

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスコンサルティングユニット所属の辻です。
現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
今回はLLMの高速化や効率化の話題の中から量子化に関するものとAttentionに関する論文をご紹介します。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
以前の調査に引き続き、LLMの高速化や効率化に関する最新の論文をピックアップしました。
LLMの量子化は熱心に研究が継続している領域ですし、Attentionの工夫による効率化もトピックとして見かけることが増えてきたので、今回はそれらを中心にご紹介します。
大規模言語モデルは高い性能を発揮する一方で、計算コストとメモリ使用量が非常に大きいという課題があります。
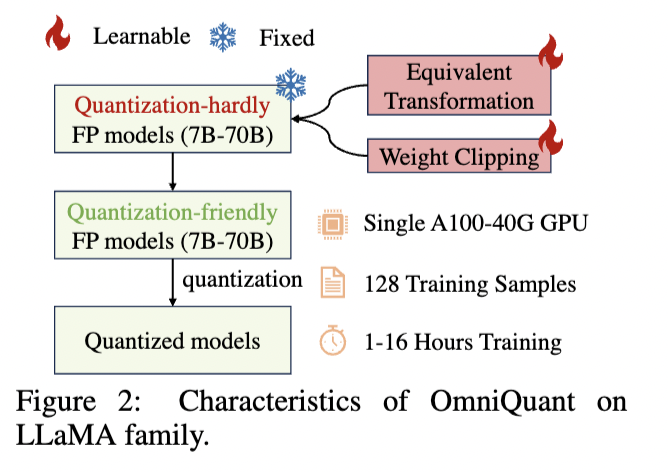
この課題に対する解決策として、量子化が頻繁に研究されています。OmniQuantは、この問題に対して画期的な手法を提供するとされており、その性能と効率性のバランスが優れているため、本論文を選定しました。
– Quantization Aware Training (QAT) と Post Training Quantization (PTQ) のトレードオフを解消
– 重みのクリッピングしきい値を最適化するLWCと、アクティベーションの離散化を容易にするLETの2つのコンポーネントがキーとなる技術
– OmniQuantは多様な量子化設定で従来手法より高性能であることを確認しており、実機での推論速度向上とメモリ削減効果が確認されている
既存の量子化手法には、トレーニング時に量子化を意識させるQuantization Aware Training (QAT)と、事後的に量子化を行うPost Training Quantization (PTQ)の2種類が存在します。しかし、QATは性能は高い一方で計算コストが大きく、PTQは効率的であるが性能が低下するというトレードオフが存在します。
特に、低ビット量子化では既存の量子化手法が性能を大幅に低下させる傾向があるため、いかに低ビットな状態でも精度を保ったままにできるかが盛んに研究されています。以前にご紹介した量子化の手法サーベイも同じモチベーションの研究結果がまとめられていますのでご参考にしてください。
今回提案されているOmniQuantは、QATの高い性能とPTQの高い効率性を両立させる新しい量子化手法となっています。
クリッピングしきい値を最適化して重みの極値を調整するLearnable Weight Clipping (LWC) と アクティベーションの離散化を容易にするLearnable Equivalent Transformation (LET) と呼ばれる2つのコンポーネントを用いることで、高精度かつ高効率な学習を可能にしています。
本論文は何を問題にしているか
本手法は、量子化を実施する際に生じる2つの課題を解消するために提案されています。
関連論文に記載している先行研究において1番目の問題は解消されており、本論文でもそれを踏襲する形で(LETがそれにあたる)採用しており、2番目の課題については、量子化誤差を最小にする動的なパラメータを求める仕組み(LWC)を採用することで解消しています。
