



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

今回は、近年注目を集めている強化学習を用いた「サプライチェーン全体の在庫管理最適化」に応用します。在庫管理の簡単なモデルケースを置いて、強化学習による在庫管理最適化がどんな強みや特徴を持っているのか、図を用いながら説明します。
こんにちは。アナリティクスサービス部の橋本です。
この記事では、近年注目を集めている強化学習という手法を用いた『サプライチェーン全体の在庫管理最適化』を扱います。
強化学習といえば、実は会話型AIとして話題のChatGPTにも応用されています。ChatGPTは、昨年12月の公開以降破竹の勢いで、日常からビジネスシーンまでさまざまな場面に影響を及ぼしてきましたが、これにより強化学習の有用性がより多くの人々に認知されることとなりました。
そんな強化学習という手法を、この記事ではサプライチェーン全体の在庫管理最適化に応用してみたいと思います。
在庫管理の簡単なモデルケースを置いて、強化学習による在庫管理最適化がどんな強みや特徴を持っているのか、図示しながら理解を深めていきたいと思います。
近年強化学習がビジネス応用として注目を集めるようになってきた理由を列挙してみました。
複雑な問題への対応:
強化学習は、一般に解くことが難しい複雑な問題において有力なアプローチとなっています。これは、深層学習と組み合わせた深層強化学習の発展やそれを可能にしてきた計算リソースの増大が原因と考えられます。そのため、従来の最適化手法では扱いづらかった複雑な問題に対して、強化学習が新たなソリューションを提供できるようになってきました(例えば化学プラントの制御や核融合炉の制御などで応用されています)。
データ駆動のアプローチ:
強化学習は、具体的な課題のシミュレーションを通じてモデル学習を実施できます。具体的なシミュレーション環境が構築しやすくなってきたことや、それによる課題の環境や制約の変化に対する適応力が向上してきたことで、強化学習が解決手法として選ばれやすくなってきました。また、深層学習の進歩により、大量のデータを効率的に学習することが可能になったことで、豊富なシミュレーションデータを活用した最適な戦略(ポリシー)の獲得が実施できる状況に至っています。
実世界への適用可能性:
強化学習は、研究領域に留まらず実世界の最適化問題にも応用されてきており、その有用性が次々に明らかになっています。ロボットの制御、自動運転、配送最適化、株式トレーディングなど、現実の状況での意思決定問題に対して強化学習の活用の幅は拡大の一途を辿っています。
以上のような理由から、ビジネス面でも特定の課題に対して強化学習モデルが十分有効に機能することが明らかになり、近年積極的に取り入れられるようになってきました。
以下に、ビジネスの現場で実践されている具体例を挙げます。
機械の自律制御
例えば、ロボットアームの運動制御やロボットの動作計画などに強化学習が応用されています。強化学習を使用することで、力学的に複雑な制御問題に対して、柔軟な対応が可能になります。
もう1つ例を挙げるなら、自動運転技術がこれに該当します。自動運転車は、随時周囲の状況を観察し、その場に応じて適切な行動を取る必要があります。強化学習によって、複雑な交通状況や道路条件に適応した運転を学習できます。
オペレーション最適化
こちらには、今回の記事で扱う在庫管理最適化が含まれています。他にも、生産ラインやタスク管理を課題とするスケジューリング問題や製品の配送最適化などを扱うロジスティクス最適化、化学プラントの自動制御が典型的な例です。時事刻々と変わる状況や考慮しなければいけない制約条件が多数存在する問題に対して、強化学習は既存の手法と比べ、より有用なソリューションを提供してくれる傾向にあります。
大規模言語モデル
