



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスコンサルティングユニット所属の羽田です。
前回の記事にもあるように、現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
第5回となる今回は第3回に引き続き、ツール拡張のトピックから、新たに取り上げた4つの論文をご紹介します。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
今回の論文は、自然言語処理分野の国際学会であるACL2023にて行われたRetrieval based言語モデルのチュートリアル講演で紹介された論文から2本、加えてSNS等で話題になった最新の技術論文を2本選んで紹介していきます。
ACLのチュートリアルは2023年7月までのRAGに関する論文が体系的にまとまっており、動画とスライドも見ることができるので興味のある方はぜひご覧ください。
LLMの性能は飛躍的に向上している一方で、LLM単体では全ての知識を網羅することができず、往々にしてhallucinationを起こしてデタラメを言う問題があります。
そのような問題の解決方法として外部情報を元に文章を生成するという手法が挙げられます。
外部情報を参照する際には何を外部から取ってくるか(単語,文章チャンク,etc…)、検索結果をどのように用いるか(入力層、中間層、出力層)、どのくらいの頻度で検索を行うか、などを考える必要があります。
今回紹介する論文は文章チャンクをLLMの入力層に前置して文章を生成するIn-Context学習の代表的な論文であると思い、選定しました。
– 言語モデルおよびRetrieverの追加学習を必要としないシンプルな手法を提案している
– 様々な言語モデル、Retrieverの組合せに対して数値実験を行っており、ほとんどの場合で密なRetriever(NN系)よりも疎なRetriever(BM25)を用いた方が性能が向上した
– 文章生成時にどのくらいの頻度で外部情報を参照するかを変えて数値実験を行っており、外部情報を参照する頻度が高ければ高いほど性能が向上した
従来の研究では外部情報を参照して文章を生成する際に、言語モデルやRetrieverをファインチューニングする手法について焦点が当てられていました。
この論文ではそのような言語モデルやRetrieverに対するファインチューニングの必要がない文章生成のアルゴリズムについて検討しています。
ざっくりとしたイメージとしては下図のように文章生成をする際に予測する前までの文章をもとに外部情報を検索して、検索結果と生成中の文章を結合させて言語モデルに入力するという流れになっています。

ここで
といったようなパラメータが存在します。 まず一つ目のどのようなRetrieverが良いのかに対してはBM25のような疎なRetrieverの方が他のニューラルネットベースのRetrieverよりも高性能を示すことが報告されています。 今回はRetrieverのファインチューニングをしないという問題設定でしたが、ファインチューニングをした場合はまた結果が変わってくると予想されます。
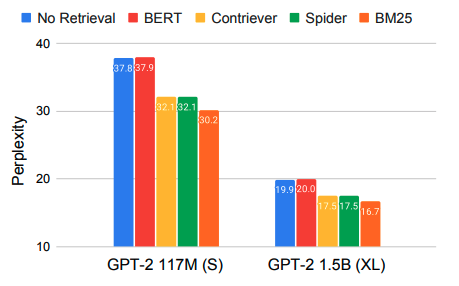
二つ目のRetrieval Strideに対しては下図のようにRetrieverで外部情報を取ってくる頻度が高ければ高いほど性能は高くなるという結果が得られています。 一方で毎単語予測するのにRetrieverで検索を行ってしまっては文章の生成速度が遅くなってしまうというトレードオフが存在します。
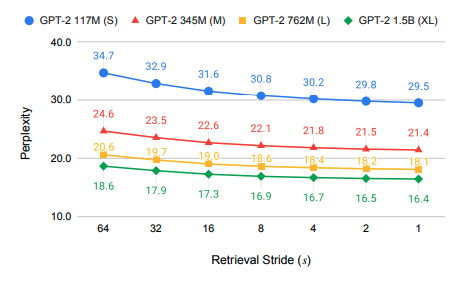
