



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

データ活用をシステム面から支援するデータエンジニアリング本部(通称:DE本部)の社員がお送りする技術ブログです。今回は、継続的デリバリーにおいて重要な負荷テストについて、短期間での簡易的な性能試験(スモークテスト)で得られた知見をご紹介します。
こんにちは、DE本部アナリティクスアプリケーション部の中島です。
継続的デリバリーは本番環境へのデプロイ前にアプリケーションの問題を見つけるために重要です。継続的デリバリーでは、テストコードでの単体テストのほか、UIテストや負荷テストも行われることがあります。今回は、この負荷テストを行うにあたって短期間での簡易的な性能試験(スモークテスト)を行いましたので、その際に得られた知見について紹介します。
負荷テストは、一般に同時ユーザのリクエスト数に対する「システムの応答性」や「システムのスケール特性」を確認するために行われます。また、負荷テストはシステムの性能改善を行うためにも重要です。
今回は負荷テストを実施するにあたってスモークテストを行いました。スモークテストの目的は主に以下の2つです。
上記が確認できない場合、そもそも負荷テストが行うことができません。
テスト環境およびアプリケーションの概略構成を以下に示します。アプリケーションはk8s上に認証サーバーを含む形で構成されています。
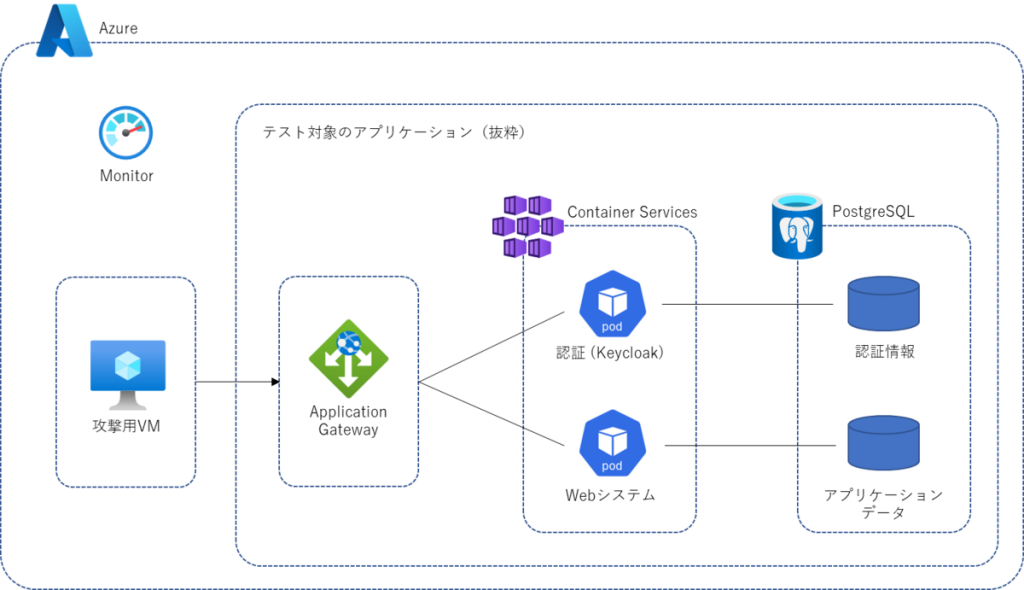
私が本テストを実施することになったときには、上記システムがほぼ完成している状態でテストを行うことになりましたが、システムが複雑であればあるほど問題があった場合にボトルネックの特定が難しくなります。本テスト環境においても、リクエストを送ってからWebシステムにたどり着くまでにApplication Gateway や認証サーバーを経由するため、適切なレスポンスが返ってこなかった場合にどこが原因かを判断しにくいという課題がありました。
そのため、システム完成後のアプリケーション総合試験の中の項目として入りやすい負荷テストですが、可能であればシステム構成が比較的単純な状態から負荷テストの準備や最低限のスモークテストを行っておくことが重要だと考えます。
また、認証サーバーを用いる場合、認証サーバー自体でさまざまな制約をかけられます。認証サーバーも含めたシステム全体の性能を確認する場合には、実際のユースケースに合わせた設定で問題ないですが、アプリケーション側の性能を確認したい場合などは一時的に認証サーバーの設定を変えるなども検討する必要があります。
一般に、負荷テストはユーザーのユースケースに合わせて負荷テストのシナリオを作成します。ユースケースにあった負荷テストを実施しないと、負荷テスト上問題がなくても実際に使ってみると想定よりレスポンスが悪いといったことが起こる可能性があるからです。
今回はスモークテストということで厳密なユースケースにあわせたシナリオを設定したわけではありませんでしたが、テストスクリプトの確認を行うためにも負荷テストでシナリオに入る可能性が高いアクセス数・アクセス頻度の高いページや、DBの参照を含むページ、DBの更新を含む処理、CSVアップロードなどの負荷が高い処理をテストシナリオに含めました。
また、シナリオではDBに登録する値をランダムに変化させるといったことも必要です。DBのキャッシュ機能が働いた場合、適切に負荷がかけられない可能性があるためです。
例として、一般的なアプリケーションにおいては、以下のようなシナリオが考えられます。
負荷テストの負荷をかけるツールとしてlocust を用いました。locust はpythonのコードで簡単に負荷テストのシナリオを書くことができます。以下では、スクリプト実行時に on_start でログインして、 index と profile のページをランダムに表示し、スクリプトが終了する際にon_stopで ログアウトするという一連のシナリオを記載しております。
# locustfile.py
from locust import TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
self.login()
def on_stop(self):