記事冒頭でも触れた通り、2022年に突如として一般に普及した会話型AI、ChatGPTにもこの手法が適用されています。ChatGPTでは、人間によるフィードバックを用いた強化学習(RLHF)という手法によって、人間の指示に従いつつ、善良な人格を持つかのような応答を返すチャットAIを生成することに成功しています。このモデルの学習過程では、強化学習の学習過程で利用される報酬関数(後述)という部分に、人間による評価を反映させることでこうした性能を実現しています。
在庫管理最適化問題に踏み込む前に、今回用いる強化学習と利用する具体的なアルゴリズムについて簡単に紹介します。
強化学習は、以前に本ブログでも紹介した通り(こちらの記事参照)、試行錯誤を繰り返すことで、得られる報酬を最大化する行動原理(ポリシー)を獲得する学習プロセスです。
具体的には、学習の場として「環境」と「エージェント」が設定されます。環境は、具体的な課題の場を設定し、報酬(=最適化したい対象)を返す機能を持ちます。エージェントは、その時点におけるポリシーに従って、その課題に対して何かしらの行動を実施します。さらに、行動の結果として環境から返される報酬の振る舞いに従って、報酬をより増大させるようにポリシーを更新します。更新したポリシーをもとに、エージェントは再び行動を決定し、環境が返した報酬の振る舞いをもとに、さらに報酬を大きくするようにポリシーを更新していきます。このループを繰り返すことで、最終的にエージェントは、報酬を最大化するポリシーを獲得します。
強化学習の体系的な理解に興味がある方は、以下の書籍もぜひ参考にしてみてください。
今回取り組む在庫管理最適化問題は、「特定の状況で補充在庫量を適切に決定する」という連続値制御問題の1つです。この場合、強化学習のアルゴリズムとしてはポリシーベースの手法が好まれ、具体的にはActor-Criticというアルゴリズムやその発展系の1つであるPPOアルゴリズムといったものが用いられます。
とくに、PPOアルゴリズムはOpenAIが開発(こちら参照)し、ChatGPTの学習プロセスでも用いられている注目株のアルゴリズムです。今回はこのPPOアルゴリズムを使って強化学習を実装します。
ここではActor-CriticとPPOアルゴリズムについて、簡単に紹介します。
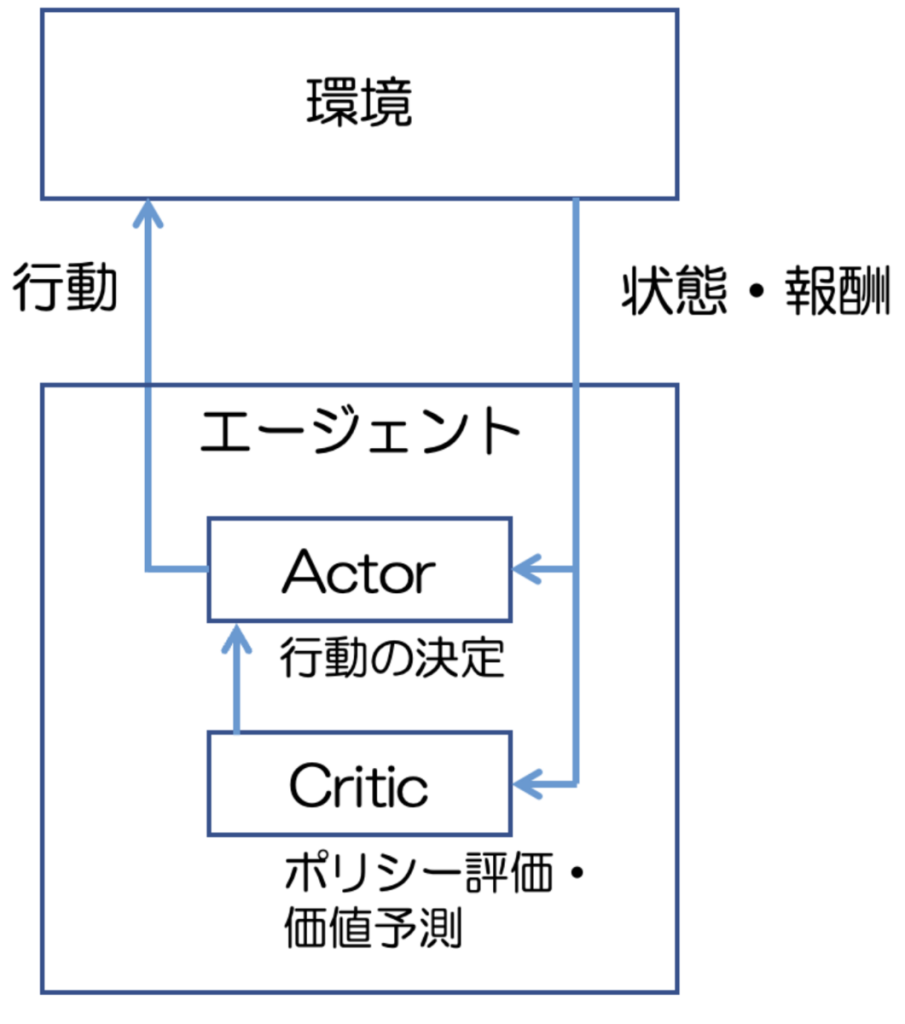
Actor-Criticでは図1のように、エージェント内にActorとCriticという2つの独立した役割が存在します。
Actorはポリシーに基づいて行動を決定する役割を担います。
CriticはActorが採用した行動の評価やポリシーに基づいた次の行動の価値を予測します。アルゴリズムの実行ステップは以下の通りです。
これらを踏まえた上で、PPOに軽く触れておきます。
基本的なアルゴリズムの設計はActor-Criticを引き継いでいます。その上で、ポリシーの更新が一工夫されています。
ポリシーベースの強化学習では、ポリシーの更新幅を大きく取ることが禁止されていない場合、学習の過程でポリシーが大幅に更新され過ぎてしまい、学習が不安定になる問題が知られています。
PPOではポリシーの更新時に、更新幅を小さくクリッピングすることで、大きなポリシーの変更を抑制する手法を採用しています。
この方法は実装が簡単であり、かつ高い学習性能を持つことが明らかになっています。
それでは、サプライチェーン全体の在庫管理最適化問題を具体的に設定した上で、強化学習モデル構築の詳細を見てみましょう。
なお、今回取り扱う強化学習による在庫管理最適化問題は、こちらの記事を先行調査として参照しています。その上で、この記事ではより発展的な事項(在庫管理の可視化やそこから見える強化学習モデルの特徴など)を含んだ内容になっています。
ここで扱う在庫管理問題を以下の条件で設定しました。設定の概要を図2で図解したので参照してください。

このケースで解くべき問題は、