三つ目のRetrieval Query Lengthに対しては下図のような結果が得られています。 実験結果より外部情報を取得する際のクエリが長すぎると、生成したい単語に対して昔の情報がノイズとして働いてしまい、短すぎると生成する際のコンテキストが十分伝わならいという問題があり、短過ぎず長過ぎないちょうど良いクエリの長さが存在することがわかります。

Q. 数値実験における評価指標は何を用いているのか
– データセットに応じて単語ごとのPerplexityとトークンごとのPerplexityを用いて評価を行っている
| タイトル | 概要 |
|---|---|
| REALM: Retrieval-Augmented Language Model Pre-Training | 文章を生成する際に一回のみ外部情報を参照して生成 |
| Active Retrieval Augmented Generation | 次の論文紹介で説明 |
本論文もRAGにおけるIn-Context学習の代表的な論文であると思い、選定しました。 さらにこの論文は、先ほど説明した論文の問題点を解決を試みた論文でもあります。
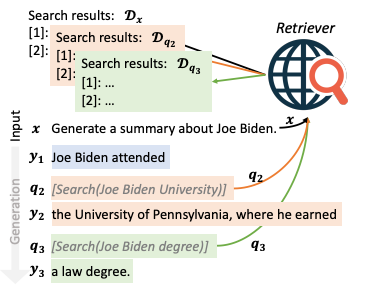
本論文では既存のnトークンごとに外部情報を取得するようなRetrieverとは異なり、言語モデルが出力した単語ごとに、その出力が自信がありそうならそのまま出力として採用して、自信がなさそうなら外部情報を検索してもう一度単語を生成するという手続きを踏むFLAREというモデルを提案しています。
モデルの出力の自信の有無を判断する基準として、論文中では以下の2種類の手法を提案しています。
Instruction FLARE
この手法では言語モデルに以下のようなプロンプトをInstructionとして与えます。
すると言語モデルが文章を生成する際に自信がない際には”[Search(query)]”のような検索クエリを出力します。
そのようなクエリが出力された際に初めてRetrieverが外部情報を検索して、取得した文章を結合して文章の生成を続けるというような手続きを踏みます。
 |  |
Direct FLARE
こちらの手法は言語モデルが予測した次単語のlogitの値を見ることで出力に対する自身の有無を判断します。
予め、適当な閾値を定めておきlogitがその閾値以上ならばその出力を採用し、そうでないならばRetrieverを用いて取得した結果を結合して改めて次単語を出力させるという手続きを踏みます。
下図の実験結果よりFLAREが既存モデルに比べて高い性能を出していることがわかります。
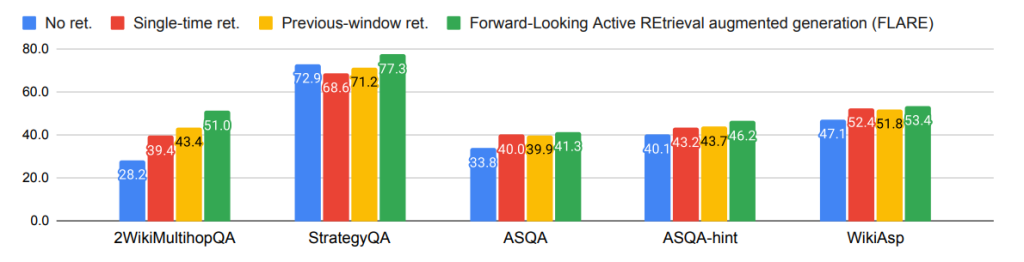
Q. ここでのRetrieverはどのようなモデルを使用しているのか – WikiAspについてはBing、それ以外の実験でBM25を使って実験を行っています。 コメント. FRAREはLangChainにも実装されている
| タイトル | 概要 |
|---|---|
| Learning to Retrieve In-Context Examples for Large Language Models | Retrieverを学習させる方向性の論文 |
最近では、GPT4のAdvanced Data Analysis(=旧Code Interpreter)やOSSのOpen Interpreterの登場によってLLMにコードを生成させて、生成させたコードを実行までさせることが可能になっています。 この論文ではGPT4がCode Interpreterを使用することでどの程度性能が向上するかを考察しており、今後Advanced Data AnalysisやOpen Interpreterを使用する上で有用な知見が書かれていると思い、選定いたしました。
本論文では以下の4つプロンプトを用いてMATH datasetの問題を解かせて正答率の違いを見ています。
