



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

このたびブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
この記事では、Retrieval Augmented Generationを使用して、ユーザーからの質問に対して外部データを基に回答を生成させてみたので、その方法をご紹介します。
こんにちは、アナリティクスサービス部の秋本です。
LLMを用いてサービスやアプリを作成する場合、プロンプトに収まらない程の長い文章や独自のデータを教えたくなる事があるかと思います。また、それらは一定の頻度で整備・更新されます。その都度トレーニング済みモデルを調整するのは手間がかかります。
本記事では、Retrieval Augmented Generation(以下、RAG)を使用して、ユーザーの質問に対して、外部データを基に回答を生成させようと思います。
モデルの外にある知識を利用して文章を生成する事を指します。実装においては、外部知識からコンテキストを取得するコンポーネントを有し、入力された文章と組み合わせてモデルに渡され、最終的な出力を生成します。
モデル内部ではなく外部に知識情報を配置するため、下記のメリットがあります。
下記の構成を想定とします。
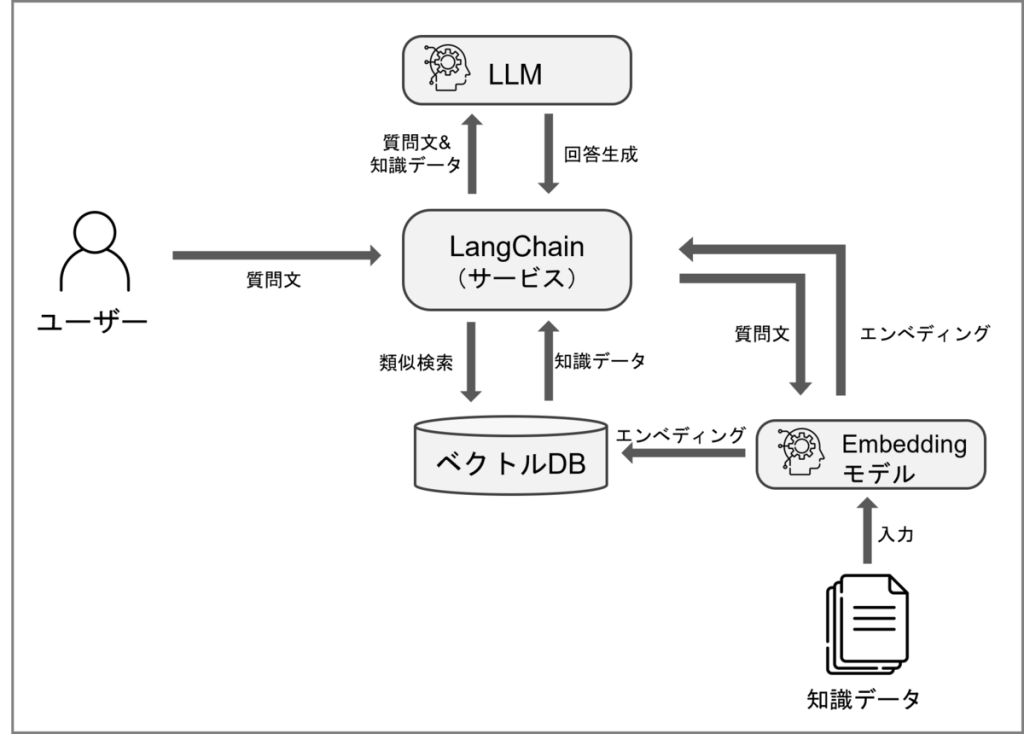
ベクトルデータベースの構築とサービスは別々に立ち上げるケースが多いかと思うので、知識データのエンべディングは別途行い、LangChainではインデックス情報の読み込みのみを行います。
併せて、外部データがサービスと独立し、データ側だけの更新ができるようになります。
こちらの記事でも紹介されているため割愛します。
今回はベクトル検索エンジンにRediSearchを使います。
RediSearchとはRedisをベースに作られたオープンソースの全文検索・セカンダリインデックスエンジンです。
ベクトル検索エンジンは現在様々なものがあり、3大クラウドのマネージドデータベースでも利用できるようになっています。
今回は、イメージが配布されており導入が簡単ということでRedisearchを用います。
docker run -p 6379:6379 redislabs/redisearch:latestデータは、Amazonが配布している商品情報のデータを用いてみます。
商品名と商品説明文をエンべディングし、商品情報として利用します。Amazon上の商品名は検索用に多くのメタ情報を含んでいるため、商品説明として利用します。
データはAmazonのリポジトリ
https://github.com/amazon-science/esci-data/tree/main/shopping_queries_dataset
から取得できます。
import pandas as pd
from pyarrow.parquet import ParquetDataset
ds = ParquetDataset(
"./shopping_queries_dataset_products.parquet",
filters=[('product_locale', '=', 'jp')] # 日本の商品に絞っています
)
df = ds.read().to_pandas()以下のようなデータが含まれます。
| product_title | product_description |
|---|---|
| SoBiC(ソビック)オーガニックプランター H-004 [2020年モデル] ※専用栽培カートリッジバッグは別売 | 【電気を使わず自然の力で野菜を育てるSoBiC(ソビック)オーガニックプランター】 ※本製品のシステム構造は特許取得済です(特許番号:第5942073号) ※栽培カートリッジバッグは別売です … |