「ある特定の期間における、サプライチェーン全体の収益(製品販売による売上と製品販売までにかかる在庫コストなどを含む総コストの差分)を最大化する在庫管理ポリシーを求める」
というものになります。
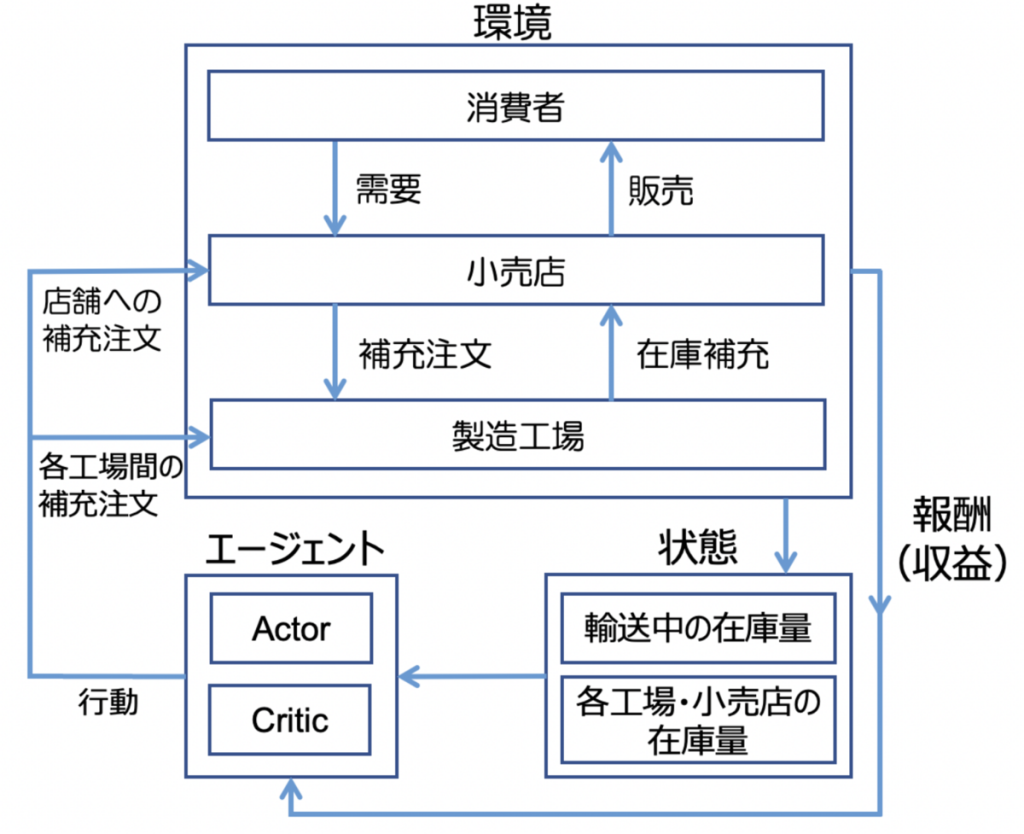
今回の問題設定における強化学習の「環境」と「エージェント」の関係は図3の通りです。
エージェントは、その時点でのポリシーに従って、小売店や各サプライヤーが発注する補充在庫量を決定します。
その後、在庫量の増減・販売処理が実行され、「状態」が更新(在庫量情報が更新)されます。その情報が収益とともに、エージェント側に返されます。エージェントはこのサイクルを繰り返し、設定したある期間の総収益を最大化するようにポリシーを更新していきます。
強化学習の学習アルゴリズムは前述の通り、PPOアルゴリズムを用います。
エージェントの強化学習は以下のPythonライブラリを利用して実行します。
ここでは、強化学習のための設定と学習自体のコードを置いておきます。ポリシー関数と価値関数のニューラルネットワークについては、共に64ノードx2層で構成しています。
一例としてシミュレーションの期間を30日、小売店での需要量を定常(+少しランダムな変動)とした場合を掲載しています。また、学習時の適切なハイパーパラメータとして、こちらの論文のテーブル3.1を参照しています。
実施した全ての強化学習は、モデルの改善が逓減する(収益の改善がみられなくなる)まで実施しており、一律に学習回数や学習時間を定めているわけではありません。
学習時間について
まず、実行環境はMacBook Pro(M1チップ、メモリ16GB、CPU8コア)を使用しました。
シミュレーション期間が30日の場合は、下記のコード中の “res = agent.train()” を2000 iteration程度回した段階で学習が完了し、全体の学習時間は2時間程度でした(iterationはポリシーが更新される単位で、2000 iterationなら2000回ポリシーが更新される)。
期間が180日の場合は、”num_workers = 4″, “num_cpus_per_worker = 4″とした上で、3000 iteration程度で学習が完了し、全体の学習時間は30時間程度でした。
学習のための設定
# 環境の作成
periods = 30 # シミュレーションの日数
env_name = 'InvManagement-v1' # 未達販売の後日販売を認めない場合の在庫管理を指定
env_config = {
"periods": periods
}
env = create_env(env_name, env_config)
# 学習に用いるバラメータ
num_workers = 1
num_cpus_per_worker = 1
num_epochs_for_sgd_minibatch = 10
num_episodes_per_train = 10 * num_epochs_for_sgd_minibatch * num_workers
# 強化学習の設定
config = {
"env": env,
"framework": "torch",
# 独立なエージェントの数と使用するCPU数
"num_workers": num_workers,
"num_cpus_per_worker": num_cpus_per_worker,
# 学習率
"lr_schedule": [[0, 5e-5], [400000, 1e-5], [800000, 5e-6], [1200000, 1e-6]],
# ネットワークに関するパラメータ
"vf_share_layers": False,
"fcnet_hiddens": [64,64],
"vfnet_hiddens": [64,64],
