

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス部の髙橋です。
ChatGPTが登場して以降、さまざまな大規模言語モデル(LLM)が発表されていますね。
使う側としては楽しみな反面、業務で使うとなるとそれぞれのモデルにどういった特徴、違いがあるのかを検証していく必要があるのかな、と感じています。
そこで今回は、いくつかの大規模言語モデルをGUIでお試し利用するために作ったツールについて話します。
なお以降、大規模自然言語モデルを(長いので)LLMと略します。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
なんとなく下記のように、複数のLLMを検証利用するツールがあるといいだろうな、と考えていました。
例えばセキュリティに関しては、この取り組みを始めた時点では、ChatGPTのWeb版は入力を学習データとして使う可能性がありました(参考: https://blog.brainpad.co.jp/entry/2023/05/17/161613)。
このため、API版を使ったインターフェースがあるといいですよね。
また、多くのLLMが公開されており、そもそも他のLLMのインターフェースもあると便利です。
こういった思惑もありつつ、単純にLLMを使ったナニカを作ってみたかったので、流行にのってLLMを使ったツールを作成してみることにしました。
前述のアイディアと重複しますが、機能としてはざっくり以下のことができるようにしました。
フロントエンドフレームワークとしてDashを使ってみました。
深い理由があったわけではなく、Pythonで手軽にフロントエンドを作れるため採用しました。
が、結果的には正直もうちょっと考えてフレームワーク選定するべきでした(後述)。
利用したLLMですが、高性能なモデルが色々と公開されていく中で、以下を踏まえて選びました。
例えばチャット対応に関して、 rinna の sft は「汎用GPT言語モデルを対話形式の指示遂行ドメインにfine-tuningした対話GPT言語モデル」です(https://rinna.co.jp/news/2023/05/20230507.html)。
一方で、サイバーエージェントのOpen CALMはファインチューニングして使われることを想定しています (https://www.cyberagent.co.jp/news/detail/id=28817) が、性能を比較してみたかったので採用しました。
また、Alpacaは元のLLaMAモデルもデータセットも商用利用不可なため、実際にはサービスとして有償提供はできませんが、今回は検証も兼ねて利用しました。