OmniQuantの全体フロー
OmniQuantの全体的な処理フローについて整理しておきます。
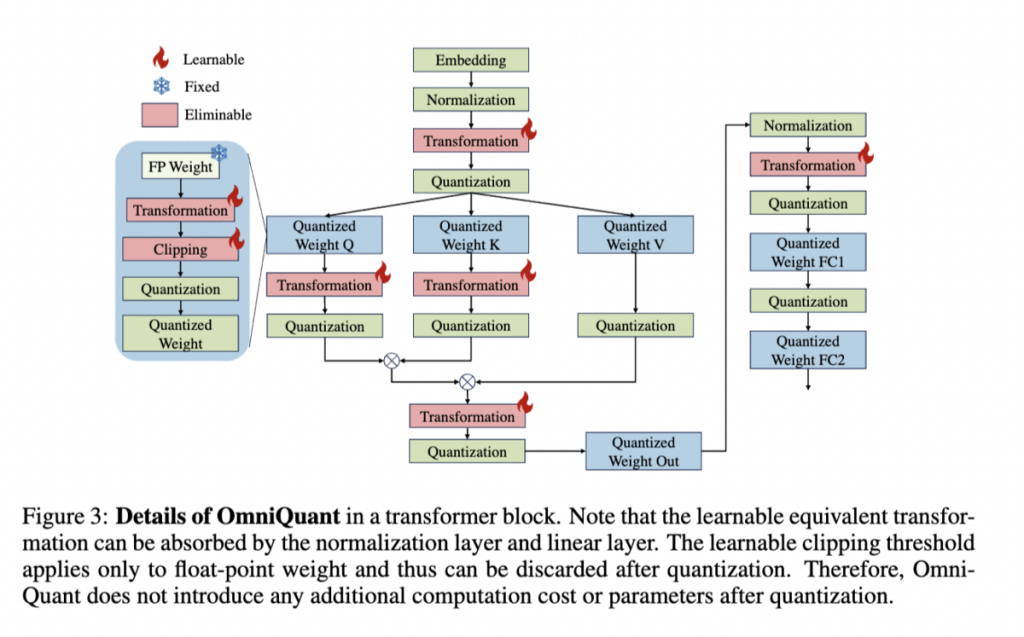
| 手順 | |
|---|---|
| 1 | 通常の精度でプリトレーニングされた全精度モデルを用意 |
| 2 | このモデルに対して、モデルの重みに閾値を適用するLWCと活性化関数に対して線形変換を適用するLETという |
| 3 | OmniQuantの2つのコンポーネントを適用。Figure.3のTransformationの部分でLETが適用され、ClippingのところでLWCが適用されているLWCとLETのパラメータを固定し、全体のファインチューニングは行わない |
| 4 | 学習済みのLWCとLETを用いて、目的の量子ビット数で重みとアクティベーションを量子化 |
| 5 | 量子化された低ビットモデルで推論を行う |
なお、論文内ではWeight-only quantizationとWeight-activation quantizationの2種類の量子化で検証が行われています。
Weight-only quantization:重みだけを低ビット値に変換する手法。これにより、モデルのメモリ消費が削減される
Weight-activation quantization:重みと活性化関数の両方を低ビット値に変換する手法。これにより、計算オーバーヘッドがさらに削減される
次にOmniQuantにおけるキーコンポーネントであるLWCとLETがどういう処理をしているのか確認してみましょう。
LWC (Learnable Weight Clipping)とは何か
LWC は、モデルの重みに対して 学習可能なクリッピングしきい値 を適用する方法です。
このしきい値は、量子化プロセス中に発生する歪み(量子化誤差)を最小限に抑えるように調整されます。
もう少し具体的な処理を確認すると、
1. 最初に、重みテンソルに対して一定の範囲(例えば-1から1)でクリッピングを行う
2. 次に学習可能なパラメータとしてクリッピングのしきい値を導入
3. 量子化による損失を最小化するように、このクリッピングしきい値を最適化
4. 最適なしきい値が見つかったら、それを固定
このようにして、LWCは量子化時の歪みを抑制し、量子化後のモデルの性能を向上させています。
LET (Learnable Equivalent Transformation)とは何か
LET は、アクティベーション(中間層の出力)に対して 学習可能な等価変換 を行います。
この変換は、アクティベーションの量子化による情報損失を最小限に抑えるために使用されます。
同様に、具体的な処理を確認すると、
1. 最初に、アクティベーションに対して学習可能な線形変換を適用
2. 量子化による損失を最小化するように、この変換のパラメータを最適化
3. 最適な変換パラメータが見つかったら、それを固定
このようにLETは、特にアクティベーションの量子化において、その性能を維持しつつ計算効率を向上させる役割を果たします。
OmniQuantの採用により、LLaMA-2モデルファミリーは、A100-40G GPU 1台で1~16時間以内に処理できるようになったと報告されています。