"fcnet_activation": "relu",
"vfnet_activation": "tanh",
# 経験の収集に関するパラメータ
# 参考: https://docs.ray.io/en/latest/rllib/rllib-sample-collection.html
"episode_mode": "complete_episodes", # workerから経験が収集されるとき、常にエピソード単位で収集される(エピソード途中までで終わっているrolloutは収集されない)
"sgd_minibatch_size": periods * num_workers * num_epochs_for_sgd_minibatch, # sgdが実行される際のバッチサイズ
"train_batch_size": periods * num_episodes_per_train, # 一回ポリシーを更新するにあたって収集されるバッチサイズ
# GPUの数
"num_gpus": 0
}
# 環境の登録
register_env(env_name, env_config)エージェントの強化学習
# エージェントの取得
ray.init(ignore_reinit_error=True)
agent = ppo.PPOTrainer(env=env_name, config=config)
# エージェントの学習
iteration = 5000
results = []
for i in range(iteration):
res = agent.train()
results.append(res)
# 10 iterationごとに現状までの学習の進捗(総報酬の変動)を表示
if i%10 == 0:
clear_output(wait = True)
rewards = np.hstack([i['hist_stats']['episode_reward']
for i in results])
# 各エピソードについて、その直前の100エピソードを利用した平均総収益とその標準偏差
p = 100
mean_rewards = np.array([np.mean(rewards[i-p:i+1])
if i >= p else np.mean(rewards[:i+1])
for i, _ in enumerate(rewards)])
std_rewards = np.array([np.std(rewards[i-p:i+1])
if i >= p else np.std(rewards[:i+1])
for i, _ in enumerate(rewards)])
fig = plt.figure(constrained_layout=True, figsize=(20, 10))
ax = fig.add_subplot()
ax.set_title('Iteration: {}'.format(i+1))
ax.fill_between(np.arange(len(mean_rewards)),
mean_rewards - std_rewards,
mean_rewards + std_rewards,
label='Standard Deviation', alpha=0.3)
ax.plot(mean_rewards, label='Mean Rewards')
ax.set_ylabel('Rewards')
ax.set_xlabel('Episode')
ax.set_title('Training Rewards, Iteration: {}'.format(i+1))
ax.legend()
plt.show()
# i+1 iteration目の平均総報酬
print('rIter: {}tReward: {:.2f}'.format(i+1, res['episode_reward_mean']), end='')