Chat画面は次のような感じで、使うLLMを選択できます。

また、使うLLMを選んだら、どの学習済みモデルを使うか、どういったパラメータを与えるかを設定できます。
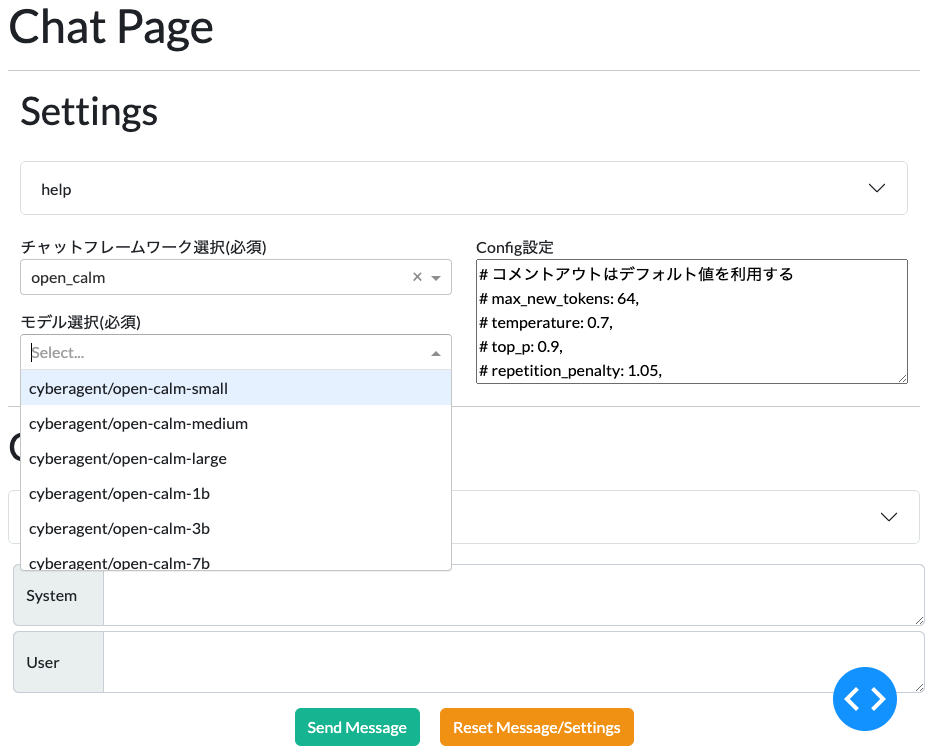
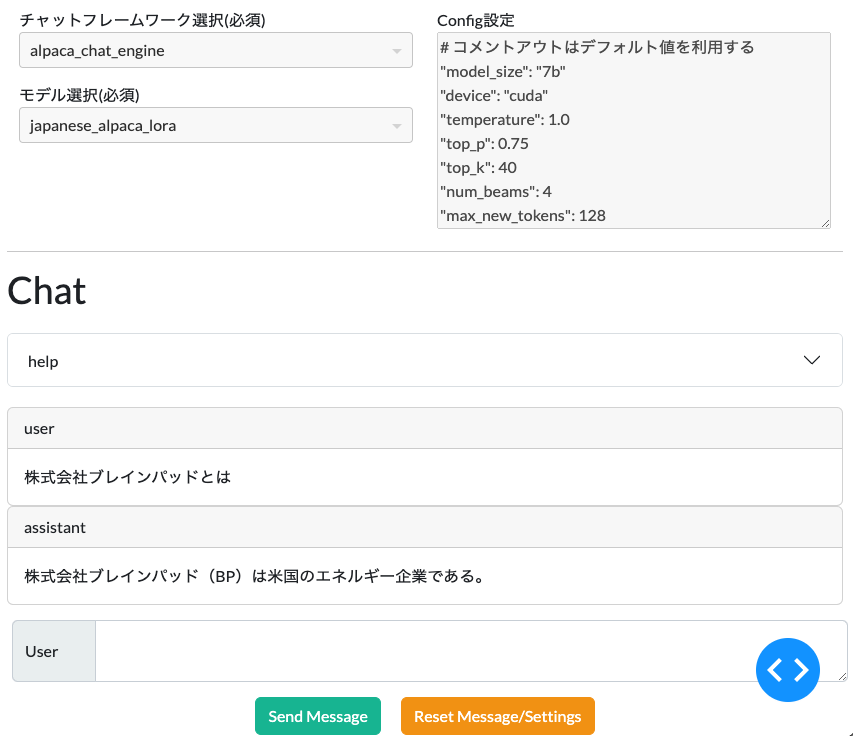
次に、Userフォームに生成したい内容を入力し、Send Message ボタンを押すと回答が得られます。
「株式会社ブレインパッドとは」の続きを生成させましたが、生成テキスト内でブレインパッドをBPと省略したため、石油エネルギー会社の方を説明してしまっています…
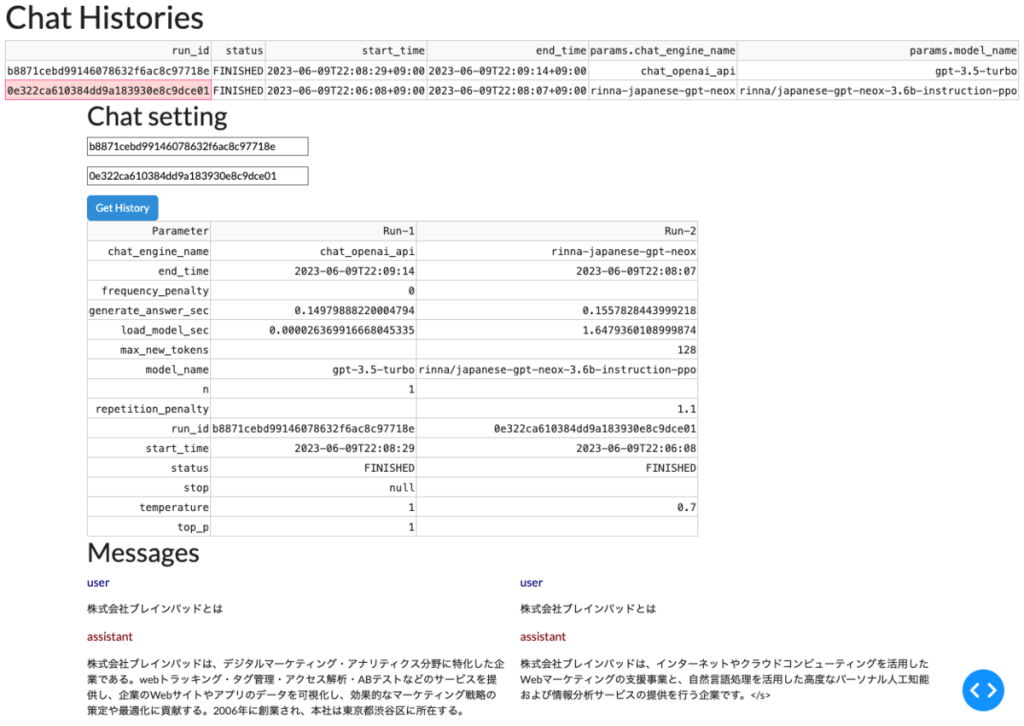
History画面では、LLMの実行履歴を見ることができます。
これはMLflowを利用して各種パラメータやログを保存しておき、参照したい時に取得するようにしています。
また、2つの結果を比較することができます。
下記はChat APIとrinnaに「株式会社ブレインパッドとは」の続きを生成させてみた場合です。
概ね正しいのですが、Chat APIでは2006年の創業(実際は2004年)、本社は渋谷区(実際は港区)と誤答しています。
もう一つ別の例として、AlpacaとOpen CALMに「DXを推進するためには何が必要」か聞いてみましょう。
Alpacaの方は質問をそのまま繰り返していますが、Open CALMはそれっぽい回答をしています。
ベンダーが提供するLLMにせよ、OSSのLLMにせよ、回答に多少クセがあるため、業務利用するにはプロンプトエンジニアリングやファインチューニングが必要になりそうですね。

LangChainに代表されるようなライブラリは、LLMを組み込んだアプリケーションの開発を素早く、簡単に実現することができます。
しかし今回のツールを作り始めたタイミングではLangChainなどは有名になりはじめたばかりだったため、採用しませんでした。
ただ、LangChainは現在もどんどん開発が進んで便利になっており、使ってみた体験談も充実してきています。
活用事例としては、是非弊社のブログもご確認ください。(ChatGPTとLangChainを活用してデータ分析アプリを作ってみた – Platinum Data Blog by BrainPad)
例えば、Open AIのChatAPIには挙動を決めるためのシステムユーザーとしてのプロンプトと、要望やコメントを記述するユーザーとしてのプロンプトがあります。(https://platform.openai.com/docs/guides/gpt/chat-completions-api)