さらに、OmniQuantは、さまざまな量子化構成(Weight:2bit Activation:16bit, Weight:4bit Activation:4bitなど)、特に低ビット設定での優れた性能を示しているため、この新しい量子化技術は、LLMの実用的な導入を前進させる可能性がありそうです。
Q: clippingの上下限は全ての層で設定するのか
A: LWCにおいて、全ての重みテンソルに対してクリッピングを適用していると思われる
| 関連論文 | 概要 |
|---|---|
| SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression | 大きな量子化誤差の原因となる外れ値の重みを特定して分離し、それらを高精度で保存することで量子化精度を改善 |
| SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models | 数学的に同等の変換を使用してアクティベーションの外れ値を平滑化。LETはこの論文から着想を得ていると思われる。 |
| Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling | チャネルごとのシフトにより、アクティベーションの外れ値の非対称性が除去されるように各チャネルの中心を揃える手法。同様にLETはこの論文から着想を得ていると思われる。 |
今回紹介するPaged Attentionは2023年の6月ごろに[https://vllm.ai/:title=vLLM]というオープンソースライブラリーがリリースされたタイミングで採用されていたアルゴリズムになります。当時は論文としてはまとまっていませんでしたが、2023年9月に論文として発表されたため今回選出しました。
– OSのページング技術に触発された新しいアルゴリズムであるPaged Attentionを提案
– 提案手法により、メモリの断片化(フラグメンテーション)が大幅に軽減されLLMの処理速度が2〜4倍向上
先ほど紹介した論文の背景でも述べたとおり、Attentionメカニズム が導入されて以降、そのメモリ使用量はさらに増大しています。Attentionメカニズムでは、入力データと内部的に生成されるキー/バリューのペアを用いて、各単語やフレーズの重要度を計算していますが、この計算過程で生成されるキー/バリューのペアは、通常キャッシュメモリに一時的に保存されます。
従来のAttentionメカニズムでは、Attentionの計算に必要なキーとバリューを全てメモリに格納する必要があり、メモリの断片化(フラグメンテーション)が発生することでバッチサイズやスループットに制約をもたらしていました。
一方、本提案手法であるPaged Attentionはキーとバリューをページ単位で分割し、必要なページのみをメモリにロードすることで、メモリフラグメンテーションを軽減しています。また、それを基盤としたLLMサービングシステム「vLLM」についても論文内では詳細な解説が行われています。
LLMの従来のキー/バリューのメモリ管理のどこに問題があるのか