i+=1さて、それでは実際に在庫管理シミュレーションを実施してみましょう!…と言いたいところですが、もう1点だけ用意するものがあります。それは、強化学習モデルによる在庫管理の結果を比較参照するためのベースラインモデルを用意することです。
ここではベースラインモデルとして、基準在庫ポリシーという考え方を採用したモデルを利用します。
基準在庫ポリシーとは、最適な一定の基準在庫量を保持するように、各サプライチェーン間での補充注文量を決定する考え方で、従来から在庫管理最適化問題でよく利用されてきました。
このポリシーの下では、たとえばある工場の手持ちの基準在庫量を100としている場合に、手持ちの在庫が50だったとすると、工場サイドはサプライヤーへ50の補充注文を出すことになります。
エシェロン在庫
今回考える基準在庫ポリシーでは、基準在庫として単なる手持ちの在庫ではなく、エシェロン在庫を考慮します(本ブログで過去に最適在庫に関する記事を書いているので興味があればこちらもご参照ください。)。
エシェロン在庫とは、ある店舗やサプライヤーの手持ち在庫に加えて、それより下流にあるサプライチェーン全体の在庫(輸送中の在庫含む)のことを指します(エシェロンは「階層」の意)。
これによって、サプライチェーン下流の需要量変動によるサプライチェーン上流の過剰在庫や在庫の不合理な変動を防ぐ効果が知られています。
ベースラインモデルの実装
1サイクル(行動の決定→行動による環境の変化→収益・環境の状態のフィードバック)の流れは強化学習モデルと変わりありません(図4参照)。
基準在庫量ポリシーをもとに補充在庫量を決定し、その行動に応じた収益を環境から受け取ります。その後、在庫量の増減・販売処理を実行し、環境の状態を更新します。
このサイクルを1ヶ月や1年など与えた期間だけ実行し、その間に生じた総収益を計算します。
この総収益を目的関数として、これを最大化するような在庫ポリシーを求め、最適な基準在庫ポリシーを算出します。
基準在庫ポリシーの実装は、先行調査として参照しているこちらの記事記載のソースコードを取り入れています。記事中に実装内容が示されているので、実装の詳細が気になった方は参照してみてください。

それでは、上記で解説した強化学習モデルとベースラインモデルを使って在庫管理シミュレーションを実施してみたいと思います。
ここでは、2つのモデルによるシミュレーション結果から強化学習モデルの特徴や強みについて、理解を深めていきましょう。
実際に強化学習モデルを構築するにあたって、シミュレーションを実施する期間(1エピソードの長さ)を指定する必要があります。今回は30日と180日の2パターンを与えてみました。
なお消費者サイドで発生する需要量変動については、若干のランダムな変動を含む定常需要(ポアソン分布を利用)を仮定しています。
それ以外の在庫量の初期値や工場の生産能力、在庫保持コスト、製品の売上価格などは、断りがない限りは全てor-gymのデフォルトの値を採用しています。それらの数値に興味のある読者の方は、or-gymのソース上に全ての値が記載されていますのでご参照ください。
これらの条件の下で、強化学習モデルとベースラインモデルの性能や在庫変動の振る舞いの違いに着目しました。
図5は、1000エピソード分のシミュレーションを実施した際の、強化学習モデルとベースラインモデルの総収益のヒストグラムです。分布の広がりは、確率的な需要変動によるエピソードごとの総収益の違いを表しています(強化学習モデルについては、需要量変動だけでなく、学習したポリシー自体の確率的なばらつきも含まれているため、ベースラインモデルよりも広がった分布になっています)。

図5のグラフから、強化学習モデルがベースラインモデルより平均で60以上も総収益が高く、より良いモデルであることがうかがえます。なぜこのようになっているのでしょうか?