しかしHuggingFaceにある他のLLMなども同様とは限らず、設定できるモデルのパラメーターもモデルごとに異なります。
そういった差分を吸収しつつ、全てのモデルで同じように動かすためのインターフェースを作ることに苦労しました。
一例としてalpaca-loraとrinnaのプロンプトを比べてみましょう。
| alpaca-lora | rinna | |
| 入力と回答のユーザー名 | Instruction Input Response | ユーザー システム |
| 各メッセージの区切り文字 | ### | <NL> |
| 入力プロンプトの前に書くプロンプト | Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. |
このためフォーマットはそれぞれ以下のようになります。
alpaca-lora
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input_ctxt}
### Response:rinna
ユーザー: コンタクトレンズを慣れるにはどうすればよいですか?<NL>システム: これについて具体的に説明していただけますか?何が難しいのでしょうか?<NL>ユーザー: 目が痛いのです。<NL>システム: 分かりました、コンタクトレンズをつけると目がかゆくなるということですね。思った以上にレンズを外す必要があるでしょうか?<NL>ユーザー: いえ、レンズは外しませんが、目が赤くなるんです。<NL>システム: また、HuggingfaceのAutoModelForCausalLM経由で利用する場合、単純に推論すると「入力したプロンプトも合わせて推論される」「パラメータで指定した出力トークン数になるまで回答を繰り返してしまう場合がある」といった問題があります。
それぞれ「入力したプロンプトを取り除くことでモデルの回答を抽出する」「区切り文字を利用して1つ目の回答を取り出す」といった工夫が必要になります。
例えば、Japanese-Alpaca-LoRAでは、区切り文字とユーザー名を利用して回答部分の1つ目を抜き出すという実装になっています。
LLM選定のところでも紹介しましたが、公開されているLLMは想定されている用途が異なり、またデフォルトでは回答の精度もまちまちです。
こういったことから、用途に合わせてどういったLLMが使えるか、ファインチューニングが必要かを検討する必要があります。
そしてファインチューニングするには、利用用途に合わせてデータセットを用意する必要があります。
往々にしてMLのサービス活用では、データセットの用意が重いタスクになることがあるため、実際にLLMを組み込む際にはこの点をスコープにきちんと入れる必要があるでしょう。