LLMは、前のトークンに基づいて新しいトークンを生成します。この逐次的な生成プロセスは、特定のシーケンス内の前のすべてのトークン、特にそれらのキーと値のベクトルに依存します。そのため、生成中に使用される前のトークンのキーと値のベクトルは高速に読み込みができるようにキャッシュしておく必要があります。キャッシュされたキー/バリューのペアはKVキャッシュと呼ばれます。
従来の手法ではKVキャッシュは入力とキー/バリューの対応付けのために、キャッシュメモリ上に全キー/バリューを格納する必要があり、リクエスト数が大きくなるにつれてメモリの大部分を占めるようになってしまう性質がありました。
実際にAttentionの計算では使われないKVキャッシュも大量にメモリに格納する必要があるためメモリフラグメンテーションが発生し、非効率なメモリ管理となっていました。また、LLMは入力Promptの長さから出力の長さを事前に予測できない点もメモリ管理を難しくしている点として指摘されています。
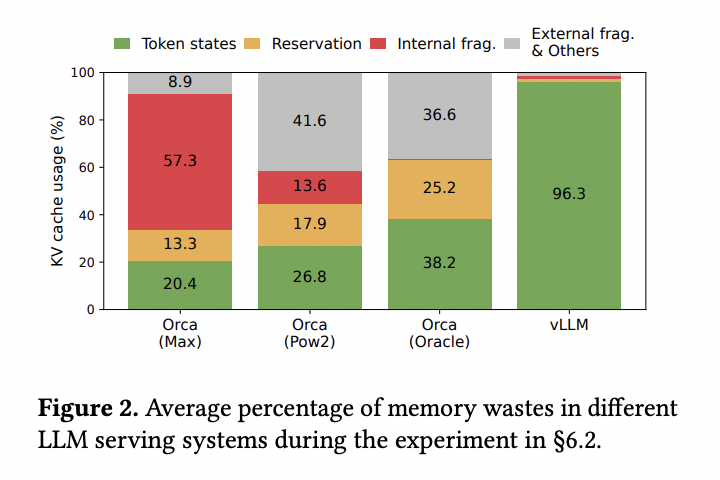
下図はvLLMと同様にKVキャッシュのバッチ処理とスケジューリングを改善したOrcaとPaged Attentionを採用したvLLMのメモリ消費の比較実験の結果であり、Orcaでは発生しているメモリフラグメンテーション(赤色部分)がvLLMではほぼ発生していないことがわかります。
提案手法であるPagedAttentionは、上記のKVキャッシュのメモリ管理の問題を以下のように解消しています。 PagedAttention
PagedAttentionの最も基本的なアイデアは、キー/バリューを一定サイズの「ページ」に分割することです。このページは、論文中ではKVブロックと表現されており、固定された数のトークンのキーと値のベクトルを持っています。このKVブロックは実際の物理メモリに連続して配置される必要なく、非連続なメモリ領域でも十分に機能します。PagedAttentionカーネルは、異なるKVブロックを個別に識別し、フェッチし各タイミングでクエリベクトルを特定のキーベクトルと掛け合わせ、Attentionスコアを計算するため、メモリフラグメンテーションの大幅な減少が期待できます。
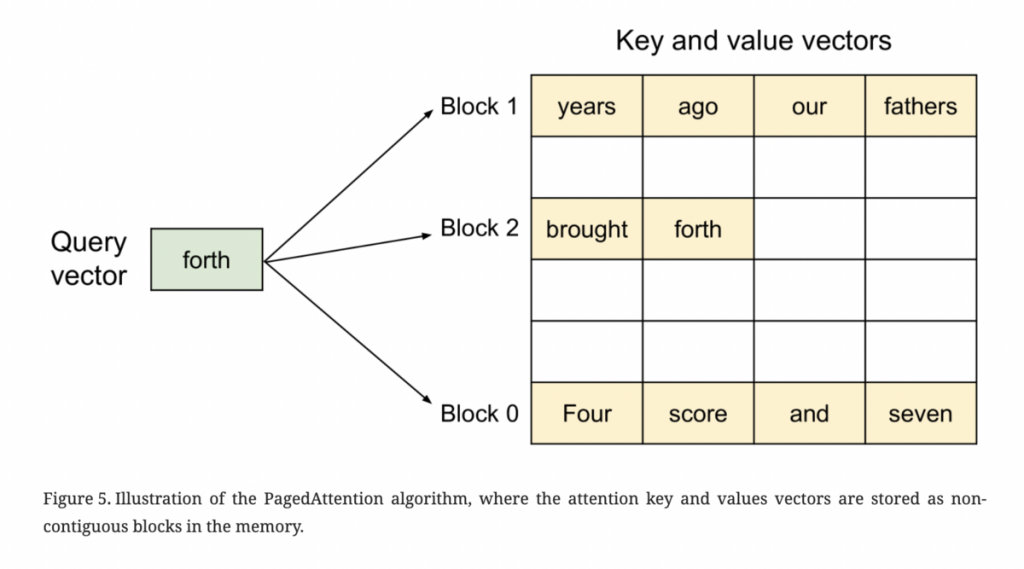
Paged Attentionのアルゴリズム自体は上記のシンプルなものですが、このコンセプトを最大限に活かすためにvLLMでは以下のような工夫が別途加えられています。 KV Cache Manager
vLLMはOSシステムの仮想メモリと同じコンセプトでKVキャッシュを管理する仕組みを導入しています。仮想メモリは、物理的なメモリを固定サイズのページに分割し、それらのページをユーザプログラムの連続した論理的なページにマッピングすることでユーザプログラムは物理的なメモリが断片的であっても連続しているかのようにメモリにアクセスできるようにするものです。
このコンセプトを応用して、KV Cache Managerは各リクエストの論理と物理のKVブロックのマッピングを管理しており、論理ブロックと物理ブロックを分離することでKVキャッシュメモリを動的に拡張することができ、全ての位置を事前に予約することなく、既存のシステムにおけるメモリの無駄をほとんど排除することを可能にしています。
レビュー会FB
Q: メモリが十分に余裕がある場合にはそこまでメリットはない?