| シャチハタ おなまえスタンプ おむつポン専用 交換用スタンプパッド・補充インクセット GAB-AR | |
| アイリスオーヤマ 高反発マットレス シングル 高反発 一体型 敷布団 プロファイル加工 体圧分散 吸汗速乾 L字ファスナー 厚さ8cm MAKK8-S ブラウン/ベージュ | |
| MYNUS iPhone X CASE (マットホワイト) | |
| SEL DE COULEUR セルデ・クルールバスソルト 1箱(全7種セット)x3 | ・やさしい香りと色とりどりの湯色が疲れた体と心を満たしてくれます。 ・肌に合わない時はご使用をおやめください ・天然塩のため、まれに不溶物が混入する場合がありますが、品質には変わりはありません。 … |
| ワイングラス 320ml 赤ワイン エナメルカップ 無鉛クリスタル ペアセット クリスタルガラス ハンドメイド 1500mlワイン交換器 ワイン酔い覚まし ワイン保存器 おしゃれ 贈り物 プレゼント (グリーン) | 舞い降りるオーロラのような優雅な曲線が美しいグラスです。ガラス素材はきらびやかでクラシックながら上品で、高貴でスタイリッシュな外観は機能的でありながら装飾的です。 透明度が高く、限りなく透明に近いとされています、それによるグラスの透明感、清涼感が人々を魅了しています。 … |
データに対してエンべディングを行い、ベクトル化を行います。その後、それらのデータを取得するためにベクトルデータベースに格納します。
今回、エンべディングには'text-embedding-ada-002' を利用します。
import os
import tiktoken
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
OPENAI_API_KEY = "sk-XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
tiktoken.encoding_for_model(''text-embedding-ada-002'')
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=(), )
return len(tokens)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=20,
length_function=tiktoken_len,
separators=["nn", "n", " ", ""], )
embedding = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key=OPENAI_API_KEY, )データベースに接続し、インデックスを作成します。インデックスとする列Embeddingは、エンべディングに使用するモデルの次元数に揃え、類似度にコサイン類似度を設定します。
import redis
from redis.commands.search.field import NumericField, TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
INDEX_NAME = "rag-index"
DOC_PREFIX = "doc:"
VECTOR_DIMENSION = 1536 # text-embedding-ada-002の次元数
r = redis.Redis(host="localhost", port=6379)
def create_index(vector_dimension: int):
try:
r.ft(INDEX_NAME).info()
print("Index already exists!")