それを確認するために、あるエピソードのログを取り出して、強化学習モデルとベースラインモデルそれぞれの需要量に対する、販売個数と小売店および工場2、工場3の在庫量変動をプロットしました(図6)。
ちなみに、このエピソードにおける総収益は強化学習モデルが497、ベースラインモデルが438で、ともに平均値付近の値です。

まず、図6の1枚目のグラフから強化学習モデルの販売量(青線)のほうがベースラインモデルの販売量(オレンジ線)よりも需要量(灰色線)を満たしており、多くの商品を販売していることがわかります。
商品に欠品が生じる様子は、図6の下2枚の在庫量変動グラフからも伺えます。強化学習モデルの場合(図6の2枚目)は、エピソードの中盤でも上流から下流にかけて在庫供給が実施され、ある程度の在庫量を保っています。
一方で、ベースラインモデルの場合(図6の3枚目)は、エピソード中盤で在庫の供給が滞り、20日付近でサプライチェーン全体から在庫がなくなっているのがわかります。
なぜこのような事態になっているのでしょうか?
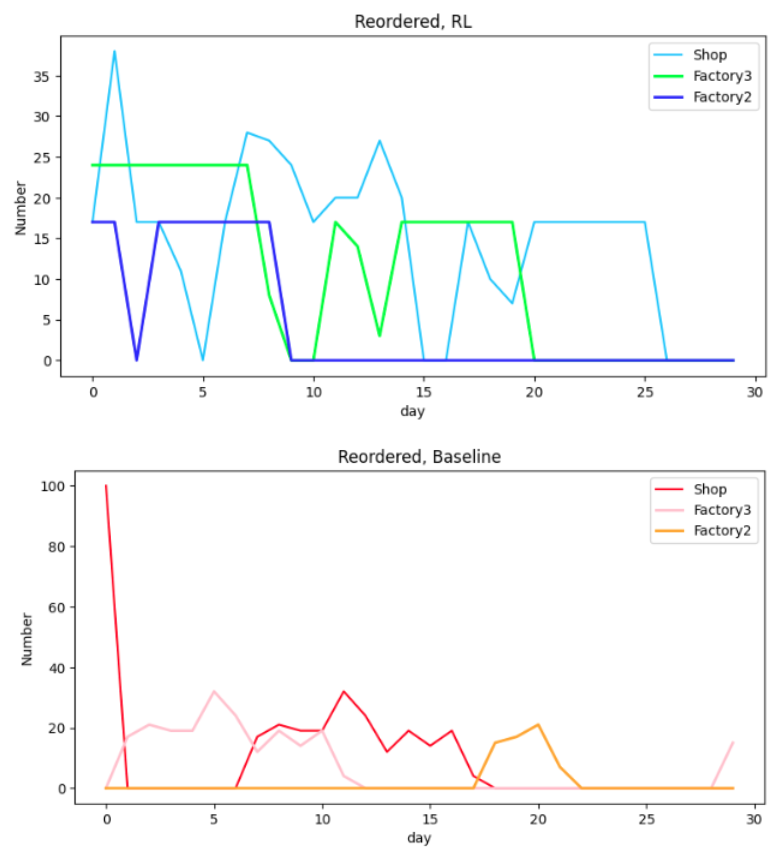
状況をより詳しく見るために、1日ごとにサプライヤーに発注する補充注文量を見てみましょう。
図7は、1つ上流のサプライヤー(小売店であれば工場3のこと)が対応した補充注文に対する発送数です。
注目すべきは工場2の補充注文です。強化学習モデルの場合(図7の1枚目青線)、エピソード序盤で発注をかけています。これにより、エピソード中盤で下流の在庫が枯れずに済んでいます。
一方で、ベースラインモデルの場合(図7の2枚目オレンジ線)、工場2はほとんど発注をかけていないために、エピソード前半で在庫が全く補充されていません。このせいでエピソード後半で、より下流のサプライチェーン上で慢性的な品薄状態となっています。
工場2の発注が遅れた根本的な原因は、3つあります。
したがって、工場2のエシェロン在庫が基準在庫量を下回るまで17日ほどかかる計算になります。実際に図7の2枚目にそれが表れています(18日目で初めて工場2から補充注文が出ています)。
それならば、基準在庫量を多くしたらどうかと思うかもしれませんが、そうすると今度はエピソード全体にわたって在庫保持コストがかかってしまい、販売による売上を上回ってしまうと考えられます。
結局、
という条件のもとでは、基準在庫量を少なくし、在庫保持コストを削減するほうが、需要をしっかり補うよりも収益増につながるということです。基準在庫ポリシーの弱点として、初期在庫を考慮した在庫管理ができないという点が明確になりました。