A: 小規模なLLMで適用する場合には、メモリフラグメンテーションが生じてもスループットに影響は少なそうなので大したメリットは享受できないかもしれないが、LLMが大規模化していることを考えるとPaged Attentionのブロック化によるオーバーヘッドよりも動的なメモリ管理によるメモリフラグメンテーションの回避の方が実務上のパフォーマンスには好影響なのではと推察している
| 関連論文 | 概要 |
|---|---|
| Orca: A Distributed Serving System fo Transformer-Based Generative Models | 提案手法と同様にメモリスケジューリングを改善したLLMサービングシステム。論文中で比較対象としている。 |
| FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU | メモリの分散処理によりLLMのスループットを改善するアプローチ。弊社でも参考となるブログを執筆済み |
最近Huggingfaceにも実装されたトランスフォーマーのAttention層の計算コストを削減する新しい手法であるFlashAttentionとその拡張であるFlashAttention-2(実装されたのは[https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flash-attention-2:title=こちら])をご紹介します。これらの手法は、計算の並列性と作業分割(ワークパーティショニング)を改善することで、高速なアテンション計算を実現しており、今後実務においても活用の機会が多いと思われましたので選出させていただきました。
– FlashAttentionの貢献: Attentionの計算を再順序化とタイリングによって高速化
– FlashAttentionはGPUの高帯域幅メモリ(HBM)とGPUのSRAM間でのメモリの読み書きを最適化するためのIO-Awareなアルゴリズム
– FlashAttention-2の貢献: 並列性とワークパーティショニングをさらに改善し、FlashAttentionよりも約2倍のスピードアップ
今回はFlash Attentionの説明をした後に、Flash Attention-2でどのように改善されたのかを述べていきたいと思います。
FlashAttentionは、Stanford大学の研究チームによって提案された新しいAttentionアルゴリズムであり、既存のTransformerモデルが長いシーケンスで遅く、メモリ効率が低い問題に対処するために設計されました。
FlashAttentionは、下図にもあるようにGPUの高帯域幅メモリ(HBM: High Bandwidth Memory)とGPUのオンチップSRAM間でのメモリの読み書きを最適化するためのIO(Input/Output)-Awareアルゴリズムであり、タイリング(tiling)と呼ばれるテクニックを用いて、ソフトマックスの計算を部分的に行い、途中結果をSRAMに保存することで、HBMへのアクセスを削減しています。
また、FlashAttentionは既存のベースラインよりも高速で、長い文書に対する精度も向上させることが確認されています。
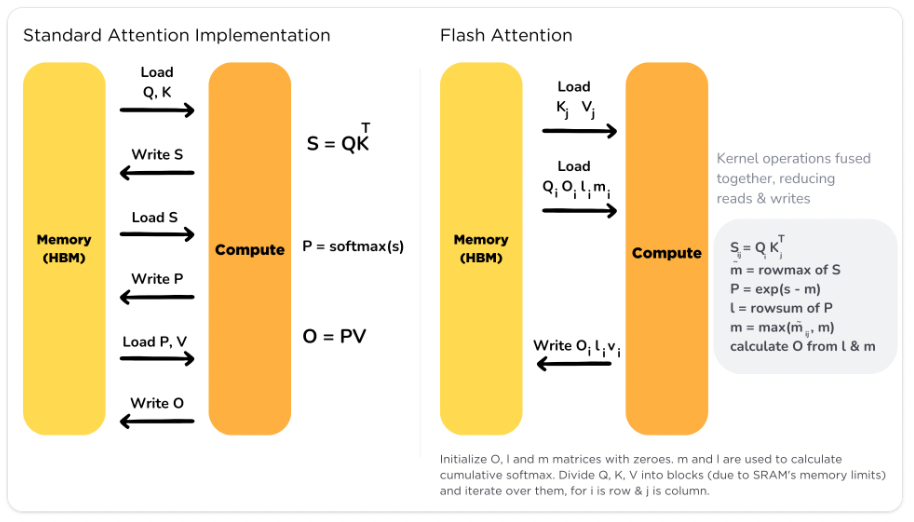
今回の記事で度々触れているように、Attention層の計算コストが高いために長いシーケンスを扱う際には計算時間とメモリが大きな問題となります。