3番の状況設定は普通に手元のGPT4のAdvanced Data Analysisを使って問題を推論させるような状況に対応しています。
特に4番の状況としては以下のようなものが論文中で例示されています。

< この例ではコードを使って予測した解に対して、LLM自身が検証コードを作って先ほど出力した解が誤りだと気づいて最終的に正しい答えを導き出しています。 数値実験の結果を下に示します。 結果よりコードの使用回数が増えるほど正答率が上がることが見て取れます。 さらに言語モデル自身に出力結果を検証させる手続きによっても正答率が大幅に向上していることが分かります。
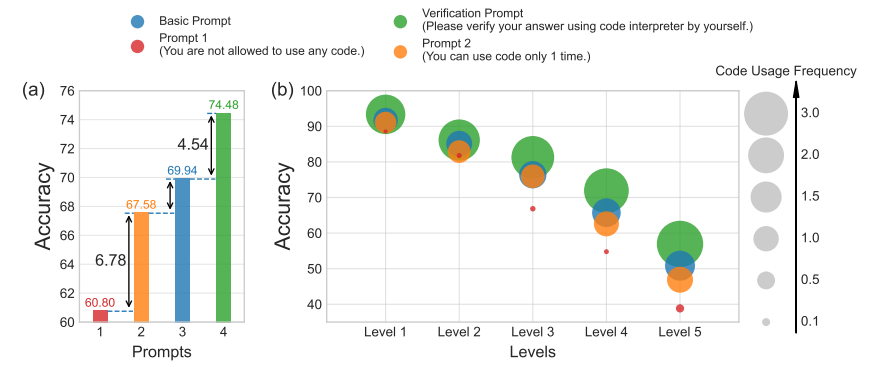
このようにして不等式の問題や方程式の問題に対しては、誤った回答を正すのに非常に強力な手続きのように思えます。 最近は、似たような検証作業を通して性能を上げる方向性の論文として以下の論文も挙げられます。
Chain-of-Verification Reduces Hallucination in Large Language Models
コメント. 最近だと似たような方向性の論文として”GPT Can Solve Mathematical Problems Without a Calculator“が提案されているこちらの論文はRAGを用いないモデルを考えている
| 関連論文 | タイトル |
|---|---|
| Chain-of-Verification Reduces Hallucination in Large Language Models | 文中で紹介 |
| GPT Can Solve Mathematical Problems Without a Calculator | 文中で紹介 |
実際に特定のタスクをLLMで解こうと思った際には、モデル, 学習データセット, 評価方法など様々決めなければならないことが存在します。 この論文では自然言語で解きたいタスクを説明すると、自動的に言語モデル学習のためのパイプラインを作成してくれるというモデルを提案しています。
Prompt2Modelは以下のように解きたいタスクを与えられた際に、モデルやファインチューニング用のデータセット、さらには必要ならば学習データを生成して最終的に評価指標とともに学習済みモデルを出力してくれます。
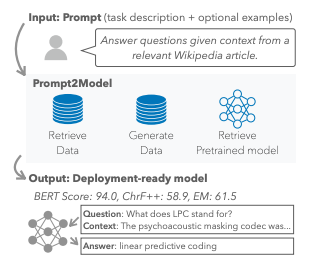
Prompt2Model細かいアーキテクチャは以下のようになっております。 ModelやデータセットはHugging上の説明文を参考にして取得してきます。
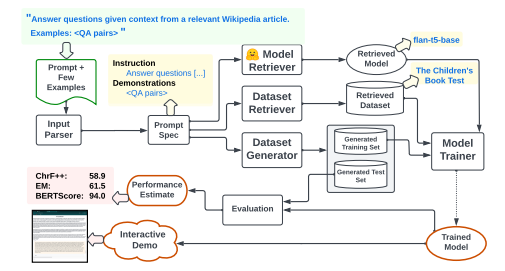
ちなみにこの論文の著者の方が今月末に行われる国内機械学習分野のワークショップであるIBIS2023の招待講演にてPrompt2Modelを話されるようです。
| タイトル | 概要 |
|---|---|
| A Survey on Large Language Model based Autonomous Agents | AgentベースLLMのサーベイ論文 |
| MetaGPT: Meta Programming for Multi-Agent Collaborative Framework | 複数のエージェントをコラボレーションさせることで、より複雑な問題な対処させる研究 (詳しくは第3回の記事をご覧ください) |
今回はRAGやAgentなどLLMのツール拡張に関する技術論文を4つ紹介させていただきました。 今後も、社内で実施しているレビュー会での発表内容をブログで発信させていただくつもりですので、ご期待ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