self.logout()
def login(self):
self.client.post("/login", {"username":"ellen_key", "password":"education"})
def logout(self):
self.client.post("/logout", {"username":"ellen_key", "password":"education"})
@task
def index(self):
self.client.get("/")
@task
def profile(self):
self.client.get("/profile")locust はGUIを用いたテスト実行もできますが、CUIを用いて行うことも可能です。私は実行条件と実行結果を対応させて保存したかったため、configファイルを読み込んでCUIで実行する方法を取りました。以下のようにconfig ファイルを記載することが可能です。
# locust.conf
locustfile = locustfile.py # テストシナリオのファイルを指定
headless = true # CUIでの実行
host = http://target-system # アプリケーションのURL
users = 2 # 同時接続ユーザー数
spawn-rate = 1 # 1秒当たりの増加ユーザー数
run-time = 300s # 実行時間CUIで実行する際に、実行引数に–csv を指定することで、example_stats.csv, example_failures.csv, example_history.csv (–csv=example の場合) の3つのファイルが作成されます。
$ locust --config=locust.conf --csv exampleexample_stats.csv, example_failures.csvのファイルには、テスト実行全体の統計情報と失敗例が含まれます。example_history.csv は、テストの間の10秒単位での統計情報が表示されます。
なお特に接続ユーザー数が多い場合には、負荷をかけた直後の値は正確な値でないため、一定時間計測した後の値を見るようにしたり、中央値の値をとるといったことが必要になります。
本アプリケーションはAzure上に構成されたシステムのため、負荷の状況等はAzureMonitorを用いて確認することができます。そのため、はじめはAzureMonitorを用いてメモリ使用量やCPU使用量をみていましたが、AzureMonitorの値は一定時間の平均値をとっており、負荷のピークの値が測定できないことに気が付いたため、以下のパフォーマンス値を一定間隔で取得してファイルに書き出すスクリプトを作成しました。
また、攻撃サーバー側の状況を確認するために、必要に応じて以下のlinux コマンドを使いました。
なお、攻撃サーバーの状況も確認する理由としては、アプリケーション側より先に攻撃サーバー側のメモリやCPUを使い切ってしまった場合に、十分にアプリケーションに負荷がかけられないことがあるためです。
テストの結果、作成したテストスクリプトでシナリオに沿ってリクエストを送れ、正しくレスポンスを返すことが確認できました。
一方で、アプリケーションからのレスポンスタイムは最高でも100μs くらいを想定していましたが、レスポンスタイムの中央値が500μs以上とかなり高い値を示しており、アプリケーションのAPIの速度に課題があることを確認できました。
今後のアクションとしては、ボトルネックの特定を行います。今回のケースでは、ある程度すでに複雑な構成となっているため、アプリケーションに問題があるのか、認証サーバーに問題があるのか、DBに問題があるのかなど、様々な原因のパターンが考えられます。そのため、なるべくシステム構成が単純なうちから負荷テストを実施できるようにし、定期的に負荷テストを実施する必要があると感じました。
また、今回の実施により負荷テストを行うための事前確認ができたので、より具体的なユースケースやレスポンスタイムの目標値などを定めた負荷テストを行っていきたいと思っています。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