FlashAttentionは、この問題に対処するために非対称GPUメモリ階層を効率的に活用して、Attentionの計算を高速化し、メモリ使用量を削減しています。具体的には、計算時間が2-4倍高速になり、メモリ使用量も線形に削減されるように設計されています。
FlashAttentionは、メモリの読み書きを削減するためにタイリングと呼ばれる古典的な技法を適用しています。先ほど紹介した論文ではメモリをページと見立てて動的にメモリを割り当てていましたが、こちらはデータをタイル状(小さな矩形)に分割して並列化しています。
さらに、オンラインソフトマックス((オンライン・ソフトマックスは、各ブロックに関して「ローカル」なソフトマックスを計算し、後で全体を再スケーリングすることで、一般的なソフトマックスの近似を実現する手法))を用いて、Attention計算をブロックに分割し、各ブロックの出力を再スケーリングしています。これにより、2-4倍のスピードアップが可能となっています。
FlashAttention-2は、FlashAttentionの基本的なアプローチにさらなる3つの改良を加えています。
1. アルゴリズムの微調整
GPUは行列乗算に特化しているという性質を踏まえて、非行列乗算のFLOP数(浮動小数点演算)を減らし、全体の効率を向上させています。
2.並列化の強化
シーケンスの長さに沿って計算を並列化することで、GPUの占有率を高めることが可能となります。
これは特に、シーケンスが長くバッチサイズが小さい場合に有効とされています。
3. 効率的なワーク・パーティショニング
異なるスレッドブロックやワープ間で作業を効率的に分割することで、共有メモリの使用量と通信コストを削減してます。
FlashAttentionは、BERT-large、GPT-2、およびlong-range arenaといった様々なベンチマークで既存の方法よりも高速であることが実験により確認されています。特に、GPT-2での処理速度は約3倍に向上し、BERT-largeでも15%の高速化が確認されました。
FlashAttention-2は、既存のFlashAttentionよりも約2倍高速であり、理論上の最大スループットにもっと近づいています。具体的には、フォワードパスでは73%、バックワードパスでは63%の理論上の最大スループットを達成しています。
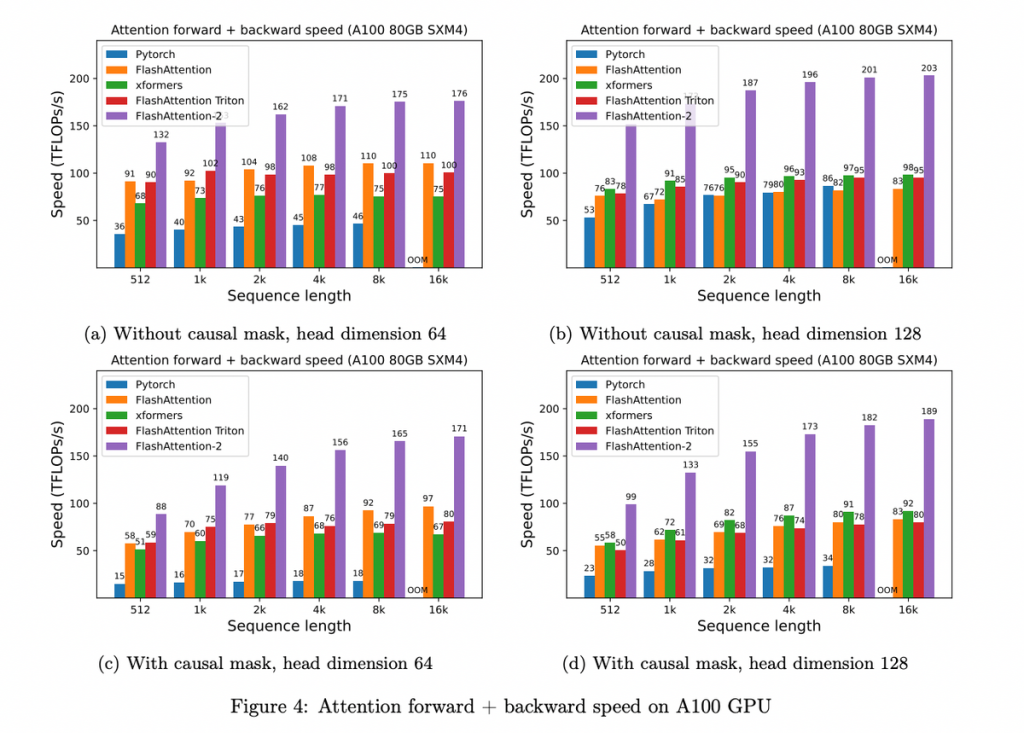
Q: 通常のAttentionと比べて同じ精度を達成できるのか、それとも精度を犠牲にして計算量を少なくしているのか A: 論文内では精度に関する検証は行われていないので、通常のAttentionから精度劣化があるかは不明。メモリの最適化に関するアプローチのため、劇的な精度劣化が生じる可能性は低いと思われるが断言はできない
| 関連論文 | 概要 |
|---|---|
| Reformer: The Efficient Transformer | Attentionの計算にlocal hashを用いてメモリ量を削減するアプローチ |
今回はLLMの高速化・効率化のテーマのうち、量子化に関する最新の論文とAttentionに関する論文についてレビューさせていただきました。 特にAttentionのキーバリューの計算やメモリ管理が実行速度に大きな影響を与えている点は実務面でも大きな課題になっているため、今後も現在のLLMを取り巻く課題を解決する論文を調査していければと考えております。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