一方で、強化学習モデルに話を移すと、こちらはエピソード中盤でも在庫がしっかりと補充されていて、終盤の需要量をある程度補えていると言えます。
強化学習によって、サプライヤーへの適切な発注タイミングを初期在庫も考慮して学んだ結果と言えます。
ここまで扱ってきたのは30日という短期間のケースですが、ビジネスではより長期にわたって在庫管理する必要があります。したがって、より期間を長くした場合に2つのモデルで在庫量変動がどうなるかは気になるところです。
では、1エピソードを180日に設定した場合でそれを確認してみましょう。
まず2つのモデルの総収益のヒストグラムを図8にまとめました。これを見ると平均収益で45程度強化学習モデルが上回っています。

30日の場合と同様に、具体的なエピソードを取り出して、販売量と在庫量の振る舞いを見てみます(図9)。このエピソードの総収益は、強化学習モデルが693、ベースラインモデルが647で、ともに平均値付近の値です。
販売量については、ベースラインモデルでの欠品が少し目立つ一方で、強化学習モデルはより需要を満足できているように見えます。
在庫量変動は、最初の25日間以外は同じような振る舞いをしていることがわかります。ほぼ一定の需要の下では、強化学習モデルは一定在庫量を保つポリシーを獲得するということを意味しています。したがって、この点で、強化学習モデルはベースラインモデルと同等の性能を持つモデルだと言えます。
そうなると、総収益の平均が45程度離れているのは、在庫量が安定するまでの期間(開始から25日程度)に生まれているのではないかと考えることができます。
実際にそうなっていて、開始25日以降の総収益の差を見てみると、強化学習が4程度下回っているだけです。
つまり、30日のケースと同様に、2つのモデルの総収益の差分は、初期在庫を考慮した在庫管理ができているか否かで説明できるということです。

基準在庫ポリシーの最適化のTips
基準在庫ポリシーを決定する際に、報酬関数を最大化する手続きをとりますが、報酬関数に局所解が多数あるせいか、単に前述の基準在庫ポリシーの実装を紹介した記事の通りに、scipy.optimize.minimizeで最適化を実行してもうまくいかない(明らかに報酬関数が最大化されない解が返ってくる)可能性があります。そうした時には、scipy.optimize.minimizeを実行する際に、解を探索する範囲として、boundsパラメータを指定すると最適解が探索しやすいです。場合によっては探索の初期値(init_policy)も動かしてみる必要があるかもしれません。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













