では、マルチモーダル系のタスクを網羅的に紹介してきました。
マルチモーダル系の生成AIの進歩は近年特に非常に速くなっており、明日、来週、来月には、まったく新しい革命的なモデルが登場しているかもしれません。
この分野に関心を持っていただけた方は、ぜひご自身で最新の情報を入手して、この領域の進歩を実際に体感していただければと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