LLMに必要なデータセットや出力の制御については、弊社のデータセットとLLMの制御の記事を参照ください。
Chat APIに対しては単にリクエストを投げているだけですが、他のLLMでは、モデルを取得して推論によるテキスト生成も行っているため、入力から回答まで場合によっては1分ほど時間がかかります。
社内で試してもらっても、このレイテンシーの高さは使いにくいとコメントをもらいました。
実際に本番で利用する場合は、LLMをロード済みのバックエンドに対して処理をリクエストし、出力を取得する方が高速になるでしょう。
そうなるとGPU付きの計算リソースをモデル数分用意して、リクエストが大きい時にはスケールアウトできるように…と考えると、検証用ツールとしてはかなりコストがかかるため、これはこれでハードルが高いです。
また、LLMに行わせたいタスクが文書の要約やラベリングなどであれば、非同期で処理を行うことも検討できますが、チャットなど同期的に利用するには、より高速に動作するような工夫が必要だと感じました。
シンプルに使ってみたいという理由で採用したDashですが、上記の通り、LLMによる出力を得るのは時間がかかります。
基本的に対話型のやりとりを想定していたため、同期的な処理にしていたのですが、こう時間がかかると、非同期処理にした方がいいのではと思えてきます。
しかし残念ながらDashのOSS版には非同期処理をする仕組みがなく、Enterprise版を利用するか、別途バックエンドを用意する必要がありました。
お試し開発に割ける時間と費用を考えると、前述のようなLLMをロード済みのバックエンドをモデル分用意するというのも現実的でなく、もうちょっと全体として使いやすいフレームワークにするか、最初から割り切ってフロントとバックエンドを分けた方がよかったかなと思いました。
作っている間に、こちらの記事のように複数モデルを同時に試せるサービスが発表されました。
実際、複数モデルを同時に実行させて、結果を比較できるのは便利だと思います。
残念ながら我々の場合では、複数モデルの同時実行はアーキテクチャの課題と上記のレイテンシーの問題もあり、一旦保留し、前述のようにモデルの利用後に2つの結果を比較できるようにしました。
今回は複数のLLMをお試し利用できるツールを作成しました。
ChatGPTの中身については公開情報が少ないですが、他のLLMに触れてみることで、その挙動や仕組みを推察できて勉強になりました。
またGUIを備えたアプリケーションをはじめてゼロから自分で作ることになったため、楽しかったです。
本取り組みの中で主に以下が重要だと感じました。
本記事が皆様の参考になれば幸いです。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