except:
schema = (
VectorField(
"Embedding",
"FLAT",
{
"TYPE": "FLOAT32",
"DIM": vector_dimension,
"DISTANCE_METRIC": "COSINE",
},
),
TextField("ProductId"),
TextField("ProductTitle"),
TextField("ProductDescription"),
TextField("ProductBulletPoint"),
NumericField("ChunkNumber"),
NumericField("ChunkCount"),
)
definition = IndexDefinition(
prefix=[DOC_PREFIX],
score_field="Embedding",
index_type=IndexType.HASH,
)
r.ft(INDEX_NAME).create_index(
fields=schema,
definition=definition,
)
create_index(vector_dimension=VECTOR_DIMENSION)商品名 product_title と商品説明 product_descriptionをエンべディングし、データベースに格納します。ベクトル型フィールドはbytes型で格納する必要があります。
※LangChainでRedisを用いる場合、contentキーとmetadataキーの参照に問題があるため、カラムをこの段階で作成しています。
import json
from uuid import uuid4
import numpy as np
pipe = r.pipeline()
for i, record in df.iterrows():
texts = text_splitter.split_text(
(record["product_title"] or "") + (record["product_description"] or ""))
vectors = embedding.embed_documents(texts)
for j, (vector, text) in enumerate(zip(vectors, texts), start=1):
mapping = {
"ProductId": record["product_id"],
"ProductTitle": record["product_title"],
"ProductDescription": record["product_description"] or "",
"ProductBulletPoint": record["product_bullet_point"] or "",
"Embedding": np.array(vector).astype(np.float32).tobytes(),
"ChunkNumber": j,
"ChunkCount": len(texts),
"content": record["product_title"],
"metadata": json.dumps({
"product_brand": record["product_brand"],
"product_color": record["product_color"] or ""})}
pipe.hset(f"doc:{uuid4()}", mapping=mapping)
pipe.execute()ベクトルDBを作成し、チェーンを生成します。
from langchain.vectorstores.redis import Redis as RedisVectorstore
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
vector_store = RedisVectorstore.from_existing_index(
embedding=embedding,
index_name=INDEX_NAME,
vector_key="Embedding",
redis_url="redis://localhost:6379", )
retriever = vector_store.as_retriever()
chain = RetrievalQA.from_chain_type(
ChatOpenAI(),
chain_type="stuff",
retriever=vector_store.as_retriever(), )適当な商品を取ってきます。
> df.sample().product_title.values[0]
'What Say カラーレンズ ミラーレンズ サングラス クリアレンズ 伊達メガネ 全17色 クラシックフレーム トレンド UV400 メンズ レディース ソフト & ハードケース 付 (ライト ブルー/ブラック)'カラーレンズが出てきたので、カラーレンズについて聞いてみます。
> chain.run("カラーレンズについて教えてください。")
' カラーレンズは17色から選択でき、クラシックフレームの伊達メガネを装着できます。UV400保護のレンズになっており、ソフト&ハードケースが付属しています。'17色などのラインナップにも触れており、外部データベースを参照した回答になっています。
独自データをエンべディングしてベクトルデータベースに格納することで、プロンプトに含められる文字数制限に関係なく大量のデータを扱うことができました。
Amazonの商品情報を利用し、商品説明を生成する事ができました。実際にはトークスクリプトや商品マスタといったデータを利用するケースが多いと思いますが、それらを用いた場合にも十分に力を発揮できるのではないでしょうか。
また、今回は入力部分は特に何も設定しませんでしたが、テンプレートの設定することで回答形式を整えたり、精度向上の余地はまだあります。
商品マスタと直接的に繋がるということで、質疑応答の他にも商品POPの作成や商品説明の自動生成にも転用可能かと思います。
今回はRAGにて外部データとの接続を試みましたが、他にも様々な手法がありそれぞれにPros/Consがあるため、機会があればそれらについても触れていければと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













